この記事は PagerDuty Advent Calendar 2023 22日目です![]()
初めに
こんにちは!
NTTデータ ペイメント事業本部 カード&ペイメント事業部デジタルペイメント開発室の松井です。
本記事では大規模アジャイル組織で PagerDuty をどのように活用しているかについて、アーキテクチャにも触れながら解説していきたいと思います。
組織とサービスについて
デジタルペイメント開発室
デジタルペイメント開発室は、日本最大級のキャッシュレス決済プラットフォームであるCAFISの開発/維持/運用を手掛けるカード&ペイメント事業部に特区として創設された組織で、CAFISのDXプロジェクトであるDigital CAFISを推進する役割を担っています。
※ここでは簡単にしか触れないので、デジタルペイメント開発室について詳しく知りたい方は以下の記事も併せてお読みください。
担当するサービス
デジタルペイメント開発室が開発を進めるサービスの1つが、チャネル統合型の次世代決済代行ソリューションOmni Payment Gatewayです。
あらゆるチャネルからの決済を実現する「決済中継サービス」や申込み/問合せのデジタル化データの集約&可視化等ができる「デジタルオペレーション」の機能を有しています。
そんな Omni Payment Gateway の開発手法にはアジャイル開発が採用されており、プロジェクトの参画人数は協働者様を含めると200名を軽く超えます。まさに大規模アジャイル組織です。
※サービスの詳細は以下の記事がありますので、参考に御覧ください。
大規模アジャイルにおけるPagerDutyの活用方法
それでは、このような大規模アジャイル組織においてどのように PagerDuty を活用しているかについてご説明していきたいと思います。
アーキテクチャ
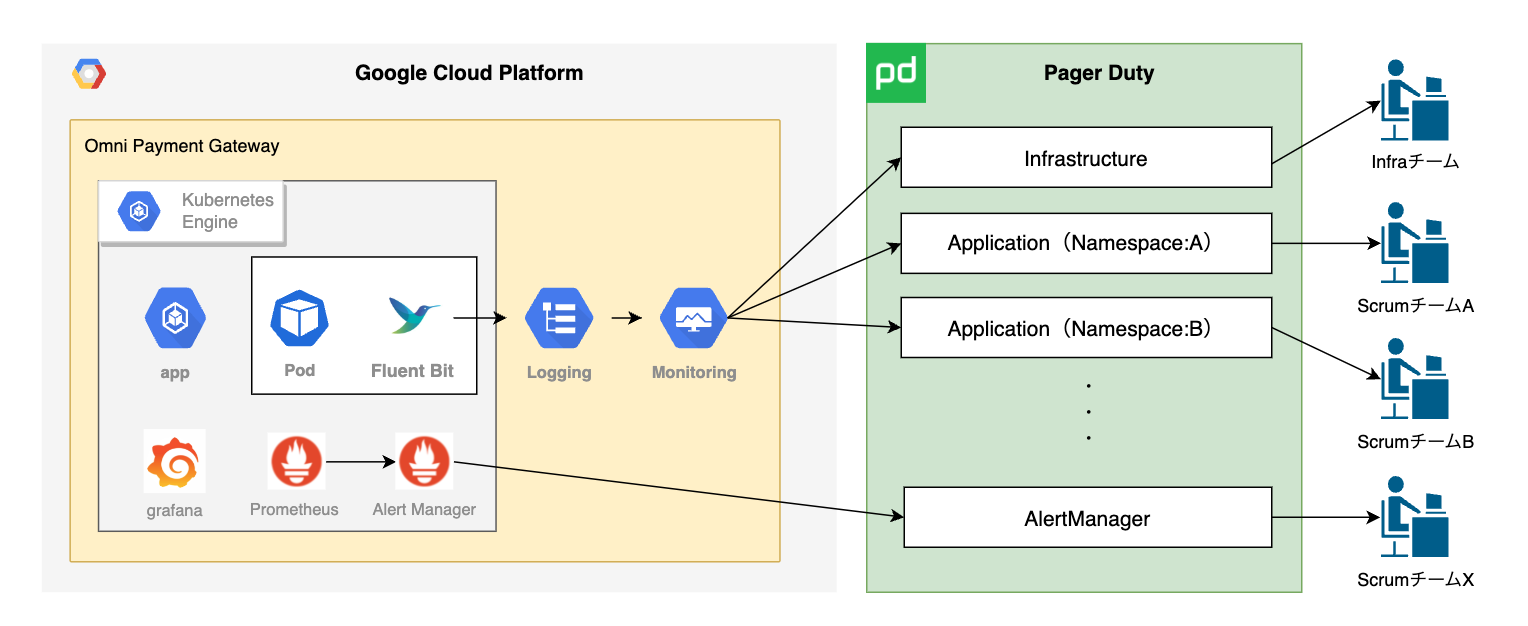
