はじめに
私は高校卒業後工場勤務を5年ほどしていました。ある時友人に誘われて無料のプログラミング学習サービスを利用することになりました。それから自分が作成したプログラムがネット上に表示される事に楽しさを感じ理解を深めるためにAidemyを受講する事になりました。
本記事の概要
犬猫識別アプリの開発
アプリをご覧いただきたい方はこちらから。
・この記事は犬と猫の識別をするアプリのモデルの過程をメインに記事にしました。どのような流れでモデルが作られ、どの様な工程を踏んで一つのアプリが完成するのかがこの記事をご覧いただいたら理解出来ると思います。
・この記事は何か始めたいけどキッカケが掴めない方、IT関係に興味があるけど難しそうだからなかなか一歩を踏み出せない方が、プログラムを触るキッカケになればと思いこの記事を書かせてもらってます。
・この記事ではpythonでの開発になりますのでpython関連以外の言語等は扱いませんのでご了承ください。
まず初めに
初めに、Python・Deep Learningの実行環境に、Google Colab(GPU)を利用します。
データ収集のプログラムを実行する前に、必ずGPUに設定してください。
GPUに設定せず、CPUの状態で学習させてしまうと大変時間がかかってしまう場合がございますので注意してください。
注意
※途中GPUなどに変更した場合、その前までにインストールしていたライブラリなどは全て初期化されますので注意です。
※また、手元の環境で動作させる場合、KerasやTensorFlowなどのインストールは必要になります。
このサイトでは記載して無いので注意してください。
※さらに、画像ファイルやその他cnn.h5などの読み込みはお使いのPCの場合、ファイルのパス(PATH)を適切にする必要があります。そのためテキストのままのコードだと動作しない場合がございますのでご注意ください。
Google Colabによる環境構築の設定
1.Google Colabの初期化設定
2.学習させるデータ集め
3.学習データの作成
4.学習 (機械学習)
5.推論 (予測)
ここでは、Google Colabの初期設定としてGPUの設定をします。
Googleアカウントでログインして後に、こちらにアクセスしてください。
Google Colaboratoryの詳細設定はこちらを見ていただけたら分かりやすいと思いますので参考にしてください。
アクセスしていただくとこのような画面が出てくると思いますので、「ノートブックの新規作成」を選びクリックしてください。


横向いた三角ボタンの横にテキストエディタがありますのでそこにプログラムを記述していきます。
print("hello python")
作成したノートブックは、自動的にGoogle Driveに保存されます。

GPUの設定
ノートブック新規作成時はGPUでは無いので下記の方法でGPUを設定してください。
上部メニューの ランタイム > ランタイムのタイプを変更を選択。
ハードウェアアクセラレータ を None から GPU に変更して保存します。

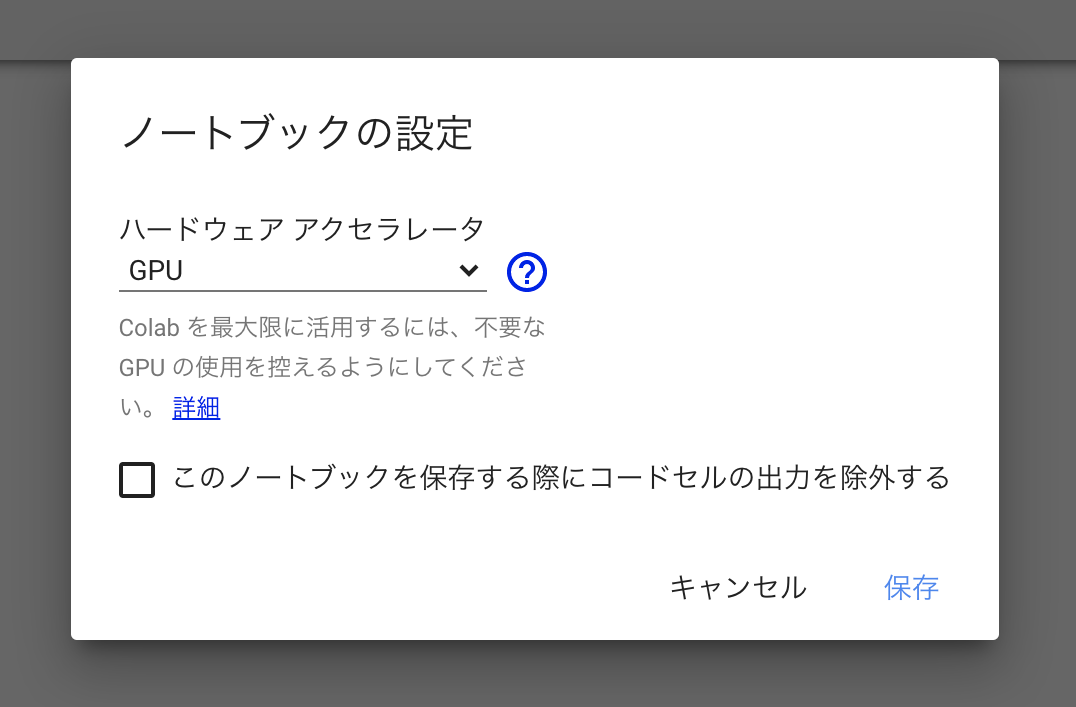
保存できましたらGPUの設定は完了です。
犬と猫の画像の収集
画像をネットから集めるプログラムをインストールするために、Pythonの画像収集ライブラリをGoogle Colabにインストールします。
Google Colabのセルで下記コマンドを入力&実行すると、インストールが開始されます。
!pip install icrawler
次に画像を収集するプログラムを書きます。
下記を実行すると、catフォルダが作成され、100枚の画像が収集できます。
from icrawler.builtin import BingImageCrawler
# 猫の画像を100枚取得
crawler = BingImageCrawler(storage={"root_dir": "cat"})
crawler.crawl(keyword="猫", max_num=100)
次に犬の画像を100枚収集します。
from icrawler.builtin import BingImageCrawler
# 犬の画像を100枚取得
crawler = BingImageCrawler(storage={"root_dir": "dog"})
crawler.crawl(keyword="犬", max_num=100)
同様に上記実行すると、dogフォルダが作成され100枚の画像が収集出来ます。
ここまでで、100枚猫と犬の画像をダウンロードする事ができました。
それでは、そのうち1枚の猫の画像を表示してみます。
# 猫の画像を表示
from IPython.display import Image,display_jpeg
display_jpeg(Image("./cat/000001.jpg"))

