はじめに
機能を実装してテストを書こうとしたとき、こんな迷いに引っかかることはないでしょうか。
- このロジックの確認、ユニットテストでいいのか
- DBまで巻き込んで統合テストを書くべきか
- ユーザー操作越しのE2Eまで必要か
自分も最初は、ここでよく止まっていました。
「ユニットテスト」「結合テスト」「E2Eテスト」という言葉は知っていても、
それぞれが何のための装置で、どこに限界があるのかを正面から整理した記憶がない。
なので「とりあえず全部ユニットで書く」「念のためE2Eで広く取る」のような、
勘でテストレベルを選ぶ状態になりがちでした。
この記事では、4つのテストレベル(ユニット/統合/システム/受入)を「種類のカタログ」ではなく「目的と限界の地図」として整理します。
最後には、目の前のテストをどのレベルに置くかの判断軸も持ち帰れる構成にしています。
TL;DR
- テストレベルは「種類のカタログ」ではなく「目的と限界の地図」。
守備範囲と限界がレベルごとに違う - 1つのレベルだけで全部はカバーできない。
捕まえたい「壊れ方」ごとに必要な粒度が変わる - ピラミッド型は機械的な比率ルールではなく「速度と信頼性のための混合比」として読み解く
1. 開発の流れの中でのテスト
そもそもテストはいつ走らせるものなのか。
「全部最後にまとめてテスト」では遅すぎる、
という直感は多くの人が持っているはずです。
このセクションでは次の流れで整理します。
- 開発の段階の中で、テストがどこに位置していたか
- 現代では、その位置がどう変わっていったか
ここを押さえると、レベル分けの動機が自然に立ち上がってきます。
1.1 開発の段階とテストの位置
ソフトウェアを作る流れは、ざっくり次のような段階で進みます。
これを SDLC(Software Development Life Cycle、ソフトウェア開発の一連の流れ)と呼びます。
- 要件定義(何を作るか決める)
- 設計(どう作るか決める)
- 実装(コードを書く)
- テスト(壊れていないか確かめる)
- 保守(直し続ける)
古典的なイメージでは、テストは「最後にまとめて行う工程」でした。実装が一通り終わってから、品質保証チームに引き渡してテストが始まる、という形です。
ただ、現代のWebやモバイル開発では、このイメージはほぼ合わなくなっています。
1日に何度もリリースする世界では、最後にまとめてテストではフィードバックが間に合いません。
バグが見つかった頃には、すでに次の機能が積み上がっていて、原因がどこにあるかも追いにくい状態になります。
1.2 シフトレフト —— テストを開発に織り込む
そこで登場するのが シフトレフト(shift-left)という考え方です。
テストを「最後の工程」に置くのではなく、
開発の早い段階から並行して走らせる発想を指します。
SDLCの図で言うと、右端に固まっていたテストを、
左側(要件・設計・実装の段階)に少しずつずらしていくイメージです。
シフトレフトを徹底すると、
テストは「タイミングと粒度が違う複数の活動」に分かれます。
- 実装と同時に書く軽くて速いテスト
- 複数のモジュールが揃ってから走らせる中規模のテスト
- リリース直前にユーザー視点で全体を確認するテスト