こちらが簡易的なアーキテクチャ図となっています。
アプリケーションは GoogleCloud の GKE (Google Kubernetes Engine) 上に構築されており、クラスタに kube-prometheus-stack で Prometheus, Alertmanager, Grafana がデプロイされています。
- システムメトリクス監視
Prometheus の rule によって Alertmanager 経由で PagerDuty を鳴らすようにしています。 - ログ監視
ログベースのメトリクスとして Cloud Monitoring 経由で PagerDuty を鳴らすようにしています。
PagerDutyのサービスは大きくインフラとアプリケーションに分けて作成しており、中でもアプリケーションは Namespace ごとにサービスを作成しています。このサービスと各スクラムチームごとに作成したエスカレーショングループを紐付けており、インフラ関連のエラーを検知した場合はインフラ担当のチームメンバに電話が鳴り、Namespace:Aにあるアプリケーションでエラーが発生した場合はそのアプリを開発しているチームメンバに電話が鳴ります。
以下は各ツールの簡単な説明です。
■kube-prometheus-stack
Kubernetes 上に Prometheus と Grafana 環境を簡易にインストールすることが出来るもの。
Prometheus Operator を使って Kubernetes クラスターを監視するために必要なコンポーネントがスタックとして集合されており、 prometheus-community の helm-chart を使ってインストールすることができます。
■Prometheus
主にシステム監視とそれに連動したアラート機能を提供するツール。
