この記事について
この春、緊急事態宣言下で全国の動物園、水族館は休園を余儀なくされていました。
そんな中、各園が少しでもお客さんに楽しんでもらおうとSNS上で動物たちの様子を発信していました。
それが「#休園中の動物園水族館」というタグです。
このタグの投稿が少しでも広まるようにという思いから、
このタグ付きのTwitter及びInstagramの投稿を自動でリツイート及びツイートするbotを作りました。
ハッシュタグ #休園中の動物園水族館 を自動でRTするbotです。
— 休園中の動物園水族館bot (@cheer_zoo_aqua) May 9, 2020
とりあえず試運転させてます。
ここではその中身を共有します。
githubはこちら
概要
このbotのメイン機能は以下です。
- Twitterの「#休園中の動物園水族館」というタグ付きの投稿を自動RTする。
- Instagramの「#休園中の動物園水族館」というタグ付きの投稿をTwitterに自動投稿する。
それぞれ実装はPython3系で行い、インフラにはAWSのECSとLambdaを使用しています。
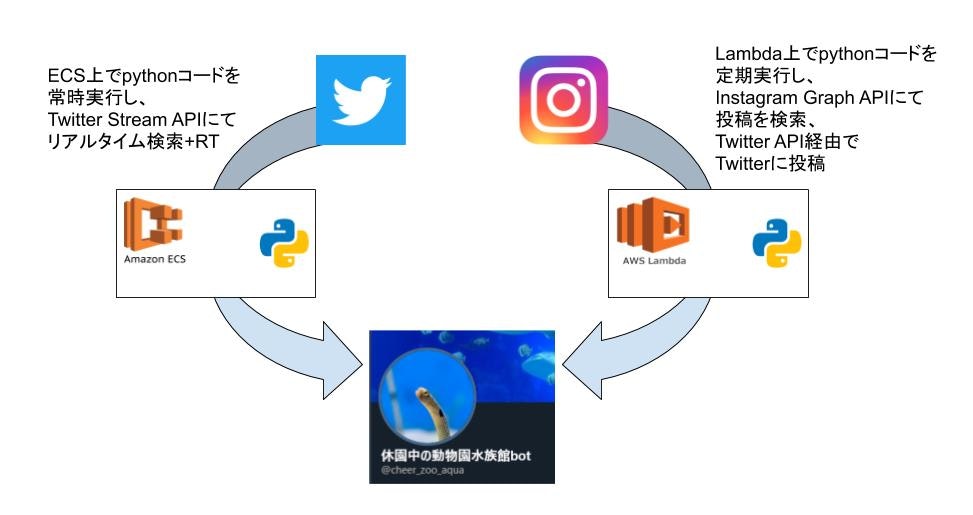
Twitter投稿の自動リツイート
このbotのメインとなる機能です。
全体コード
import tweepy
import json
import os
import traceback
# Twitter APIで使用する各種キーをセット
# API Key
consumer_key = os.environ['CON_KEY']
# API secret key
consumer_secret = os.environ['CON_KEY_SEC']
# アクセストークン
Access_token = os.environ['ACC_KEY']
# アクセストークンシークレット
Access_token_secret = os.environ['ACC_KEY_SEC']
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(Access_token, Access_token_secret)
api = tweepy.API(auth)
me = api.me()
class Listener(tweepy.StreamListener):
""" Handles tweets received from the stream. """
def on_status(self, status):
""" Prints tweet and hashtags """
if "RT" not in status.text:
""" 引用RTならファボ、そうでないならRT """
if status.is_quote_status:
try:
api.create_favorite(status.id)
except:
print('------------------------------')
print("@" + status.user.screen_name)
print(status.text)
print("")
print(traceback.format_exc())
else:
try:
if status.user.screen_name != me.screen_name:
api.retweet(status.id)
except:
print('------------------------------')
print("@" + status.user.screen_name)
print(status.text)
print("")
print(traceback.format_exc())
return True
def on_error(self, status_code):
print('Got an error with status code: ' + str(status_code))
return True
def on_timeout(self):
print('Timeout...')
