はじめに
突然ですが、OpenTelemetry Demo をご存知でしょうか。複数言語で書かれたマイクロサービス群に対して、OpenTelemetry を活用してオブザーバビリティを体験できる公式デモアプリです。
こちらと AWS DevOps Agent を組み合わせて色々検証できないかと考えており、その前段階としてまずはローカルで触ってみたいと思います。本記事では、デモをローカルで起動し、意図的に障害を発生させて、トレース・メトリクス・ログの3つの観点から原因を追う体験をしてみたいと思います。
OpenTelemetry とは
OpenTelemetry(略称:OTel)は、アプリケーションの「内部で何が起きているか」を観測するためのオープンソースの標準フレームワークです。CNCF(Cloud Native Computing Foundation)のプロジェクトとして開発されています。
3つのシグナル
OTel が扱うデータは大きく3種類あり、それぞれ異なる役割を持っています。
| シグナル | 役割 | 例 |
|---|---|---|
| トレース | リクエストがどのサービスをどの順番で通ったかを追跡する | ユーザーが注文ボタンを押してから完了するまでの処理の流れ |
| メトリクス | 数値の推移を継続的に計測する | CPU使用率、リクエスト数、レイテンシの統計値 |
| ログ | 個別イベントの詳細を記録する | ERROR: DB接続タイムアウト(host=db-01, timeout=30s) |
障害対応の場面では、こんな使い分けになります。
- メトリクスで「何かおかしい」ことに気づく(アラート発火)
- トレースで「どこがおかしいか」を特定する(遅いサービスの発見)
- ログで「なぜおかしくなったか」を詳しく調べる(エラーメッセージの確認)
OpenTelemetry Demo とは