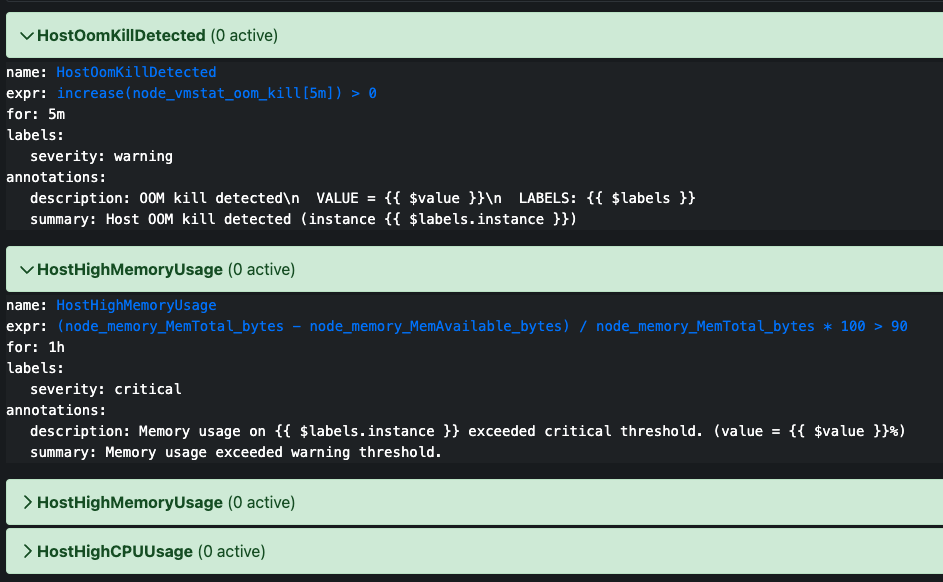
特徴としてはサービス固有のメトリクスを時系列データとして収集して保存し、PromQLというクエリ言語でデータを操作してアラートを上げます。メトリクスの例としてはWebサーバーにおけるリクエスト数やリクエストの処理時間といったものが挙げられます。
下記画像のように Alert の rule を設定することができます。
■Alertmanager
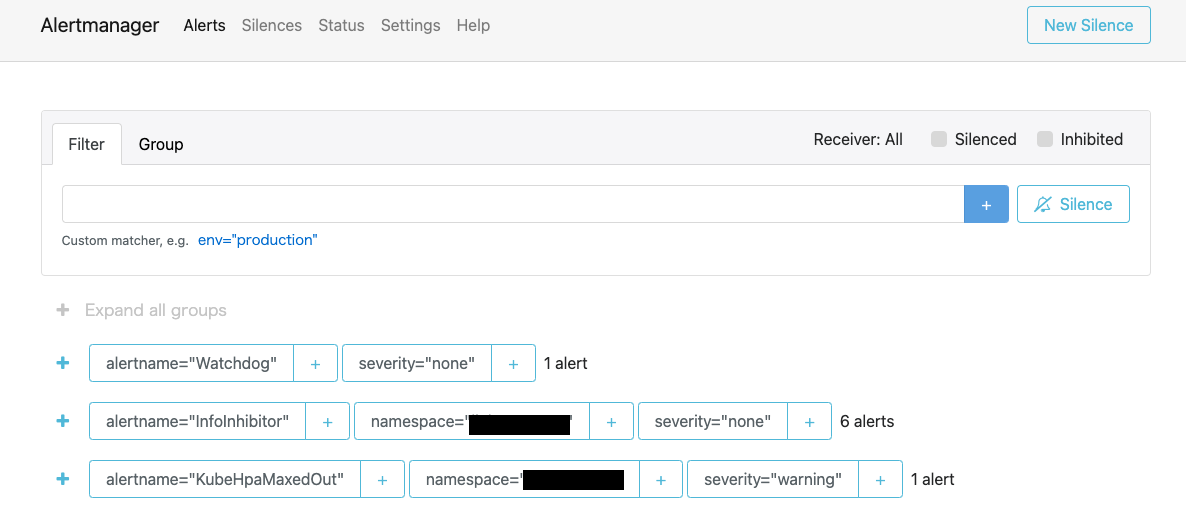
Prometheus からのアラートに関する情報を受け取って、通知を行う機能。
Prometheus とは別に起動するプロセスで、アラートの重複排除やグループ化を行い、メールや PagerDuty へルーティングすることができます。
■Grafana
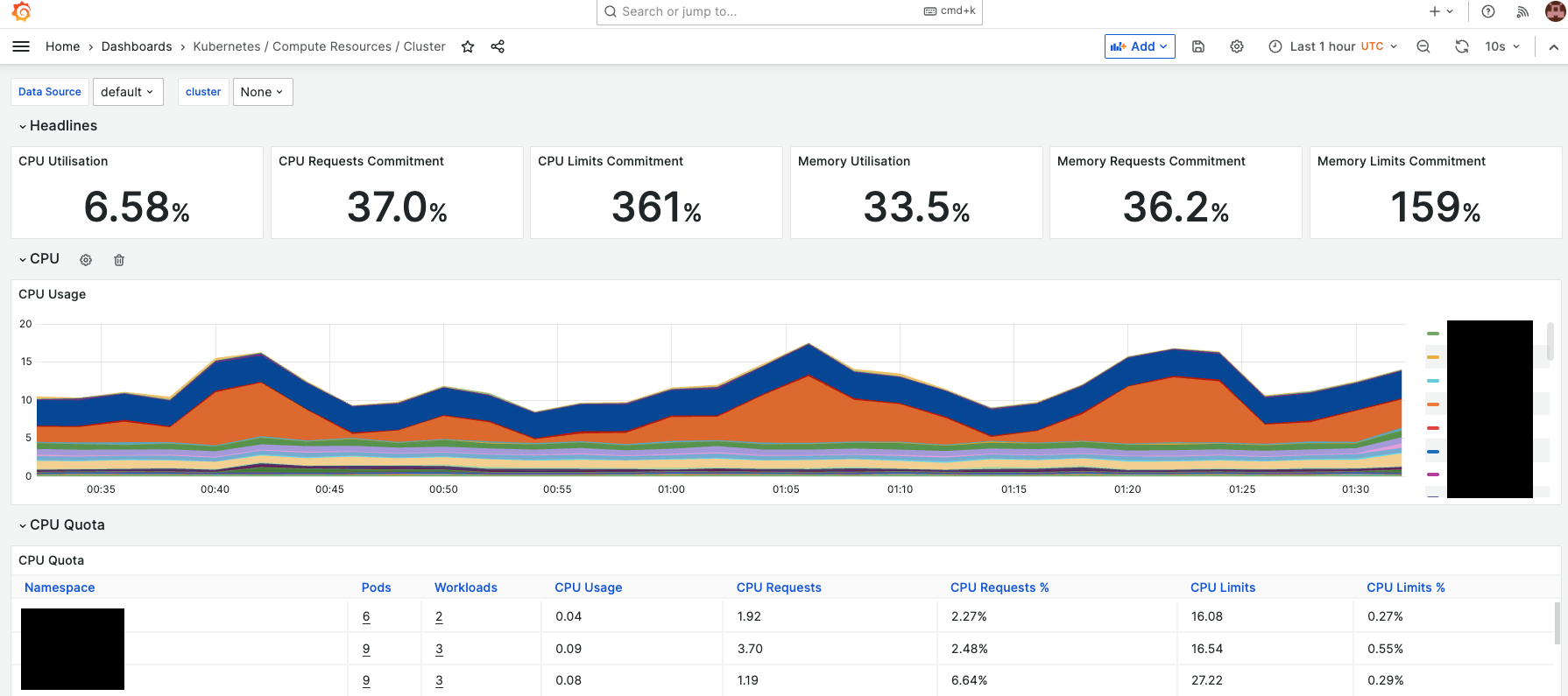
データ可視化ツール。
Grafana を利用するためには元のデータが必要であり、データを収集するツール(Prometheus や Elasticsearch 等)と組み合わせて使用します。
可視化に特化しているため、他プロダクトが各自で用意しているダッシュボードよりも時系列グラフの可視化自由度が高いという特徴があります。
もう少し具体的に見ていきます。
Apps → Cloud Logging
GKE上に DaemonSet としてデプロイされた FluentBit が Cloud Logging にログを送信します。
FluentBitは、アプリケーションやコンテナから出力されたログデータを収集し、フィルタリングして指定した宛先に送信できるツールです。
Cloud Logging → Cloud Monitoring
ログベースの指標
