はじめに
の続きです。
最新のアップデートでは、
- ノートブックのスケジュールまたは、パイプライン実行おいて、キューイングにより Spark 用の CPU が解放され次第ジョブが実行される仕組み
- Spark Pool 用の vCore が最大値ではなく最小値に基づいて確保される仕組み
という形で、Spark ジョブの同時実行数について緩和されるようになりました。
説明・検証
パイプラインからのノートブック実行のキューイング
Job Queueing for Notebook ※試用版は不可
これまでのパイプライン実行では、Core 数が限界まで使用されていると、即座にエラーとなりました。
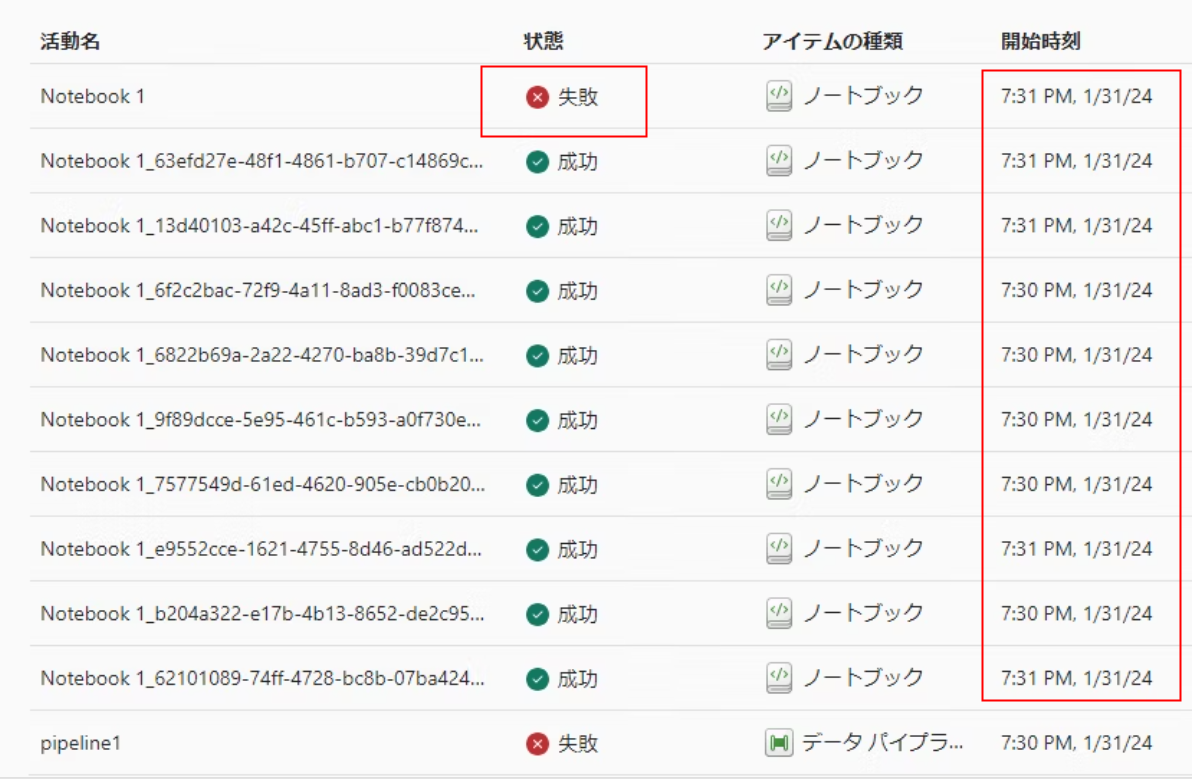
今回はキューイングを使用することでこれが成功するはずです。
5 ノード(1ノードあたり 8 vCoreのため40 vCore)が使用されるようにカスタムプールを作成してこの環境で実行します。
このカスタムプールを使って 10 点並列実行すると 400 vCore となり、前回の検証と同様に制限を超えるはずです。