OpenTelemetry Demo は、OTel コミュニティが公式に提供しているマイクロサービスのデモアプリケーションです。天文学グッズを販売するECサイトという設定で、11言語・16以上のサービスで構成されています。
サービス構成
主要なサービスの一部を紹介します。様々な言語で実装されていることがわかります。
| サービス | 言語 | 役割 |
|---|---|---|
| Frontend | TypeScript | Webストアの画面 |
| Cart | .NET | カート管理 |
| Checkout | Go | 注文処理 |
| Payment | JavaScript | 決済処理 |
| Product Catalog | Go | 商品カタログ |
| Recommendation | Python | おすすめ商品 |
| Ad | Java | 広告配信 |
| Shipping | Rust | 配送計算 |
| Currency | C++ | 通貨変換 |
| Ruby | メール送信 |
Feature Flag による障害注入
このデモの面白いところは、Feature Flag で意図的に障害を注入できる点です。Web UI からフラグを切り替えるだけで、さまざまな障害シナリオを試せます。以下に代表的なフラグをいくつか紹介します。(全フラグの一覧は公式ドキュメントを参照してください)
| フラグ名 | 対象 | 障害内容 |
|---|---|---|
imageSlowLoad |
Frontend | 商品画像の読み込み遅延 |
adServiceHighCpu |
Ad Service | CPU 高負荷 |
paymentServiceFailure |
Payment Service | 決済エラー |
cartServiceFailure |
