はじめに
- こちらは私自身の機械学習やディープラーニングの勉強記録のアウトプットです。
- 今回はGoogle Colaboratoryで画像データの2種分類を行います。柴犬の写真から「うちの子(愛犬)」「うちの子(愛犬)以外」を判定します。
- 様々なエラーでつまずいた箇所などもできる限り記述し、なるべく誰でも再現がしやすいように記載します。
- qiitaには初めての記事投稿になりますので、お気づきの点や修正点などありましたら、教えていただけると幸いです。
この記事の対象者
- ディープラーニングの勉強をしていて、いろんな分析をしてみたいが、知識や情報が足りなくてGoogle Colaboratoryやその周辺でいろいろとつまずいて、思うように分析が進まない方(バリバリの上級者向けの記事ではありません!)
- あと柴犬好きの方はぜひ!!
私について
- 2018年から機械学習の勉強を始め、2019年以降はディープラーニングを中心に、主に勤務のない土日に勉強を進めている社会人です。
- これまでエンジニア経験はなく事務一筋に社会人生活をやってきました。実務で機械学習などを活用する機会は全くないのですが、勉強すればするほど、この分野の奥の深い魅力にずぶずぶとハマっていき、2019年9月にJDLA Deep Learning for Engeneer 2019#2を取得しました。
- 様々なディープラーニングの分析経験を積みたいと思い、現在は実データを使用したケース分析などに参加させてもらっております。
- 2020年3月いっぱいで勤続18年の公務員を退職し、4月からはデータエンジニアにジョブチェンジします。
参考にした文献
-
 『PythonとKerasによるディープラーニング』
『PythonとKerasによるディープラーニング』 Francois Chollet著 株式会社クイープ訳 巣籠悠輔監訳 株式会社マイナビ出版刊
Francois Chollet著 株式会社クイープ訳 巣籠悠輔監訳 株式会社マイナビ出版刊 - この本の著者**Chollet氏のgithub** にこの文献のソースコードが公開されています。
- 今回は5.2-using-convnets-with-small-datasets.ipynbをベースに分析をしていきます。
(余談ですが、機械学習については2018年に某スクールで監訳者の巣籠先生の講義を受けておりました)
事前の準備
- Google Accountを持っている必要があります。
- 持っていない方は**こちらの記事**を参考に、あらかじめ自分自身のアカウントを取得してください。
手順の概要
手順1 分析用の写真を集め、リサイズして、Google Driveにzip形式でアップする
手順2 Google Drive上に作業用フォルダを作成し、データを解凍する。
手順3 柴犬の写真(各50枚)から所定枚数だけtrain,test,validationの各フォルダにコピーする。
手順4 モデル構築
手順5 学習
手順6 結果
手順7 Data Augumentation
手順8 その他調整結果(画像の入力サイズの変更等)
うちの子について

まず分析手順を進める前にうちの子を紹介させてください。2020年1月現在で16歳の雌の柴です。名前はみりんといいます。命名は私の妻ですが、和犬なので和風の名前にしたということでした。もう、このみりんがかわいくてかわいくて!
後ほど出てくる分析データのzipファイル(mydog)にこのみりんのかわいい写真がたくさん入っています。ぜひこちらもご覧いただき、うちのみりんのいろんな表情を一緒に楽しんでいただければと思います(←親バカ)
具体的な手順
手順1 分析用の写真を集め、リサイズして、Google Driveにzip形式でアップする
(1) 柴犬の写真集め
-
ネットで版権フリーな柴犬の写真を集めます。だいたいこの辺のサイトから持ってきました。海外のサイトで検索する際には、検索語句が"Shiba Inu"というワードで写真が出てきます。
pixabay
unsplash
Gahag
写真素材 足成
フリー素材ドットコム -
複数のフリー素材サイトを横断的に検索できるこちらのサイトも便利でした。
O-DAN -
みりんの写真は自分のスマホやデジカメのフォルダなどから集めました。その際に、特徴量がばらつかないように、写真の期間としては子犬時代などを一応外して、12歳~16歳(現在)の期間に絞って選択しました。
(2) 画像のトリミング、リサイズ
