はじめに
Synapse Data Engineering を活用するうえで、Spark ジョブの同時実行数の記載を読み解いて検証しました。
2024/04/19追記
以下2点の拡充により、ジョブ同時実行は大幅に緩和されました。(本記事は古い情報となり、検証方法や、考え方の参考レベルとなります
注意:以下は2024/01時点の情報です。
Spark ジョブについて
Spark ジョブは以下を対象にして検証します。
- Notebook の対話型セッション
- データパイプラインから実行するNotebook 実行タスク
参考ドキュメント
前提知識
Microsoft Fabric における Spark ジョブ
冒頭で申し上げたように、この記事ではジョブとは対話型セッションとパイプラインの実行と位置付けていますが、これは監視ハブから確認するとわかりやすいです。
Notebook の対話型セッションは、 Notebook の画面でセッションが起動中にジョブとして認識されます。
ノートブックの画面で、コードセルを実行するとセッションの確立が実行されます。
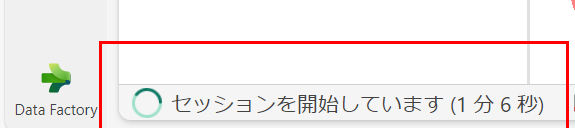
セッションが確立すると通知が表示され
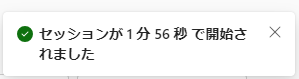
セッションの準備が完了し、ノートブックのコマンドが実行されます。
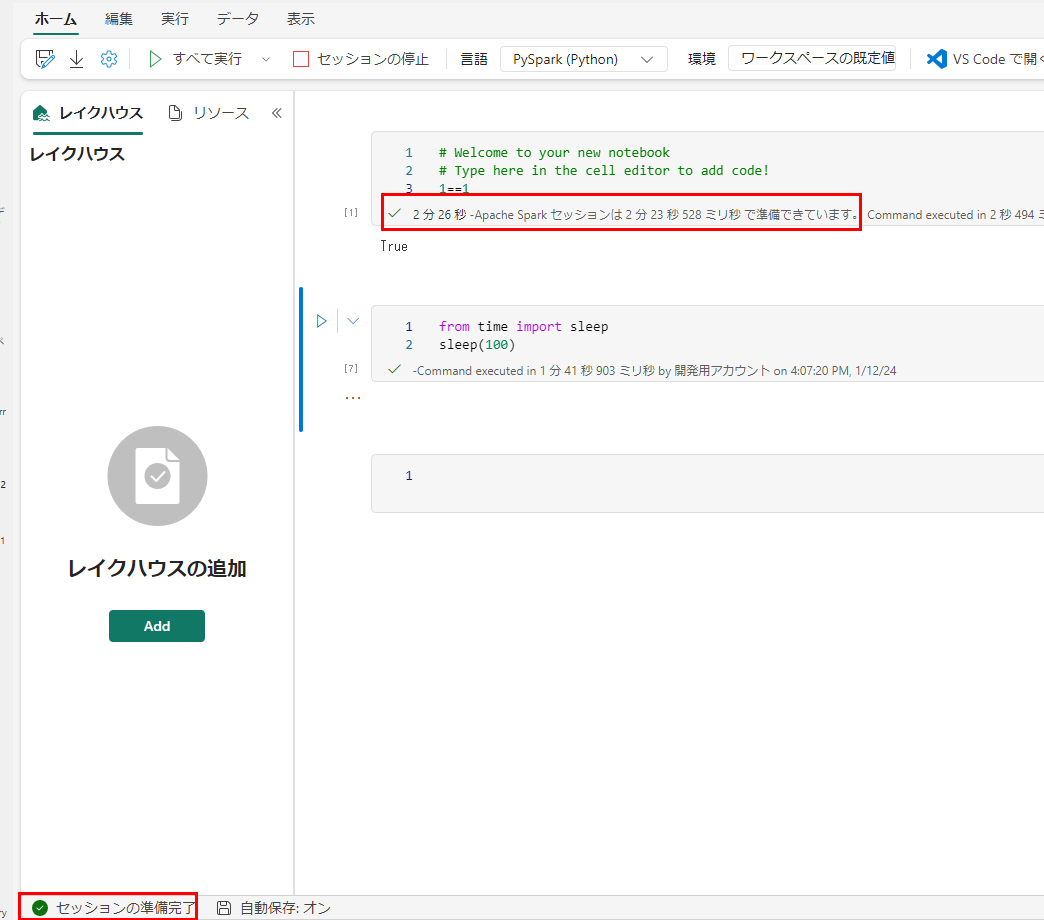
監視ハブからは、進行中のジョブとしてノートブックセッションが認識されます。

詳細を見るとランタイム情報などが表示されます。
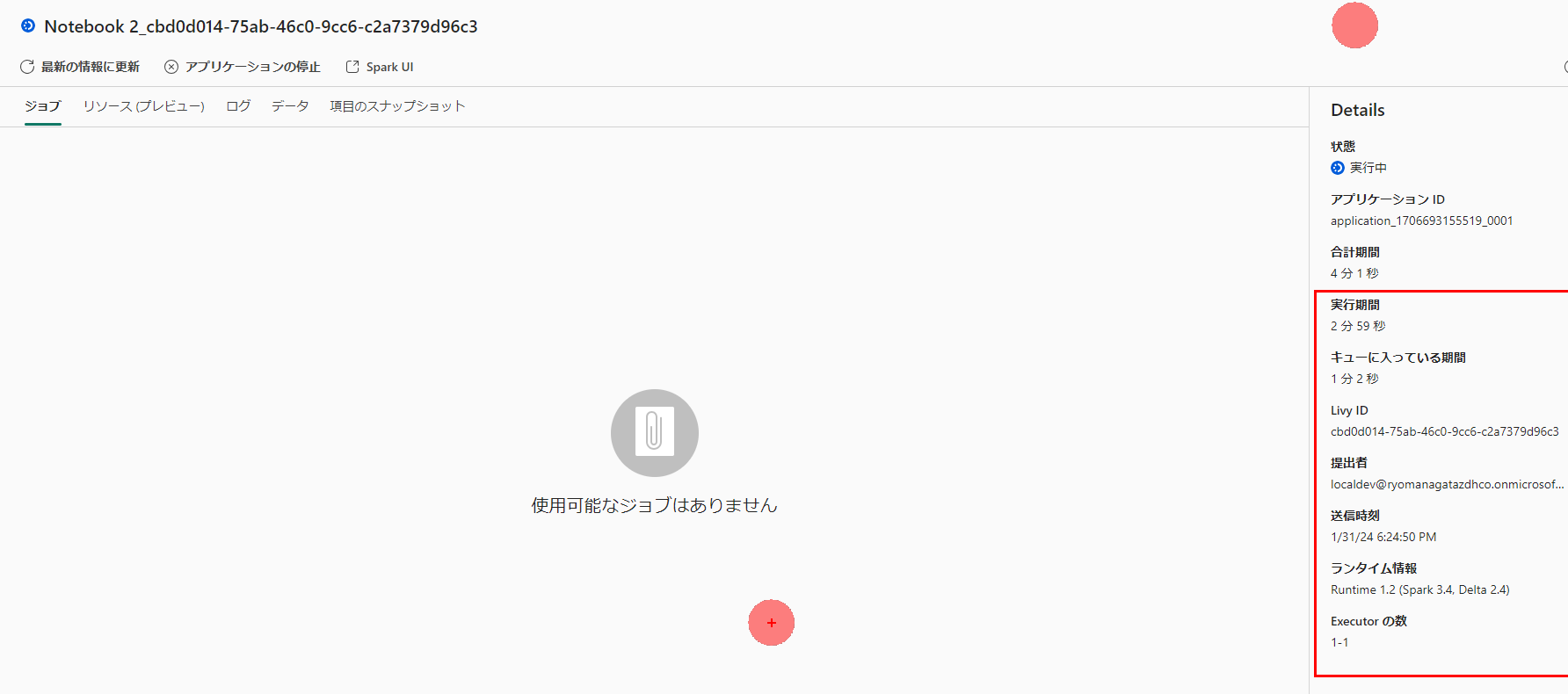
セッションを停止すると、
監視ハブからもジョブの状態が進行中から完了になります。

一方データパイプラインのNotebook アクティビティの実行も一つのジョブです。
このような、並列で動作する二つのNotebook アクティビティを構成した場合、2つのジョブが同時に送信されることになります。
