
この記事では以下の内容を紹介しています。
- 部品表やサプライチェーンを模したサンプルデータを作成した(download)
- トレーサビリティ分析のための 9 ホップのパス検索クエリを試した
- 600 万エッジに拡張しても約 200 ms のレスポンス性能を確認できた
はじめに
トレーサビリティの確立は品質向上を目指す工業製品だけでなく、安全や環境に対する意識の高まりから食品や医薬品、衣料品といった多くの分野で注目されている課題です。今回は工業製品における特徴的なデータとして部品表とサプライチェーンネットワークに注目しますが、ご紹介するパス検索という技術はより多くの分野で活用できるのではないかと期待しています。
まず、部品表 は BoM (Bill of Materials) とも呼ばれ、製品を組み上げるための部品の情報をツリー構造で保持しています。部品表を参照することによって、設計の際にはその製品の総重量を求めるといったことが可能になり、生産の際には必要となる資材の数がわかります。近年では、多くの製品にソフトウェアが搭載されているため、これらに含まれるライブラリのライセンスを部品表で管理することも求められています。
次に、サプライチェーンネットワーク という言葉は、製品に必要な原材料や部品の供給網を指すことが多いようです。ただし広義には、企業内で原材料を処理して部品を組み立てる過程、さらには製品が工場から出荷された後に倉庫に保管、運送、販売店に並び、消費者が手に取るまでの過程もサプライチェーンと言えます。
そして、ここで トレーサビリティ とは、原材料が工場に入ってきてから、製品が出荷されて消費者に届くまで、すべての段階において部品や製品を追跡することです。トレーサビリティは、製造工程の各ステップを可視化し、製造上の問題の根本的な原因を特定するために重要です。これにより、メーカーは問題の予防と解決に積極的に取り組むことができ、品質と効率を向上させることができます。
高いトレーサビリティを実現するためには、こうした一連の過程を、前から後ろまたは後ろから前へと辿る処理(それぞれ、トレースフォワードとトレースバック)を可能にする必要があります。そのために注目されているのが、この記事で取り上げるグラフデータベース技術です。
グラフを用いたデータモデリング
では、早速、検証のためのデータを作ってみます。ここでは非常にシンプルな部品表として、部品は常にふたつの子部品で構成されているようなツリー構造を考えます。ちょうど二分木(バイナリツリー)と呼ばれる構造になります。
部品表の構造はなるべく単純にしましたが、今回はこれに ロット情報 を付与しておきます。部品表やサプライチェーンのモデリングは、今までグラフデータベースの活用例として取り上げられることが多かったのですが、ロット情報が考慮されていない場合が多く、それではトレーサビリティという観点では実用性が限定的です。
