はじめに
本記事では、WSL2 上の Docker を使って Ollama(ローカル LLM ランタイム)と Open WebUI(ブラウザ UI)をセットアップする手順を紹介します。
- データが外部に送信されない 完全ローカル環境
- API 費用 ゼロ
- ブラウザから ChatGPT 風に操作可能
Ollama とは?
Ollama = ローカル LLM の実行環境です。
| 項目 | 内容 |
|---|---|
| 動作場所 | 自分のマシン上(クラウド不要) |
| データ | 外部に送信されない(完全オフライン可) |
| モデル | gemma3 等のオープンソースモデルを実行 |
| 料金 | 無料 |
公式サイトはこちら https://ollama.com/
前提条件
- Windows 10/11 上で WSL2 が有効化済み
- WSL2 上に Docker Engine がインストール済み
- WSL2 のディストリビューションは Ubuntu 22.04 / 24.04 推奨
- 空きディスク容量:モデルによるが最低 10GB 以上(gemma3:12b は約 8GB)
- メモリ:8GB 以上推奨(16GB 以上が快適)
セットアップ
compose.yaml を作成
services:
ollama:
image: ollama/ollama
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama:/root/.ollama
restart: always
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
volumes:
- open-webui:/app/backend/data
environment:
- OLLAMA_BASE_URL=http://ollama:11434
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 20s
retries: 10
start_period: 120s # 初回起動の猶予時間
restart: always
volumes:
ollama:
open-webui:
コンテナを起動
docker compose up -d
起動確認
docker compose ps
docker logs -f open-webui
こんな感じで表示されれば起動完了です。
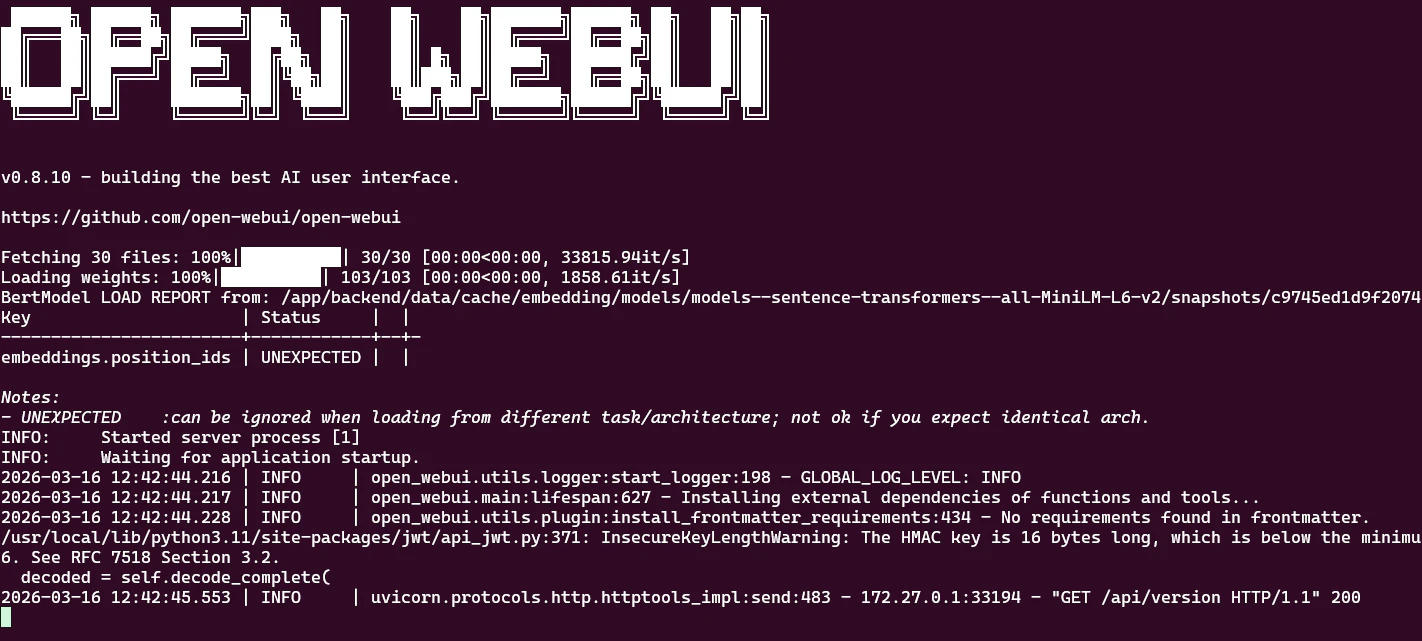
モデルのダウンロード
Open WebUI が起動したら、使いたいモデルをダウンロードします。
# 日本語対応でおすすめのモデル
docker exec -it ollama ollama pull qwen2.5 # Alibaba製
docker exec -it ollama ollama pull gemma3 # Google製
docker exec -it ollama ollama pull llama3.2 # Meta製
# ダウンロード済みモデルの確認
docker exec -it ollama ollama list
Open WebUI を使う
ブラウザで http://localhost:3000 を開きます。
初回セットアップ
1. アカウント登録(ローカルのみ・外部送信なし)
2. 画面上部「Select a model」でモデルを選択
3. チャット開始!