return True
listener = Listener()
stream = tweepy.Stream(auth, listener)
stream.filter(track=[os.environ['QUERY']], is_async=True)
実装
このbotはPythonのライブラリ、tweepyを使用しています。
tweepy
TwitterのAPI登録を事前に実施し、
参考:Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ ※2019年8月時点の情報
- Consumer key
- Consumer Secret
- Acccess Key
- Access Secret
の4つを取得した上で、このtweepyを使用していきます。
# Twitter APIで使用する各種キーをセット
# API Key
consumer_key = os.environ['CON_KEY']
# API secret key
consumer_secret = os.environ['CON_KEY_SEC']
# アクセストークン
Access_token = os.environ['ACC_KEY']
# アクセストークンシークレット
Access_token_secret = os.environ['ACC_KEY_SEC']
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(Access_token, Access_token_secret)
api = tweepy.API(auth)
me = api.me()
上記部分にてtweepyのオブジェクトを作成しています。
(Key類は環境変数に格納しています)
各認証情報をtweepyに渡して生成した「api」というオブジェクトに対し、
各関数を使用すれば、投稿やお気に入り、RTなどができるようになります。
参考:【Python】 Tweepyで、ツイート・フォロー・リムーブ・検索・画像投稿する方法をまとめてみた
例えば、最下部のme()という関数は、tweepyにて認証したユーザの各種情報を取得できる関数です。
class Listener(tweepy.StreamListener):
""" Handles tweets received from the stream. """
def on_status(self, status):
""" Prints tweet and hashtags """
if "RT" not in status.text:
""" 引用RTならファボ、そうでないならRT """
if status.is_quote_status:
try:
api.create_favorite(status.id)
except:
print('------------------------------')
print("@" + status.user.screen_name)
print(status.text)
print("")
print(traceback.format_exc())
else:
try:
if status.user.screen_name != me.screen_name:
api.retweet(status.id)
except:
print('------------------------------')
print("@" + status.user.screen_name)
print(status.text)
print("")
print(traceback.format_exc())
return True
def on_error(self, status_code):
print('Got an error with status code: ' + str(status_code))
return True
def on_timeout(self):
print('Timeout...')
return True
listener = Listener()
stream = tweepy.Stream(auth, listener)
stream.filter(track=[os.environ['QUERY']], is_async=True)
一方で、こちらはTwitterのタイムラインをリアルタイムに検索できるようにする部分です。
参考:tweepyでリアルタイムハッシュタグ検索
tweepy側で定義されているクラス StreamListener 及びその中のメソッドを上書きすることで、
リアルタイム検索とそれに対する処理を定義していきます。
listener = Listener()
stream = tweepy.Stream(auth, listener)
stream.filter(track=[os.environ['QUERY']], is_async=True)
実際に関数が動作しているのは上記部分で、
Streamオブジェクトに上書きしたStreamListenerオブジェクトと認証情報(auth)を渡して、
リアルタイムにTwitterのタイムラインを受信できるようにします。
さらにfilter(track=["hoge"])で、タイムライン上にてhogeを含むツイートをリアルタイム抽出できます。
(ここも環境変数にしてますが、検索ワードは "#休園中の動物園水族館" です)
def on_status(self, status):
""" Prints tweet and hashtags """
if "RT" not in status.text:
""" 引用RTならファボ、そうでないならRT """
if status.is_quote_status:
try:
api.create_favorite(status.id)
except:
print('------------------------------')
print("@" + status.user.screen_name)
print(status.text)
print("")
print(traceback.format_exc())
else:
try:
if status.user.screen_name != me.screen_name:
api.retweet(status.id)
except:
print('------------------------------')
print("@" + status.user.screen_name)
print(status.text)
print("")
print(traceback.format_exc())
return True
通常処理はon_statusの部分で、このメソッドの引数statusに抽出されたツイートの情報が含まれています。
これをそのままRTさせるようにすればよいっちゃよいのですが、
誰かのRTや、タグを含む引用RTもRTしてしまうようで、ツイート数が増えるため処理を分岐させました。
- 誰かのRTはRTしない
- 引用RTはお気に入り登録のみする
- 上記にあてはまらないものはRTする
RTかどうかはstatusの属性textに「RT」という文字があるかどうかで判別します。