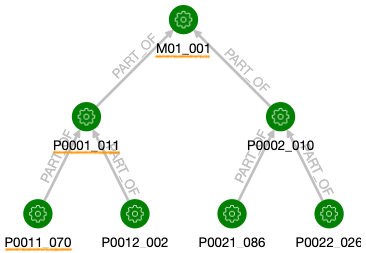
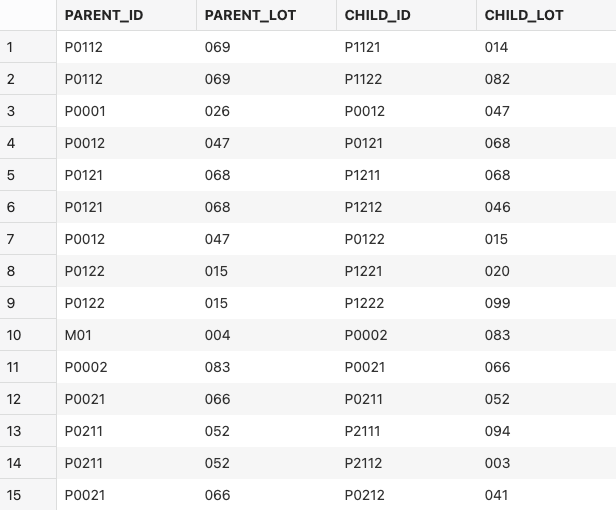
この結果、以下の図のような部品表ができました。読み方は「製品 M01 のロット 001 には部品 P0001 のロット 011 が含まれていて、さらにこれには部品 P0011 のロット 070 が含まれている」というようになります。
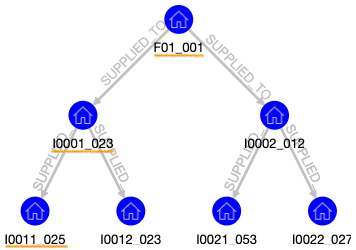
さらに、サプライチェーンとしては出荷後の製品が工場から販売店に運送される過程のみを考えることとして、部品表と全く同じ構造を仮定します。この図では「工場 F01 のロット 001 として出荷された製品の一部が倉庫 I0001 でロット 023 として保管され、さらにその一部は販売店 I0011 でロット 025 として保管されている」ことを表しています。
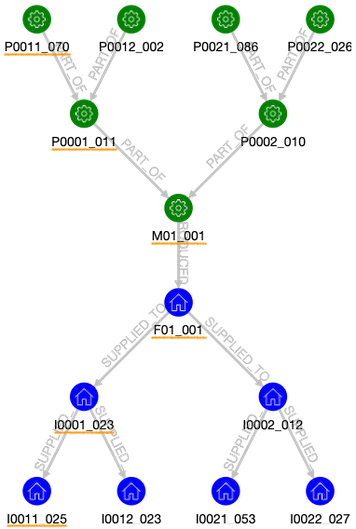
最後に、上の二種類のグラフを繋ぎ合わせます。ここでは、製造された製品のロットと工場から出荷されるロットが一対一で対応している状況を仮定します。つまり、次の図で「製品 M01 のロット 001 は工場 F01 の 001 というロットとして出荷される」ということになります。こうしてできた次の図では、最上層の部品 P0011 のロット 070 が最下層の倉庫 I0011 のロット 025 に含まれていることがわかります。
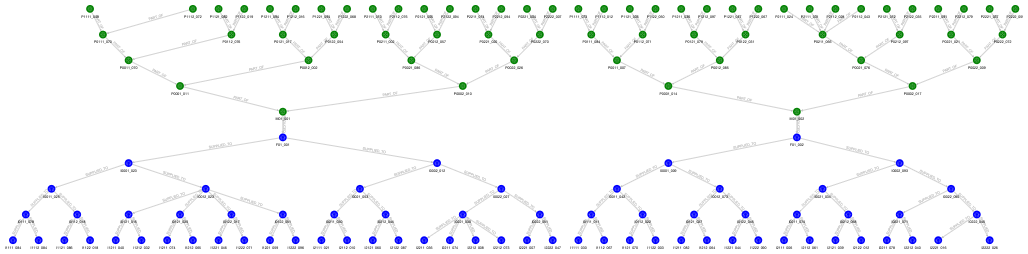
ここで、部品表とサプライチェーンのそれぞれを 5 階層にして、製品のロット数を 2 つにすると(製品 M01 のロット 001 と 002)以下のようになります。データベース上の製品のロット数もこの時点では 10 のみとしました。
このようなグラフ構造は、通常のデータベース上では以下の表のように保持されるため、グラフを辿るためには巨大な表を再帰的に結合していく必要があり非常に計算コストがかかります。一方で、Oracle Graph を使うと表データをメモリ上のグラフに展開しておく(その方法は後述)ことができるため、瞬時にグラフを辿る処理が実行できてしまいます。
グラフを「辿る」クエリの利用
上のようなグラフを準備できたら、早速クエリを実行してみましょう。ここで使われるクエリは SQL とは少し異なる PGQL というグラフ専用の言語で書かれています。
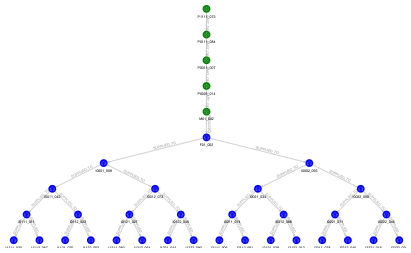
まずは、ある部品のあるロットがどこに行き着いたかを調べてみます。これは トレースフォワード と呼ばれます。このクエリでは「部品 P1111 のロット 073」について検索しています。パスのパターンとして (->(p)){1,9} としているのは 1 〜 9 回のホップを示しています。p1 がパスの始点になっているので、ここに条件を与えています。
