はじめに
インデックスを足し、EXPLAIN を読み、AI に手伝ってもらってクエリも整えた。それでも応答時間がじわじわ伸びていく。
最初は「クエリさえ磨けば速くなる」と思っていました。
でも、ある時点から打ち手が尽きます。原因はクエリの中ではなく、その外側にありました。
この記事では、個別のSQLチューニングやインデックス設計の話には深く入りません。それらを見直したあとでも効いてくる、データ量・データの年齢・アクセスパターンの話に絞ります。
なお、この記事では主に MySQL / InnoDB を前提に書いています。
TL;DR
- クエリの応答時間はクエリ単体では決まらない。データの量と年齢、アクセスのされ方が、その外側で効いてくる
- データ量が増えても「よく使う部分(ワーキングセット)」がメモリに収まる間は速いまま。崩れたら、削除・アーカイブ・ホット/コールド分離で取り戻す
- アクセスパターンを 4 つの観点(read/write・スループット・並行度・行アクセス)で見ると、読み込みを逃がす/書き込みを均す、といった打ち手を選び分けられる
1. クエリの外側を見る必要が出る瞬間
クエリ単体の最適化で解ける問題と、解けない問題があります。
後者は「データそのもの」と「アプリのアクセスのされ方」が原因なので、観察する場所を変えないとどうにもなりません。

インデックスが効いていても、テーブルの行数が増えるにつれて応答時間が伸びることがあります。インデックス自体もデータと一緒に育つからです。
「よく使うデータ」がメモリに収まる間は速いままなんですが、データ全体が増えてその範囲を超えると、ストレージ I/O に圧力がかかって全体が遅くなる。
この「よく使うデータ」は専門用語で ワーキングセット と呼ばれていて、次の章で詳しく扱います。
もう一つ厄介な性質があるんですよね。
スループット(流量)を上げ続けると、ある点から「速くなる」のではなく「不安定になる」のです。
MySQL に限らず、CPU・メモリ・I/O のどれかが飽和に近づくと、応答時間は線形には伸びず、不安定になりやすくなります。
「まだ少し余裕があるように見える」のに急に遅くなることがある、というのがクエリの書き方では解けない事実です。
2. レイヤ 1:データのライフサイクル
クエリの外側に最初にあるのは、データそのもの。データは時間とともに溜まり、古くなる。この変化が応答時間にじわじわ効いてきます。
2-1. ワーキングセット:少ないメモリで多くのデータを捌く仕組み
ワーキングセットとは「全データの中で、よく使われている部分」のことです。
MySQL は、よく使われるデータがメモリ上に乗っている間は、残りがディスクにあっても十分に速く動きます。
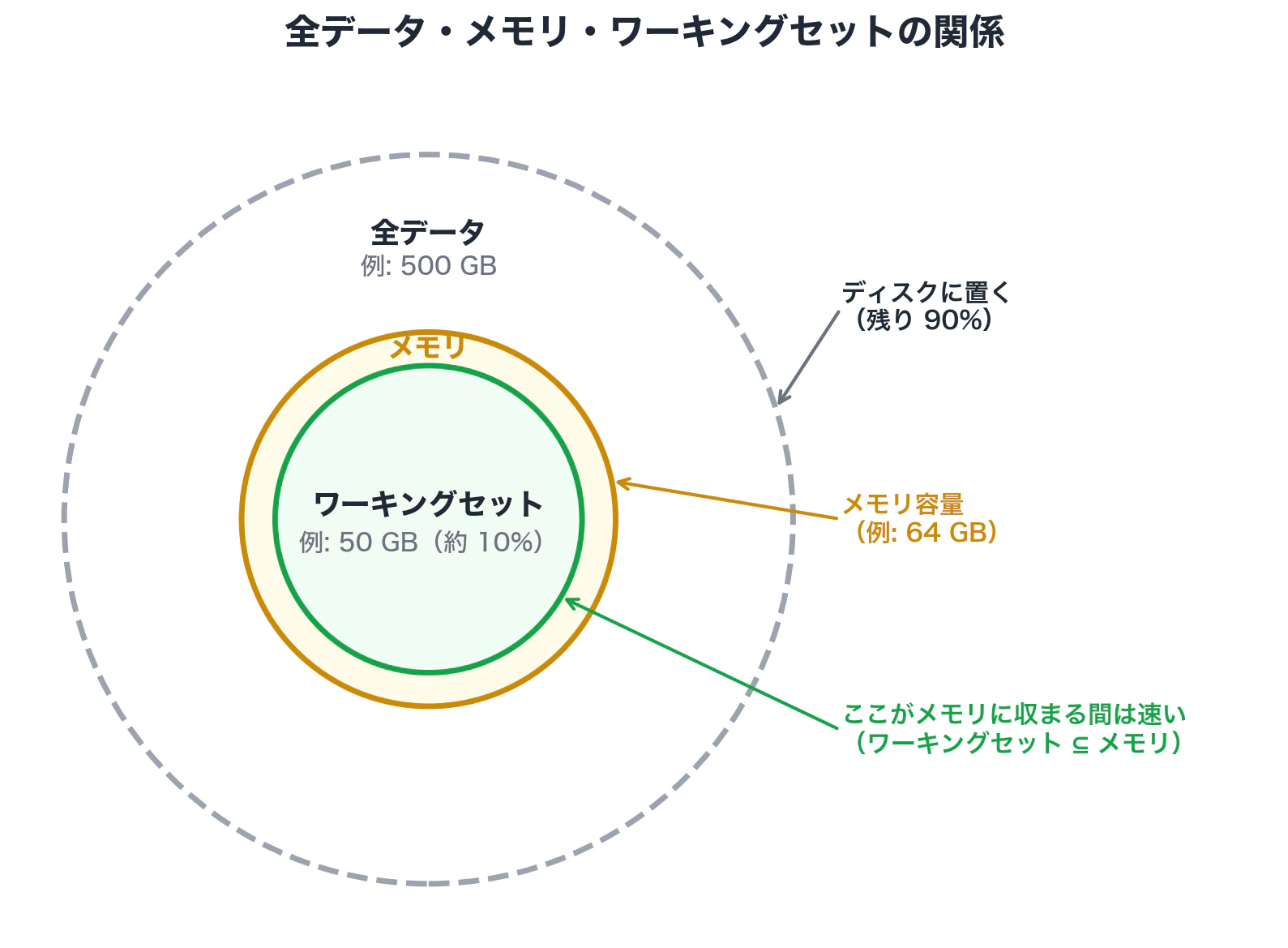
かなり雑な出発点としては、総データ量の 10% 程度のメモリから考えることがあります。
500 GB のデータベースなら 50 GB、丸めて 64 GB という具合です。
ただし、この比率はワークロードのアクセス局所性で大きく変わるので、最終的には計測しながら調整します。
これが崩れる条件は 2 つあります。
「総データ量がメモリより極端に大きい」と「古いデータへのアクセスが頻繁」が組み合わさったとき。
このとき、ワーキングセットがメモリに収まらなくなって、ディスクから読み直す回数が増え、全体が遅くなります。
2-2. データの「年齢」は時間ではなくアクセス順で決まる
ここでいう「古いデータ」は、時計の意味での古さではないんですよね。最後にアクセスされてから、他のデータがどれだけ多く触られたか で決まる相対的な位置です。
ここでは便宜上、メモリ上でどれだけ追い出されやすい位置にいるかを「年齢」と呼びます。
たとえば 1 週間前に登録されたユーザーでも、その後で他のユーザーへのアクセスが何百万回も発生していれば、そのユーザーのデータは「古い」状態になっています。