- 個々の画像は写真写りが様々なため、そのままデータとして使用するには不向きです。そこでなるべく1枚の画像内に犬の要素のみを含んでいる割合が高くなるようにトリミングしました。フォトレタッチソフト(Photoshop Elements,gimpなど)を使用し、縦横比1:1で、画像サイズは気にせずどんどん切り出し、画像ファイル(jpgファイル)として保存します。
- 切り出したファイルは**縮専などのソフトを使用し、今回は320×320ピクセルの画像として一括でリサイズします。画像ファイルの一括リネームにはFlexRena84**を使用しました。
- こうしてみりん60枚、他の柴犬60枚、計120枚の画像ファイルを用意し、それぞれ"mydog" "otherdogs"と名前を付けたフォルダに格納し、フォルダごとzipファイルにしておきます。
何枚か写真を掲示します。
みりんの写真(mydog)




他の柴犬の写真(otherdogs)




(3)Google Driveにアップロード
- あらかじめGoogle drive内にデータを格納するフォルダを作成します。
- 図は私のディレクトリの構成例です。(実際にはオレンジ色のフォルダを使って作業をしていきます)これと同じ構成で実行すればソースコードはそのままで動くと思います。
-
"mydog1.zip" **"otherdogs1.zip"の2つのzipファイルをGoogle Drive("original_data"**フォルダ)にアップロードします。

手順2 Google Drive上に作業用フォルダを作成し、データを解凍する。
ここからは実際にGoogle Colaboratoryを起動してColab上で操作していきます。
(1) まずはGoogleDriveをマウントします。
初めての方は**こちら**を参考にしてください。
# Google Driveマウント
from google.colab import drive
drive.mount('/content/drive')
(2) カレントディレクトリを作業するフォルダに変更して、zipファイルを解凍します。
# cd '/content/drive/'My Drive/'Colab Notebooks'内の作業フォルダへカレントディレクトリを変更
%cd '/content/drive/'My Drive/Colab Notebooks/Self_Study/02_mydog_or_otherdogs/original_data
# mydog1.zipの解凍
!unzip "mydog1.zip"
# otherdogs1.zipの解凍
!unzip "otherdogs1".zip"
# 解凍したファイル数の確認
!ls ./original_data/mydog1 | wc -l
!ls ./original_data/otherdogs1 | wc -l
**注) データは圧縮したものをGoogle Driveにアップロードしてから解凍すること。**圧縮せずに直接Google Driveにアップロードするやり方でも一度やってみましたが、時間がかなりかかります。colaboratory上で操作をするので、解凍コマンドは「!」で始まるLinuxコマンドを使用します。

こんな感じのメッセージが出てきて、ファイルが解凍されます。
手順3 柴犬の写真(各60枚)から所定枚数だけtrain,test,validationの各フォルダにコピーする。
(1) 画像ファイルをコピーするためのファイルパスを設定するとともに、使用するフォルダを新規に作成します。
# 必要なライブラリの読み込み
import os, shutil
# 必要なファイルパスを定義する
# cd '/content/drive/'My Drive/'Colab Notebooks'内の作業フォルダへカレントディレクトリを変更
%cd '/content/drive/'My Drive/Colab Notebooks/Self_Study/02_mydog_or_otherdogs
# original_dataフォルダのファイルパスの設定
original_dataset_dir = 'original_data'
# original_data(定義名'original_dataset_dir')内に次の2つのフォルダパスを設定する。
original_mydog_dir = 'original_data/mydog'
original_otherdogs_dir = 'original_data/otherdogs'
# use_dataのファイルパスの設定
base_dir = 'use_data'
