はじめに
データサイエンス部のRyuです!
いきなりですが、みなさんはPytorchで機械学習してますか?
私は大学院の2年生あたりからTrainerというとても便利なHuggingFaceのクラスを利用しているのですが、社内でも意外と知られていなかったりするので、この機会に紹介しようと思います!
Trainerとは
HuggingFaceが提供するPytorchの学習部分を簡単に実装できるようにしたクラスです。
Lossの計算や推論用モデルの決定、推論などをサポートしていて、簡単にニューラルネットワークを使った実装ができるようになっています。
Trainerのここがすごい!
それではTrainerのここがすごいポイントを紹介していきます!
Pytorchだけで書くよりも記述量が大幅に減る!
Trainerを利用することの最大の利点とも言えるのが記述量の削減です。
以下にPytorchとHuggingFaceのTrainerを利用した際の学習コードを記載します。(長くなるので推論部分は記載しません)
全く同じ出力にはなりませんが、このくらい記述量が減らせるんだと感じて貰えれば嬉しいです!
Pytorchのみ
ソースコード(長いので割愛)
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn import datasets
from sklearn.model_selection import train_test_split
from torch.nn import functional as F
from torch.utils.data import DataLoader, Dataset
class Classifier(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(4, 100)
self.fc2 = nn.Linear(100, 50)
self.fc3 = nn.Linear(50, 3)
def forward(self, batch):
out = self.fc1(batch)
out = F.relu(out)
out = self.fc2(out)
out = F.relu(out)
out = self.fc3(out)
return out
class IrisDataset(Dataset):
def __init__(self):
# Iris データセットを読み込む
x, y = datasets.load_iris(return_X_y=True)
self.data = [
{
'features': torch.tensor(xx, dtype=torch.float32),
'labels': torch.tensor(yy, dtype=torch.long)
} for xx, yy in zip(x, y)
]
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def evaluate(model, dataloader, device, loss_fn):
model.eval()
total_loss = 0.0
with torch.no_grad():
for inputs, labels in dataloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = loss_fn(outputs, labels)
total_loss += loss.item()
return total_loss / len(dataloader)
def main():
# Iris データセットを読み込む
x, y = datasets.load_iris(return_X_y=True)
x = torch.tensor(x, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
dataset = torch.utils.data.TensorDataset(x, y)
train_x, valid_test_x, train_y, valid_test_y = train_test_split(x, y, test_size=0.2)
valid_x, test_x, valid_y, test_y = train_test_split(valid_test_x, valid_test_y, test_size=0.5)
# DataLoader で読み込むバッチサイズ
batch_size = 64
train_dataloader =DataLoader(dataset, batch_size=batch_size, shuffle=True)
valid_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
test_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
# モデルの呼び出し
model = Classifier()
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 最大エポック数
max_epoch = 100
early_stopping_patience = 10
early_stopping_patience_count = 0
# エポックを回す
for epoch in range(max_epoch):
model.train()
total_loss = 0.0
for batch_idx, (inputs, labels) in enumerate(train_dataloader):
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch [{epoch + 1}/{max_epoch}], Train Loss: {total_loss / len(train_dataloader)}")
print(f"Epoch [{epoch + 1}/{max_epoch}], Validation Loss: {valid_loss}")
# Lossの更新
if valid_loss < best_vbalid_loss:
best_vbalid_loss = valid_loss
early_stopping_patience_counte = 0
else:
early_stopping_patience_counte += 1
# Early Stoppingの判定
if early_stopping_patience_counte >= early_stopping_patience:
break
if __name__ == "__main__":
main()
Trainerを利用
ソースコード(長いので割愛)
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn import datasets
from sklearn.model_selection import train_test_split
from torch.nn import functional as F
from torch.utils.data import DataLoader, Dataset
from transformers import TrainingArguments
from transformers import Trainer
from transformers import EarlyStoppingCallback
from transformers.modeling_outputs import ModelOutput
class Classifier(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(4, 100)
self.fc2 = nn.Linear(100, 50)
self.fc3 = nn.Linear(50, 3)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, features, labels):
out = self.fc1(features)
out = F.relu(out)
out = self.fc2(out)
out = F.relu(out)
out = self.fc3(out)
loss = self.loss_fn(out, labels)
return ModelOutput(loss=loss, logits=out)
class IrisDataset(Dataset):
def __init__(self):
# Iris データセットを読み込む
x, y = datasets.load_iris(return_X_y=True)
self.data = [
{
'features': torch.tensor(xx, dtype=torch.float32),
'labels': torch.tensor(yy, dtype=torch.long)
} for xx, yy in zip(x, y)
]
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def main():
# Iris データセットを読み込む
dataset = IrisDataset()
train_dataset, valid_test_dataset = train_test_split(dataset, test_size=0.2)
valid_dataset, test_dataset = train_test_split(valid_test_dataset, test_size=0.5)
# バッチサイズ
batch_size = 64
# 学習時の設定を作成
training_args = TrainingArguments(
output_dir='./output/model',
eval_strategy='epoch',
logging_strategy='epoch',
save_strategy='epoch',
save_total_limit=1,
metric_for_best_model='loss',
load_best_model_at_end=True,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=100,
report_to='tensorboard',
)
# モデル
model = Classifier()
# Trainerインスタンスを作成
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)],
optimizers=(optim.Adam(model.parameters(), lr=1e-3), None),
)
# モデルを学習する
trainer.train()
if __name__ == "__main__":
main()
自作関数でカスタマイズ可能!