引用かどうかはis_quote_statusにbooleanで入ってるのでこれを利用します。
参考:Tweepyのstatusリストで何が取れるのかわからなかったので、取り出してみた
create_favorite()、retweet()がそれぞれお気に入りとリツイートの関数です。
引数にstatus.idを渡して実行します。
idはツイートの投稿そのものについているIDです。
try:
if status.user.screen_name != me.screen_name:
api.retweet(status.id)
ちなみに上記のような分岐をいれているのは、これまで書いたロジックだと自分で該当タグの投稿をした時に、
自分自身をRTしてしまうためで、これを避けるために実装してます。
(後述のInstagramの投稿をするときにあたりがあるため)
user.screen_nameで@始まりのTwitter IDが取得できるため、これを自分自身(me)と比較し、
一致しないときのみリツイートするようにしています。
デプロイ
AWS ECSへはgithubとCircle CIの連携によりデプロイしています。
docker-composeで使用できる書式のymlファイルを利用してタスク定義を定義し、
ECS上でサービスとして起動します。
githubにプッシュ
↓
Circle CI起動
↓
CI上でdockerfileをビルド + ECRにimageをデプロイ
↓
ECS上で上記デプロイしたimageを指定してサービスを起動
でデプロイ完了になります。
(本来はここにテストを入れるべきなのですが、シンプル + 個人コードなので割愛しました。。。)
参考:ローカルで使用したdocker-compose.ymlを使ってECS上でコンテナを起動する
参考:CircleCI+ECS+ECR環境でDockerコンテナのCD(継続的デプロイ)環境を構築する
参考:Rails × CircleCI × ECSのインフラ構築
version: 2.1
executors:
default:
machine: true
orbs:
aws-ecr: circleci/aws-ecr@6.0.0
jobs:
deploy:
executor:
name: default
steps:
- checkout
- aws-ecr/build-and-push-image:
region: AWS_REGION
account-url: AWS_ECR_REPOSITORY_URL
repo: 'zooaqua'
dockerfile: ./dockerfile
- run:
name: Install ECS-CLI
command: |
sudo curl -o /usr/local/bin/ecs-cli https://amazon-ecs-cli.s3.amazonaws.com/ecs-cli-linux-amd64-latest
sudo chmod +x /usr/local/bin/ecs-cli
- run:
name: ECS Config
command: |
ecs-cli configure \
--cluster zooaqua \
--region ${AWS_REGION} \
--default-launch-type EC2
- run:
name: Deploy
command: |
ecs-cli compose \
--file docker-compose_deploy.yml \
--ecs-params ./ecs-params.yml \
-p zooaqua \
service up \
--timeout 10 \
workflows:
build_and_deploy:
jobs:
- deploy:
name: deploy
上記でCircle CI上で動く流れを定義しています。
必要最小限しか実装していませんが、、
環境変数系はCircle CI側にて指定しています。
version: 1
task_definition:
task_execution_role: ecsTaskExecutionRole
上記ファイルでECS上でタスクに割り当てるロールを指定しています。
(この辺のAWS周りの話は本記事では割愛します)
version: '3'
services:
web:
image: ${AWS_ECR_REPOSITORY_URL_FULL}
command: python function.py
environment:
# 本体のAPIのKEY
- CON_KEY
- CON_KEY_SEC
- ACC_KEY
- ACC_KEY_SEC
- QUERY=#休園中の動物園水族館
- AWS_ECR_REPOSITORY_URL_FULL
logging:
driver: awslogs
options:
awslogs-region: ap-northeast-1
awslogs-group: zoo_aqua
awslogs-stream-prefix: zoo_aqua
タスク定義です。
pullするimageは、Ciercle CIにてbuildとpushしているECR上の物を指定しています。
ここでpython function.pyを起動時コマンドとして指定することで、
ECSのコンテナ上でPythonのコードが実行され、bot機能を動かすことができます。
なんらかの理由でこのプロセスが死んでも、ECSによって再起動され機能を維持できるのです。
ここも環境変数系はCircle CI側に持たせています。
コード上のTwitter APIのkey等もここを経由して渡しています。
(QUERYだけべた書きなのは特に意味はないです。ここで指定した単語でリアルタイム検索を仕掛けます)
またログはAWSのCloud watchにて収集できるようにしています。
参考:Amazon CloudWatch Logs logging driver
# ベースイメージを指定
FROM python:3.6-stretch
ENV PYTHONUNBUFFERED 1
RUN mkdir /code
# ディレクトリを移動する
WORKDIR /code
# pipでrequirements.txtに記載のパッケージをインストール
COPY requirements.txt /code/
RUN pip install --upgrade pip
RUN pip3 install -r requirements.txt
COPY function.py /code/
tweepy
ここはコンテナの定義です。
tweepyをpipでインストールするように指定しています。
dockerfile内にてビルド時にfunction.pyをコンテナ内にコピーしておくことで、
このimageをpullするだけで定義したPython関数をコンテナ内で使えるようになります。
Twitter側の自動RT機能については、ここまでが大枠です。
Instagremの投稿の自動Twitter投稿
ここから後半部分になります。
ここの機能はInstagramのGraph APIというのをTwitter APIに合わせて利用しています。
参考:Instagram Graph APIを使おう!