# use_dataフォルダ(定義名'base_dir')内に次の3つのフォルダパスを設定する。フォルダを作成する。
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# trainフォルダ内に'mydog'フォルダと'otherdogs'フォルダのパスを設定する。フォルダを作成する。
train_mydog_dir = os.path.join(train_dir, 'mydog')
os.mkdir(train_mydog_dir)
train_otherdogs_dir = os.path.join(train_dir, 'otherdogs')
os.mkdir(train_otherdogs_dir)
# validationフォルダ内に'mydog'フォルダと'otherdogs'フォルダのパスを設定する。フォルダを作成する。
validation_mydog_dir = os.path.join(validation_dir, 'mydog')
os.mkdir(validation_mydog_dir)
validation_otherdogs_dir = os.path.join(validation_dir, 'otherdogs')
os.mkdir(validation_otherdogs_dir)
# testフォルダ内に'mydog'フォルダと'otherdogs'フォルダのパスを設定する。フォルダを作成する。
test_mydog_dir = os.path.join(test_dir, 'mydog')
os.mkdir(test_mydog_dir)
test_otherdogs_dir = os.path.join(test_dir, 'otherdogs')
os.mkdir(test_otherdogs_dir)
(2) ファイルコピーを実施し、コピーしたファイル数を確認します。
# train用にtrain_mydog_dirにmydogファイルを30個コピー
fnames = ['mydog{}.jpg'.format(i) for i in range(30)]
for fname in fnames:
src = os.path.join(original_mydog_dir, fname)
dst = os.path.join(train_mydog_dir, fname)
shutil.copyfile(src, dst)
# validation用にvalidation_mydog_dirにmydogファイルを20個コピー
fnames = ['mydog{}.jpg'.format(i) for i in range(30,50)]
for fname in fnames:
src = os.path.join(original_mydog_dir, fname)
dst = os.path.join(validation_mydog_dir, fname)
shutil.copyfile(src, dst)
# test用にtest_mydog_dirにmydogファイルを10個コピー
fnames = ['mydog{}.jpg'.format(i) for i in range(50,60)]
for fname in fnames:
src = os.path.join(original_mydog_dir, fname)
dst = os.path.join(test_mydog_dir, fname)
shutil.copyfile(src, dst)
# train用にtrain_otherdogs_dirにotherdogsファイルを30個コピー
fnames = ['otherdogs{}.jpg'.format(i) for i in range(30)]
for fname in fnames:
src = os.path.join(original_otherdogs_dir, fname)
dst = os.path.join(train_otherdogs_dir, fname)
shutil.copyfile(src, dst)
# validation用にvalidation_otherdogs_dirにotherdogsファイルを20個コピー
fnames = ['otherdogs{}.jpg'.format(i) for i in range(30, 50)]
for fname in fnames:
src = os.path.join(original_otherdogs_dir, fname)