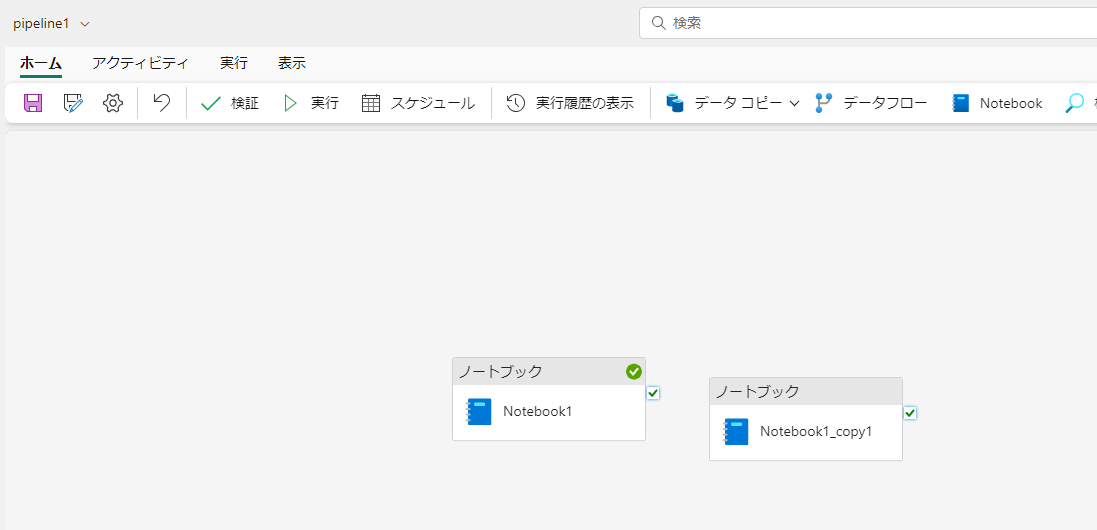
実行時に監視ハブはこのような状態になり、2つジョブが認識されています。
スタータープールとカスタムプール
Fabric では既定で Spark を数秒の起動で利用できるスタータープールがあります。
Fabric Spark でスターター プールを構成して管理します。 - Microsoft Fabric | Microsoft Learn
ワークスペースを作成した時点のFabric 容量 SKU で、最大ノード数が決まります(既定のノード数列を参照)が、1 ノードのサイズ= Spark 仮想コア数は固定で Medium = 8コアです。
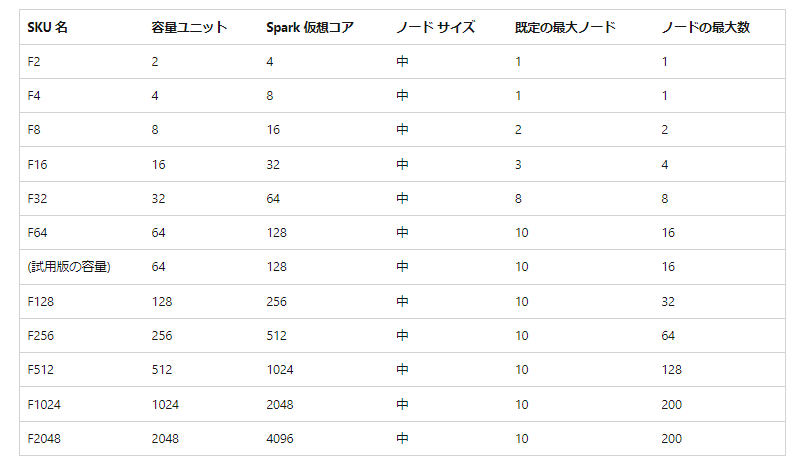
たとえば、試用版では既定の最大ノードが 10 なので、スタータープールを利用したジョブは 80 コアを消費します。
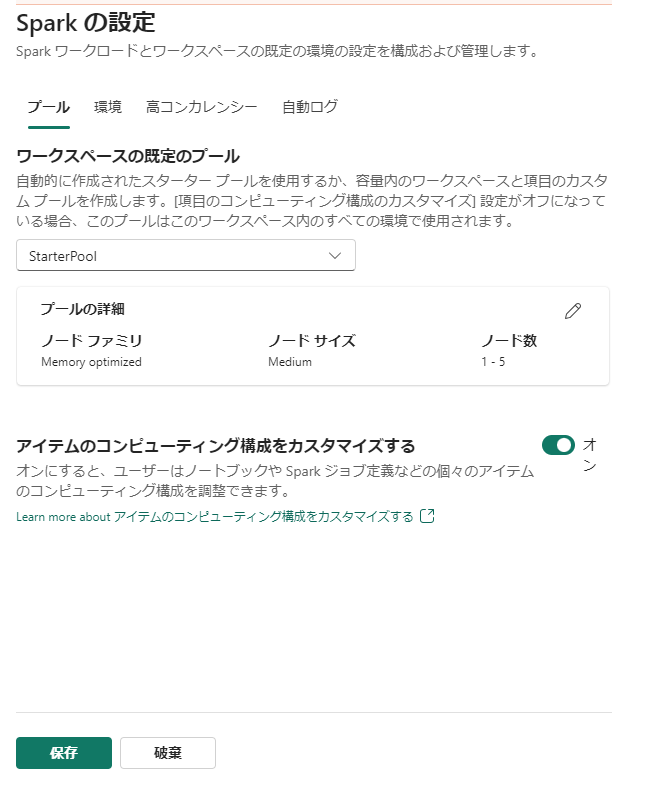