Cart Service | カート操作エラー |
productCatalogFailure |
Product Catalog | 商品取得エラー |
今回は imageSlowLoad(画像読み込み遅延)を使って検証していきます。
実際に触ってみる
Demo を使えるようにするまで
以下ページを参考にしています。
前提条件
- Docker(Docker Desktop 推奨)
- Docker Compose v2 以上
- メモリ: 6GB 以上(Docker Desktop の設定で確認)
- ディスク: 14GB 以上の空き容量
起動手順
# リポジトリをクローン
git clone https://github.com/open-telemetry/opentelemetry-demo.git
cd opentelemetry-demo
# 起動(初回はイメージ取得で数分かかります)
docker compose up --force-recreate --remove-orphans --detach
起動状況は docker compose ps で確認できます。全サービスが Up になるまで少し待ちます。
私は PROMETHEUS_HOST_PORT が既存のものと被ったので 19090 に変更しています。同様の現象が発生しうるのでご注意ください。
起動確認
以下の4つの URL にアクセスできればOKです。
| URL | 画面 |
|---|---|
| http://localhost:8080/ | Web ストア(フロントエンド) |
| http://localhost:8080/grafana/ | Grafana ダッシュボード |
| http://localhost:8080/jaeger/ui/ | Jaeger トレース UI |