以下のように Cloud Logging のログベースの指標を Namespace ごとに作成しています。
ログベースの指標を設定することで、ログエントリの内容から指標データを取得し、条件に該当するログエントリの数をカウントすることができます。
resource.type=k8s_container AND
resource.labels.project_id={PROJECT_ID} AND
resource.labels.cluster_name={CLUSTER_NAME} AND
resource.labels.namespace_name={NAMESPACE_NAME} AND
-logName = projects/{PROJECT_ID}/logs/server-accesslog-stackdriver AND resource.labels.container_name = (
"{NAMESPACE_NAME}"
) AND
severity >= ERROR
↑を簡単に説明すると、「あるNamespace内のアプリケーションで エラーレベルが ERROR 以上のログが出た場合」という指標です。
指標ベースのアラートポリシー
上記で作成した指標をベースに Cloud Monitoring のアラートポリシーを作成しています。
作成したログベースの指標Count数 > 0 となった時にアラートになるように設定しています。
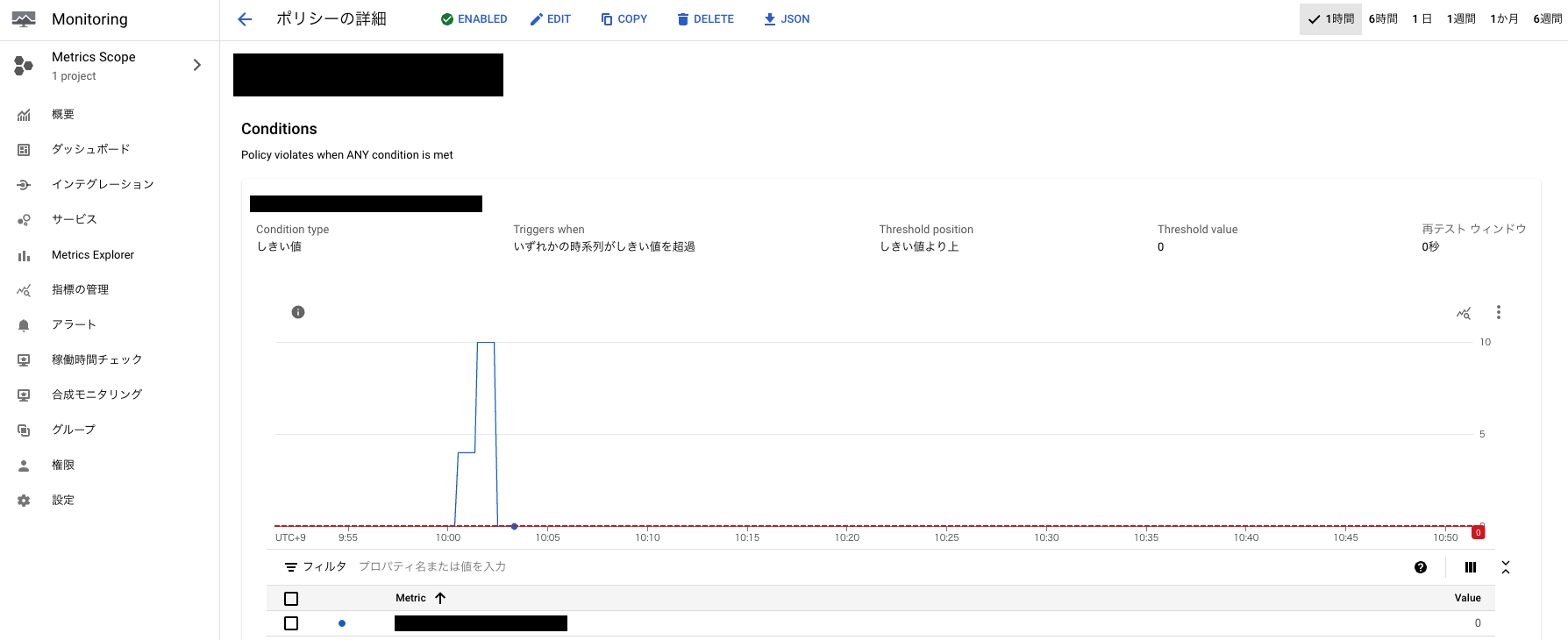
Cloud Monitoring → PagerDuty
Notification Channels
上記で作成したアラートポリシーには、 通知チャネルを指定することができます。
ここで PagerDuty の IntegrationKey を指定することで、 GoogleCloud と PagerDuty の連携をしています。