以下の画像のようにワークスペースの設定からノード数は変更が可能ですが、ノードサイズは Medium で固定であることがわかります。また、この構成は1ジョブあたり、8 コアを消費する構成であることもわかります。
一方、カスタムプールではこの構成が自由ですが、起動時間は数分必要です。
Fabric でカスタム Apache Spark プールを作成する - Microsoft Fabric | Microsoft Learn
つまり、使用する Spark Pool の構成によって、Spark 仮想コアの消費数が大きく違う点を理解する必要があります。
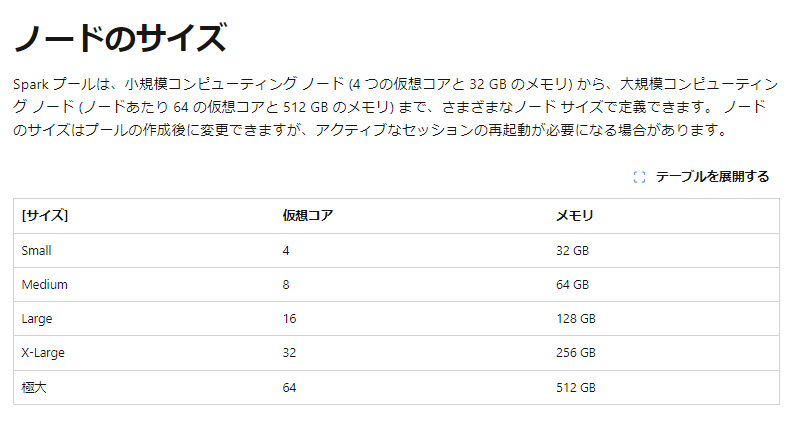
補足:ノードのサイズ
SKU と Spark 仮想コア、キューの関係
SKUにより同時に使用できるSpark仮想コアとキューの数(同時に実行できジョブ数)が決まります。
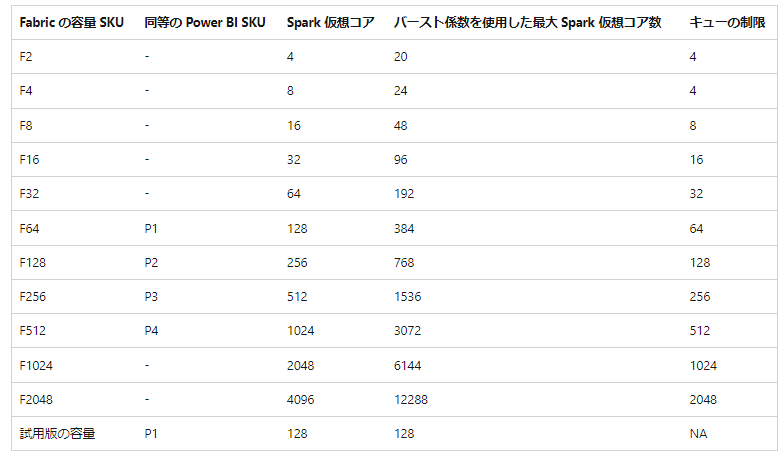
