はじめに
- GROUP BY: 行を畳んで集計値を返す
- ウィンドウ関数: 行を畳まず、集計値だけ横に並べる
「畳まない」が要件になった瞬間、ウィンドウ関数の独壇場です。
TL;DR
- ウィンドウ関数は「集合を集約せずに、各行に集計値を横に持たせる」装置です
-
OVER句の中身は「どの集合に対して/どの順序で/どの範囲で」という3つの問いに答えています - これが分かれば、累計・移動平均・前行との差分・カテゴリ内ランキングが同じ枠組みで書けます
第1章 GROUP BYでは書けないクエリ
具体的なテーブルを置いて話を進めます。ECサイトの注文ログを記録した Orders テーブルを考えます。
CREATE TABLE Orders (
order_id INTEGER,
user_id INTEGER,
category VARCHAR(20),
order_date DATE,
amount INTEGER
);
サンプルデータは次の通りです。
| order_id | user_id | category | order_date | amount |
|---|---|---|---|---|
| 1 | 101 | books | 2025-04-01 | 1500 |
| 2 | 102 | books | 2025-04-02 | 2000 |
| 3 | 103 | apparel | 2025-04-02 | 3500 |
| 4 | 101 | apparel | 2025-04-03 | 4000 |
| 5 | 104 | books | 2025-04-04 | 1800 |
| 6 | 102 | apparel | 2025-04-05 | 2800 |
ここで「カテゴリごとの売上合計」だけを出すなら、GROUP BY で十分です。これは見慣れた世界です。
SELECT category, SUM(amount) AS category_total
FROM Orders
GROUP BY category;
| category | category_total |
|---|---|
| books | 5300 |
| apparel | 10300 |
ところが、要件が少し変わって「個々の注文行を残しつつ、その注文が属するカテゴリの売上合計を横に並べたい」となると、途端に書けなくなります。
ほしい出力はこうなります。
| order_id | category | amount | category_total |
|---|---|---|---|
| 1 | books | 1500 | 5300 |
| 2 | books | 2000 | 5300 |
| 3 | apparel | 3500 | 10300 |
| 4 | apparel | 4000 | 10300 |
| 5 | books | 1800 | 5300 |
| 6 | apparel | 2800 | 10300 |
GROUP BY は行を畳む道具なので、order_id や amount と category_total を同じ行に並べる構造は作れません。代わりに自己結合や相関サブクエリで頑張ることになり、コードはぐっと複雑になります。
第2章 ウィンドウ関数の核アイデア「行を残しながら集約する」
一文で言うと 「行を畳まず、各行に集計値を横付けする」 関数です。第1章のほしい出力は、ウィンドウ関数を使うとこう書けます。
SELECT order_id,
category,
amount,
SUM(amount) OVER (PARTITION BY category) AS category_total
FROM Orders;
出力は先ほどの「ほしかった表」と同じです。元の6行がすべて残ったまま、各行にカテゴリ合計が横に並びます。
GROUP BY 版とウィンドウ関数版を並べて見ると、違いが鮮明になります。
| 観点 | GROUP BY | ウィンドウ関数 |
|---|---|---|
| 行数 | カテゴリ数まで畳まれる | 元の行数のまま |
個々の order_id
|
出力できない | 出力できる |
| 集計値 | 1行に1つ | 各行に横付け |
| 関数 |
SUM / AVG / COUNT / MAX など |
同じ。違うのは OVER (...) が付くだけ |
SUM / AVG / COUNT / MAX は OVER (...) が付くか付かないかで集約関数とウィンドウ関数のどちらとして動くかが切り替わります。一方、ROW_NUMBER のように OVER 句を必ず必要とするウィンドウ専用関数もあります(第4章で扱います)。