以下のような画面が表示されますので、ChatGPTのように使って見てください
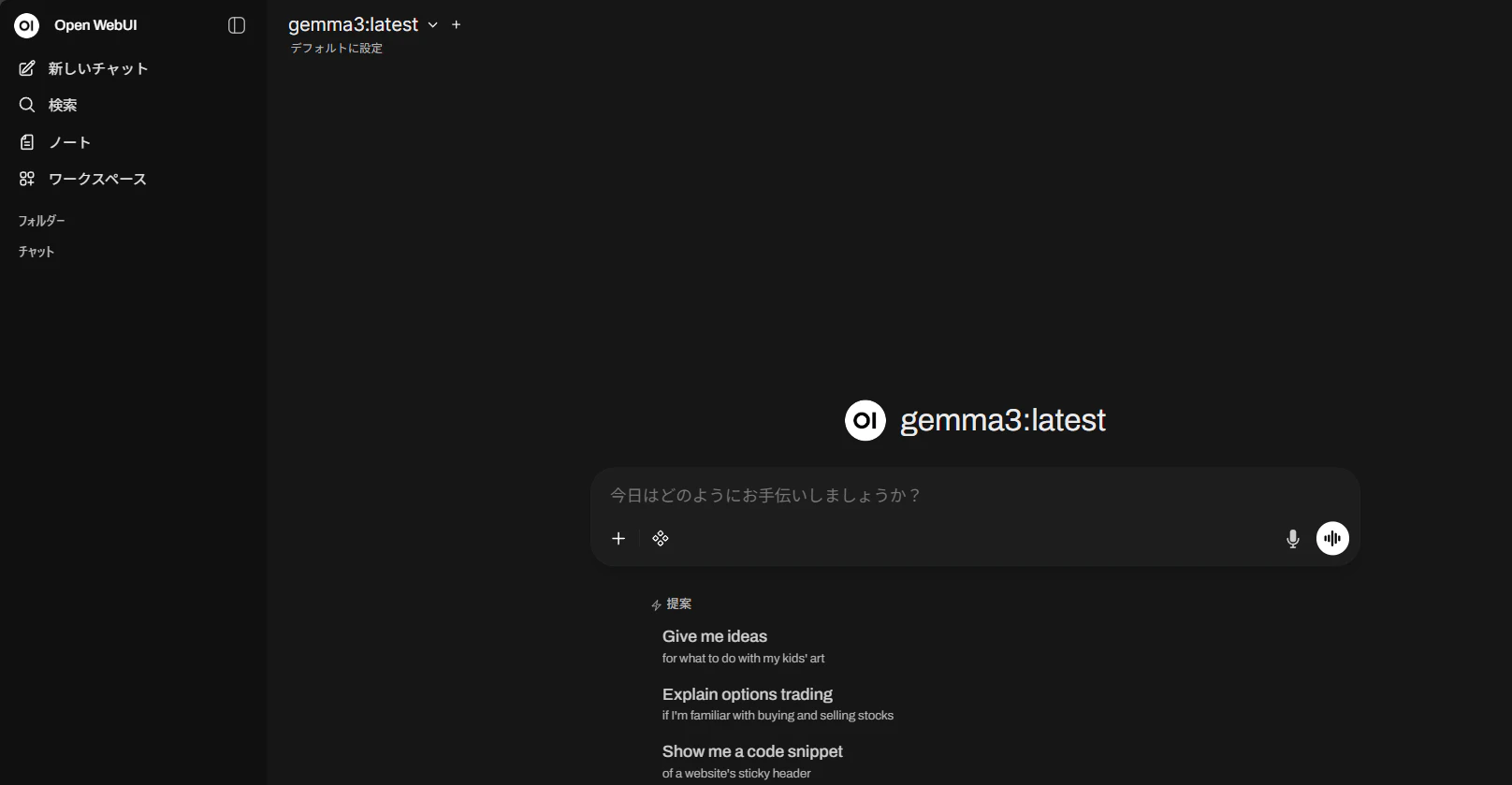
まとめ
| 項目 | 内容 |
|---|---|
| ✅ 完全ローカル | データが外部に出ない |
| ✅ 無料 | API 費用ゼロ |
| ✅ ブラウザ UI | Open WebUI で快適操作 |
| ✅ GPU 対応 | NVIDIA GPU で高速化可能(任意・なくても動作します) |
ローカル LLM 環境として、プライバシーを重視した用途や検証目的に最適です。ぜひ試してみてください!
※私はノートPCなのでGPUを設定をしていません。設定する場合はYamlの修正が必要です。