SELECT v1, e, v2
FROM MATCH ALL (p1) (->(p)){1,9} (p2) ONE ROW PER STEP ( v1, e, v2 ) ON TRACE_ALL
WHERE p1.part_id = 'P1111' AND p1.lot = '073'
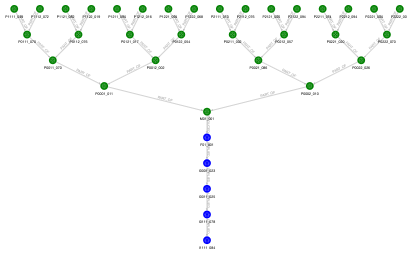
次は逆に、ある販売店の在庫がどの部品のどのロットを使ったものであるかを調べます。これは トレースバック と呼ばれます。このクエリでは「販売店 I1111 のロット 084」について検索しています。先程とパターンは同じですが、パスの終点になっている p2 に条件を与えています。
SELECT v1, e, v2
FROM MATCH ALL (p1) (->(p)){1,9} (p2) ONE ROW PER STEP ( v1, e, v2 ) ON TRACE_ALL
WHERE p2.place_id = 'I1111' AND p2.lot = '084'
最後に、始点と終点を指定した パス検索 も試してみます。「部品 P1111 のロット 049 が販売店 I1111 のロット 084 に含まれるかどうか、その場合、どの経路をたどった可能性があるか」を調べることができます。
SELECT v1, e, v2
FROM MATCH ALL (p1) (->(p)){1,9} (p2) ONE ROW PER STEP ( v1, e, v2 ) ON TRACE_ALL
WHERE p1.part_id = 'P1111' AND p1.lot = '049' AND p2.place_id = 'I1111' AND p2.lot = '084'

小さな複雑さが生じた場合
上のような単純でわかりやすいデータの場合に期待通りの結果が得られることはわかりました。そこで、少しだけデータに複雑さがあった場合に、このモデルが使えるかどうか試してみます。
例えば、次の図では「部品 P0021 のロット 076 と 048 の両方で部品 P0211 のはロット 066 が使われている」という状況を表しています。
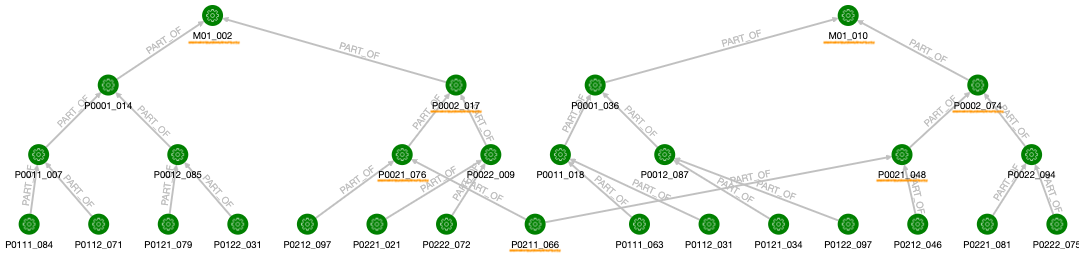
この場合、仮に部品 P0211 のロット 066 に問題があった際には、製品 M01 のロット 002 と 010 の両方にこの部品が含まれることになるので、その影響範囲は大きくなるはずです。
そこで、部品 P0211 のロット 066 からトレースフォワードのクエリを実行してみます。すると、期待した通り、製品 M01 の 2 つのロットの出荷先が取得できることがわかります。