逆に 1 年前に登録されたユーザーでも、毎日ログインしていれば「新しい」まま。
年齢の高いデータに頻繁にアクセスし始めると、メモリから一度追い出された情報を、その都度ストレージから読み直すことになる。応答時間が伸びるのはこの瞬間です。
ポイントは「年齢 × アクセス頻度」の組み合わせで考えること。
たまにしか触らない古いデータは問題になりません。
古くて、しかも頻繁に触るデータが問題を起こします。
2-3. データを減らす:削除とアーカイブ
ライフサイクルの末端にあるデータは、削除するかアーカイブ(別の場所に移して本体から外す)します。
よく使われる範囲が小さくなれば、ワーキングセットが再びメモリに収まりやすくなります。
ただし、削除そのものが MySQL に負荷をかける操作だったりします。
運用中のデータベースで一気に大量に消すと、応答時間が伸びたり、レプリカへの反映が遅れたりするんですよね。
そこで、少しずつ消す バッチ削除 が使われます。
| パラメータ | 役割 | 目安 |
|---|---|---|
| バッチサイズ | 1 回の DELETE で消す行数 |
1,000 行からスタート |
| 1 文の実行時間 |
DELETE 1 文あたりの上限 |
500 ms 以内に収める |
| 実行間隔(スロットリング) | 次の DELETE までの待ち時間 |
まず 200 ms から始め、様子を見て短縮 |
数字はあくまで出発点で、実環境で計測しながら調整します。
1 文あたり 500 ms 以内に収める、くらいを最初の目安にすると、レプリカへの反映遅れ(レプリケーションラグ)やロック時間を観察しながら調整しやすくなります。
注意点が 2 つあります。
一つは、データを削除しても、OS から見える空きディスク容量がすぐ戻るとは限らない こと。
InnoDB 内では再利用可能な領域になりますが、ファイル自体を小さくするにはテーブル再構築などの別操作が必要になることがあります。
もう一つは、削除の操作そのものがバイナリログに書き込まれるため、削除しているのに ディスク使用量は一時的に増える ことすらある、という点。
2-4. ホット/コールド分離:データを動かさずに置き場所を変える
削除も難しいデータには、もう一つの選択肢があります。頻繁に触る ホットデータ と、滅多に触らない コールドデータ を物理的に分けることです。
決済データを例にすると分かりやすいと思います。
直近 90 日の取引はホット(変更・参照の対象)、それ以前は明細表示など参照頻度が低いコールド、と分ける。
アプリの大半の処理は「直近 90 日」しか触りません。
分離すると、ホット側のテーブルが小さくなって、ワーキングセットがメモリに収まりやすくなる。
コールド側は別テーブルでも、別データベースでも、Amazon S3 のようなオブジェクトストレージでも構いません。
コールド側に求める検索性能や保管要件で決まります。
先ほどの削除が「データを捨てる」打ち手だとすると、こちらは「データを残したまま分ける」打ち手。
どちらもワーキングセットを小さく保つための手段で、捨てるか分けるかの違いです。
3. レイヤ 2:アクセスパターン
データ量と年齢を整えても、まだ応答時間に効く要素が残っています。同じ量のデータでも、アプリの アクセスのされ方 が違えば、性能はまったく違ってくる。
MySQL の性能上限は、MySQL 側の設定やスキーマだけでなく、それを使うアプリのアクセスパターンにも大きく左右されます。
「なぜ CPU 50% のままで QPS が上がらないのか」と MySQL を睨んでも答えは出ません。
MySQL だけを見ていても、原因にたどり着けないことがあります。
3-1. 観点で切る:主軸 4 つ
アクセスパターンを見るときは、まず次の 4 つに分けると考えやすいです。
| 観点 | 何を問うか | 性能にどう効くか |
|---|---|---|