様々な機能がデフォルトで備わっているTrainerですが、Contrastive Learning(対照学習)やRank Learning(ランク学習)などでは少し複雑なLossを使いたい場合もあると思います。
そういった場合に自作関数を引数にとれるのもTrainerの良さの一つです。
例えば以下のように自動評価を行う関数を作成し、Trainerに渡してやることで、検証データセットやテストデータセットに対して個別の推論関数を作成せずに評価を行うことができます。
from transformers import EvalPrediction
from sklearn.metrics import precision_score, recall_score, f1_score
def compute_metrics(res: EvalPrediction):
preds = res.predictions.argmax(axis=1)
targets = res.label_ids
precision = precision_score(target, pred, average='macro')
recall = recall_score(target, pred, average='macro')
f1 = f1_score(target, pred, average='macro')
return {
'precision': precision,
'recall': recall,
'f1': f1
}
ちなみにEvalPredictionは推論結果やLossを持っており、上記以外にも様々な評価方法が実現できます。
具体的にEvalPredictionがどのような値を持っているかは以下に載っていまいます。
実験をサポートする機能が備わっている!
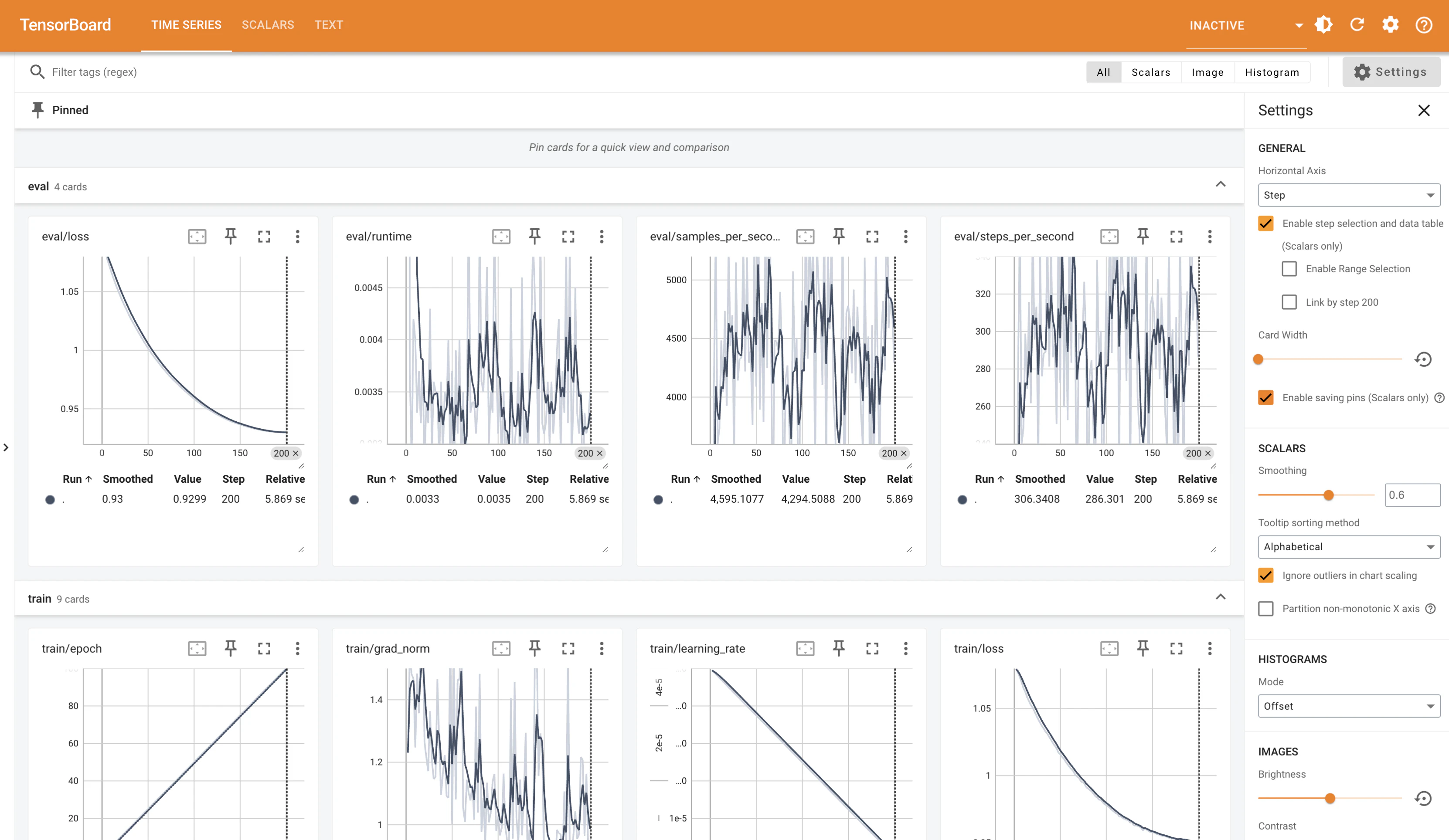
Tensorboardに簡単に出力できる
Trainerでは引数にtensorboardを指定するだけで自動でTensorboardに出力してくれます。
デフォルトでLossや学習率、学習/推論時間の推移などを出力してくれるため、見たい指標がここにあれば自分でTensorboardに載せる情報を取捨選択せずに済みますね。
シーケンスバーがデフォルトでついている
なんとTrainerはデフォルトでシーケンスバーがあるので、for文にtqdmを利用してシーケンスバーを出すという一手間を省くことができます。
機械学習の実験でシーケンスバーがないと夜も眠れないと思うので、素晴らしい機能ですね!!
$ poetry run python3 trainer_main.py
{'loss': 1.0796, 'grad_norm': 1.2308217287063599, 'learning_rate': 4.9500000000000004e-05, 'epoch': 1.0}
{'eval_loss': 1.087805986404419, 'eval_runtime': 0.0353, 'eval_samples_per_second': 425.507, 'eval_steps_per_second': 28.367, 'epoch': 1.0}
...
{'loss': 0.9508, 'grad_norm': 0.9162365198135376, 'learning_rate': 0.0, 'epoch': 100.0}
{'eval_loss': 0.9299165606498718, 'eval_runtime': 0.0035, 'eval_samples_per_second': 4294.509, 'eval_steps_per_second': 286.301, 'epoch': 100.0}
{'train_runtime': 6.2894, 'train_samples_per_second': 1907.974, 'train_steps_per_second': 31.8, 'train_loss': 0.9895061445236206, 'epoch': 100.0}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:06<00:00, 31.80it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1510.37it/s]
Trainerで学習してみる
それではコードの各部分について解説していこうと思います。
データセットの作成
今回はコードをなるべく簡単にするため有名なIrisデータセットを利用しています。
まずはdatasets.load_iris(return_X_y=True)でデータセットを読み込み、説明変数をxに、ラベルをyに格納します。