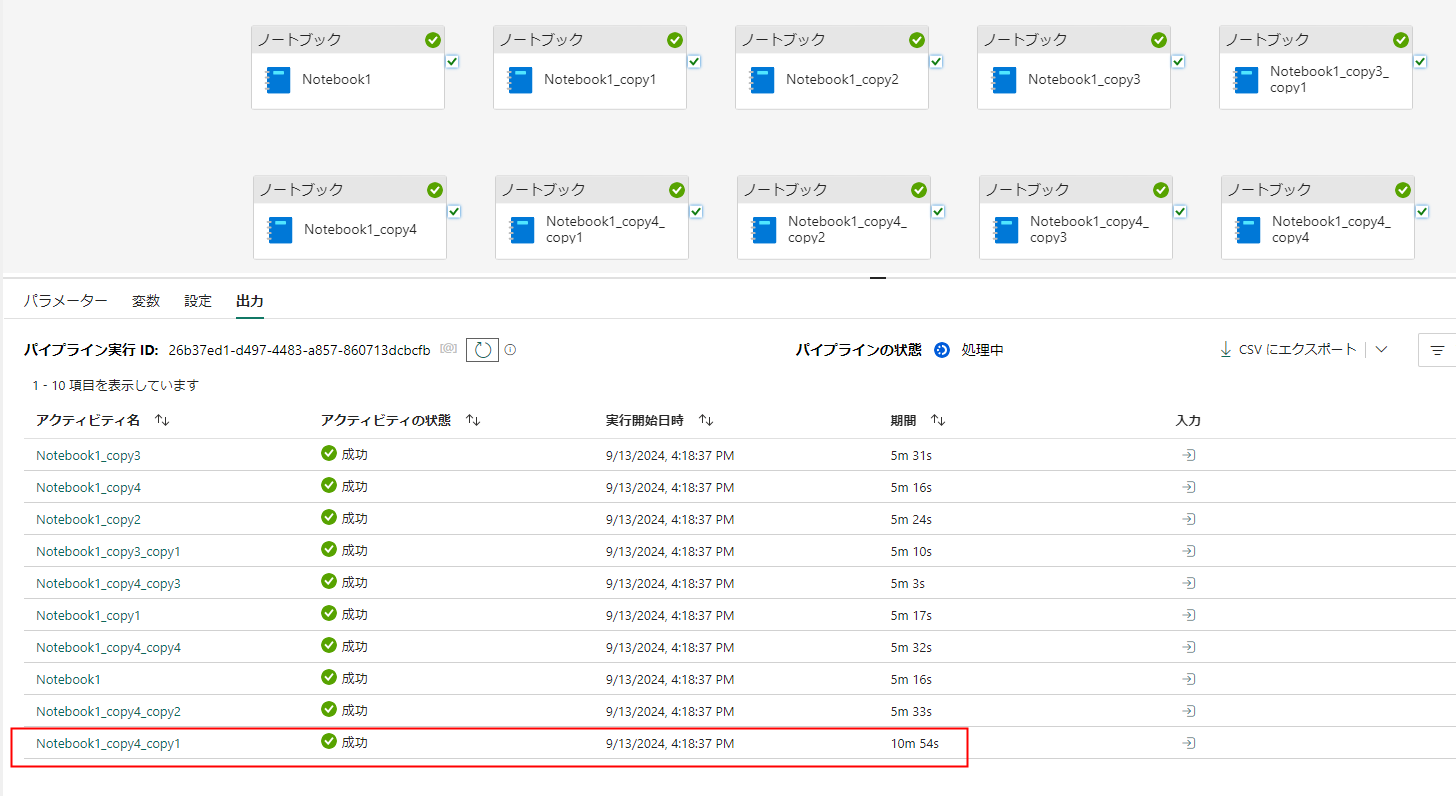
実行の結果、すべての実行がエラーにならず実行されています。
また、10個目の実行がキューイングされて後追いで実行されていることがわかります。
最小値での Spark vCore 確保
これまでのノートブックの対話型セッションでは、Core 数が限界まで使用されていると、即座にエラーとなりました。
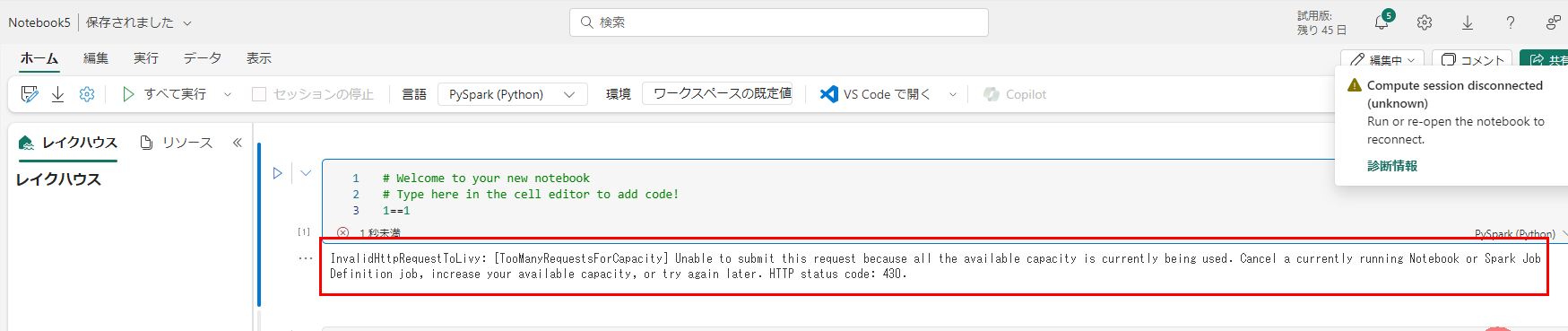
検証記事ではMin:1 Max:10 の設定で Max 値 × セッション数 で判定
スタータープールに戻して実行複数のセッションを立ち上げてみます。最大値で考えると80 vCore/セッション となるため、最大値で考えられた場合には、5セッション目でバースト制限を超えます。
1つめ:成功
2つめ:成功
3つめ:成功
4つめ:成功
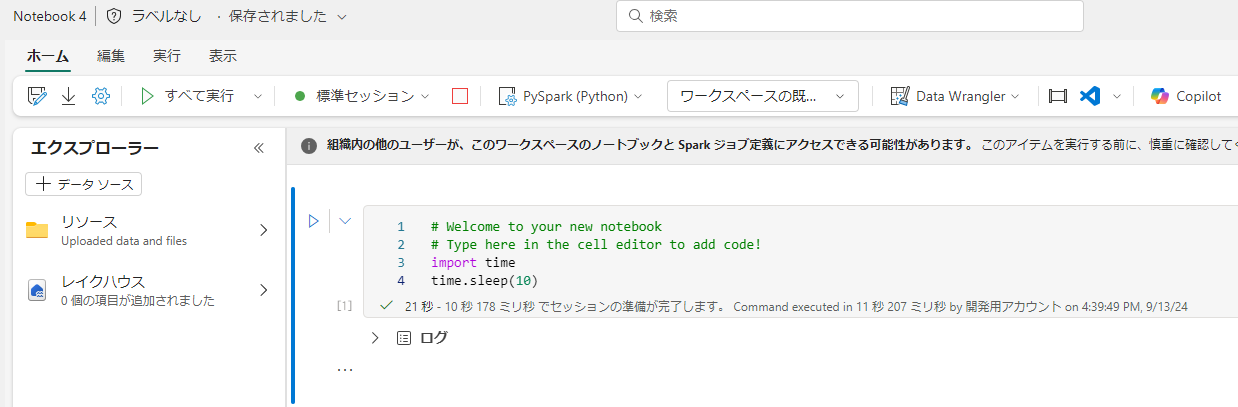
5つめ:成功!