元のテーブルの行数も行内容も壊さず列だけを追加する。この性質が、第1章で詰まっていた要件に正面から答えています。
第3章 OVER句を3つの問いで読み解く
OVER 句の中身(PARTITION BY、ORDER BY、フレーム指定)は初見だと呪文に見えます。ただ、これらは全部「集計対象の絞り方」を決めるための指定で、次の3つの問いに分解できます。
-
どの集合に対して 集計するのか? →
PARTITION BY -
どの順序で 並べた前提で集計するのか? →
ORDER BY - そのうちどの範囲を 集計対象に含めるのか? → フレーム句
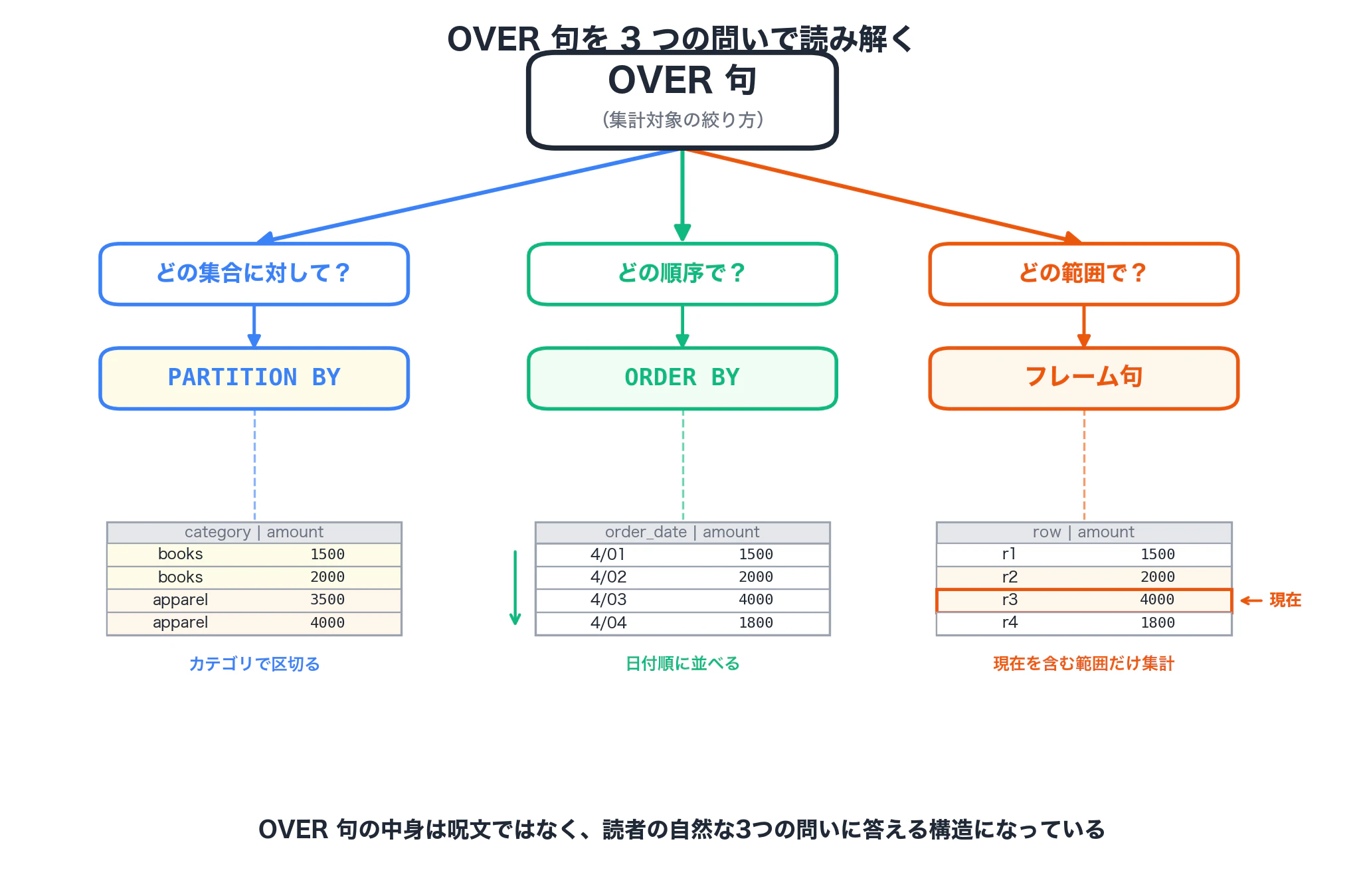
3-1 どの集合に対して?(PARTITION BY)
「集計対象の集合をどう区切るか」を指定するのが PARTITION BY です。「カテゴリごとの集計」が欲しいなら、行をカテゴリで区切って、その区切りの中で集計します。
SELECT order_id,
category,
amount,
SUM(amount) OVER (PARTITION BY category) AS category_total
FROM Orders;
PARTITION BY は 集合の区切り方 を指定する句です。
区切られたそれぞれの行のグループを パーティション と呼びます。
今回の例だと、books パーティションと apparel パーティションができます。
各行は自分が属するパーティションの集計値を横に持つことになります。
| order_id | category | amount | パーティション | category_total |
|---|---|---|---|---|
| 1 | books | 1500 | books | 5300 |
| 2 | books | 2000 | books | 5300 |
| 5 | books | 1800 | books | 5300 |
| 3 | apparel | 3500 | apparel | 10300 |
| 4 | apparel | 4000 | apparel | 10300 |
| 6 | apparel | 2800 | apparel | 10300 |
区切り方そのものは GROUP BY と同じで、行を集約しない点だけが違います。
PARTITION BY = GROUP BY − 集約 と覚えるのが一番分かりやすい整理です。
OVER () と書けば結果セット全体が1つのパーティション扱いになります(全注文の総合計を各行に横付け)。
3-2 どの順序で?(ORDER BY)
「パーティション内で行をどう並べるか」を指定するのが OVER 句内の ORDER BY です。
SQLの ORDER BY は2箇所に登場するので、本記事では区別のため呼び分けます。
ORDER BY の場所 |
役割 |
|---|---|
OVER (...) の中 |
パーティション内で行をどう並べるかを決める |
| クエリ全体の末尾 | 結果セットの最終的な表示順を決める |
注文を日付順に並べた累計売上(running total)を出す例です。
SELECT order_id,
order_date,
amount,
SUM(amount) OVER (ORDER BY order_date) AS running_total
FROM Orders;
| order_id | order_date | amount | running_total |
|---|---|---|---|
| 1 | 2025-04-01 | 1500 | 1500 |
| 2 | 2025-04-02 | 2000 | 7000 |
| 3 | 2025-04-02 | 3500 | 7000 |
| 4 | 2025-04-03 | 4000 | 11000 |
| 5 | 2025-04-04 | 1800 | 12800 |
| 6 | 2025-04-05 | 2800 | 15600 |
SUM なのに全行が15600にならないのは、OVER 句に ORDER BY を入れた瞬間、暗黙のフレーム指定が発動するためです。
デフォルトの集計範囲は「パーティションの先頭から、カレント行と同じ並び順の値を持つ行まで」になり、累計として動きます。
表で 2025-04-02 の2行が同じ running_total = 7000 になっているのはこのためです。
逆に OVER () と ORDER BY なしで書くと全行が同じ値(15600)になります。
これが ORDER BY の有無で挙動が変わる正体です。
3-3 どの範囲で?(フレーム句)