表の通り、F2 容量では、Spark 仮想コアを4コア/秒が使えます。さらに、バーストという機能により、一時的に3倍の同時実行が可能です。以下のように、バーストはジョブの同時実行に寄与するものであり、1つのジョブを増強させられるわけではないことをご注意ください。

例:
- 〇: F64 環境では、Starter Pool Max 5 ノード構成(40 Spark コア消費)のジョブを9つ同時に実行できる
-
- 1ジョブあたり80-> 128 未満と、F64の提供する仮想コア内であるためOK
-
- 9ジョブ同時送信により40*9=360 だが、バーストにより合計消費コア数は384まで拡張されているため、同時実行可能
- ×:F64 環境では、Starter Pool Max 20 ノード構成(160 Spark コア消費)のジョブを1つ同時に実行できる。
-
- F64 で構成できるのは、128コアまでであるためそもそも構成不可。バーストは寄与しない
検証
F64環境で、40 コア消費するジョブをデータパイプラインで9つ同時実行
先ほどの例で挙げたケースを実際にやってみます。
まず、ワークスペース設定を以下のようにします。
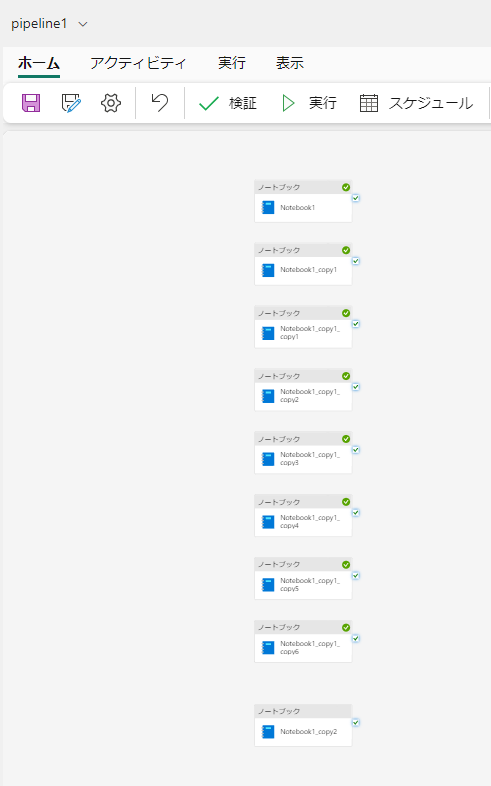
パイプラインはこんな感じ
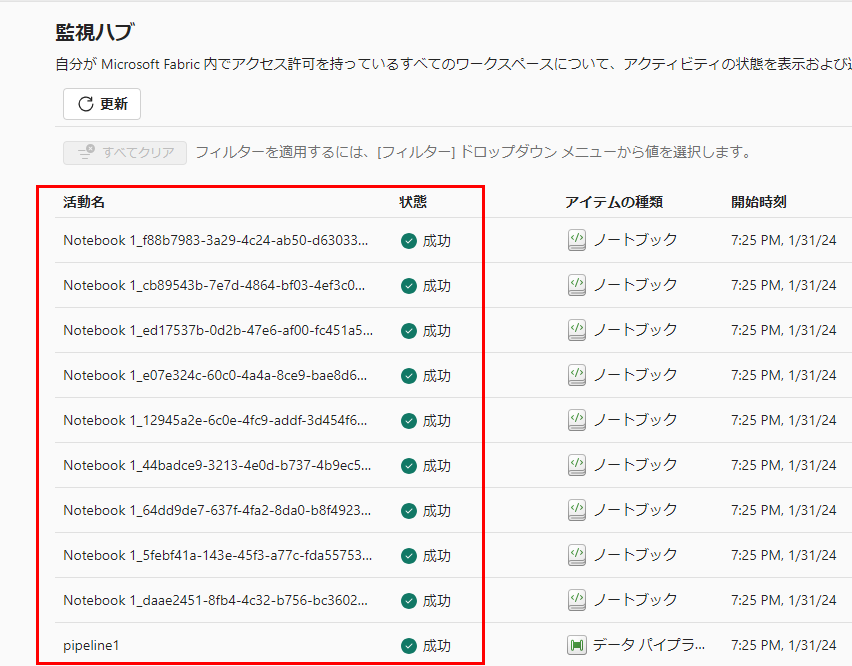
実行結果は以下の通り。同時実行すべてが成功します。
F64環境で、40 コア消費ジョブをデータパイプラインで10同時実行
では、1つ増やすとどうでしょうか。資産では、40*10=400でバースト係数を使用した最大 Spark 仮想コア数:384を超えるはずです。
パイプラインはアクティビティが10個並びました。
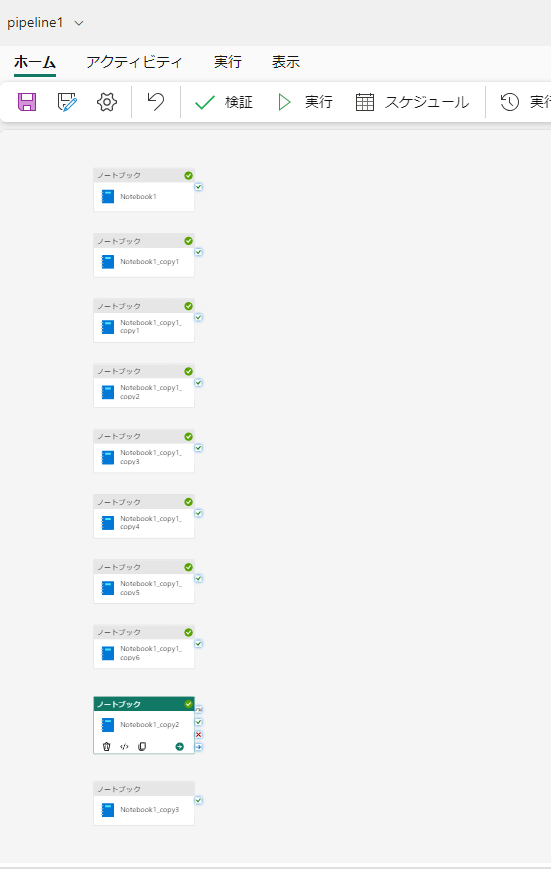
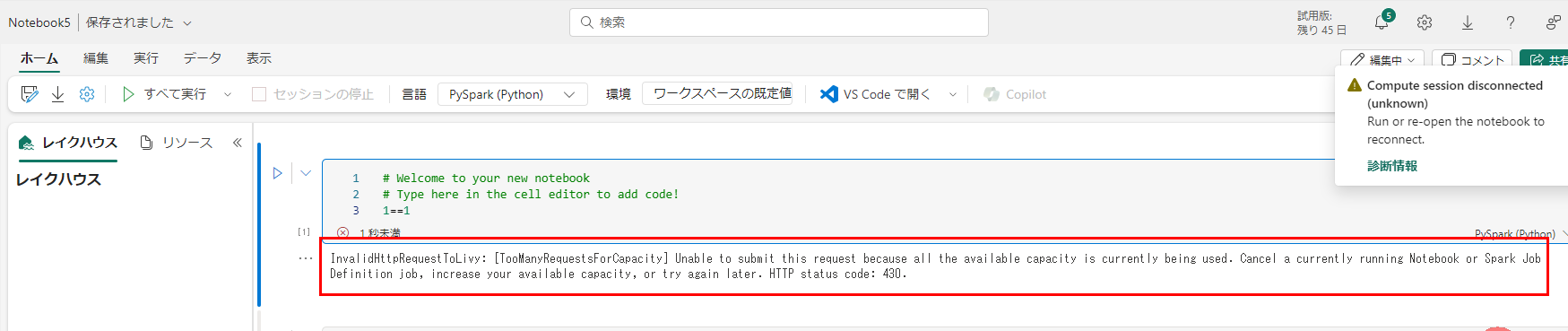