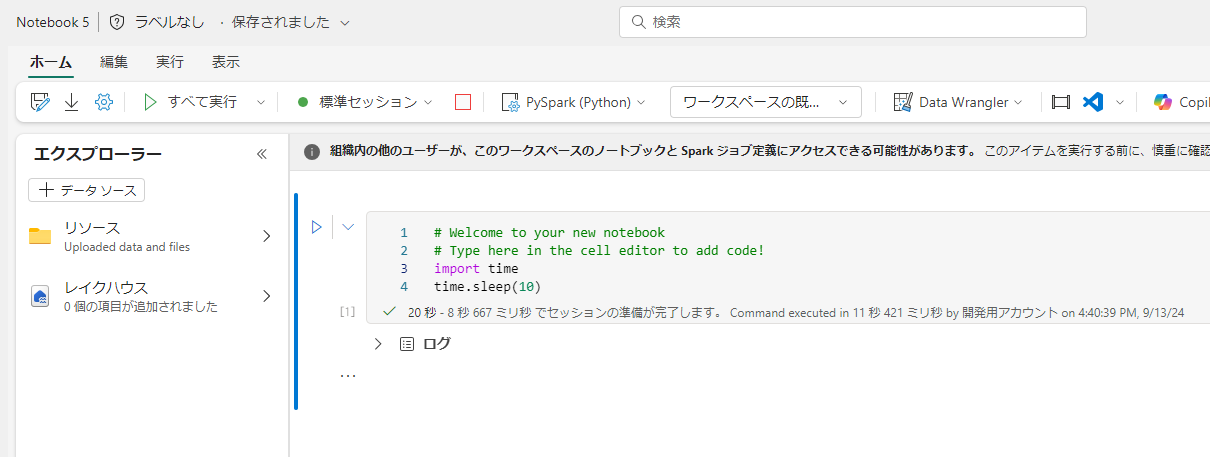
すべてのセッションが起動しました。最大値での確保ではないことがわかります。
おすすめの使用法
今回は F64 環境で検証しましたが、まとめとして、F2 容量などで特に重要な、 Spark vCore をいかに無駄遣いしない ようにするかについておすすめを記載します。
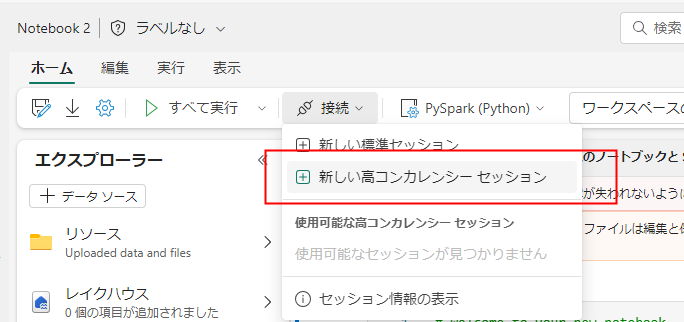
重要度高:ハイコンカレンシーセッションを利用して複数のノートブックを立ち上げる
かなり重要です。一人で複数のノートブックを開発するときは ハイコンカレンシーセッション 必ず利用するようにしましょう。
これを使用しない場合、ノートブックごとに Spark Pool のコア数が確保されてしまい、他の開発者に迷惑がかかります。
注意点:
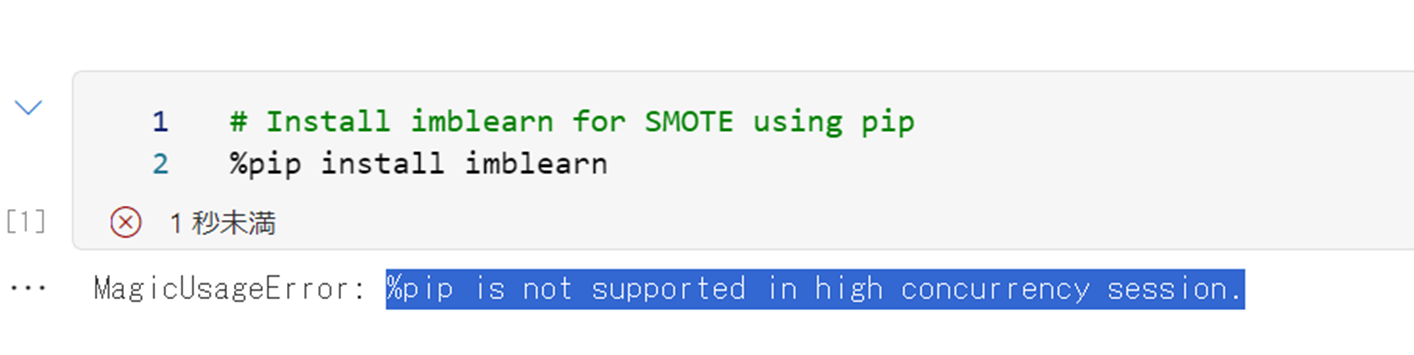
ハイコンカレンシーセッションでは、pip install はサポートされていないようです。