「カレント行(今処理している1行)から、どの範囲を集計対象にするか」を指定するのが フレーム句 です。「直近7日の移動平均」のように有限の窓を切りたいときに使います。
フレーム句で使うキーワードは次の通りです。
| キーワード | 意味 |
|---|---|
ROWS |
範囲を「行数」で指定する |
RANGE |
範囲を「列の値の範囲」で指定する(基準列は ORDER BY で指定した列) |
n PRECEDING |
n行(またはn単位)だけ前 |
n FOLLOWING |
n行(またはn単位)だけ後 |
CURRENT ROW |
カレント行 |
UNBOUNDED PRECEDING |
パーティションの先頭まで |
UNBOUNDED FOLLOWING |
パーティションの末尾まで |
カレント行を含めて直近7行で平均を取るクエリです。
SELECT order_date,
amount,
AVG(amount) OVER (
ORDER BY order_date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS moving_avg_7rows
FROM Orders;
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW は「カレント行を含めて直前の7行」を意味し、カレント行が進むにつれてフレームもスライドします。
各時点でフレーム内の amount を平均した値が moving_avg_7rows 列に入ります。
ROWS と RANGE の違いは次の通りです。
| 種別 | 数え方 | 向いている場面 |
|---|---|---|
ROWS |
物理的な並びでn行 | 歯抜けや同日複数行を無視してよい場面 |
RANGE |
ORDER BY 列の値の差 |
歯抜けや同日複数行を値ベースで扱いたい場面 |
RANGE を日付差で指定する場合の構文例は次のとおりです。
AVG(amount) OVER (
ORDER BY order_date
RANGE BETWEEN INTERVAL '6' DAY PRECEDING AND CURRENT ROW
)
RANGE BETWEEN INTERVAL ... はPostgreSQLやOracleで動作する標準SQL構文です。
MySQLは数値オフセット中心の実装になっており差があるため、移行時は方言を確認することになります。
第4章 行を持ってくる専用関数
SUM / AVG / COUNT / MAX は集約関数のウィンドウ版でした。一方、ウィンドウ関数固有の関数群もあります。代表的なのは次の2系統です。
| 関数の系統 | 役割 |
|---|---|
ランキング関数(ROW_NUMBER / RANK / DENSE_RANK) |
順序に沿って行に順位を付ける |
LAG / LEAD
|
カレント行から相対的にずれた行の値を持ってくる |
これらも第3章で押さえた3つの問いの枠組みで読み解けます。
4-1 ランキング関数(ROW_NUMBER / RANK / DENSE_RANK)
カテゴリ内で売上順位を出すのに使うのが ランキング関数 です。
SQL標準では ROW_NUMBER / RANK / DENSE_RANK の3種類があります。
違いはタイ(同順位)の扱いだけです。
SELECT category,
order_id,
amount,
ROW_NUMBER() OVER (PARTITION BY category ORDER BY amount DESC) AS rn,
RANK() OVER (PARTITION BY category ORDER BY amount DESC) AS rk,
DENSE_RANK() OVER (PARTITION BY category ORDER BY amount DESC) AS dk
FROM Orders;
| category | order_id | amount | ROW_NUMBER | RANK | DENSE_RANK |
|---|---|---|---|---|---|
| apparel | 4 | 4000 | 1 | 1 | 1 |
| apparel | 3 | 3500 | 2 | 2 | 2 |
| apparel | 6 | 2800 | 3 | 3 | 3 |
| books | 2 | 2000 | 1 | 1 | 1 |
| books | 5 | 2000 | 2 | 1 | 1 |
| books | 1 | 1500 | 3 | 3 | 2 |
books の上位2行(2000円)のタイで、3関数の違いがそのまま現れています。
| 関数 | タイの扱い | 向いている用途 |