実行結果は以下のように、1つのジョブが失敗しています。ちなみにこのジョブは進行中にもなりませんでした。リクエスト時点で弾かれたということですね。
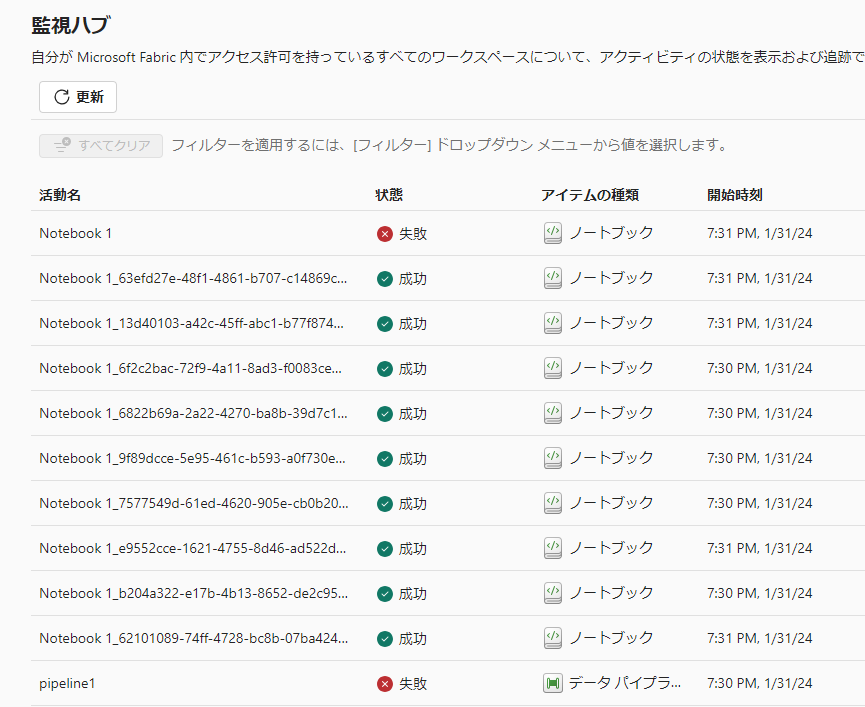
エラーメッセージを見ると、最大のコア数を超えたことを示すHTTP 状態コード 430 が出力され、容量の上限を超えた旨が記載されています。
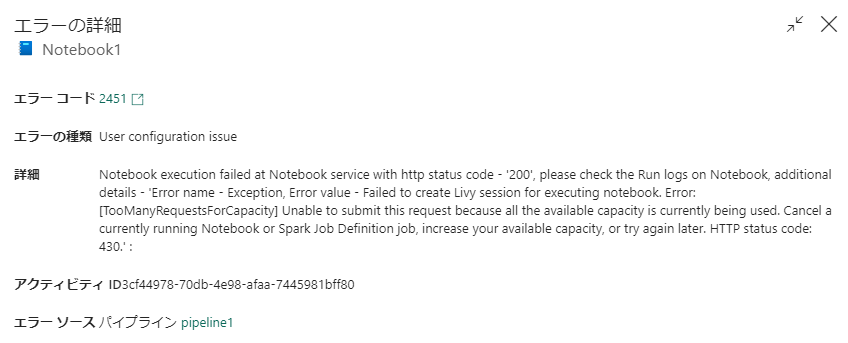
F64 環境で、80コア消費するNotebook の対話型セッションを5つ同時に起動していく
ワークスペース設定を以下のように変更します。
この状態でまずは一つ目:成功
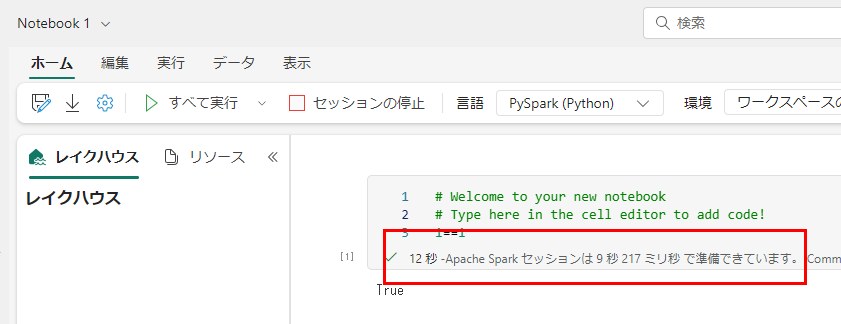
2~4つ目
ここまでで、ジョブは4つ進行中になっています。
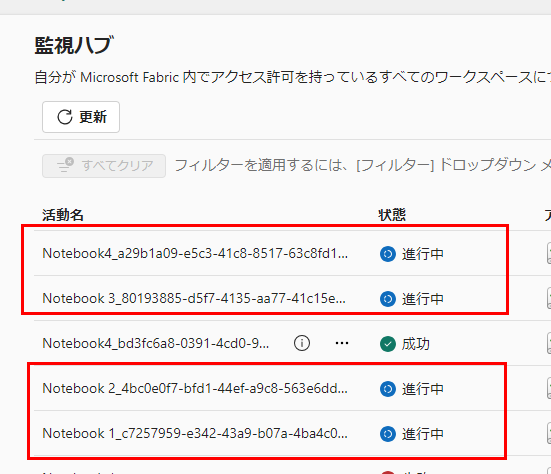
5つ目で想定通り失敗しました。
まとめ
Spark ジョブの同時実行数はSKUと Spark Pool の構成により大きく幅が変わることがわかりました。特にSPark Pool の構成は試用版=F64という大きな環境でも既定で80コア確保されるような設定になっています。
Notebook開発者、パイプラインによるノートブックアクティビティの実行は同時にどれだけ実行されるのかに気を付けて、ワークスペース設定を構成してあげることで、余分なSpark 仮想コアを消費しないように気を付けましょう。
補足
最後の検証で、一人の開発者が複数のノートブックを開発する際に、このような制限がかかるのは厳しいという印象があるかもしれませんが、その場合には高コンカレンシーモードを使うことで、同じノートブックセッションを複数のノートブックで使いまわすことができます。これにより、制限に抵触しないで複数のノートブック実行を開発できますね。こちらの利用についてはまたの機会に
Fabric Spark コンピューティングでの高コンカレンシー モード - Microsoft Fabric | Microsoft Learn