それぞれが違う目的で、違うタイミングで走る。
これが「テストレベルを分ける」発想の入り口になります。
開発のどの段階でも、何かしらの「壊れていないか確かめる活動」が走っている状態を目指す。これがシフトレフトのざっくりした絵姿です。
2. なぜレベルを分けるのか
シフトレフトの話で「タイミングと粒度が違う」とは触れました。
ただ、ここで一度立ち止まって考えたいことがあります。
なぜわざわざ「分ける」必要があるのか。
「全部E2Eで書けばいい」ではダメなのか、という疑問です。
このセクションでは、2つの角度から「分ける動機」を見ていきます。
- 速度・安定性・原因特定の観点で「全部E2E」が苦しい
- 捕まえたい「壊れ方」がそもそも違う
2.1 「全部E2Eで書く」の何がダメか
E2Eテストは、ユーザー操作と同じレベルで、ブラウザやアプリ越しに本番に近い構成で動かすテストです。
これだけで全部のテストを賄おうとすると、いくつか厳しい現実にぶつかります。
- 遅い: 1テストに数十秒〜数分かかる。何百本も走らせると、開発のフィードバックが死ぬ
- 不安定: ネットワーク・タイミング・外部サービスの状態に依存して、同じテストでも結果がブレる
- 失敗時の原因がわからない: 画面にエラーが出たとき、その原因がUI、API、DB、ロジックのどこにあるか、特定に時間がかかる
ここで大事なのは、E2Eが悪いわけではないという点です。
E2Eにはあとで見るように、E2Eにしか捕まえられない壊れ方があります。
問題は「全部をE2Eだけで書く」やり方が、速度・安定性・原因特定の3つの面で厳しい、ということです。
これがレベルを分ける根本的な動機になります。
2.2 開発段階ごとに違う「壊れ方」を捕まえる
もう一つの動機は、捕まえたい「壊れ方」がそもそも違うという点です。
- 関数1つの中のロジックが間違っている、という壊れ方
- 複数のモジュール/サービスを繋いだら噛み合わない、という壊れ方
- システム全体としては動くけれど、ユーザーの期待と違う、という壊れ方
同じ「テスト」と呼ばれていても、捕まえたい壊れ方が違えば、必要な粒度が変わります。
関数1つの壊れ方を捕まえるのに、毎回ブラウザを起動するのは過剰です。
逆に、システム全体の挙動の壊れ方を、関数単体のテストで捕まえるのは無理があります。
だからレベルを分ける。ここまでくると、4つのレベルがそれぞれ別の役割を持っている理由が見えてきます。
3. 4つのレベルを地図として歩く
ここから本論です。
4つのレベル(ユニット/統合/システム/受入)を1つずつ眺めていきます。
それぞれを「目的(何の壊れ方を捕まえる装置か)」と「限界(このレベルでは見つからない壊れ方)」のセットで整理します。
3.1 ユニットテスト
目的(守備範囲)
ユニットテストは、関数・メソッド・クラス単位のロジックを検証するテストです。
たとえば「税込み金額を計算する関数」「入力をバリデーションする関数」のような、外部とのやり取りを最小化した小さい単位を対象にします。
def calc_total_with_tax(price: int, tax_rate: float) -> int:
"""税込み金額を計算する(端数は切り捨て)"""
if price < 0:
raise ValueError("price must be >= 0")
return int(price * (1 + tax_rate))
def test_calc_total_with_tax_basic():
assert calc_total_with_tax(1000, 0.10) == 1100
def test_calc_total_with_tax_truncates_fraction():
# 1234 * 1.10 = 1357.4 → 切り捨てで 1357
assert calc_total_with_tax(1234, 0.10) == 1357
def test_calc_total_with_tax_rejects_negative_price():
import pytest
with pytest.raises(ValueError):
calc_total_with_tax(-1, 0.10)
特徴
- 速い(ミリ秒単位で完了する)
- 安定している(外部依存がほぼない)
- 失敗時の原因が局所化される(落ちたテストの周辺コードを見ればよい)
- 書きやすく、実装と同時にどんどん追加していける
限界
ユニットテストでは捕まらない壊れ方は、大きく2種類あります。
- ユニット同士の繋ぎ目の不整合: 関数Aは「文字列で日付を返す」、関数Bは「Date型で受け取る」つもりで作っていたら、両方のユニットテストは緑でも、繋いだ瞬間に動かない
- 本物のインフラに触ったときの問題: SQLの構文エラー、タイムアウト、文字コードの取り違えなど、DBや外部APIとの本物のやり取りでしか出ない問題
本物に触らない代わりに、本物特有の問題は別レベルに任せる。
これがユニットテストの割り切りです。
3.2 統合(インテグレーション)テスト
目的(守備範囲)
統合テストは、複数のコンポーネントを実際に繋いで、その繋ぎ目(インターフェース、契約)が正しく動くかを検証するテストです。
サービスとDB、APIとそのクライアント、複数のサービス間の連携などが対象になります。
ユニットテストが「箱の中身」を見るのに対して、統合テストは「箱と箱の繋ぎ目」を見る、と言うとイメージしやすいかもしれません。
| 観点 | ユニットテスト | 統合テスト |
|---|---|---|
| 検証する場所 | 箱の中身 | 箱と箱の繋ぎ目 |
| 対象の例 | 関数A単体 | サービスA ↔ DB |
| 何を見るか | 計算・分岐などのロジック | SQL・契約・データ形式 |
特徴
- ユニットより遅く、ユニットより本番に近い
- ユニット単体では見つからない「噛み合わない壊れ方」を捕まえる装置
- 本物のDBや本物のメッセージブローカーを使うことで、設定や接続周りの問題も見つけやすい
限界
統合テストの限界は、大きく次の2つに整理できます。
- 全体通しの挙動はカバーできない: 注目している「繋ぎ目」のあたりは厚く検証できるが、フロントエンドからバックエンド、DB、外部サービスまでを通したシステム全体の挙動は見えない。フォームの入力値が最終的にDBの正しい行に入るかを一気通貫で見たいなら、もう一段上のレベルが必要