Trainerではデータセットを読み込む際、各特徴量に名前を付ける必要があるので、説明変数をまとめてfeatures、ラベルをlabelsという名前にして辞書を作成します。
ラベルに関してはlabelという名前を含んでいれば勝手にラベルとして認識してくれるので、labelでもcategory_labelでも大丈夫です。
完全にオリジナルの名前をつけたい場合は、後ほど紹介するTrainArgumentsのlabel_namesに好きな名前をつけると例えばcategory_idなど自由につけることができます。
class IrisDataset(Dataset):
def __init__(self):
# Iris データセットを読み込む
x, y = datasets.load_iris(return_X_y=True)
self.data = [
{
'features': torch.tensor(xx, dtype=torch.float32),
'labels': torch.tensor(yy, dtype=torch.long)
} for xx, yy in zip(x, y)
]
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
モデルの定義
続いてはモデルの定義です。
Pytorchでモデルを作る際は学習関数側でLossを計算する方法もありますが、Trainerではモデルクラスの中でLossを計算する必要があります。
今回は適当に3層の線形分類モデルを作ってみました。
注意点として、forward()が受け取る変数名はデータセット作成時につけた特徴量の名前にする必要があります。
そのため、モデルへの入力としてfeatures、Lossの計算用にlabelsを受け取るようにしています。
そして、Lossを計算しModelOutputでラップして返すようにしています。
class Classifier(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(4, 100)
self.fc2 = nn.Linear(100, 50)
self.fc3 = nn.Linear(50, 3)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, features, labels):
out = self.fc1(features)
out = F.relu(out)
out = self.fc2(out)
out = F.relu(out)
out = self.fc3(out)
loss = self.loss_fn(out, labels)
return ModelOutput(loss=loss, logits=out)
データセットの分割
上記で作成したIrisDatasetを呼び出し、学習、検証、評価データセットに分割します。
今回は学習、検証、テストデータセットにそれぞれ8:1:1で分割しています。
# Iris データセットを読み込む
dataset = IrisDataset()
train_dataset, valid_test_dataset = train_test_split(dataset, test_size=0.2)
valid_dataset, test_dataset = train_test_split(valid_test_dataset, test_size=0.5)
学習設定の作成
TrainArgumentsクラスを利用して学習に関する細かい設定が行えます。
今回はそこまで複雑な設定はしませんが、以下のように設定しています。
# バッチサイズ
batch_size = 64
# 学習時の設定を作成
training_args = TrainingArguments(
output_dir='./output/model',
eval_strategy='epoch',
logging_strategy='epoch',
save_strategy='epoch',
save_total_limit=1,
metric_for_best_model='loss',
load_best_model_at_end=True,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=100,
report_to='tensorboard',
)
これだけだと想像しづらいと思うので、各設定とその説明を表にまとめました。
| 設定 | 説明 |
|---|---|
| output_dir | 結果の出力先ディレクトリを指定します。Tensorboardに出力するオプションを利用した場合もこちらに出力されます。 |
| eval_strategy | エポックやステップなどどのような方法で評価を行うか決定します。今回はepochを指定しているのでエポックごとにLossが計算され、学習が行われます。 |