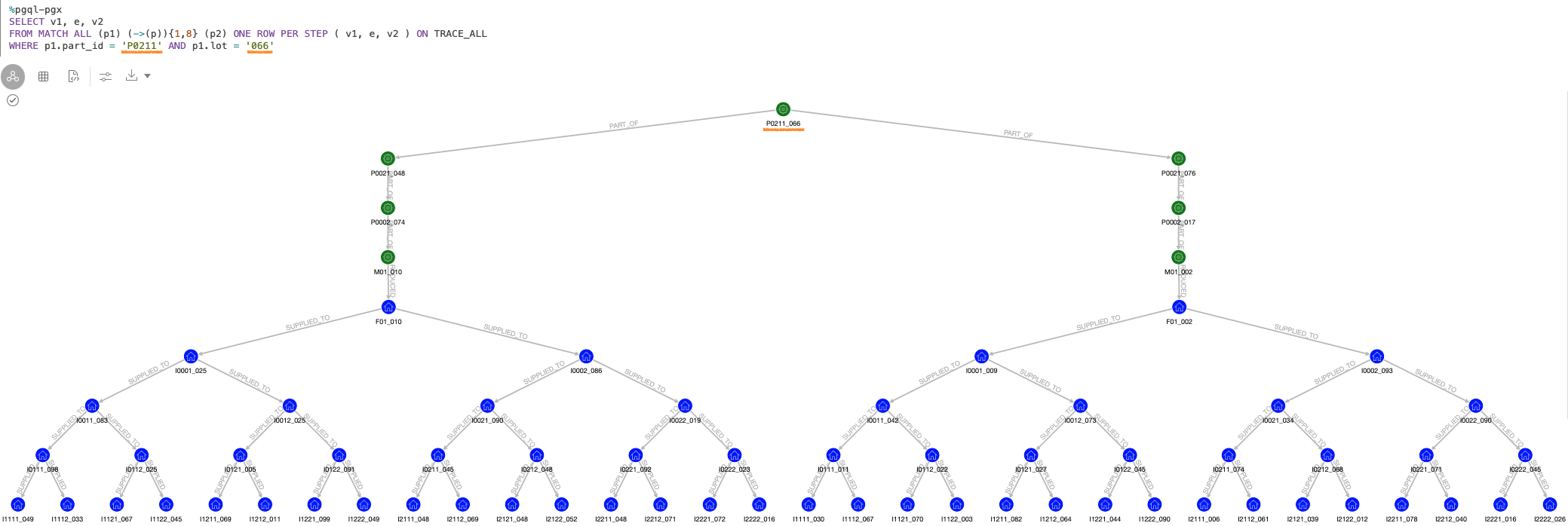
このような複雑さが生じると、製品 M01 の異なるロットの間でグラフが結合されるため、ロット数を 10(エッジの総数は 610)としただけでも、ずいぶん大きな「あみだくじ」のようになることがわかります。

データを拡張した場合
検索の性能を確認するためには、十分なサイズのデータに対してクエリを実行してみる必要があるので、簡単なシミュレーションデータを作成してみます。以下はデータの詳細なので必要に応じて 読み飛ばして ください。
ーー
ある製品には 2 つの部品が、その部品にも 2 つの部品が、と繰り返して計 4 階層を用意すると 30(= 2 + 4 + 8 + 16)のエッジからなる木ができます。サプライチェーン側にも同じ構造の 30 エッジの木を用意して、ルート同士(組み上がった製品と出荷元の工場)を 1 対 1 で繋ぎます。すると、ルートである製品 M01 のロット(= 工場の出荷ロット)が 100,000 あった場合、エッジの総数は 100,000 * (30 + 30 + 1) = 6,100,000 となります。
ここで、それぞれの製品を組むために使う各部品のロット番号は 7 桁の数字をランダムに選んでいいことにしておくと、木が絡まり合って大きなグラフになります。サプライチェーン側も同じ構造にします。同じロットがランダムに複数回選択されることがあるため、ノードの数は一意に決まりませんが、今回は 5,909,678 となりました。
ーー
これはまだ決して十分なサイズではありませんが、同じ要領でグラフのサイズや複雑さを調整していくことができるはずです。
このグラフに対して、ある部品のあるロット(= P1111 のロット 0190295)からトレースフォワードのクエリを実行した結果がこちらです。グラフ全体のサイズが大きくなっても、ある部品から辿った範囲のみを瞬時に取ってくることができています。
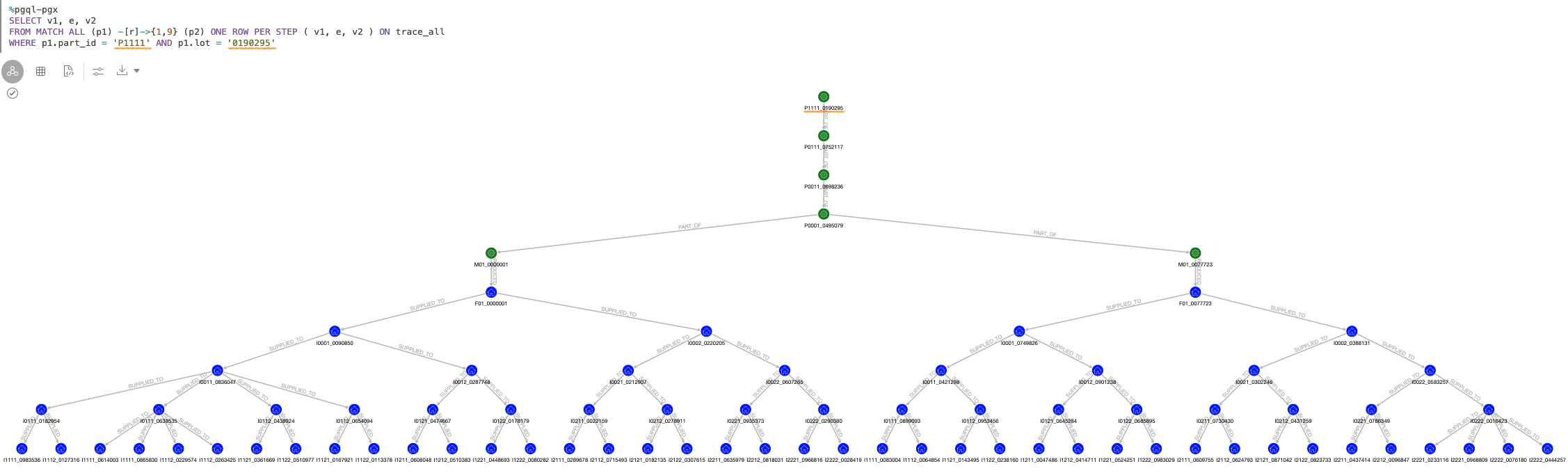
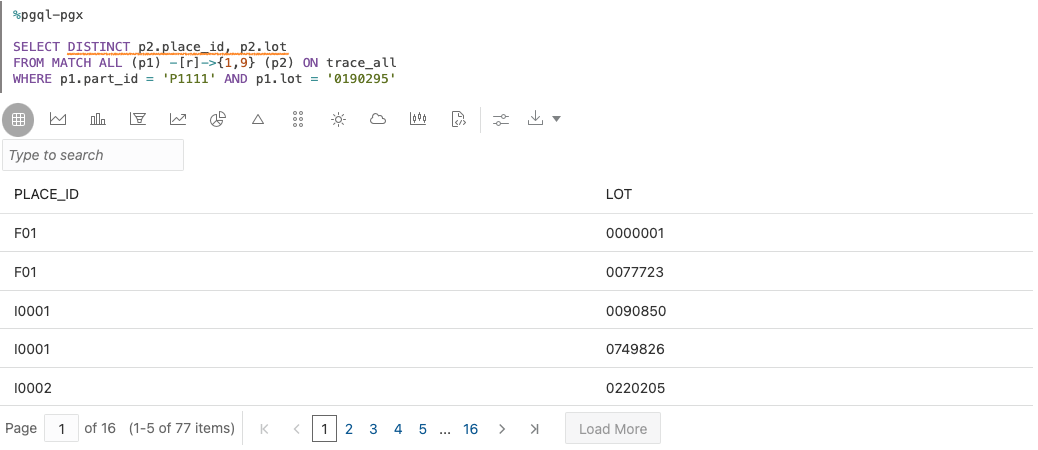
もしも末端の販売店とその在庫ロットのリストのみが欲しいのであれば、グラフを描画するよりも結果を表で取得するほうがわかりやすいはずです。
クエリの実行時間を次のように測定してみると 203 ms であることがわかります。この時間にはクライアントとサーバーとの通信も含まれますので、データベース上の実行時間はもっと短いことになります。いずれにしても、分析の用途にストレスのない実行時間であることがわかります。(独立した Graph Server にて試してみたところ、サーバー側の実行時間は 100 ms 程度でした。)
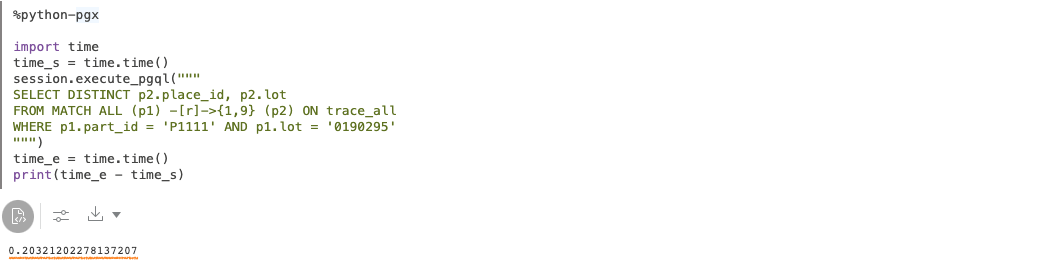