- 書きやすいが、安定して動かし続けるのが難しい: 本物のDBを起動する時間、テスト間でデータが汚染されないようにする工夫など、雑に書くとすぐ「時々落ちる信頼できないテスト」に転落する
3.3 システム/E2Eテスト
目的(守備範囲)
システムテスト、またはE2E(エンドツーエンド:端から端まで)テストは、システム全体を本物に近い構成で動かすテストです。
ユーザー操作(または外部APIの呼び出し)から全体が期待通り動くかを検証します。
システムテストとE2Eの厳密な違い
厳密には、両者は別の概念です。
- システムテスト: 統合された全体が要求を満たすかを問う「テストレベル」
- E2E: 端から端まで通す「スコープ」
ただし実務、特にWeb開発の現場では両者がほぼ重なって扱われることが多いので、本記事ではまとめて扱います。
具体的なイメージは、「ログインしてカートに商品を入れて決済まで通せる」のような業務シナリオです。
こうしたシナリオを、ブラウザ越しに自動操作して確認するテストになります。
特徴
- 一番本番に近い構成で動く
- 一番遅い(1シナリオで数十秒〜数分かかることもある)
- 一番不安定(ネットワーク、タイミング、外部サービスの影響を受ける)
- 設定の問題、本番特有の構成ミスなど、下のレベルでは出ない壊れ方を捕まえる
限界・使うときの心得
E2Eを使うときの心得は、次の2点に集約できます。
- 失敗時の原因切り分けに時間がかかる: 最近のE2Eフレームワークはトレース機能やスクリーンショット保存で支援してくれるが、それでもユニットや統合に比べると一手間多い
- 数を増やすとフィードバックが死ぬ: だから少数の重要シナリオに絞るのが基本姿勢
「ログイン→主要な業務フロー→ログアウト」のような、業務として外せない動線だけをE2Eに残し、細かい入力バリデーションや分岐は下のレベルに渡す。
この棲み分けが効きます。
E2Eシナリオを書くときの落とし穴
-
タイムアウトに頼って待つ:
sleep(3)のような決め打ち待機は不安定さの源。要素が表示されるまで待つ・APIが返るまで待つ、のように条件で待つ - 前のテストの状態に依存する: 「テストAでユーザーを作る → テストBでそのユーザーでログイン」のような順序依存は、テスト並列化や単体実行で必ず壊れる。各シナリオは独立して動くようにする
- 重要度の低いシナリオまでE2Eで書こうとする: 入力1文字ごとのバリデーション、ヘルプ画面の表示、のような細部はE2Eに置かない。下のレベルで足りる
3.4 受入テスト
目的(守備範囲)
受入テストは、システムが「ユーザー(顧客)の期待」を満たしているかを確認するテストです。
技術的な「動く/動かない」ではなく、業務要件としてOKかが観点になります。
ここで、システムテストとの違いに混乱しやすい場面があります。観点を分けると整理しやすくなります。
- システムテスト: 仕様通りに動くか(作る側 の視点)
- 受入テスト: 使う側にとって望ましいか(使う側 の視点)
仕様書通りに動くシステムでも、業務で使ってみたら「ボタンの位置が業務フローに合わない」「想定していた帳票項目が抜けている」といった指摘が出ることがあります。
これらは仕様としては満たされているけれど、業務としては受け入れられない、という状態です。
受入テストはここを掬い取る装置です。
特徴