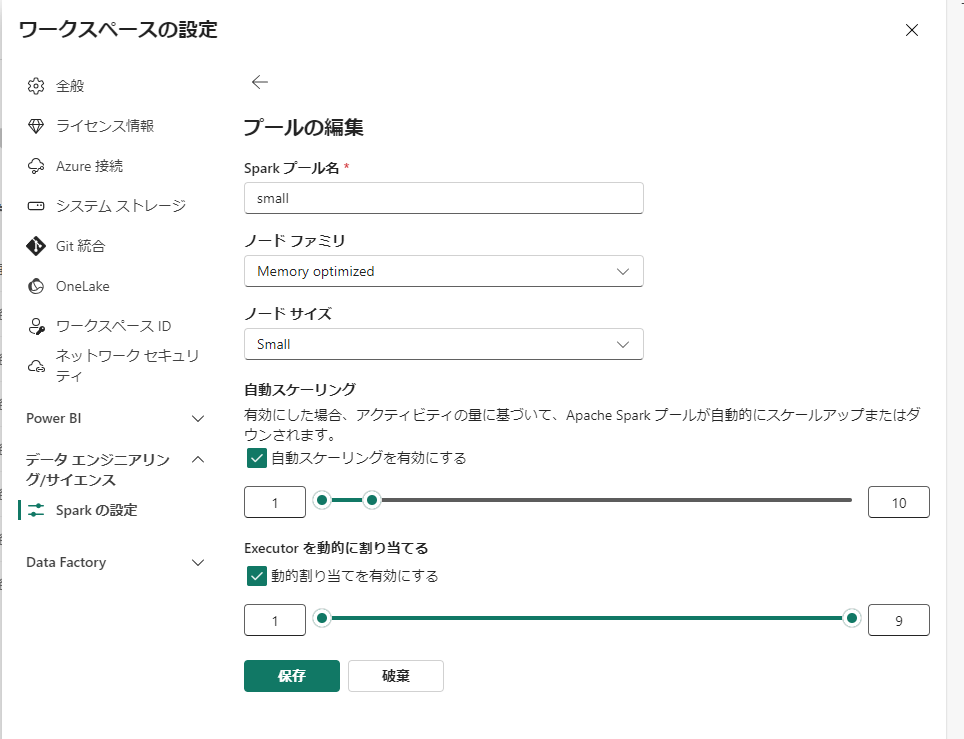
重要度中:ワークスペース既定の Spark プールのノードサイズを下げる
スタータープールは Medium サイズとなっており、 ノードあたり 8 vCore を使用します。
したがって、small に変えておくことで、消費を 4 vCore にして抑えることができます。
ただし、カスタムプールはセッションの起動が遅いことに注意です。

ハイコンカレンシーセッションだとちょっと早いらしいけど、この設定下では差が出ませんでした。

https://learn.microsoft.com/ja-jp/fabric/data-engineering/high-concurrency-overview
重要度低:ワークスペース既定の Spark プールのノード数を減らす
確保される vCore 数は最小値で計上されるため、必ずしも必須ではないと思いますが、 現状ワークアラウンドを必要とする設定状態もあるので紹介します。
ノード数はワークスペース設定→データエンジニアリング→Sparkの設定にて変更します。