| read/write | 読み込みと書き込みのどちらが多いか | スケールさせる手段がまったく違う |
| スループット | QPS とその変動 | 突発か定常か周期的かで取れる手が変わる |
| 並行度 | 同じデータに同時にアクセスする頻度 | 行ロック競合の発生確率を決める |
| 行アクセス | 単一行・範囲・ランダムのどれか | 書き込み時のロック範囲と性質が変わる |
ほかにもデータモデル、整合性要件、トランザクション分離、結果セットの形などを見ることはあります。
ただ、この記事で扱う打ち手からは少し外れるので、ここでは深掘りしません。
整合性要件だけは、あとで読み込みオフロードの前提として出てきます。
3-2. read/write:スケールの非対称性
読み込みと書き込みでは、スケールさせる方法がまったく違います。
| 種別 | スケールの難易度 | 主な手段 |
|---|---|---|
| 読み込み | 比較的楽 | レプリカ(ソースノードの複製)・キャッシュへの分散 |
| 書き込み | 難しい | 最終手段は シャーディング(データを複数 MySQL に水平分割) |
書き込みが難しいのは、整合性や順序を保つ必要があり、単純にコピー先を増やせばよいわけではないからです。
打ち手を考える前にまず、自分のアプリが read-heavy なのか write-heavy なのかを掴むだけで、取りうる手の候補が大きく絞れます。
3-3. スループット:QPS は「量」ではなく「質」
QPS(秒間クエリ数、Queries Per Second)は数値としては分かりやすいんですが、それ単体では性能を語れません。
同じ 1,000 QPS でも、軽い主キー検索 1,000 件と、5 テーブルを結合する集計クエリ 1,000 件では、MySQL にかかる負荷は桁違い。
「QPS が高いから危険」「低いから安全」とは言えないんですよね。
もっと重要なのは 変動の形 です。同じ平均 QPS でも、変動のされ方で取れる手が変わってきます。
| 変動の形 | 例 | 取りうる手 |
|---|---|---|
| 突発型 | キャンペーン開始時に一気に流入 | キュー・キャッシュで吸収 |
| 定常型 | 24 時間ほぼ一定 | ハードウェア増強・シャーディング |
| 周期型 | 平日 9〜17 時だけ高い | 夜間にスキーマ変更やバックフィルを逃がす |
「常に高い」状態だと、重い作業を流す窓がありません。「周期的」が見えていれば、その低い時間帯に重い作業を寄せる打ち手が取れます。
3-4. 並行度と行アクセス:書き込みのロック競合
並行度 は、同じ行に同時に書き込みが集中する頻度のこと。
たとえば「いいねカウンタ」のような単一行への書き込みが秒間 1,000 件来るような状況は、並行度が高い書き込みの典型です。
並行度が高くなると、行ロック競合(同じ行への書き込みが順番待ちになる現象)が起きます。
応答時間の悪化なら許容範囲ですが、待ち時間がタイムアウトに達するとクエリエラーになり、アプリ側でリトライ処理が必要になる。
もう一つ関連する観点が、行アクセスの種別 です。
| 行アクセスの種別 | 例 | 書き込み時の典型的な問題 |
|---|---|---|
| 単一行 | 主キーで 1 行を更新 | 同じ行への並行度が高いとロック競合 |
| 範囲 |
WHERE created_at BETWEEN ... で更新 |
ギャップロック(範囲内の隙間にも乗るロック)で競合が広がる |
| ランダム | 順序を持たない複数行を更新 | デッドロック(互いのロックを待ち合う状態)が起きやすい |
※ 実際のロック範囲は、分離レベルや使われるインデックスによって変わります。
書き込みで応答時間が伸びていて、原因が並行度や行アクセスにあると分かったら、取れる手は基本的に 2 つ。
「並行度そのものを下げる」か「データを分散させて競合の発生確率を下げる(シャーディング)」か、です。