| logging_strateg | ログの出力方法を指定します。今回はepochを指定しているので、標準出力もTensorboardもepochごとに出力されます。 |
| save_strategy | モデルの保存方法を指定します。今回はepochを指定しているので、epochごとに最も良い性能となったモデルを保存します。 |
| save_total_limit | 保存する最大モデル数を指定します。例えば2を指定すると、2番目の性能を持つモデルまでを保存します。 |
| metric_for_best_model | 性能の良さをどのように定義するかを指定します。基本的にはlossを指定して損失を最小化します。例えばF1スコアなどを利用したい場合は自作で評価関数を作り、その返り値のキーをここで指定すると利用できます。 |
| load_best_model_at_end | 学習終了後にモデルのインスタンスに最高性能のモデルをロードしておくかを指定します。Trueにしてロードしておくとそのまま推論に使うことができます。 |
| per_device_train_batch_size | 学習時のバッチサイズを決定します。デバイス1つあたのバッチ数なので、複数のGPUを使う場合はGPU数で割ってあげる必要があります。 |
| per_device_eval_batch_size | 推論時のバッチサイズを決定します。デバイス1つあたのバッチ数なので、複数のGPUを使う場合はGPU数で割ってあげる必要があります。 |
| num_train_epochs | 最大のepoch数を指定します。 |
| report_to | ログの出力先を指定します。今回はTensorboardに出力するようにしています。 |
こちらの内容は以下の公式ドキュメントにもあるので、詳細はそちらをご覧ください。
公式ドキュメントにはここで紹介している何倍もオプションがあるので、ぜひご活用ください。
学習
学習部分についての解説です。
まずは作成したモデルを呼び出し、Trainerクラスに渡してあげます。
データセットもここで利用します。
ここでは学習、検証データセットを渡しているため、検証データセットのLossが最小となるモデルだけが保存されます。(TrainArgumentで〇〇を1に設定しているため)
そして、callbacksにEarlyStoppingCallback(early_stopping_patience=3)を設定することで、エポックで数えて3回以上Lossが下がらなくなった時点で学習を打ち切ります。
また、optimizersにAdamを指定しています。
そして最後にtrainer.train()を実行すると自動で学習が開始されます。
# モデル
model = Classifier()
# Trainerインスタンスを作成
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)],
optimizers=(optim.Adam(model.parameters(), lr=1e-3), None),
)
# モデルを学習する
trainer.train()
評価
Trainerクラスの機能を利用して評価を指せることもできますが、関数を自作してTrainerクラスにわたす必要があるので、今回はsklearnでF1スコアだけを使って評価を行います。
ただ、推論に関してもTrainerの利用でかなり小規模なコードにできるため、恩恵は大きいと思います。
trainer.predict(test_dataset)でテストデータセットに対して推論を行います。
そしてテストデータセットからラベルを取りだり、F1スコアを計算します。
# テストデータでF1スコアを求める
predictions = trainer.predict(test_dataset).predictions.argmax(axis=1)
gold_labels = [data['labels'].item() for data in test_dataset]
f1 = f1_score(gold_labels, predictions, average="macro")
print(f"F1 score: {f1}")
おわりに
ここまで読んでいただきありがとうございます!
Trainerを使うことでここまでコードを削減でき、工数削減やバグ発生率の低下が見込めるのではないでしょうか。
今回はIrisデータセットを使った簡単な学習にとどめましたが、Trainer側で自動でトークナイゼーションしてくれるなど、まだまだ紹介しきれていない機能もあるので、次の機会にまた紹介させてください!
いいねやストック、拡散がモチベーションに繋がりますので、せひしていただけると嬉しいです!!🎉