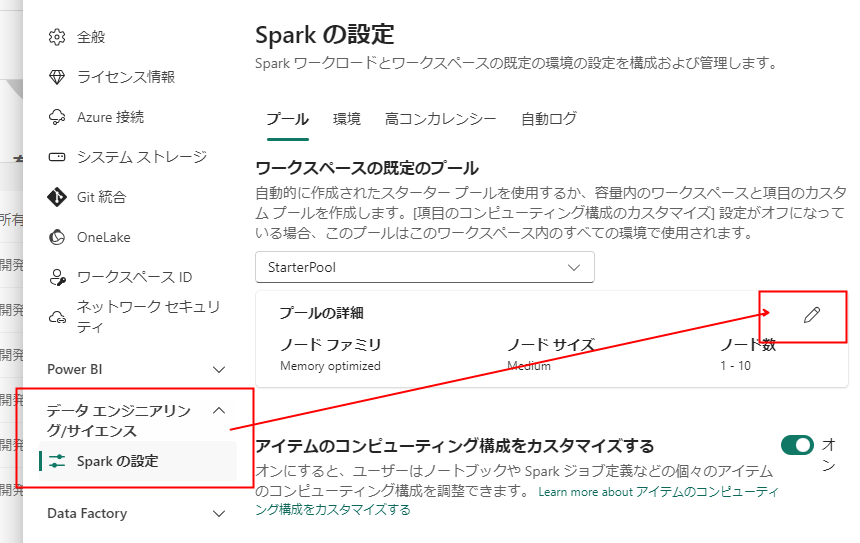
最大ノード数を1にすることで、8core 固定のスタータープールができあがります。
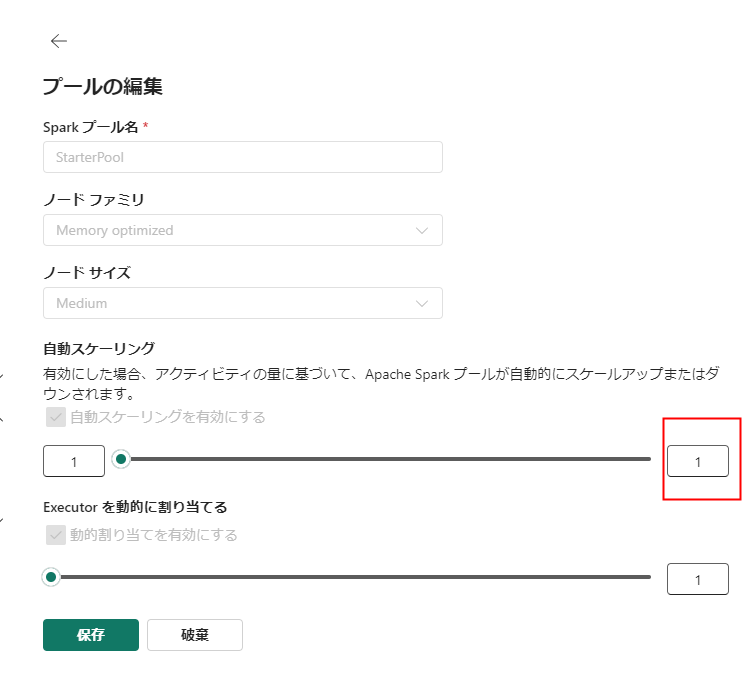
ただ、現時点ではこのままだと動きません。(そのうち解消されるとは思いますが)
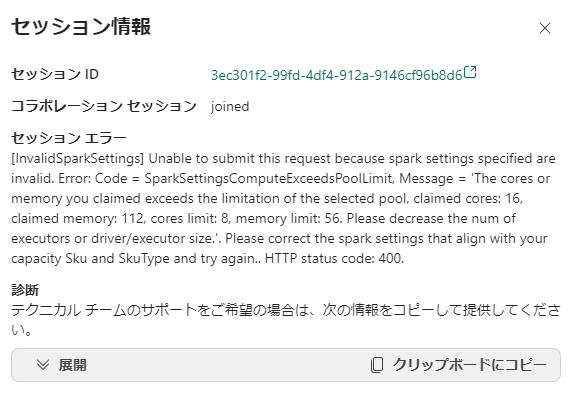
ワークアラウンド
環境を作成します。環境は Spark ジョブが実行される、コンピューティング、ライブラリ設定の定義です。
チームで共通して使うライブラリなんかを登録しておくのにも使えます。(というか、パイプライン実行では、pip install は許可されないため、追加のライブラリを使用するときには必須です)
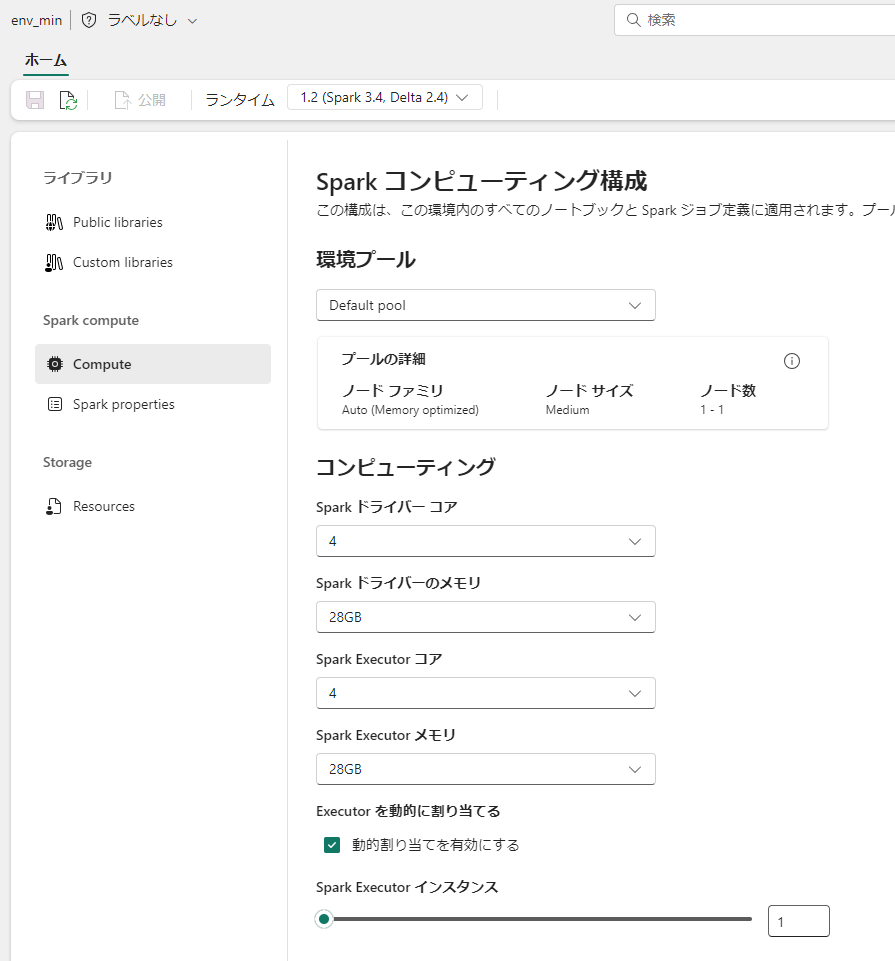
現状はスタータープールが1ノードで立ち上がる状況において、通常のドライバーとワーカーの役割通りに8core ずつ要求、つまり確保できる以上に要求してしまうようです。