| http://localhost:8080/feature | Feature Flag 管理画面 |
監視ツールについて
このデモには、3つのシグナルに対応した監視ツールがあらかじめ組み込まれています。テレメトリデータの流れは以下のようになっています。
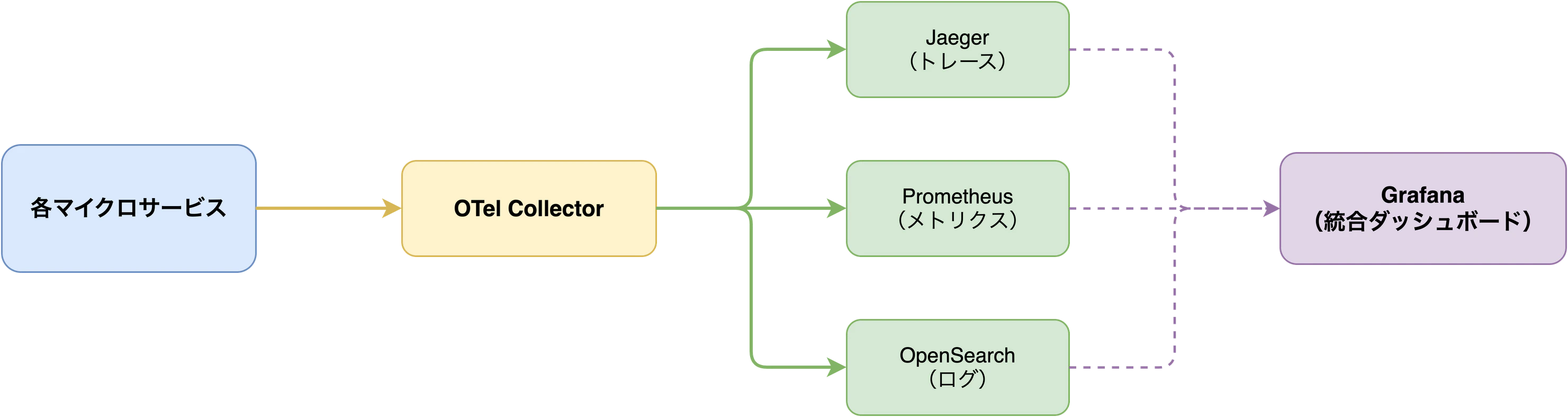
OTel Collector がデータの中継役として、各サービスからテレメトリを受け取り、適切なバックエンドに振り分けています。
Jaeger(トレース)
Jaeger は分散トレーシングツールです。「ユーザーのリクエストがどのサービスをどの順番で通り、各サービスで何ミリ秒かかったか」をウォーターフォール形式で可視化できます。
http://localhost:8080/jaeger/ui/ で専用の UI にアクセスできます。Grafana にもデータソースとして登録されているので、Grafana 上からトレースを参照することも可能です。
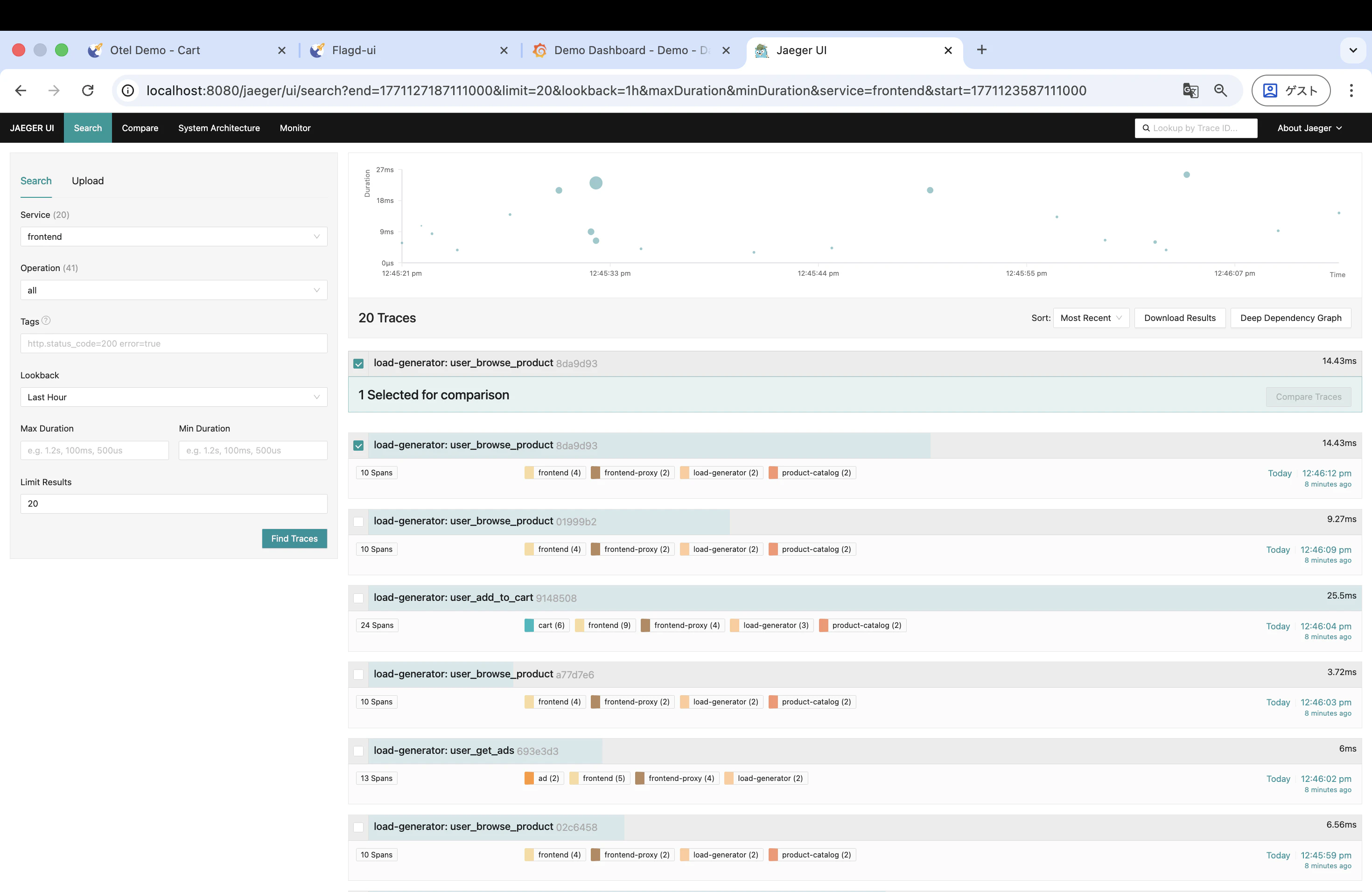
まずは正常時のトレースを1つ見てみます。
- 左上の「Service」から
frontendを選択 - 「Find Traces」をクリック
- トレースの一覧が表示されるので、1つクリック(今回は
load-generator: user_browse_productを確認)
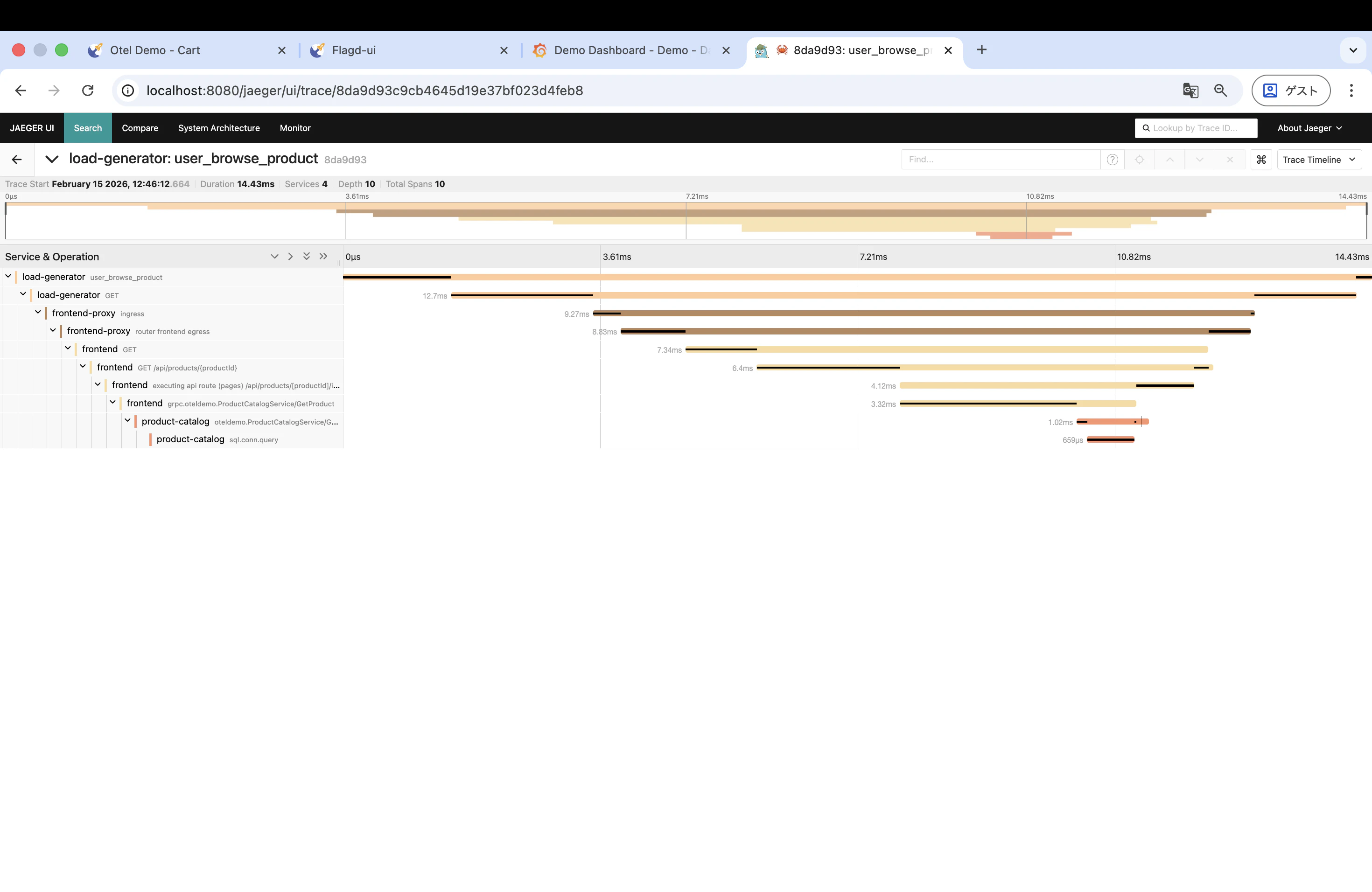
すると、各サービスの処理時間が横棒(スパン)で表示されます。正常時はどのスパンも短く、全体の処理時間も小さいことが確認できます。
Grafana / Prometheus(メトリクス)
Prometheus がメトリクスを収集し、Grafana がそれをダッシュボードとして可視化します。