データの整形と学習データの作成
画像をダウンロードしたので、次に入力データ(画像)の前処理とデータの分割を行います。
from PIL import Image
import os, glob
import numpy as np
from PIL import ImageFile
# IOError: image file is truncated (0 bytes not processed)回避のため
ImageFile.LOAD_TRUNCATED_IMAGES = True
classes = ["dog", "cat"]
num_classes = len(classes)
image_size = 64
num_testdata = 25
X_train = []
X_test = []
y_train = []
y_test = []
for index, classlabel in enumerate(classes):
photos_dir = "./" + classlabel
files = glob.glob(photos_dir + "/*.jpg")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
if i < num_testdata:
X_test.append(data)
y_test.append(index)
else:
# angleに代入される値
# -20
# -15
# -10
# -5
# 0
# 5
# 10
# 15
# 画像を5度ずつ回転
for angle in range(-20, 20, 5):
img_r = image.rotate(angle)
data = np.asarray(img_r)
X_train.append(data)
y_train.append(index)
# FLIP_LEFT_RIGHT は 左右反転
img_trains = img_r.transpose(Image.FLIP_LEFT_RIGHT)
data = np.asarray(img_trains)
X_train.append(data)
y_train.append(index)
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
xy = (X_train, X_test, y_train, y_test)
np.save("./dog_cat.npy", xy)
numpyのsave()によって、dog_cat.npyというファイル名で、データセットが作成出来ました。
1行目のPILはPython Imaging Librarという画像処理のためのライブラリになります。
学習
ここでは認識モデルを作るためのメインのプログラムになります。
このプログラムを実行すると、機械学習を行います。
(機械学習では学習と推論の2つの工程があり、ここでは学習にあたります。)
グーグルコラボラトリーのランタイムをGPUにしている場合、1分かからない程で学習が終わります。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.optimizers import RMSprop
from keras.utils import np_utils
import keras
import numpy as np
classes = ["dog", "cat"]
num_classes = len(classes)
image_size = 64
# データを読み込む関数
def load_data():
X_train, X_test, y_train, y_test = np.load("./dog_cat.npy", allow_pickle=True)
# 入力データの各画素値を0-1の範囲で正規化(学習コストを下げるため)
X_train = X_train.astype("float") / 255
X_test = X_test.astype("float") / 255
# to_categorical()にてラベルをone hot vector化
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
return X_train, y_train, X_test, y_test
# モデルを学習する関数
def train(X, y, X_test, y_test):
model = Sequential()
# Xは(1200, 64, 64, 3)
# X.shape[1:]とすることで、(64, 64, 3)となり、入力にすることが可能です。
model.add(Conv2D(32,(3,3), padding='same',input_shape=X.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.1))
model.add(Conv2D(64,(3,3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.45))
model.add(Dense(2))
model.add(Activation('softmax'))
# https://keras.io/ja/optimizers/
# 今回は、最適化アルゴリズムにRMSpropを利用
opt = RMSprop(lr=0.00005, decay=1e-6)
# https://keras.io/ja/models/sequential/
model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=['accuracy'])
model.fit(X, y, batch_size=28, epochs=40)
# HDF5ファイルにKerasのモデルを保存
model.save('./cnn.h5')
return model
# メイン関数データの読み込みとモデルの学習を行います。
def main():
# データの読み込み
X_train, y_train, X_test, y_test = load_data()
# モデルの学習
model = train(X_train, y_train, X_test, y_test)
main()
上記、プログラムをグーグルコラボラトリーのGPU環境の場合、数分で処理が終わります。
処理が終わると、cnn.h5がColab上に生成されます。
推論
予測させたい「犬」や「猫」の画像をダウンロード&アップロードしましょう。
次のプログラムを貼り付けて、実行しダウンロードした画像をアップロードしましょう。
ファイルタブのアップロードから下記画像をアップロードします。