このため、環境を利用することで設定される、確保できるメモリ量に即した設定(8Coreを分割してる状態)が効いてくると推察されます。
環境を作成したら、ノートブックの設定か、ワークスペースの既定の環境設定を変更します。
ノートブックで変更する場合:
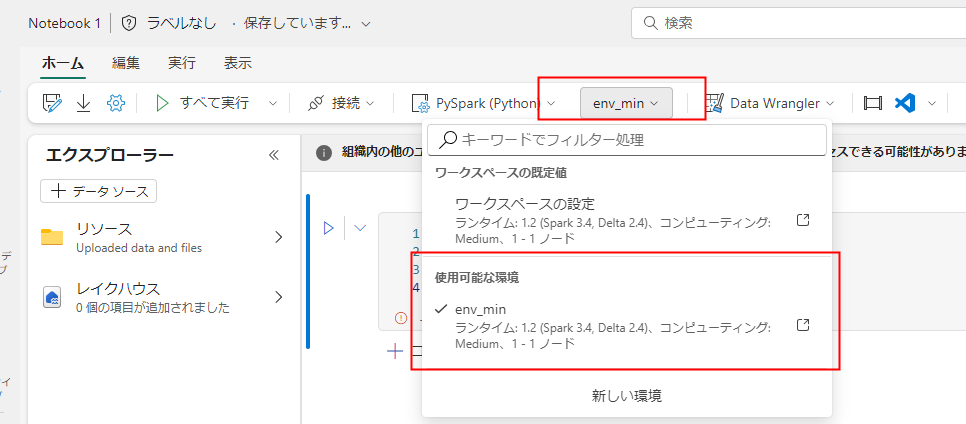
ワークスペースの既定環境で変更する場合:
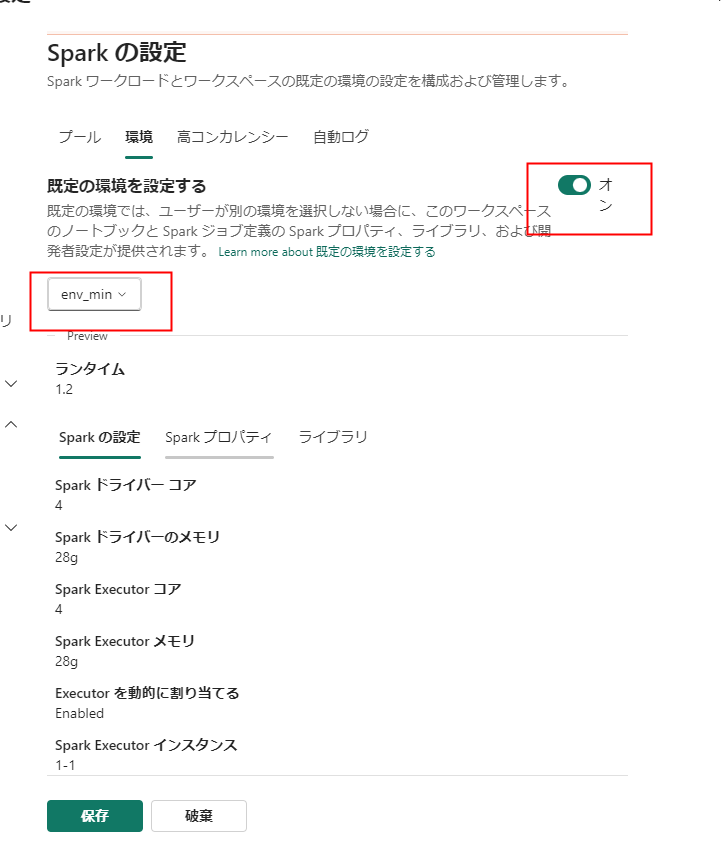
この状態であれば、ノートブックが起動します。
シングルノードクラスターは通常数秒で起動するスタータープールに比べて少し時間がかかるようです。

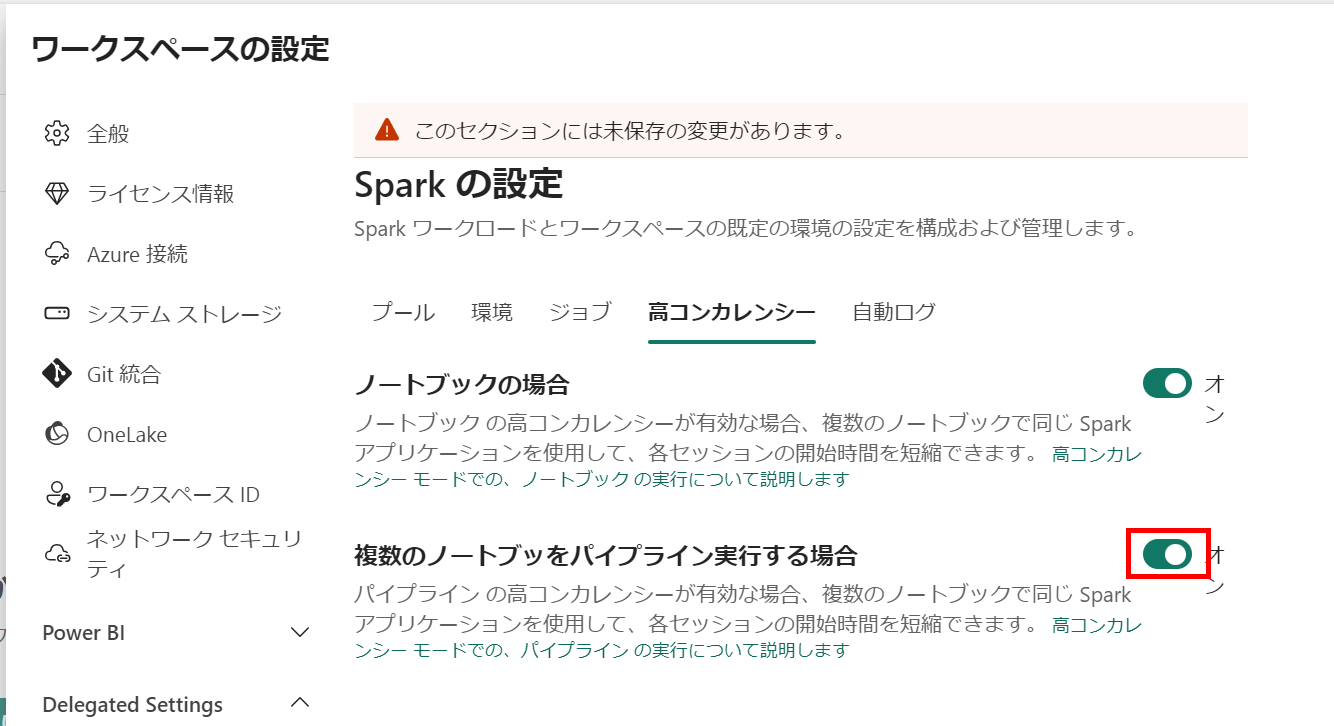
重要度中:Pipelines のノートブックの高コンカレンシーモード (2024 FABCON でのアナウンスを受けてアップデート)