4. 打ち手:読み込みを逃がす・書き込みを均す
ここまでで見るべきポイントは揃いました。
データ側の対策が「減らす/分ける」だとすると、アクセス側の対策は「逃がす/ならす」です。
read 側と write 側で打ち手の性質はまったく違う。read は「逃がす」、write は「均す」、と方向性が分かれます。
4-1. 読み込みオフロード:レプリカとキャッシュ
読み込みを全部ソースノードに集める必要はありません。レプリカやキャッシュに逃がせる読み込みは逃がしてしまう。
ただし、逃がせるのは次の条件を満たす読み込みに限られます。
- 少し古いデータが返っても問題ない(結果整合性 を許容できる、つまり「最新ではないが、いずれ最新に追いつく」状態を受け入れられる)
- 複数文をまたぐトランザクションの一部ではない
「いいね数が 100 ではなく 98 で返ってきても構わない」ようなケースは前者を満たします。逆に決済の残高確認のように最新値が必須の読み込みは逃がせません。
レプリカとキャッシュには、それぞれ向き不向きがあります。
- レプリカ: 同じ SQL がそのまま動く。高可用性のために用意したインフラを流用できるので追加コストが小さい。読み込みのオフロード先として最初に検討する候補
- キャッシュ(Redis や Memcached): MySQL より圧倒的に速いが、無効化・更新・障害時のフォールバックなど、アプリ側に持つロジックが増える
どちらを選ぶにしても、逃がし先が落ちたときの振る舞い(完全停止か、機能制限で動かすか、ソースに自動で戻すか)を先に決めておきます。
設計しないままオフロードを始めると、依存先が落ちた瞬間にアプリ全体が止まります。
4-2. 書き込みキュー:スループットを均す
書き込みは尖りやすい性質があります。
普段は秒間 20,000 件で安定していても、5 秒のメンテで止まれば 100,000 件の積み残しが一気に押し寄せる。
待っていたリクエストが一斉に殺到する、いわゆる サンダリング・ハード(Thundering Herd) の状況です。
MySQL は突発的な流入に対して自分でブレーキをかけません。来たクエリを全部実行しようとして、結果として性能が崩れる。
そこで、アプリと MySQL の間に キュー(書き込みを一時的に溜める仕組み。Amazon SQS や Apache Kafka が代表例)を挟みます。
キューが突発分を吸収するので、MySQL は安定したレートで処理を続けられる。
副次的な利点もあります。
MySQL が一時的にダウンしてもアプリは書き込みを受け付けられますし、失敗したリクエストの再投入や、Kafka なら過去イベントの再生もできます。
write-heavy で突発的な流入があるアプリでは、キューはかなり有力な選択肢になります。
4-3. 打ち手の選び分け
ここまでの打ち手を、症状から逆引きできるように並べると次のようになります。
| 症状 | 主な打ち手 |
|---|---|
| read-heavy で応答時間が伸びる | 読み込みオフロード(レプリカ・キャッシュ) |
| write-heavy で書き込みが尖る | 書き込みキューでスループットを均す |
| 古いデータを引きずる/履歴アクセスが重い | ホット/コールド分離 |
| データ量が増えてワーキングセットが膨れる | 削除・アーカイブで総量を減らす |
症状が複数当てはまることもあります。その場合は、効果の大きそうなものから一つずつ試して、各段階で計測するのが現実的です。
5. おわりに
MySQL の応答時間は、MySQL の中だけを見ても説明しきれないんですよね。データの量と年齢、そしてアプリのアクセスパターンが、その背景に静かに効いています。
クエリチューニングを尽くしたあとで「あとは何ができるか」と感じたら、観察する場所をクエリの外側に移してみてください。
同じ MySQL でも、アプリの設計次第で出せる性能はまったく違います。