受入テストには、自動化されるパターンと手動のパターンの両方があります。
- 自動化された受入テスト: 業務シナリオを自然言語に近い形で書き起こし、それをそのまま自動実行する仕組み
- 手動の受入テスト: 実ユーザーや業務担当者による検収。リリース判定の最終ゲートとして使われることが多い
限界
自動化しても、受入テストの守備範囲は限定的です。
業務として使えるかの最終判断は、どうしても人の感覚や定性的評価に依存する部分が残ります。
逆に、細かいロジックの欠陥(境界値の取り違えなど)は受入テストでは見つけられません。
それは下のレベル(ユニット・統合)の責務です。
ここで、4つのレベルを横並びで眺めると、それぞれの位置づけが見えやすくなります。
| レベル | 目的(捕まえる壊れ方) | 速度 | 安定性 | 本番との近さ | 典型的な担当 |
|---|---|---|---|---|---|
| ユニット | 関数・クラス単体のロジック | 速い | 高い | 遠い | 開発者 |
| 統合 | 複数コンポーネントの繋ぎ目 | 中 | 中 | 中 | 開発者 |
| システム/E2E | システム全体のユーザー動線 | 遅い | 低い | 近い | 開発者・QA |
| 受入 | 業務要件としての妥当性 | 場合による | 場合による | 近い | 業務担当・QA |
「速度と安定性は下に行くほど高く、本番との近さは上に行くほど高い」という構造が見えてきます。これが、次に出てくるピラミッドの形に直結します。
4. ピラミッドという混合比
4つのレベルを別々に見てきました。
現場では「全部書く」のではなく「比率を考えて混ぜる」必要が出てきます。
その指針として広く知られているのが、テストピラミッドです。
このセクションでは次の3つを順に見ていきます。
- ピラミッドの形(どんな比率で混ぜるか)
- なぜその形が合理的になるのか
- 形が崩れるとどんな状態になるのか
4.1 ピラミッドの形
ピラミッドは、業界の経験則として広く知られている図です。下から順に、ユニットが大量、統合が中くらい、システム/E2Eが少数、という3層構造で描かれます。
よく引かれる比率として「ユニット 70% / 統合 20% / E2E 10%」や「80% / 15% / 5%」のような数字があります。
ただ、この比率は出典によってばらつきがあり、厳密に守ること自体にはあまり意味がありません。
チームによってサービスの性質も違うし、何を「1テスト」と数えるかの基準も違います。
大事なのは数字ではなく、
「速いテストを土台に、遅いテストを少数載せる」という形そのもの です。
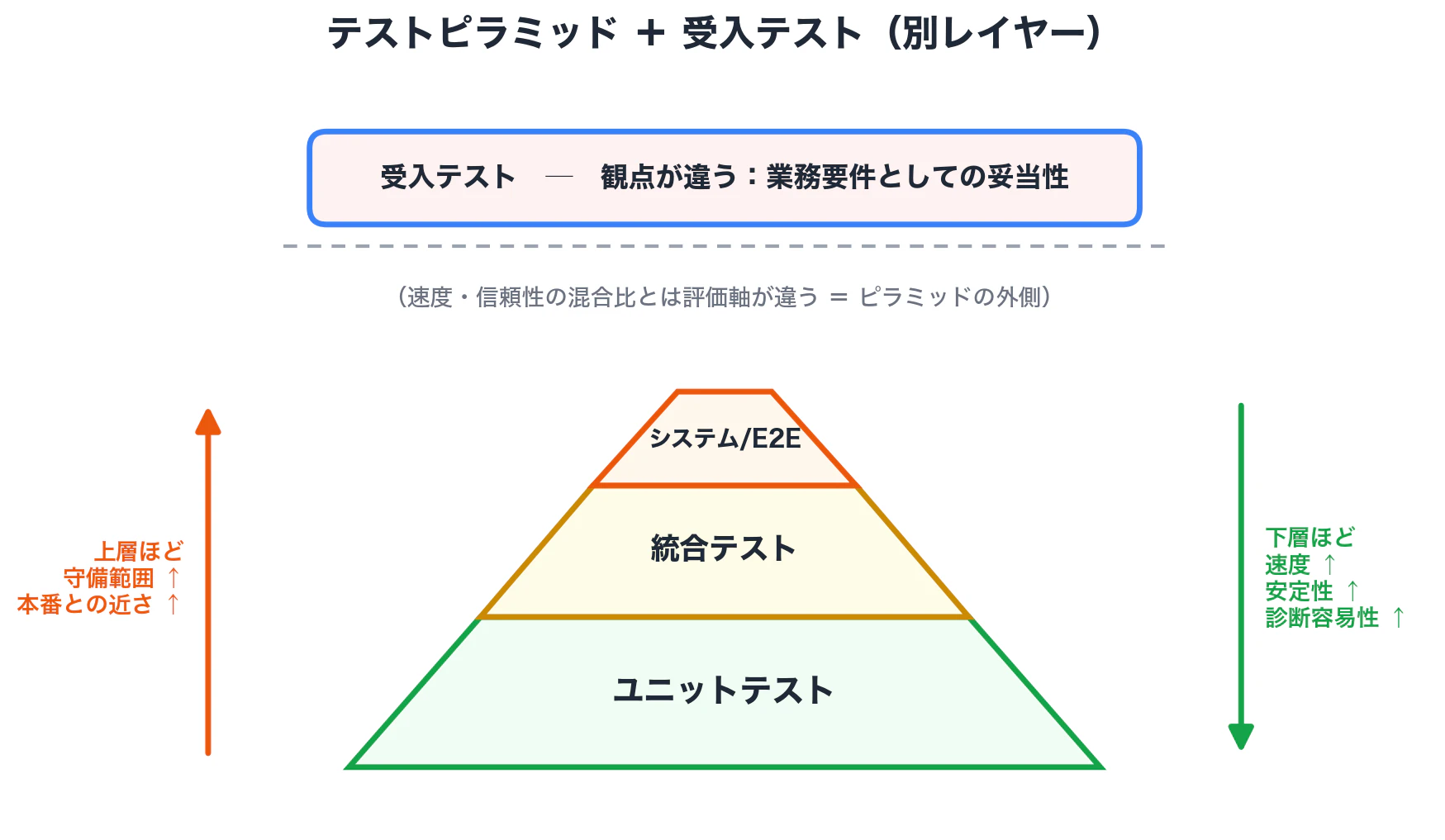
ここで一つ、よく混乱する点に触れておきます。
受入テストは、この3層ピラミッドの中に収まりません。
理由は観点の違いです。
ピラミッドは速度・信頼性・守備範囲の混合比を語る図ですが、受入テストは「業務要件としてOKか」を問うテストで、評価軸そのものが違います。
なので、ピラミッドの内側に積み上げるよりも、ピラミッドの上に被さる別レイヤーとして捉えるほうが整合します。
自動化された受入シナリオがE2Eと重なる場合もありますが、目的=「使う側との合意」が違う、と理解しておくとブレにくくなります。