パイプライン内のノートブックの高コンカレンシー モードを構成する を使用するとパイプラインから同じ環境構成となっているノートブックが同じセッション(ハイコンカレンシーセッション)で起動します。
これにより、パイプライン内でノートブックをループや、パラメータを変えての並列実行するときにセッションが無駄に立ち上がることを防ぐことが出来ます。また、直列実行においても前回のアクティビティで立ち上がったspark セッションが再利用できるため、起動時間をスキップすることでパイプライン全体の実行時間を削減する効果も望めます。
有効にする場合にはワークスペース設定を変更するだけです。
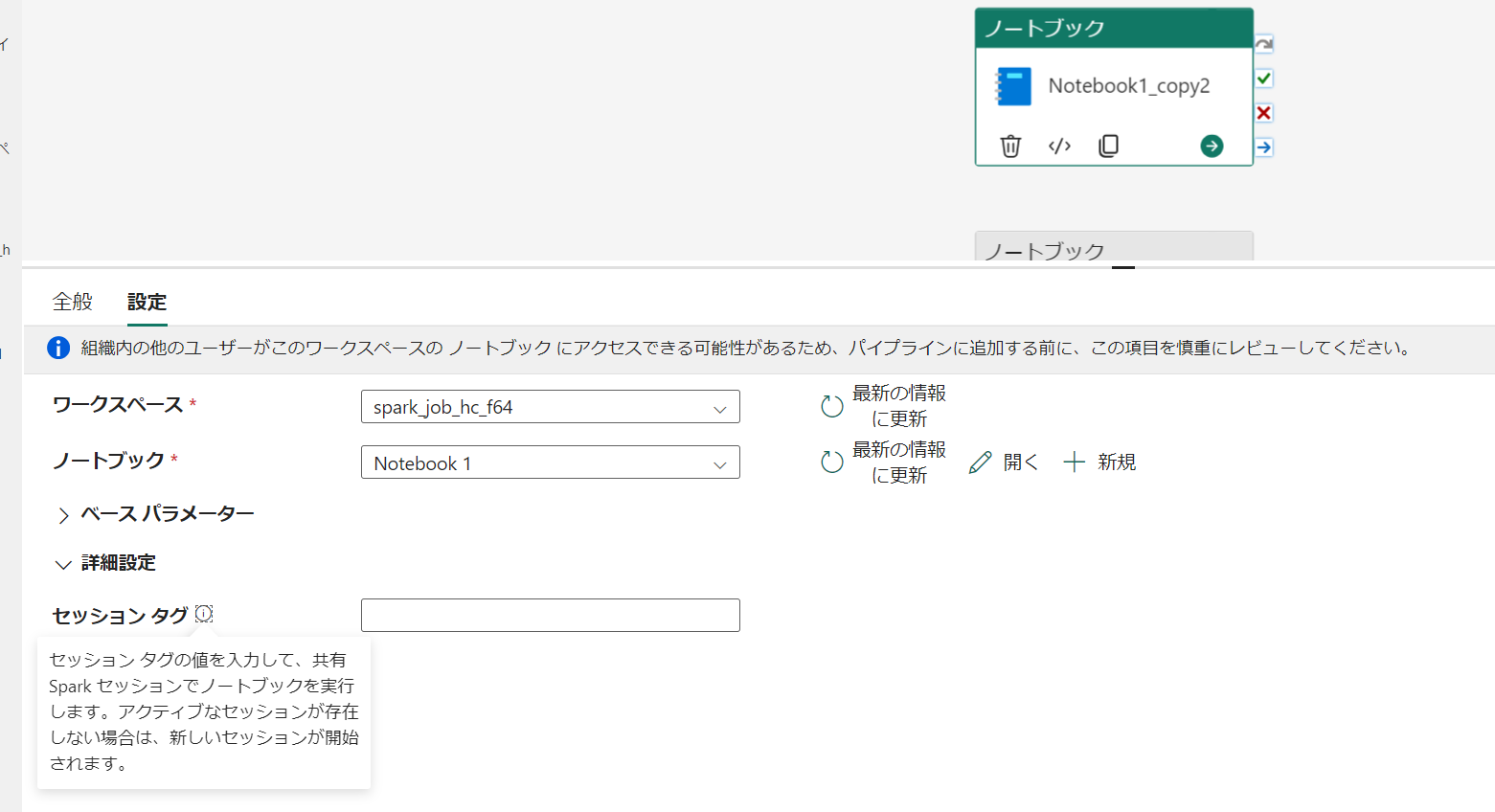
特定のノートブックアクティビティをグループ化してセッションを作成したい場合には session tag を指定します。
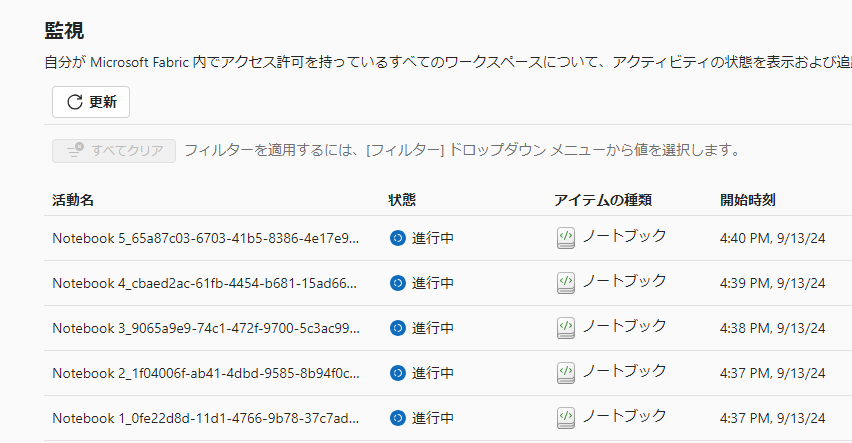
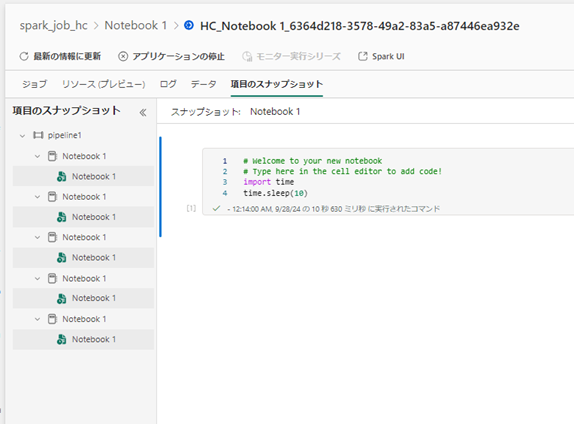
この機能を有効化した状態でパイプラインから複数のノートブックを実行するとHC_~と接頭辞がついたnotebook job が同じセッション内で実行されます。
