はじめに
この記事は GCP(Google Cloud Platform) Advent Calendar 2023 21日目です![]()
本記事では Cloud Spanner に Dataflow を用いて大量のデータを積み込む方法について書いていきます。
Cloud Spanner とは
■概要
Cloud Spannerは、Google Cloudが提供するフルマネージド型の分散リレーショナルデータベースです。高い拡張性、強力な一貫性、そして信頼性の高いパフォーマンスを特徴としています。
■主な特徴
- グローバルな分散
地理的に分散されたリージョンにまたがるデータのレプリケーションをサポートし、高い可用性を実現 - 強力な一貫性
トランザクションのACID特性を保持し、強力な一貫性を提供 - スケーラビリティ
トランザクションの量に応じて自動的にスケールアップ・ダウン
Dataflow とは
■概要
Dataflowは、ストリームおよびバッチデータ処理を簡単に行えるフルマネージド型のサービスです。Apache Beamのプログラミングモデルを採用しており、データの変換や集計などの処理を効率的に実行できます。
■主な特徴
- フルマネージドサービス
サーバーの管理や設定の必要がなく、データ処理に集中できる - スケーラビリティ
必要に応じてリソースを自動的にスケールアップ・ダウン - リアルタイム処理とバッチ処理
ストリーミングデータとバッチデータの両方を処理可能
Cloud Spannerへのデータ積み込み
SQLやgcloudコマンドを使用してデータを挿入することはもちろん可能ですが、大量データには適していません。以下がその理由です。
-
CLIとコンソール両方でクエリ文字数の制限がある
ERROR: spanner: code = "InvalidArgument", desc = "Query string length of XXXXXXX exceeds maximum allowed length of 1048576." -
コンソールからのクエリ実行時間は5分に制限されている
クエリは失敗しました: コンソールからのクエリは 5 分に制限されていますが、クエリの実行に時間がかかりすぎました。長いクエリには gcloud を使用します。 -
gcloudコマンドだと時間がかかる & 動作が不安定
①gcloud spanner rows insert コマンド
→筆者環境では800レコードを20分程度
②gcloud spanner databases execute-sql コマンド
→筆者環境では1000レコードを3分程度
今回は Spanner に1000万レコードのデータを詰め込みたかったので、上記のやり方では厳しいものがありました。
そこで利用したのがGoogleが提供する Dataflow の 「Cloud Storage Avro to Cloud Spanner」 というテンプレートです。
ここからは、このテンプレートを実行する手順について解説します。
また、下記の公式docに必要なロールや注意事項などが書いてあるので、本記事と併せて読んでみてください。
インポートに必要なファイルを作成
インポートに必要なファイルは大きく以下の3種類です。
- spanner-export.json
- {TableName}-manifest.json
- {TableName}.avro-#####-of-#####
spanner-export.jsonはテーブル数だけ name と manifestFile を書く必要があります。
{
"tables": [{
"name": "{TableName}",
"manifestFile": "{TableName}-manifest.json"
}]
}
{TableName}-manifest.jsonはテーブル数だけファイルを用意する必要があります。
また、各テーブルごとavroファイルの数で、ファイル名末尾を変えてあげる必要があります。
