はじめに
この記事では,論文の解説をしつつ,それを基にPythonで再現実装したパッケージを紹介していきます.
具体的には,英語と日本語文に対しての例文を用いた検証を行います.
英語文は本家様の論文中でかなり検証が行われているため,本記事では例文の検証のみに留めます.
本家様の論文及び実装ではmxnetと呼ばれるフレームワークが使われており,Huggigfaceのモデルは数個しか利用できません.
そこで,Huggingfaceで公開されている大体のモデルが試せるように実装しました.
MLM Scoringとは
Masked Language Model Scoring (ACL 2020) という論文でで提案された文章の自然さをスコアとして表そうという試みの中で登場するスコアの計算手法がMLM Scoringです.
MLM Scoringと一括りにしてしまっていますが,本記事で紹介する部分は正確には論文中で PLL (pseudo-log-likelihood scores = 擬似対数尤度スコア) と呼ばれています.
PLLは 各単語をマスクしたときの単語の予測確率の対数尤度の和 で,以下のような式で表されます.
PLL(\boldsymbol{W}):=\sum_{t=1}^{|\boldsymbol{W}|}logP_{MLM}(\boldsymbol{w_{t}}|\boldsymbol{W_{\t}})
本家様の論文中の図が大変わかりやすいので,そちらを引用させていただきます.
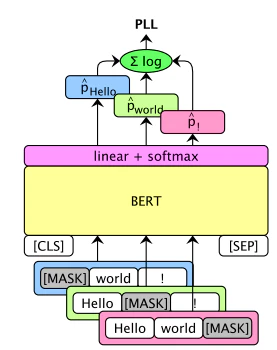
論文中ではマスクを使用せずに文章の自然さのスコアを計算する手法が提案されていますが,数%の性能劣化があり,今後の課題として挙げられていました.
mlm-scoring-transformersの紹介
次に,私が作成したMLM Scoringを簡単に試すことができるパッケージを紹介します.(宣伝)
まずはインストールからです.
git cloneしてpipで簡単に導入できます.
git clone https://github.com/Ryutaro-A/mlm-scoring-transformers.git
cd mlm-scoring-transformers
pip install .
Pytorch以外の依存ライブラリは自動でインストールされますが,Pytorchは環境依存が多いのでご自身でインストールしてください.
MLM Scoringの英語文への適用
インストールが完了したら,さっそく試してみましょう.
まずは本家様と同様に英語文に対して文章の自然さを測ってみます.
同じ文章で比較する方が自然さの比較になると思うので,今回はTOEICの穴埋め問題を解かせてみようと思います.
TOEICに過去問題はないので,TOEICの公式サイトから拾ってきた練習問題を使います.
穴埋め問題
Gyeon Corporation’s continuing education policy states that ------- learning new skills enhances creativity and focus.
(A) regular
(B) regularity
(C) regulate
(D) regularly
上記の穴埋めの全パターンに対してスコアを計算することで,最適な解答を探します.
import mlmt
# 事前学習済みモデルに'bert-base-uncased'を選択
pretrained_model_name = 'bert-base-uncased'
# PLL計算のためのインスタンスを作成
scorer = mlmt.MLMScorer(pretrained_model_name, use_cuda=False)
english_sample_sentences = [
'Gyeon Corporation’s continuing education policy states that regular learning new skills enhances creativity and focus.',
'Gyeon Corporation’s continuing education policy states that regularity learning new skills enhances creativity and focus.',
'Gyeon Corporation’s continuing education policy states that regulate learning new skills enhances creativity and focus.',
'Gyeon Corporation’s continuing education policy states that regularly learning new skills enhances creativity and focus.'
]
# PLLを計算
scores = scorer.score_sentences(english_sample_sentences)
for sentence, score in zip(english_sample_sentences, scores):
print(sentence, score)
# >> 出力結果
# Gyeon Corporation’s continuing education policy states that regular learning new skills enhances creativity and focus. -13.126020889783439
# Gyeon Corporation’s continuing education policy states that regularity learning new skills enhances creativity and focus. -11.912945440603236
# Gyeon Corporation’s continuing education policy states that regulate learning new skills enhances creativity and focus. -20.98635878855242
# Gyeon Corporation’s continuing education policy states that regularly learning new skills enhances creativity and focus. -11.304739751811596
結果をまとめます.
PLLは高いほど文章が自然であるとされているため,最後の文章が最も自然であり,TOEIC公式サイトが提供する解答と同じになっています.
| 文章 | PLL |
|---|---|
| Gyeon Corporation’s continuing education policy states that regular learning new skills enhances creativity and focus. | -13.126020889783439 |
| Gyeon Corporation’s continuing education policy states that regularity learning new skills enhances creativity and focus. | -11.912945440603236 |
| Gyeon Corporation’s continuing education policy states that regulate learning new skills enhances creativity and focus. | -20.98635878855242 |
| Gyeon Corporation’s continuing education policy states that regularly learning new skills enhances creativity and focus. | -11.304739751811596 |
使用した全ての問題は記載しませんが,20問中17問の穴埋め問題を正答することが出来ました.
MLM Scoringの日本語文への適用
次は本題である日本語文に対するMLM Scoringの有効性を検証していきます.
このために本家様のコードを使わずに再現実装しました.
穴埋め問題への適用
ここでは日本語能力試験(JPLT) の穴埋め問題を使用します.
英語文と同様にPLLを計算したところ以下のような結果となりました.
| 文章 | PLL |
|---|---|
| お母さんが行けるなら、わたしは行くのをやめるよ。うちから二人も出ることはないから。 | -72.90809887713657 |
| お母さんが行けると、わたしは行くのをやめるよ。うちから二人も出ることはないから。 | -75.87569694537336 |
| お母さんが行けたなら、わたしは行くのをやめるよ。うちから二人も出ることはないから。 | -65.31722020490005 |
| お母さんが行けるのだったら、わたしは行くのをやめるよ。うちから二人も出ることはないから。 | -86.46473170552028 |
この問題の正解は1番目と4番目の文章ですが,PLLでは3番目が最も高くなっており,文章の自然さをうまく計算できていません.
さいごに
日本語で上手くいかない原因は分かりませんが,次は大規模なデータセットを用いて定量的に実験していきたいと思います.
次の記事も是非見てください.
ここまで閲覧頂きありがとうございました!