1時間に1回Instagramの投稿を検索しにいき、
過去1時間以内に投稿された「#休園中の動物園水族館」を含む投稿を画像とともにTwitterに投稿します。
全体コード
import requests
import json
import tweepy
import os
import datetime
import base64
import io
import traceback
import time
# Twitter APIで使用する各種キーをセット
# API Key
consumer_key = os.environ['CON_KEY']
# API secret key
consumer_secret = os.environ['CON_KEY_SEC']
# アクセストークン
Access_token = os.environ['ACC_KEY']
Access_token_secret = os.environ['ACC_KEY_SEC']
# インスタURL
url = os.environ['URL']
def lambda_handler(event, context):
# インスタAPIの結果を取得
response = requests.get(url)
data = response.json()["data"]
#twitter
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(Access_token, Access_token_secret)
api = tweepy.API(auth)
for i in data:
try:
# 投稿日時の確認
datestr = json.dumps(i['timestamp'], ensure_ascii=False).replace('"',"")
realdate = datetime.datetime.strptime(datestr, '%Y-%m-%dT%H:%M:%S%z')
diff = datetime.datetime.now(datetime.timezone.utc) - realdate
# 現在から1時間以内の投稿なら処理
if diff.seconds < 3600:
# Tweet文を作成
# 130文字に調整
text = json.dumps(i["caption"], ensure_ascii=False)[1:130].replace(r'\n',"\r\n") + "... #休園中の動物園水族館 "
link = json.dumps(i["permalink"], ensure_ascii=False).replace('"',"")
# 投稿種別をチェックして画像URLを取得
img_url = ""
if i["media_type"] == "CAROUSEL_ALBUM":
for j in i["children"]["data"]:
if "scontent" in j['media_url']:
img_url = j['media_url']
break
elif i["media_type"] == "IMAGE":
img_url = i['media_url']
else:
continue
if img_url is "":
continue
f=io.BytesIO(requests.get(img_url).content)
f.mode = 'rb' # 読み込み専用のバイナリモードであるというように擬態する
f.name = 'hoge.jpg' # 拡張子さえ合っていれば問題ないと思います
# 画像付き投稿
img= api.media_upload(filename="hoge.jpg",file=f)
api.update_status(status=text + link, media_ids=[img.media_id_string,"","",""]) # ←4枚投稿想定らしい。残り3枚を空値に
time.sleep(30)
except:
print(traceback.format_exc())
実装
前半と異なり、上記コードはLambda上にて動きます。
環境変数系もLambda上にて指定しています。
Lambdaではイベントを契機にlambda_handlerの中に記載した処理が実行されます。
# Twitter APIで使用する各種キーをセット
# API Key
consumer_key = os.environ['CON_KEY']
# API secret key
consumer_secret = os.environ['CON_KEY_SEC']
# アクセストークン
Access_token = os.environ['ACC_KEY']
Access_token_secret = os.environ['ACC_KEY_SEC']
# インスタURL
url = os.environ['URL']
Twitter部分は前半と同じです。
urlはInstagram Graph APIにGETするためのURLを環境変数から取得しています。
詳細は下記記事を参照いただきたいですが、「#休園中の動物園水族館」というタグを含む投稿一覧を取得できるようなエンドポイントを指定しています。
参考:グラフAPIを使って任意のハッシュタグを持つ投稿をインスタグラムから取得する
def lambda_handler(event, context):
# インスタAPIの結果を取得
response = requests.get(url)
data = response.json()["data"]
#twitter
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(Access_token, Access_token_secret)
api = tweepy.API(auth)
上記のrequests.getにてInstagram Graph APIを叩きに行き、返り値をdataに格納します。
Twitter部分は前半と同じです。
for i in data:
try:
# 投稿日時の確認
datestr = json.dumps(i['timestamp'], ensure_ascii=False).replace('"',"")