|---|---|---|
RANK |
同順位+次は飛ぶ(1,1,3) | 上位N位を同点込みで取りたい |
DENSE_RANK |
同順位+次は飛ばない(1,1,2) | 上位N段階で絞りたい |
ROW_NUMBER |
一意な番号を強制(1,2,3) | タイ無視でちょうどN件並べたい(ページネーション等) |
ROW_NUMBER のタイ部分での並び順は実装依存です。
固定したいときは ORDER BY amount DESC, order_id のようにタイブレーカ列を加えます。
3つの問いに当てはめると PARTITION BY が「どの集合」、ORDER BY が「どの順序」に対応します(フレーム句は取れません)。
4-2 LAG / LEAD
「昨日の売上と今日の売上の差を出したい」のような前後比較にはフレーム句よりも意図が伝わる専用関数があります。
それが LAG(前の行の値を取ってくる)と LEAD(後ろの行の値を取ってくる)です。
SELECT order_date,
amount,
LAG(amount, 1) OVER (ORDER BY order_date) AS prev_amount,
amount - LAG(amount, 1) OVER (ORDER BY order_date) AS diff
FROM Orders;
LAG(amount, 1) は「カレント行から1行前の amount」を意味します。第2引数を省略すると1行前として扱われます。出力は次の通りです。
| order_date | amount | prev_amount | diff |
|---|---|---|---|
| 2025-04-01 | 1500 | NULL | NULL |
| 2025-04-02 | 2000 | 1500 | 500 |
| 2025-04-02 | 3500 | 2000 | 1500 |
| 2025-04-03 | 4000 | 3500 | 500 |
| 2025-04-04 | 1800 | 4000 | -2200 |
| 2025-04-05 | 2800 | 1800 | 1000 |
最初の行は「1行前」が存在しないので NULL になります。
LEAD は逆向きで「1行後ろの値」を取る関数です。
amount - LAG(amount, 1) OVER (...) のように、同じ行に並べて差分を出せるのが本領です。
3つの問いに当てはめると、LAG / LEAD の本質は「ある順序の中で、自分から相対的にずれた行の値を持ってくる」ことだと整理できます。
-
どの順序で?:
ORDER BYが主役。前後の比較は順序があって初めて意味を持つ -
どの集合に対して?:
PARTITION BY user_id ORDER BY order_dateなら同一ユーザー内で1行前を見る、というように使う -
どの範囲で?: フレーム句は使わない(
LAG/LEADは単一の行を指すため)
第5章 「行を残す」性質が意味すること
ウィンドウ関数の出力では、個々の行の値 と その行が属する集合の集計値 が同じ行に並びます。たとえば amount = 1500(要素レベル)と category_total = 5300(集合レベル)が同じ行にある状態です。
| 階層 | 例 |
|---|---|
| 要素レベル | amount = 1500 |
| 集合レベル | category_total = 5300 |
GROUP BY は集合レベルだけを残して要素レベルを捨てます。生のテーブルは逆に要素レベルしか持ちません。ウィンドウ関数は両方を同じ行に同居させるので、要素と集合の間で比較や演算が直接できます。
かつては行間比較を相関サブクエリで書くしかなく、コードが複雑でパフォーマンスも悪くなりがちでした。その役割を「行を畳まずに集約する」1つの設計原理で吸収したのがウィンドウ関数です。
おわりに
ウィンドウ関数は「行を畳まず、各行に集計値を横付けする」装置です。OVER 句の中身は3つの問いに分解できました。
-
どの集合に対して? →
PARTITION BY -
どの順序で? →
OVER句内のORDER BY -
どの範囲で? → フレーム句(
ROWS/RANGE)
この枠組みが頭に入ると、累計・移動平均・前行との差分・カテゴリ内ランキングが全部同じ図式で書けます。本記事で扱わなかった NTILE・PERCENT_RANK・CUME_DIST のような関数も、3つの問いに当てはめれば自然に読めるはずです。
自分も最初は OVER 句の中身がまったく読めず、書けるクエリも限られていました。3つの問いに分解できるようになってから、幅が一気に広がった実感があります。