表データをグラフに変換する方法
以上のようにグラフを用いてデータを管理することで、クエリによるトレースが可能であり、その性能が非常に高いことがわかりました。一方で、通常、生産や流通の過程のデータ(トランザクションやログ)は管理や集計に向いた表の形式で収集されます。そこで、ここでは、表データからグラフを変換するための方法を紹介します。
まず、部品表を管理する trace_bom という名前のグラフを作成するための定義がこちらです。trace_bom_node と trace_bom_edge という 2 つの表が入力になっています。
CREATE PROPERTY GRAPH trace_bom
VERTEX TABLES (
trace_bom_node
KEY (id)
LABEL part
PROPERTIES (id, part_id, lot)
)
EDGE TABLES (
trace_bom_edge
KEY (id)
SOURCE KEY(child_id) REFERENCES trace_bom_node
DESTINATION KEY(parent_id) REFERENCES trace_bom_node
LABEL part_of
NO PROPERTIES
)
サプライチェーンネットワークを管理する trace_scn というグラフも同様に定義できます。
CREATE PROPERTY GRAPH trace_scn
VERTEX TABLES (
trace_scn_node
KEY (id)
LABEL place
PROPERTIES (id, place_id, lot)
)
EDGE TABLES (
trace_scn_edge
KEY (id)
SOURCE KEY(src_id) REFERENCES trace_scn_node
DESTINATION KEY(dst_id) REFERENCES trace_scn_node
LABEL supplied_to
NO PROPERTIES
)
最後に、上の 2 つのグラフを、ツリーの根となっているノード(製品と工場)で接続したグラフ trace_all がこちらです。このように、複数のデータセットを 1 つのグラフに統合することができるのも、表からグラフを定義しておくことのメリットと言えます。
CREATE PROPERTY GRAPH trace_all
VERTEX TABLES (
trace_bom_node
KEY (id)
LABEL part
PROPERTIES (id, part_id, lot)
, trace_scn_node
KEY (id)
LABEL place
PROPERTIES (id, place_id, lot)
)
EDGE TABLES (
trace_bom_edge
KEY (id)