http://localhost:8080/grafana/ でアクセスできます。
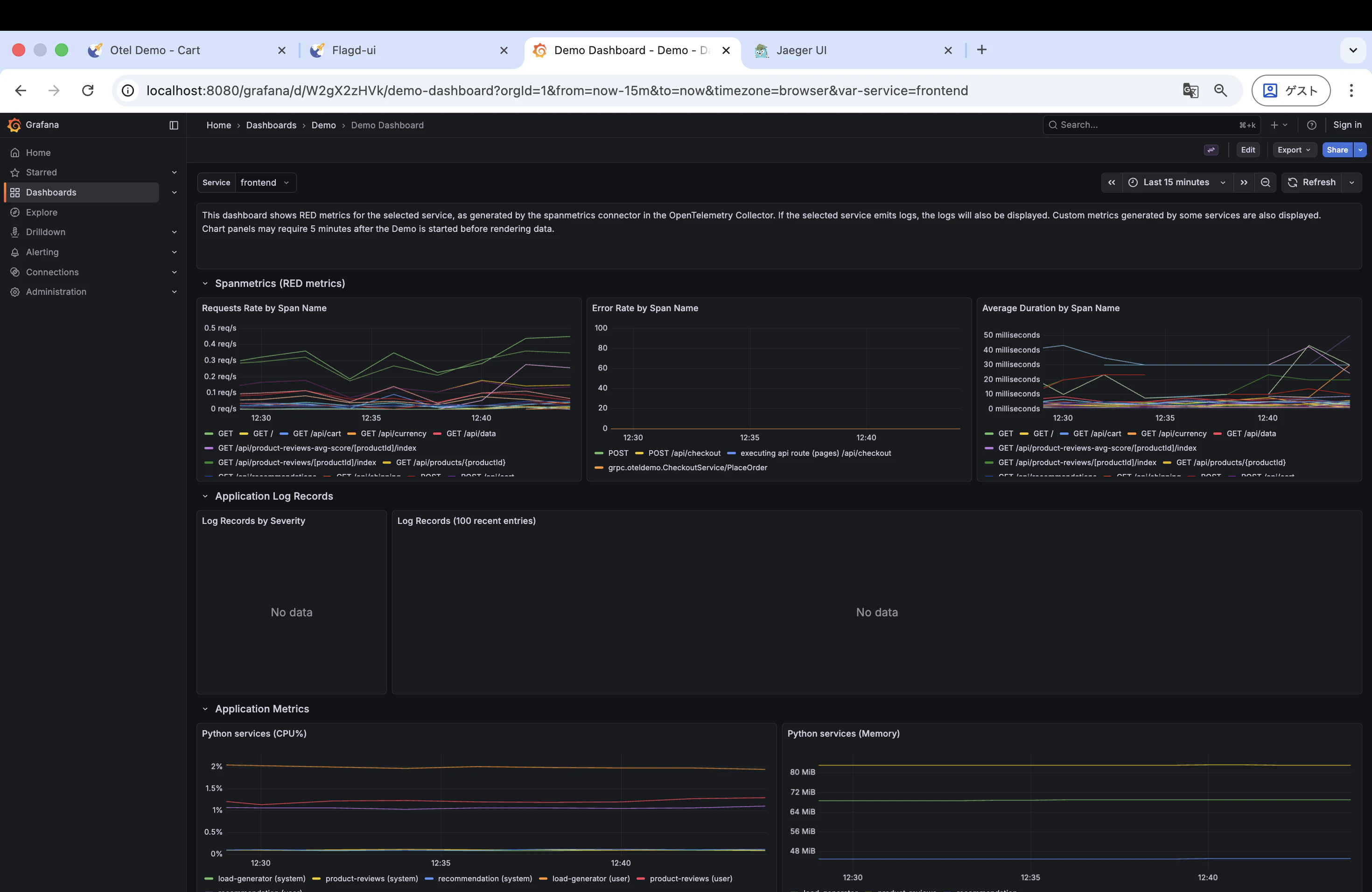
デモにはあらかじめダッシュボードが用意されています。以下の手順で正常時のメトリクスを確認してみます。
- 左メニューの「Dashboards」を選択
- ダッシュボード一覧から「Demo Dashboard」を選択
- 「Requests Rate by Span Name」「Error Rate by Span Name」「Average Duration by Span Name」などの時系列グラフが表示される
正常時は Average Duration が安定しており、Error Rate もほぼ 0 のはずです。
OpenSearch(ログ)
OpenSearch は各サービスの構造化ログを集約・検索できるツールです。エラー発生時に、関連するログをまとめて確認するのに役立ちます。
このデモでは OpenSearch の専用 UI は含まれておらず、Grafana にデータソースとして登録されているため、ログの確認も http://localhost:8080/grafana/ から行います。
- 左メニューの「Explore」を選択
- 上部のデータソースセレクターで「OpenSearch」を選択
- クエリに
resource.service.name:"frontend-proxy"と入力 - 「Run query」をクリック
frontend-proxy(Envoy)のアクセスログが時系列で表示されます。各ログにはリクエスト URL やステータスコード、traceId などが含まれています。
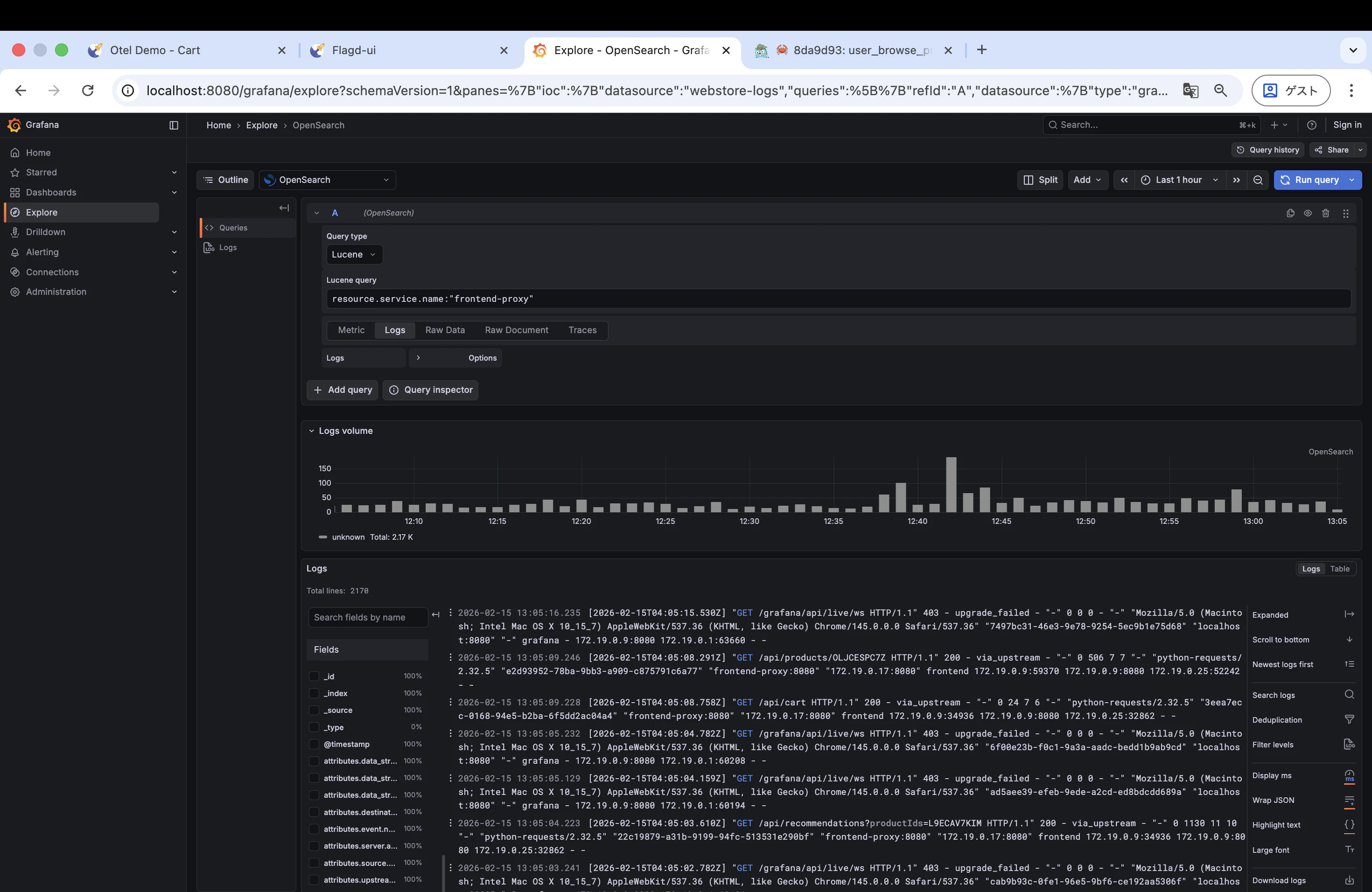