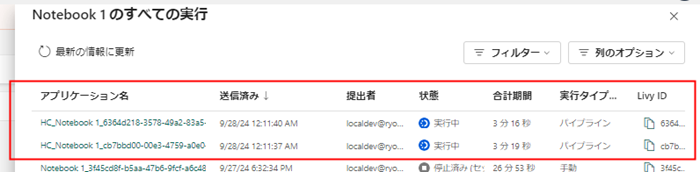
それぞれの実行は監視ハブから以下のように表示されます
重要度高:Spark セッションの自動停止設定 (2024 FABCON でのアナウンスを受けてアップデート)
通常、spark の対話型セッション(ノートブック開発時に起動するセッション)は操作がなくなって20分間経過したことをもってタイムアウト、セッション停止をしていました。
使い終わったら手動でセッションを停止すればよいのですが、なかなか徹底するのは難しいので CU の無駄遣いが発生しがちです。
そこで ワークスペースのジョブ設定 にて、セッションのタイムアウト設定を短く設定することでこうした無駄遣いを減らすことが出来ます。
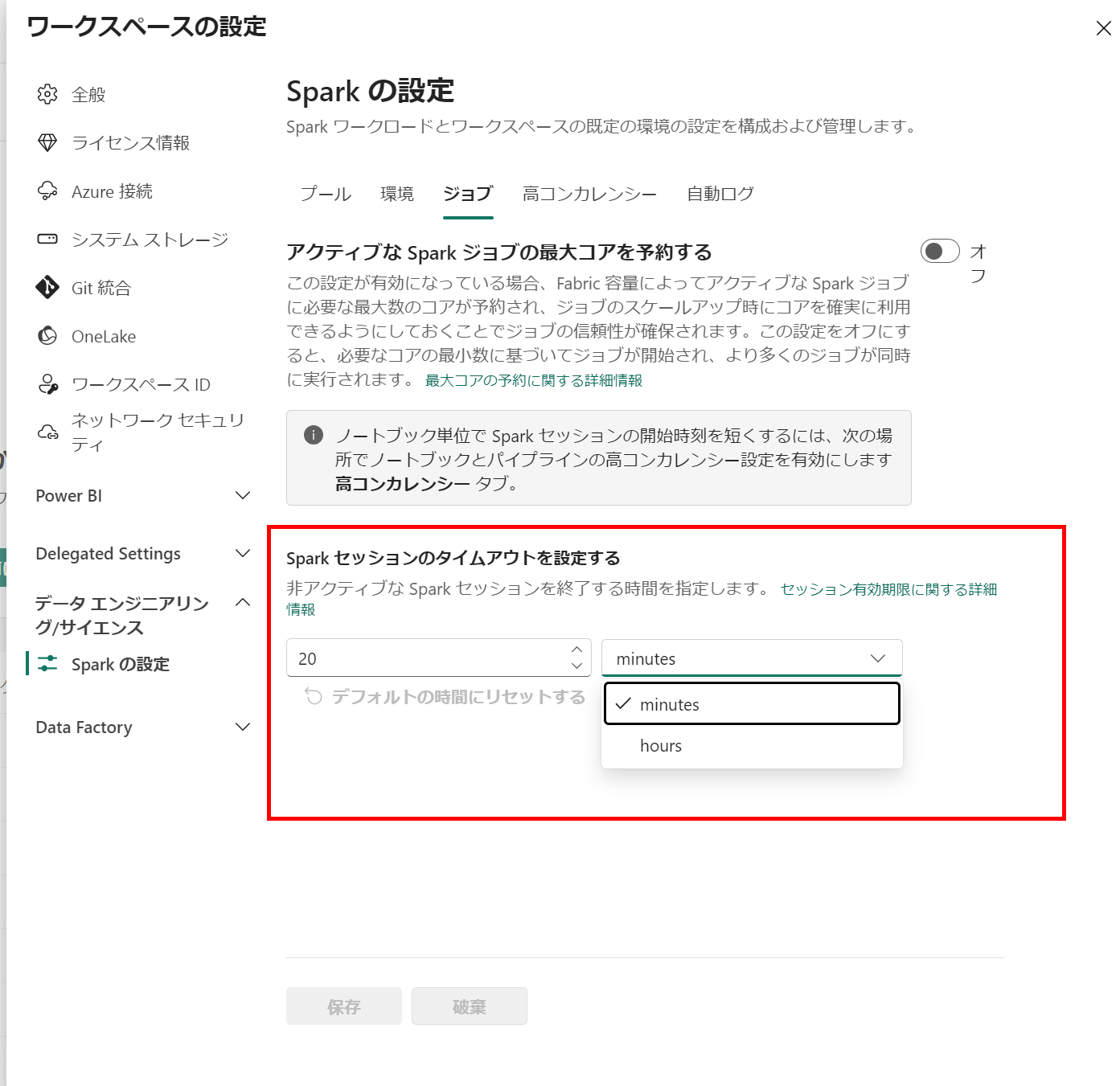
余り短い時間にすると コーディング→調べもの→コーディング再開しようとしたらセッションが切れて変数が初期化されるということになるので注意です。