SOURCE KEY(child_id) REFERENCES trace_bom_node
DESTINATION KEY(parent_id) REFERENCES trace_bom_node
LABEL part_of
NO PROPERTIES
, trace_scn_edge
KEY (id)
SOURCE KEY(src_id) REFERENCES trace_scn_node
DESTINATION KEY(dst_id) REFERENCES trace_scn_node
LABEL supplied_to
NO PROPERTIES
, trace_b2s_edge
KEY (id)
SOURCE KEY(part_id) REFERENCES trace_bom_node
DESTINATION KEY(place_id) REFERENCES trace_scn_node
LABEL produced_at
NO PROPERTIES
)
デモ環境の構築方法
上記のグラフの作成からクエリの分析までの流れをお手元で試してみたい方のため、デモ環境の構築方法をご紹介します。特に Autonomous Database を使ったことのある方であれば、簡単に構築できてしまいますので、ぜひお試しください。
- Oracle Cloud の無料アカウントを取得します
- Autonomous Database を起動します(Always-free です)
- データとテンプレートとノートブックを ダウンロード(.zip)します
- Database Actions からデータ(.csv)を表にロードします
- Graph Studio にテンプレート(.json)をインポートします
- ノートブック(.dsnb)をインポートして実行します
まとめ
今回のデモでは、部品表とサプライチェーンを模したデータをグラフに格納し、トレーサビリティを実現するためにパスのパターンを用いたクエリ(1点からグラフを辿る処理、および 2点間のパス検索)が高速かつ有効な手段であることを示しました。
デモで用いたデータは(意図的ではありますが)あまりに単純化されており、現実のデータのモデリングはずっと複雑なものになるはずです。取得できるデータに欠落が生じる場合もありますし、制約条件をロジックとして含めなくてはいけない場合もあります。データの収集と整理は高い障壁となるはずです。
その一方で、ここ数年、CREATE PROPERTY GRAPH を用いた表からグラフへのマッピング手法などが整備されてきたことで、トランザクションのようなデータもグラフを通して分析・可視化することが現実的になってきました。顕在している社会のニーズも相まって、このデータベース技術がブレークスルーとなることを期待しています。
※ 冒頭画像 Photo by carlos aranda on Unsplash