Jaeger や Grafana のメトリクスでは frontend というサービス名でデータが記録されていますが、OpenSearch のログには frontend は存在しません。frontend サービス(Next.js アプリ)はトレースとメトリクスは OTel SDK 経由で出力している一方、ログは OpenSearch に送っていないためです。代わりに frontend-proxy(Envoy)がアクセスログを記録しています。今回の imageSlowLoad は Envoy のフォルトインジェクションで発生する障害なので、frontend-proxy のログを確認するのが適切です。
障害を起こしてみる
いよいよ本題です。Feature Flag を使って障害を注入し、それを監視ツールで検知・分析してみます。
1. Feature Flag で遅延を有効化
http://localhost:8080/feature にアクセスし、imageSlowLoad フラグを有効化します。
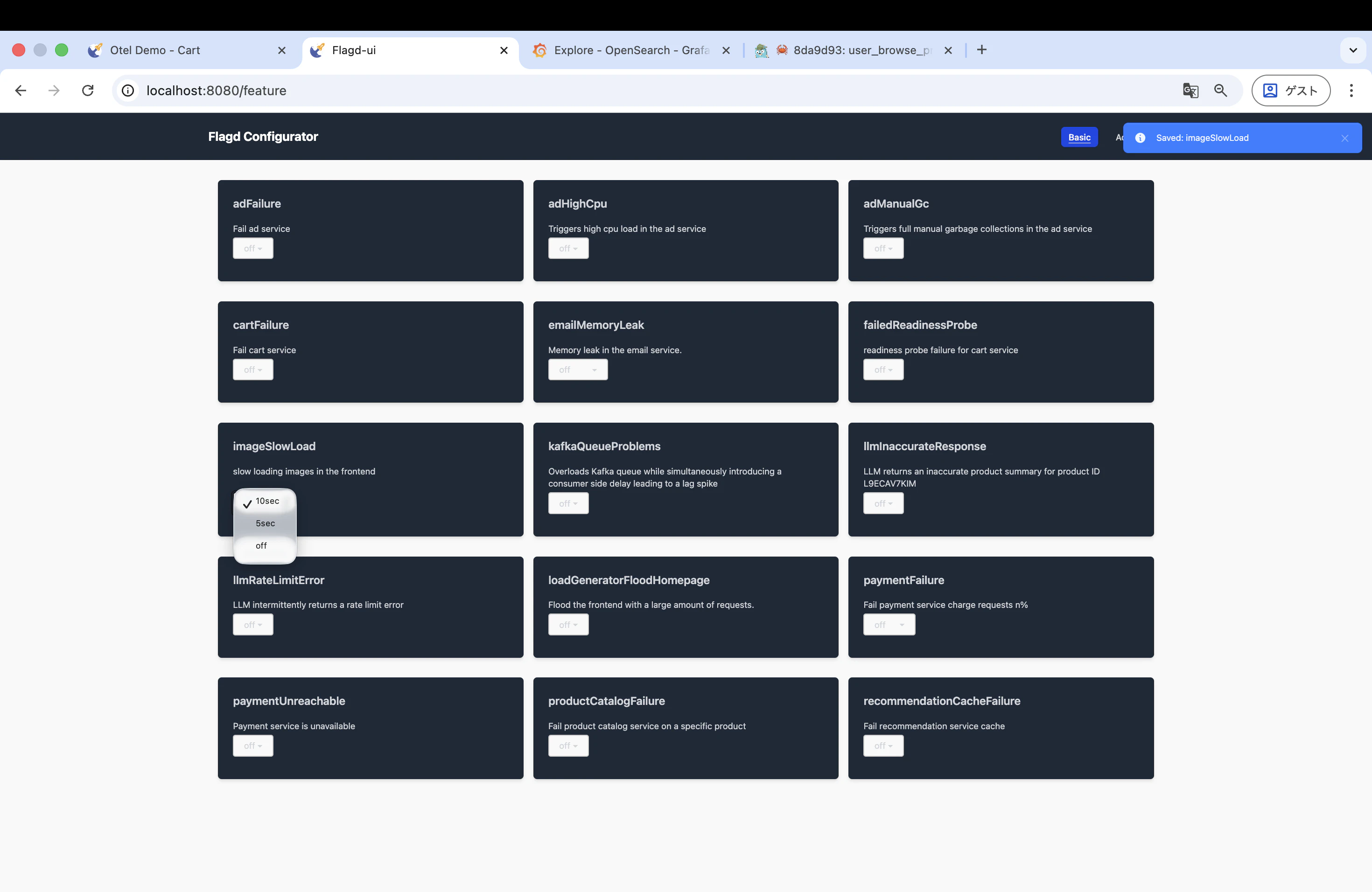
このフラグは、Envoy Proxy のフォルトインジェクション機能を使って、フロントエンドの商品画像読み込みに意図的な遅延を注入します。
2. フロントエンドで遅延を体感
http://localhost:8080/ でショップページを開き、商品画像の読み込みが遅くなっていることを確認します。
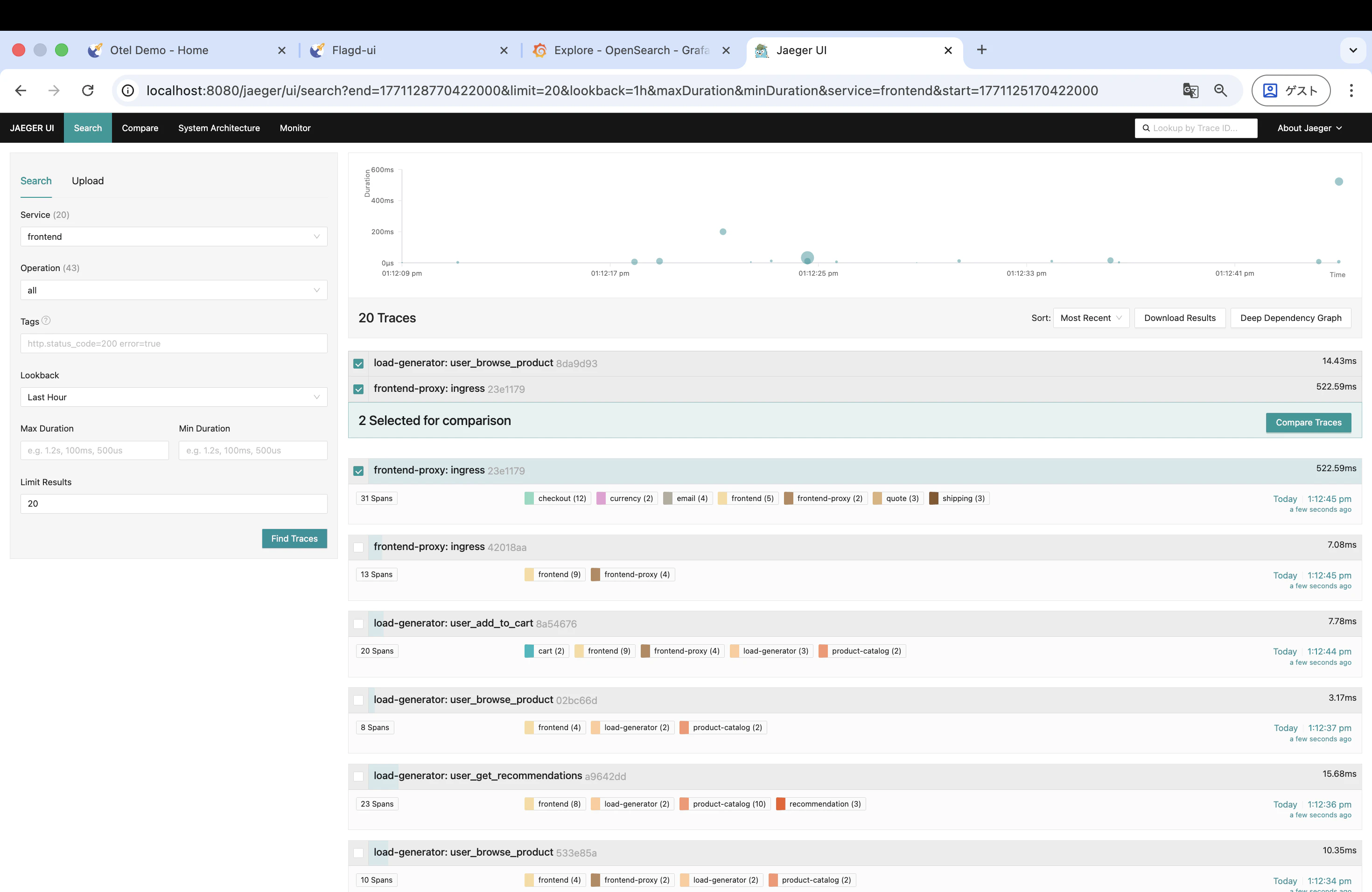
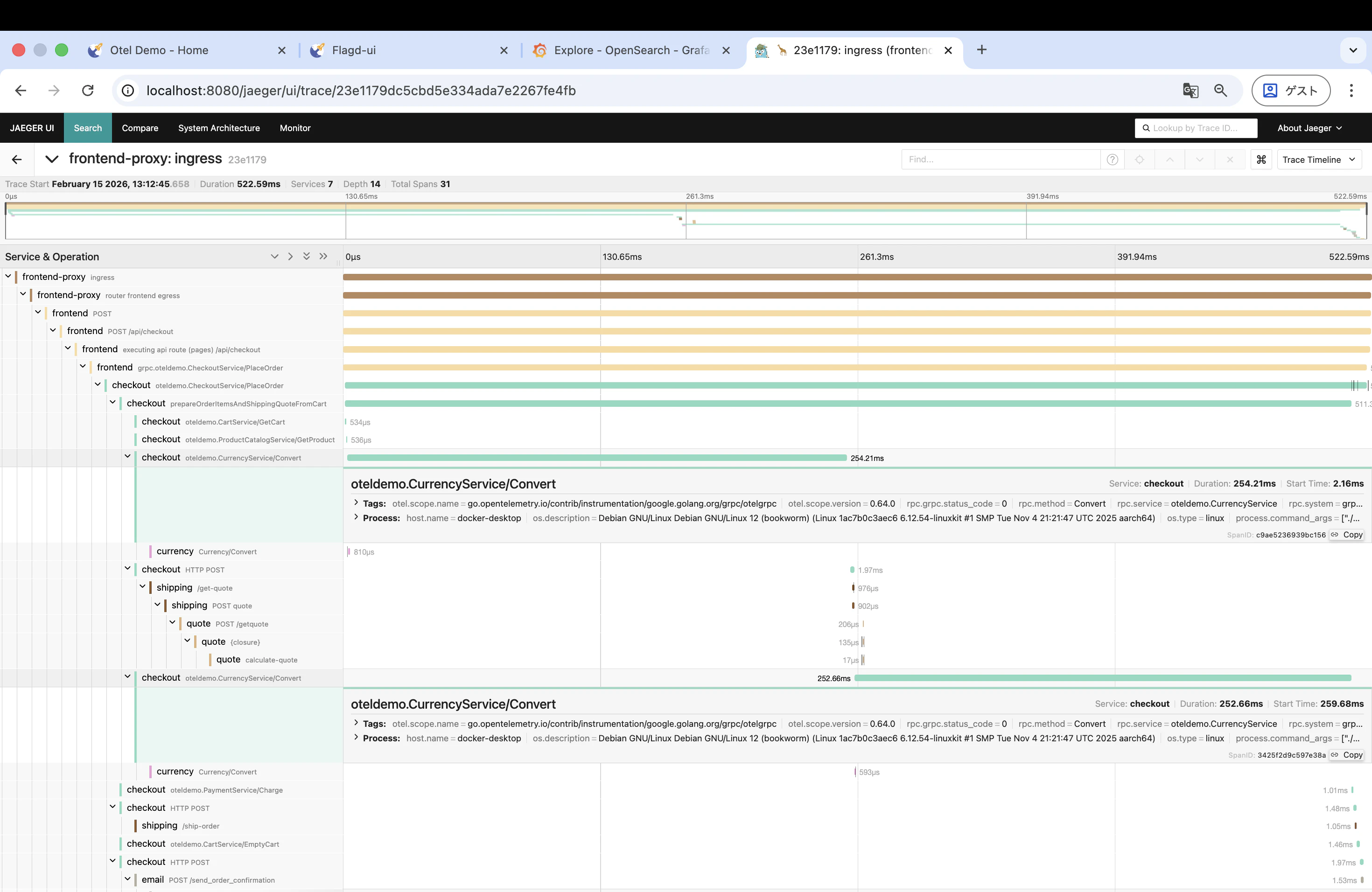
3. Jaeger でトレースを確認
Jaeger を開いて、遅延が発生しているトレースを探します。Service で frontend を選択し、処理時間が長いトレースをクリックしてみてください。どのスパン(どのサービスのどの処理)で時間がかかっているかがわかります。正常時と比べて、特定のスパンの処理時間が大幅に伸びているはずです。