dst = os.path.join(validation_otherdogs_dir, fname)
shutil.copyfile(src, dst)
# test用にtest_otherdogs_dirにotherdogsファイルを10個コピー
fnames = ['otherdogs{}.jpg'.format(i) for i in range(50, 60)]
for fname in fnames:
src = os.path.join(original_otherdogs_dir, fname)
dst = os.path.join(test_otherdogs_dir, fname)
shutil.copyfile(src, dst)
# 各フォルダに格納されているファイル数の確認
print('total training mydog images:', len(os.listdir(train_mydog_dir)))
print('total training otherdogs images:', len(os.listdir(train_otherdogs_dir)))
print('total validation mydog images:', len(os.listdir(validation_mydog_dir)))
print('total validation otherdogs images:', len(os.listdir(validation_otherdogs_dir)))
print('total test mydog images:', len(os.listdir(test_mydog_dir)))
print('total test otherdogs images:', len(os.listdir(test_otherdogs_dir)))
ファイル数は次のとおり表示されます。

手順4 モデル構築
(1)kerasをインポートし、次のとおりモデルを組みます。
入力画像の大きさは元ファイルは320320ですが、今回はインプットのサイズを150150にて読み込みます。
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
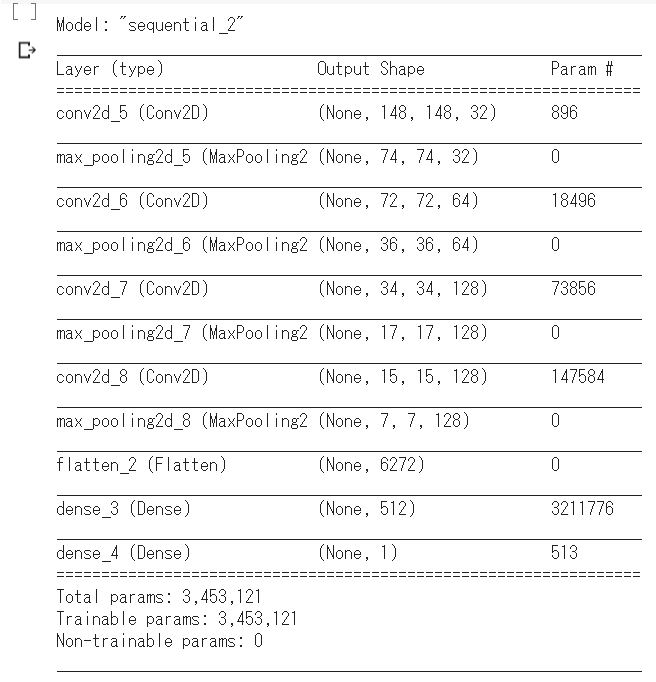
model.summary()
こんな感じでモデルの構成が表示されます。
(2) 損失関数(binary crossentropy)、オプティマイザ(RMS Prop)、監視指標(accuracy)を設定し、モデルをコンパイルします。
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
(3) kerasのライブラリImageDataGeneratorを使用して、画像ファイルをテンソルに変換します。
今回はデータオーギュメンテーションは実施無し。
from keras.preprocessing.image import ImageDataGenerator
# rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# target directory
train_dir,
# resized to 150x150
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
手順5 学習
(1) バッチジェネレーターを使用してモデルを学習させます。
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
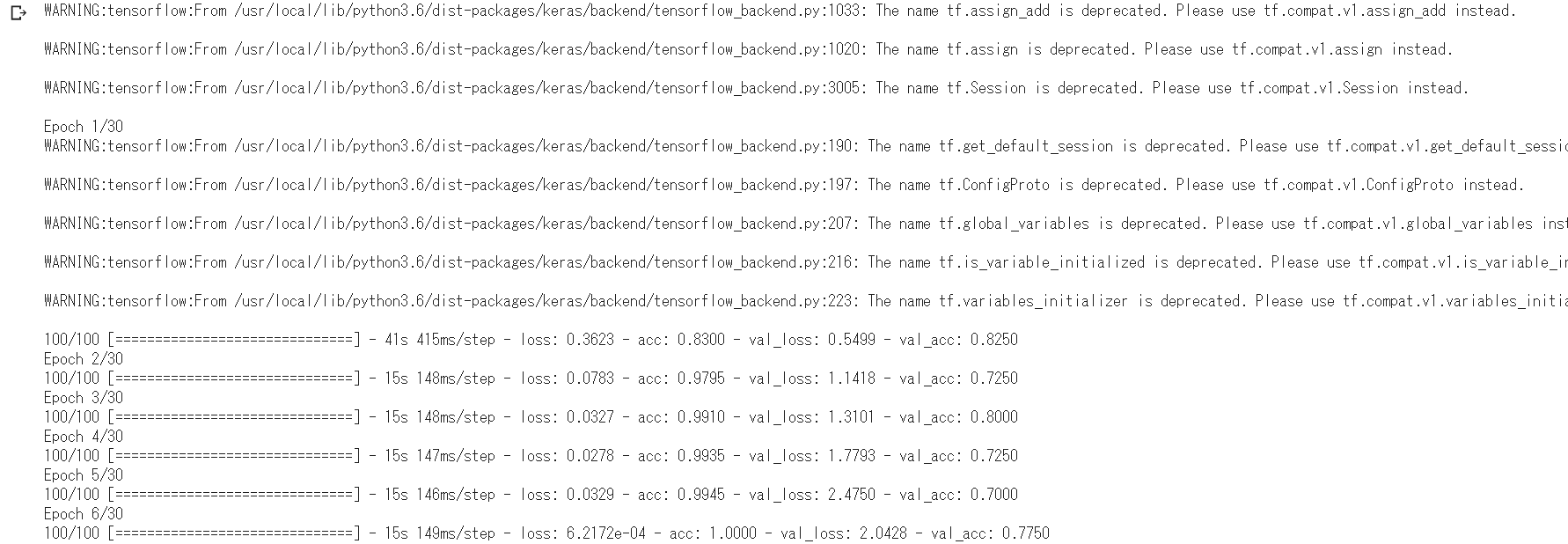
学習が始まるとこんな表示になり、計算が進んでいきます。(しばらくかかります)
(2) 学習が終わったらモデルを保存しておきます。
model.save('mydog_or_otherdogs_01a.h5')
手順6 結果
(1) 学習結果をグラフで表示
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
結果グラフ
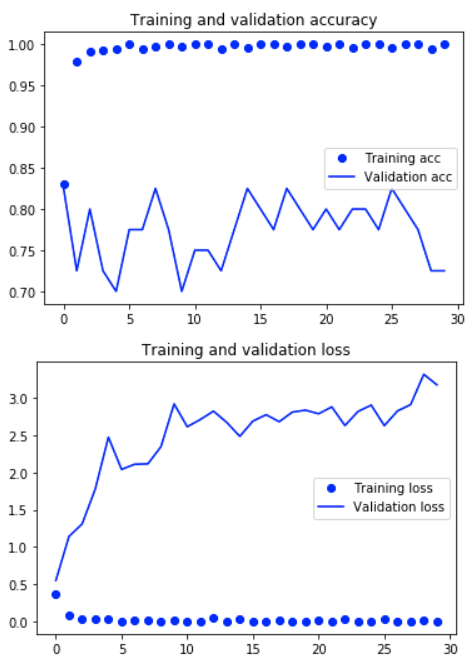
まずaccuracyですが
- traningのaccuracyが最初からすぐに100%に到達している。
- validationのaccuracyは70%~85%あたりをうろうろしており、それ以上は精度が上がっていかない。