ログベースの指標やアラートポリシーと同様に PagerDuty のサービスも Namespace ごとに作成しておくことにより、 通知先を柔軟にカスタマイズすることができます。
下記画像では、 PagerDuty と Cloud Pub/Sub を Notification Channels に設定しています。

アジャイルならではの工夫点
私達はアジャイル開発のフレームワーク SAFe を導入しており、スクラムチームと呼ばれる開発チームがいくつもあります。
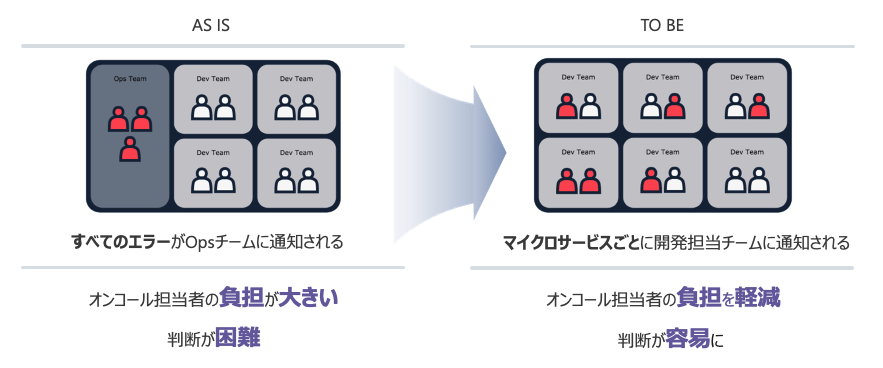
PagerDuty の設計当初は、Namespace ごとにログベースの指標やアラートポリシーを作成していなかったため、すべてのアラート通知が1つのエスカレーショングループに連携されていました。
そのため、オンコール担当者の負担が高くなっていただけでなく、オンコールを受けたOpsチームが問題の切り分けを行い、担当するスクラムチームに連絡するという無駄な時間がありました。
しかし、この記事で書いたように Namespace ごとに通知先をカスタマイズすることで、オンコール担当者の負担を分散し、アラート内容の判断までの時間を短縮することができました。
サービスやエスカレーションポリシーを柔軟に設定できる PagerDuty だからこそ実現できたと考えています。
最後に
最後まで読んでいただきありがとうございました。
決済サービスというミッションクリティカルなサービスにおける運用において、 PagerDuty を用いることでインシデントの検知から解析までのスピードを早めることができました。
今回は大規模アジャイル組織におけるPagerDutyの活用というテーマで書いてみましたが、参考になれば幸いです。
宣伝
また、PagerDuty 様の事例紹介ページにも記事がありますので是非ご覧になってください。