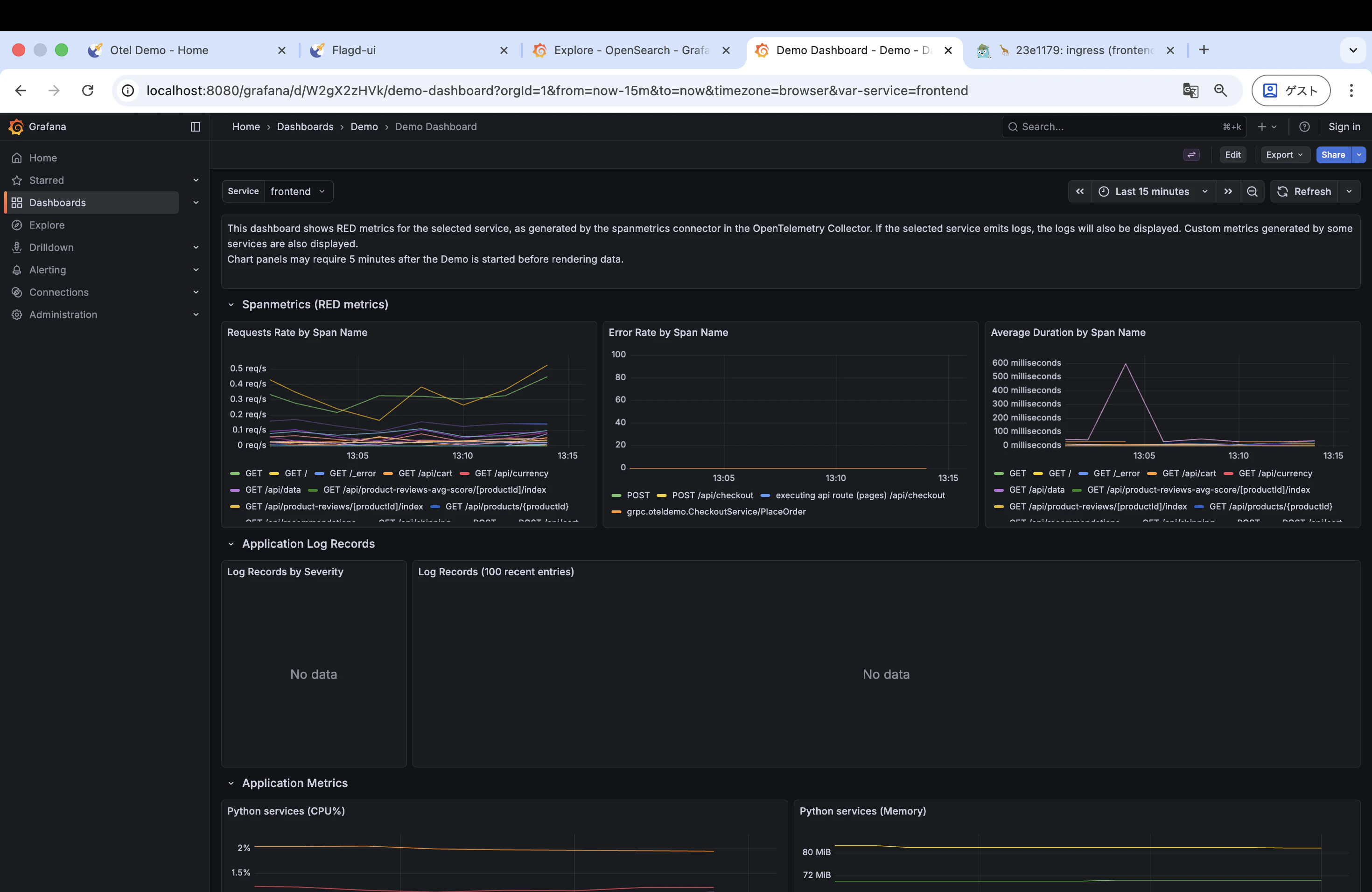
4. Grafana でメトリクスを確認
Grafana のダッシュボードで「Average Duration by Span Name」のグラフを確認します。フラグを有効化したタイミングで値が跳ね上がっているのが見えるはずです。
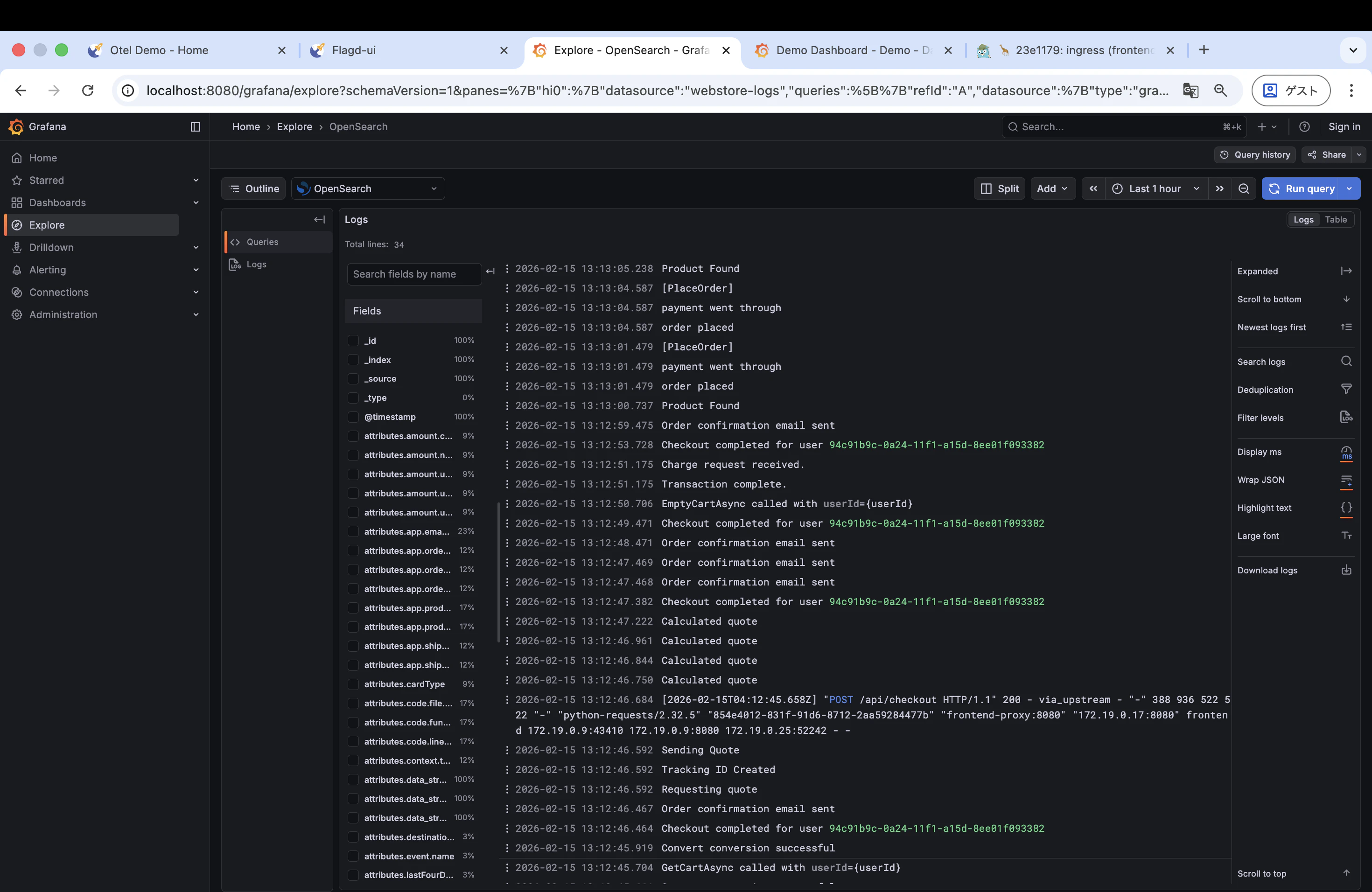
5. Grafana でログを確認
Jaeger で見つけた遅いトレースから、対応するログを追ってみます。
- Jaeger で遅延トレースを開き、画面上部に表示されている traceId をコピー
- Grafana の「Explore」→ データソース「OpenSearch」を選択
- 以下のクエリを入力して「Run query」
traceId:"<コピーした traceId>"
そのリクエストに紐づくログだけが表示されます。traceId をキーにするだけで、複数サービス(cart, checkout, payment, email など)にまたがるログを横断的に追えるのが OTel の強みです。
ログの中には Envoy のアクセスログも含まれており、例えば以下のような行が確認できます。
[2026-02-15T04:12:45.658Z] "POST /api/checkout HTTP/1.1" 200 - via_upstream - "-" 388 936 522 522 "-" ...
末尾の 522 522 の部分がレスポンスタイム(ミリ秒)で、このリクエストに 522ms かかっていることが読み取れます。