といった特徴が見て取れます。残念ながら、trainデータのみに通用する特徴しか見ておらず、trainデータ以外でも通用するうちの愛犬のはっきりした特徴を掴んでいるとは言えない状況。
一方でlossについても
- traningのlossが最初から0近くの値となっている。
- validationのlossも回数を増すごとに下がっていかず、右肩上がりに上がっていく。
以上から、trainデータに対して過学習しています。やっぱりもともとのデータ数が少なかったため、やむを得ない結果かなというところです。
(2) テストデータへの適用
このモデルを次のコードで、テストデータに適用して分類精度を見てみます。
注)ImageDataGeneratorは、ターゲットフォルダ内に2つ以上のサブフォルダがなければコンバートをせずにエラーになります。(このケースではmydogとotherdogsの2つのサブフォルダが必要)
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150,150),
batch_size=50,
class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test loss:', test_loss)
print('test acc:', test_acc)
test loss: 2.7508722241719563
test acc: 0.7666666607062022
今回の実施結果の精度は約76%。まだまだ調整が必要です。
手順7 Data Augumentation
先ほどのモデルを引き続き使用し、trainデータに対してData Augumentation(データの水増し)を行い、再度学習させてみます。ImageDataGeneratorの水増し部分のコードは以下のとおりです。
# trainデータの水増し
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# validationデータは水増し無し
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# Target directory
train_dir,
# resized to 150x150
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
100エポックでモデルを学習します。
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
学習後のモデルを保存しておきます。
model.save('mydog_or_otherdogs_01b.h5')
結果のグラフは次のとおりです。
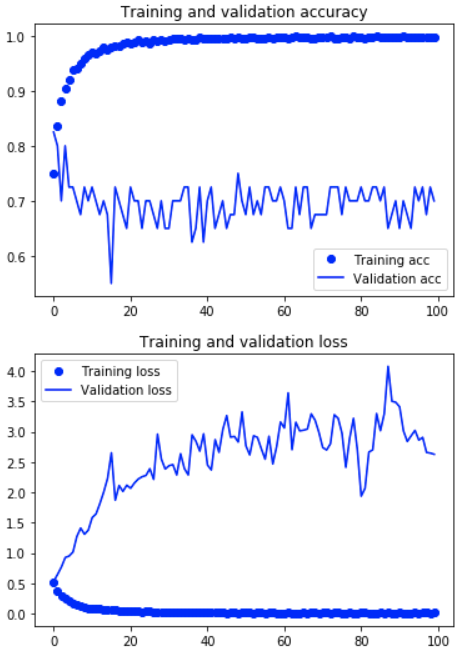
学習済みモデルをテストデータに適用して分類精度を見てみます。
test loss: 2.480180886810025
test acc: 0.7499999996026357
一般に水増しを行ったほうが精度に改善があるようですが、今回の例では先ほどに比べると、ちょっと精度は落ちてしまいました。もともとのデータサンプル数が少ないので、こういうこともあるのかと思います。
手順8 その他の調整(画像の入力サイズの変更等)
これまで入力画像のサイズを 150pixel × 150pixel で実施してきました。入力画像のサイズをもともとの大きさの 320pixel × 320pixel に変更してみたらどうなるでしょうか。これまで構築してきたモデルを使用し、①Data Augumentation なし ②Data Augumentation あり の2通りでモデルを学習させ、実施結果を見てみます。
※2020/1/4追記 数値が誤っていたので、数値を正しいものに修正し、コメントも改めました。
テストデータの分類精度は以下の結果となりました。
①の結果
test loss: 1.6523902654647826 (1.7524430536416669)
test acc: 0.75 (0.8166666567325592)
②の結果
test loss: 2.102495942115784 (1.382319548305386)
test acc: 0.75 (0.8666666634877522)
入力サイズが150pixelの時と比較して、入力サイズ320pixelでは誤差、精度共にあまり差異は見られませんでした。
次回は画像データのサンプル数を増やした場合で、再度分析したいと思います。