4.2 なぜこの形になるのか
ピラミッド型が合理的になるのは、3つの観点を同時に満たすからです。
- 速度と安定性の観点: 下層ほど速くて安定、上層ほど遅くて不安定。下が厚いほうが、テストスイート全体の回転が速くなる
- 守備範囲の観点: 下層ほど局所、上層ほど広範。広範なテストは少なくても全体を通せる
- 失敗時の診断容易性: 下層ほど原因が特定しやすい。原因特定に時間がかかるテストは、数を抑えたほうが現場の負担が減る
この3つが揃うと、自然に「下が厚く、上が薄く」という形に落ち着きます。
「速いテストを大量に、遅いテストを少数」という指針は、こうやって裏側から眺めると納得感が出ます。
4.3 ピラミッドの逆パターン
ピラミッドの形が崩れている状態には、典型的なパターンが2つあります。どちらも、テストスイートの健全性を示すサインとして読み解けます。
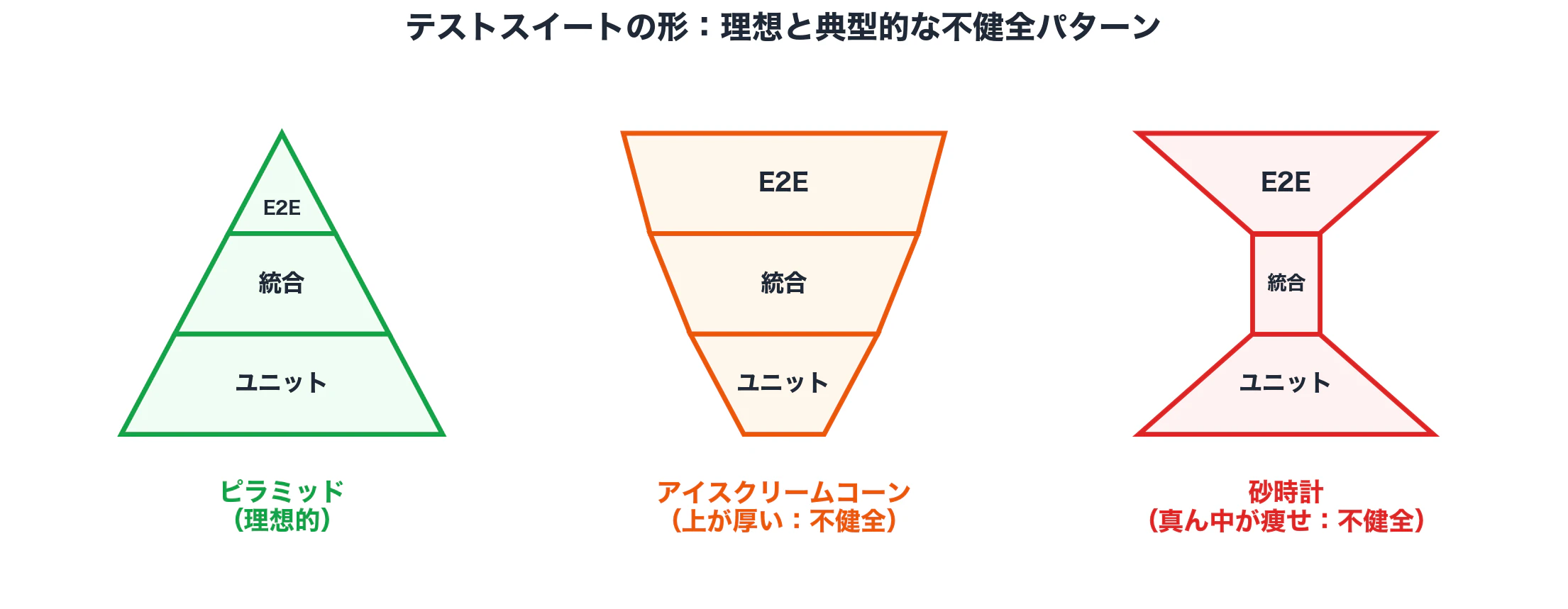
- アイスクリームコーン: 上が厚く、下が薄い形。E2Eばかり書いてユニットが薄い状態。テストスイート全体が遅く、不安定で、原因特定に時間がかかる。プロトタイプから本番に駆け上がる過程でテスト負債を放置すると、この形になりがちです
- 砂時計: 下と上は厚いが、真ん中(統合)が痩せている形。コンポーネント間の繋ぎ目で起きる壊れ方を、E2Eで間接的に捕まえる構造になってしまう。失敗の原因切り分けに時間がかかり、E2Eが連鎖的に落ちる事故が起きやすい
逆に言うと、ピラミッドの形そのものが、テストスイートが健全に育っているかを映す鏡になっている、と捉えることもできます。
5. 目の前のテストをどう置くか
地図を持ったところで、最後に「自分がいま書こうとしているテスト」をどのレベルに置くかの判断軸を整理します。次の3つを順に問うと、迷いがかなり減ります。
-
このテストで捕まえたい壊れ方は何か
- 関数のロジック → ユニット
- コンポーネント間の繋ぎ目 → 統合
- ユーザー操作越しの全体挙動 → システム/E2E
- 業務要件の妥当性 → 受入
-
どこまで本物を使う必要があるか
- 必要最小限で済む形を選ぶ
- 「念のため本物のDBを使う」は遅さと不安定さの源になりやすい
- 本物が必要な理由が言語化できないなら、もっと下のレベルで足りるはず
-
このテストはどれくらい頻繁に走るか
- 開発中に何度も回したい → 下のレベル(速くて安定なほうがいい)
- リリース前に少数回せばいい → 上のレベル(遅くてもいい代わりに本番に近い)
この3つを意識すると、「とりあえずユニットで」「念のためE2Eで」のような勘任せの判断が、目的ベースの判断に変わっていきます。
おわりに
レベル分けは、テストの「種類のカタログ」ではなく「目的と限界の地図」でした。
各レベルが何の壊れ方を捕まえる装置で、どこに限界があるか。
それを理解すると、ピラミッドの形が単なるルールではなく、速度と信頼性の混合比として読めるようになります。
そして、目の前のテストをどこに置くかを意識的に選べるようになると、テストスイート全体の回転速度と信頼性が変わっていきます。
単にテストを「書く」のではなく、「どこに書くか」を選ぶ。
この一手間が、品質を高速に届ける土台になっていきます。