今回の imageSlowLoad は遅延が発生するだけでエラーは起きないため、ログ上で ERROR が増えるわけではありません。ERROR が大量に出るような障害シナリオ(例: paymentServiceFailure)であれば、ログの威力をより実感できると思います。
6. 原因サービスの特定
ここまでの観測から、以下のように原因を絞り込めます。
- Grafana(メトリクス):Average Duration の上昇を検知
- Jaeger(トレース):遅延が
frontendの画像取得リクエストに集中していることを特定 - Grafana(ログ):該当リクエストのログから詳細を確認
- 根本原因:Envoy Proxy で画像リクエストにフォルトインジェクション(遅延)が入っている
7. 回復確認
最後に、Feature Flag UI で imageSlowLoad を無効化し、ブラウザ上で画像の読み込みが正常に戻ったことを確認しました。
おわりに
今回は OpenTelemetry Demo をローカルで起動し、Feature Flag による障害注入 → 監視ツールでの検知・原因特定という一連の流れを体験しました。
やってみてわかったこと
OTel の3つのシグナル(トレース・メトリクス・ログ)を組み合わせることで、障害の検知から原因特定までを体系的に進められることがわかりました。特にトレースは「どこが遅いか」を直感的に把握でき、マイクロサービス環境では非常に強力だと感じました。
一方で、人間が手動で各ツールを見て回る必要があり、サービス数が増えると大変になりそうだとも感じました。
今後やりたいこと
今後はこのローカル環境のテレメトリを AWS(CloudWatch / X-Ray)に送信し、AWS DevOps Agent に障害の分析を任せてみたいと思っています。先ほど述べた、情報を見て回る部分をエージェントがよしなにやってくれることを期待しています。
ありがとうございました。