テーブルに対してavroファイルが1つしかない場合は、00000-of-00001となり、2つあるときは下記のように書きます。
{
"files": [
{
"name": "{TableName}.avro-00000-of-00002",
"md5": "{MD5チェックサム値}"
},{
"name": "{TableName}.avro-00001-of-00002",
"md5": "xxxxxxxxxxxxxxxxxxxxxx=="
}
]
}
avroファイルはスキーマ定義を持つバイナリデータで、普通に見ようとしても中身を見ることができません。VSCodeの拡張機能で見ることができるらしいのですが、筆者の手元では見ることができず、以下の IntelliJ IDEA の Plugin で中身の確認を行っていました。
また、スキーマ定義をイチから書くのはキツイので、筆者はDataflowの 「Cloud Spanner to Cloud Storage Avro」テンプレートを使い一度エクスポートするという作業を挟みました。
avro生成
avroファイルの生成方法はいくつかあると思いますが、2つのパターンを試したのでご紹介します。
①avro-tools
スキーマ情報を定義した.avscファイルと、レコード部分を記述した.jsonファイルから avroファイルを生成することができます。
それぞれのファイルは以下のような形式で記述します。
{
"type" : "record",
"name" : "{TableName}",
"namespace" : "spannerexport",
"fields" : [ {
"name" : "columA",
"type" : "string",
"sqlType" : "STRING(26)"
}, {
"name" : "columB",
"type" : "long",
"sqlType" : "INT64"
},{
"name" : "columC",
"type" : "string",
"sqlType" : "TIMESTAMP"
} ],
"googleStorage" : "CloudSpanner",
"spannerPrimaryKey" : "`columA` ASC",
"spannerPrimaryKey_0" : "`columA` ASC",
"googleFormatVersion" : "1.0.0"
}
{"columA":"spanner","columB":1,"columC":"2023-12-20T17:59:09.871921+09:00"}
{"columA":"dataflow","columB":2,"columC":"2023-12-20T17:59:09.872066+09:00"}
生成は以下のコマンドで可能です。
# インストール
brew install avro-tools
# avroファイル生成
avro-tools fromjson --schema-file hoge.avsc hoge.json > {TableName}.avro-00000-of-00001
②goavro
golangのコードを書くことでavroファイルを生成することができます。
avroを生成できそうなパッケージはいくつかあるものの、上手く生成できないものもあり、最終的に採用したのがこのパッケージでした。
MD5チェックサム値出力
avroファイルを自作した場合、{TableName}-manifest.jsonに記述するmd5を知る必要があります。
以下はpythonでファイルのMD5チェックサム値を出力してくれるサンプルスクリプトです。
import hashlib
import base64
with open("{TableName}.avro-00000-of-00001", "rb") as f:
md5 = str(base64.b64encode(hashlib.md5(f.read()).digest())).lstrip('b').replace("'","")
print("{TableName}.avro-00000-of-00001:"+ md5)
GCSに配置
ファイルが生成できたら任意のGCSバケットに格納します。
Dataflow実行
テンプレートを使ってdataflowを実行します。
実行方法は以下のようにいくつかあります。
- コンソール
- gcloudコマンド
- REST API
- terraform
筆者は REST API 以外の3つの方法を試しました。
gcloudコマンドから実行する場合は以下のように実行します。
gcloud dataflow jobs run {ジョブ名} \
--gcs-location gs://dataflow-templates/latest/GCS_Avro_to_Cloud_Spanner \
--region asia-northeast1 \
--staging-location {一時的なファイルを書き込むためのGCSバケットのパス} \
--network {ネットワーク名} \
--subnetwork regions/asia-northeast1/subnetworks/{サブネットワーク名} \
--parameters \
instanceId={インスタンスID},\
databaseId={データベースID},\
inputDir={ファイルを格納したGCSバケットのパス}
terraformから実行する場合は以下のように書きます。
resource "google_dataflow_job" "{hoge}" {
name = "{ジョブ名}"
region = "asia-northeast1"
project = "{プロジェクト名}"
template_gcs_path = "gs://dataflow-templates/latest/GCS_Avro_to_Cloud_Spanner"
temp_gcs_location = "{一時的なファイルを書き込むためのGCSバケットのパス}"
network = "{ネットワーク名}"
subnetwork = "regions/asia-northeast1/subnetworks/{サブネットワーク名}"
parameters = {
instanceId = "{インスタンスID}"
databaseId = "{データベースID}"
inputDir = "{ファイルを格納したGCSバケットのパス}"
}
}
コンソールから実行する場合は、Dataflowのコンソール画面から「ジョブ」タブを押下し、画面上部の「テンプレートからジョブを作成」を押下します。
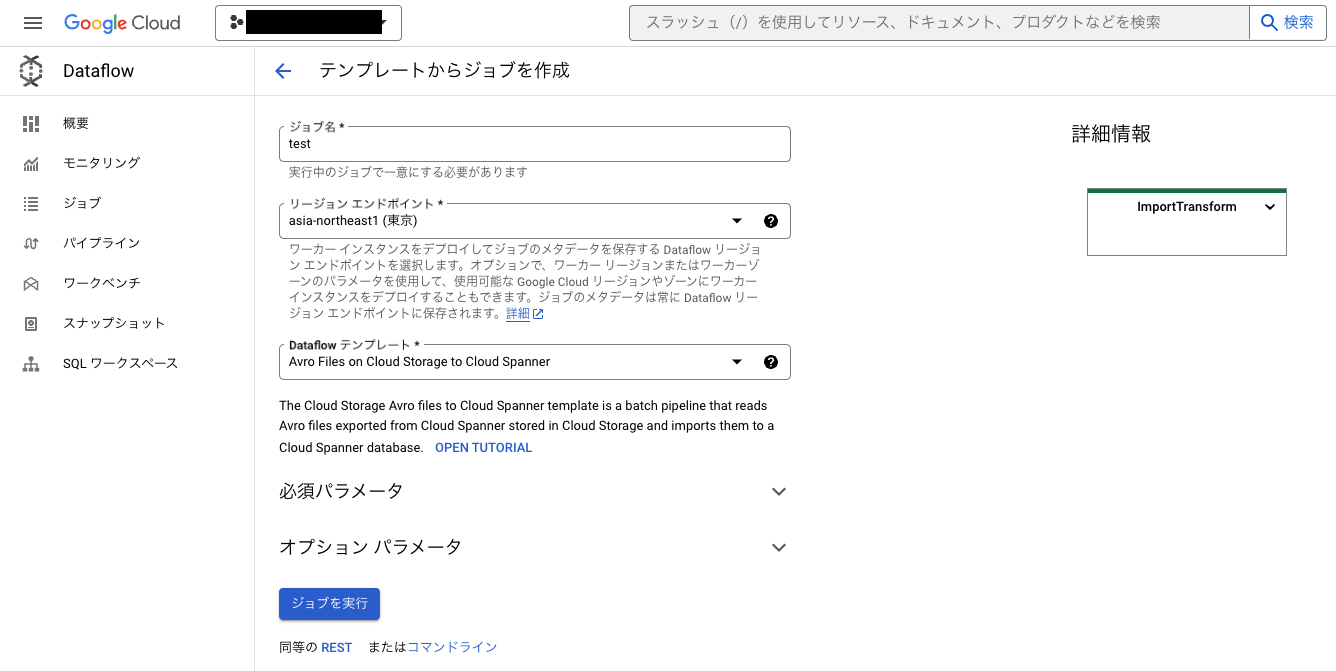
以下のような画面に遷移するので必要事項を埋めて「ジョブを実行」を押下するとDataflowが動き出します。
必須パラメータを埋めただけだと、ネットワークとサブネットワークが「デフォルト」になってしまっているので、必要に応じてオプションパラメータから指定するようにしましょう。
ジョブを実行するとコンソールのタブ「ジョブ」画面に表示されるはずです。
あとはジョブが終わるまで放置しましょう。エラー終了した場合は、ジョブの詳細画面にあるログからエラー原因を調査できます。

1時間20分程で1000万件のデータ積み込みが完了しました👏
この値はテーブルのスキーマやインデックス、インターリーブの有無、Spannerの処理ユニット等様々な要因で変わると思いますが、1つの参考値としていただけたら幸いです。
終わりに
最後まで読んでいただきありがとうございます。
今回は Dataflow を用いた Cloud Spanner への大量データ積み込みというテーマで書いてみました。
Dataflow のテンプレートは他にもありますし、自分でテンプレートを作成することもできるので、これからも色々試してみようと思います!