今回は、ダウンロードした犬の画像をdog1.jpgというファイル名でアップロードし、変数testpic に代入します。
画像はこちらからダウンロード可能です。

import keras
import sys, os
import numpy as np
from keras.models import load_model
imsize = (64, 64)
"""
dog1.jpgというファイル名の画像をGoogle Colab上にアップロードする方法は2通りあります。
1つが、下記のコードを実行し画像をアップロードする方法
from google.colab import files
uploaded = files.upload()
2つが、Colab左メニューの>アイコンを押して、目次、コード スニペット、ファイル
の3つ表示されるますが、右のファイルタブから画像をアップロードする方法です。
このファイルタブをクリックするとアップロードと更新の2つがありますが、
アップロードを押すと画像をアップロードすることが可能です。
"""
testpic = "./dog1.jpg"
keras_param = "./cnn.h5"
def load_image(path):
img = Image.open(path)
img = img.convert('RGB')
# 学習時に、(64, 64, 3)で学習したので、画像の縦・横は今回 変数imsizeの(64, 64)にリサイズします。
img = img.resize(imsize)
# 画像データをnumpy配列の形式に変更
img = np.asarray(img)
img = img / 255.0
return img
model = load_model(keras_param)
img = load_image(testpic)
prd = model.predict(np.array([img]))
print(prd) # 精度の表示
prelabel = np.argmax(prd, axis=1)
if prelabel == 0:
print(">>> 犬")
elif prelabel == 1:
print(">>> 猫")
先ほどの犬の画像を予測させて見ると、次のように正しく認識できています。

※万が一上記の推論のプログラムで、cnn.h5が存在しないというようなエラーが出た場合、うまく学習フェースのセクションのプログラムが動いていないかと思います。
その場合は、こちらからcnn.h5をダウンロードしご利用ください。
>>> 犬
念のために猫の画像でも検証を行います。
犬の画像と同様の方法で以下の猫の画像「cat1.jpg」をアップロードし、変数testpicを「./dog1.jpg」から「./cat1.jpg」に変更し、先ほどのコードを再度実行します 。
猫の画像は、インターネットからお好きなものをダウンロードしてアップロードしてください。
>>> 猫
猫も同様に正しく判別ができました。
ディープラーニングでは通常数千〜数万のデータ数で学習を行うのが一般的ですが、今回はデータ収集の都合上100枚以下のデータ数で学習を行ったため、実はモデルの精度はあまり高くなく画像によっては誤識別してしまいます。
もし、より精度を上げたい場合には画像収集時の引数max_numを増やすことで学習に使うデータ数を増やして再学習させてみましょう。
モデルの方は完成しましたので、その後作成していた下記の「Flask」「HTML」「CSS」のコードを作成。
Flaskのコード
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["cat","dog"]
image_size =64
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./cnn.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
HTMLのコード
<!DOCTYPE html>
<html lang='ja'>
<head>
<meta charset='UTF-8'>
<meta name='viewport' content="device-width, initial-scale=1.0">
<meta http-equiv='X-UA-Compatible' content="ie=edge">
<title>DOG or CAT</title>
<link rel='stylesheet' href="./static/stylesheet.css">
</head>
<body>
<header>
<img class='header_img' src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class='header-logo' href="#">DOG or CAT</a>
</header>
<div class='main'>
<h2> AIが犬と猫を見分けます</h2>
<p>画像を送信してください</p>
<form method='POST' enctype="multipart/form-data">
<input class='file_choose' type="file" name="file">
<input class='btn' value="submit!" type="submit">
</form>
<div class='answer'>{{answer}}</div>
</div>
<footer>
<img class='footer_img' src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2019 Aidemy, inc.</small>
</footer>
</body>
</html>
CSSのコード
header {
background-color: #76B55B;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 370px;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}
最後に
このようにdogcat_appフォルダに格納


最後にターミナルを開いて

上の画像のオレンジで囲われた部分を検索すると…

犬猫識別のアプリが完成している事がわかります。
アプリを作成してみて
アプリの開発内容は自由だったので私は犬も猫も飼っているいるので犬と猫の識別アプリを作成することに決めました。アプリを開発する上で一番大事だと思ったことはモデルを作る過程で、モデルの出来次第でアプリの完成度はだいぶ変わってくる事に気付かされました。
今回は凝った内容のアプリを作成する事ができなかったのですが、次アプリを作成する際には今回の経験を生かしさらに完成度の高いアプリを作成しようと思います。
最後に
Aidemyを受講しプログラムについて学べたことは私にとって良い経験になりました。プログラマーといえば独学で取得したり無料のサイトで勉強する事も可能ですが、お金を払って受講する事によって中途半端に理解が追いつかずに挫折する事もなく、理解できないところはチューターにカウンセリングをしてもらい問題解決することでモチベーションを保ち最後までやり抜く事ができました。