realdate = datetime.datetime.strptime(datestr, '%Y-%m-%dT%H:%M:%S%z')
diff = datetime.datetime.now(datetime.timezone.utc) - realdate
# 現在から1時間以内の投稿なら処理
if diff.seconds < 3600:
# Tweet文を作成
# 130文字に調整
text = json.dumps(i["caption"], ensure_ascii=False)[1:130].replace(r'\n',"\r\n") + "... #休園中の動物園水族館 "
link = json.dumps(i["permalink"], ensure_ascii=False).replace('"',"")
dataには投稿件数分のデータが格納されているので、for文にて取り出します。
まず投稿の日時をチェックし、現在時刻から1時間以内の投稿かを見ます。
投稿日時はtimestampに格納されています。
参考:IG Media
1時間以内なら次の処理に進めます。
Twitterには文字数制限があるため、Instagramのキャプションを途中省略して投稿できるようにし、変数に格納しています。
またInstagramの投稿そのもののリンクをpermalinkから取得しています。
# 投稿種別をチェックして画像URLを取得
img_url = ""
if i["media_type"] == "CAROUSEL_ALBUM":
for j in i["children"]["data"]:
if "scontent" in j['media_url']:
img_url = j['media_url']
break
elif i["media_type"] == "IMAGE":
img_url = i['media_url']
else:
continue
if img_url is "":
continue
Instagramの投稿種別には、画像と動画があり、またそれぞれ単独の時と複数同時投稿されているときがあります。
投稿種別には下記があり、media_typeに格納されているので、これを見て処理分岐させます。
- CAROUSEL_ALBUM:1つの投稿に複数の画像or動画が含まれる投稿(いわゆるアルバム)
- IMAGE:画像1枚の投稿
- VIDEO:動画1つの投稿
今回はTwitterへの投稿は画像1枚のみとしたいため、上記それぞれに対応できるようなコードを書き、
画像を1枚に絞った後、変数img_urlにそれを格納します。
CAROUSEL_ALBUMの場合、それぞれの投稿はchildrenの中にネストされますので、さらにfor文で処理を続けています。
media_url(投稿された画像のURL)に、画像ならscontent、動画ならvideoが含まれるためここで判別し、
最初にヒットした画像に対し、img_urlにmedia_urlを格納します。
一方でmedia_typeがIMAGEの場合は、そのままimg_urlにmedia_urlを格納します。
VIDEOならcontinueでスキップさせます。
上記処理にて、Twitterに投稿する画像を1枚に絞ります。
f=io.BytesIO(requests.get(img_url).content)
f.mode = 'rb' # 読み込み専用のバイナリモードであるというように擬態する
f.name = 'hoge.jpg' # 拡張子さえ合っていれば問題ないと思います
# 画像付き投稿
img= api.media_upload(filename="hoge.jpg",file=f)
api.update_status(status=text + link, media_ids=[img.media_id_string,"","",""]) # ←4枚投稿想定らしい。残り3枚を空値に
time.sleep(30)
except:
print(traceback.format_exc())
取得した画像URLをGETしてデータを取得し、これをBytesIOを経由させてtweepyから画像投稿させます。
参考:python-twitter で BASE64 形式の画像をツイートする
ちなみにTwitter APIの画像投稿はmedia_uploadとupdate_statusの2段階のようです。
(media_uploadにて画像を先にアップロードし、update_statusでそのIDを指定して本文とともに投稿)
デプロイ
こちら側はデプロイといっても、Lambdaにzipファイルにて手動でアップロードしています(工夫不足)。
Lambda上ではpipで入れるようなライブラリは使えないため、あらかじめローカルに落としたものをzipで一緒にLambdaにアップする必要があります。
(今回でいうとtweepy)
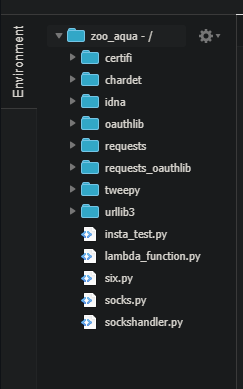
lambda_function.pyという名前の関数をLambdaは実際に読みに行きます。
lambda_function.pyでtweepyをimportするには、上記のように同じディレクトリにpipでダウンロードしたtweepyのファイル一式を配置します。
このLambda関数をCloudWatch Eventsから指定して、cron式により1時間に1回の定期処理をさせます。
参考:【AWS】lambdaファンクションを定期的に実行する
参考:Rate または Cron を使用したスケジュール式
ちなみにInstagramからの情報取得から実際のTwitterへの処理を、タグに該当する投稿分繰り返すので、
処理時間を考慮してLambdaのタイムアウト設定を10分に伸ばしています。
Instagramの投稿をTwitterに自動投稿する部分についてはここまでが大枠になります。
終わりに
「#休園中の動物園水族館」というタグの投稿が好きで、これを集めたbotがあればよいなという構想からスタートしましたが、
APIとAWSを駆使すると意外と簡単に実装できてしまうんだな、というのが率直な感想です。
特にLambdaはかなり便利だったのですが、常時プロセスを起動させておくような使い方ができなかったので、
ECSと組み合わせる方法を選択しました。
早くコロナが収束してこのbotが不要になることを望むばかりです。