はじめに
Databricks Lakeflow Connect で SharePoint Online サイト上のファイルを取り込みを試してみます。
2025/06/13 現在、Beta 版機能であるためか、いくつかつまづいた点があるのでこの対処を含めてキャプチャなどを共有します。
Lakeflow Connect
Lakeflow Connect には、一般的なエンタープライズ アプリケーション、データベース、クラウド ストレージ、ローカル ファイル、メッセージ バスなどのデータを取り込むためのシンプルで効率的なコネクタが用意されています。 このページでは、Lakeflow Connect で ETL のパフォーマンスを向上させるいくつかの方法について説明します。 また、フル マネージド コネクタから完全にカスタマイズ可能なフレームワークまで、一般的なユース ケースとサポートされているインジェスト ツールの範囲についても説明します。
出典:https://learn.microsoft.com/en-us/azure/databricks/ingestion/overview
セットアップ(管理者側の作業)
Microsoft SharePoint インジェストのための OAuth U2M の構成 に従って進めます。
機能の有効化
ワークスペース設定から本機能を有効化します。

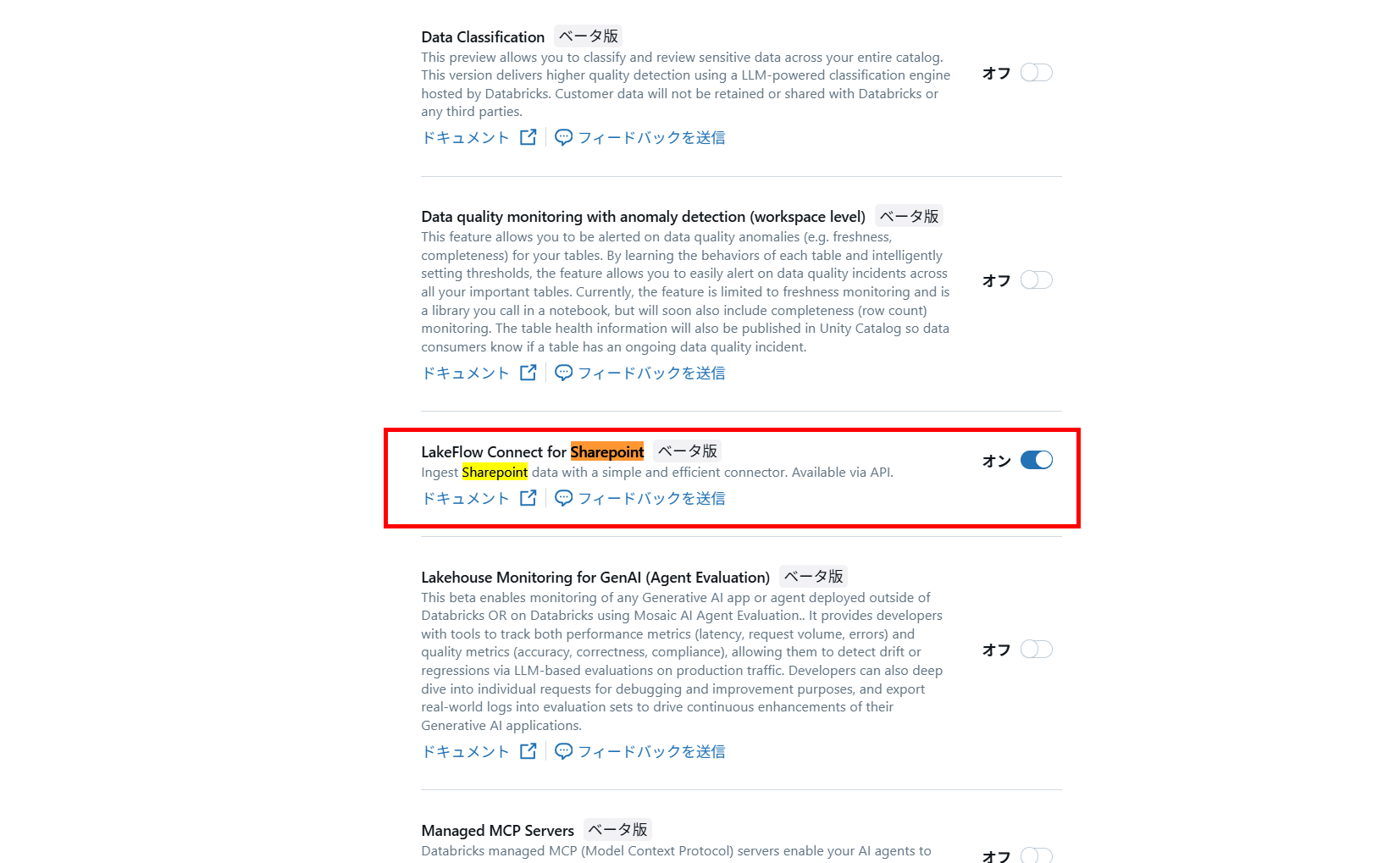
1. Sharepoint サイト ID の取得
対象のサイトはこちらです。(Fabric のデモ用に用意したものを流用しました)
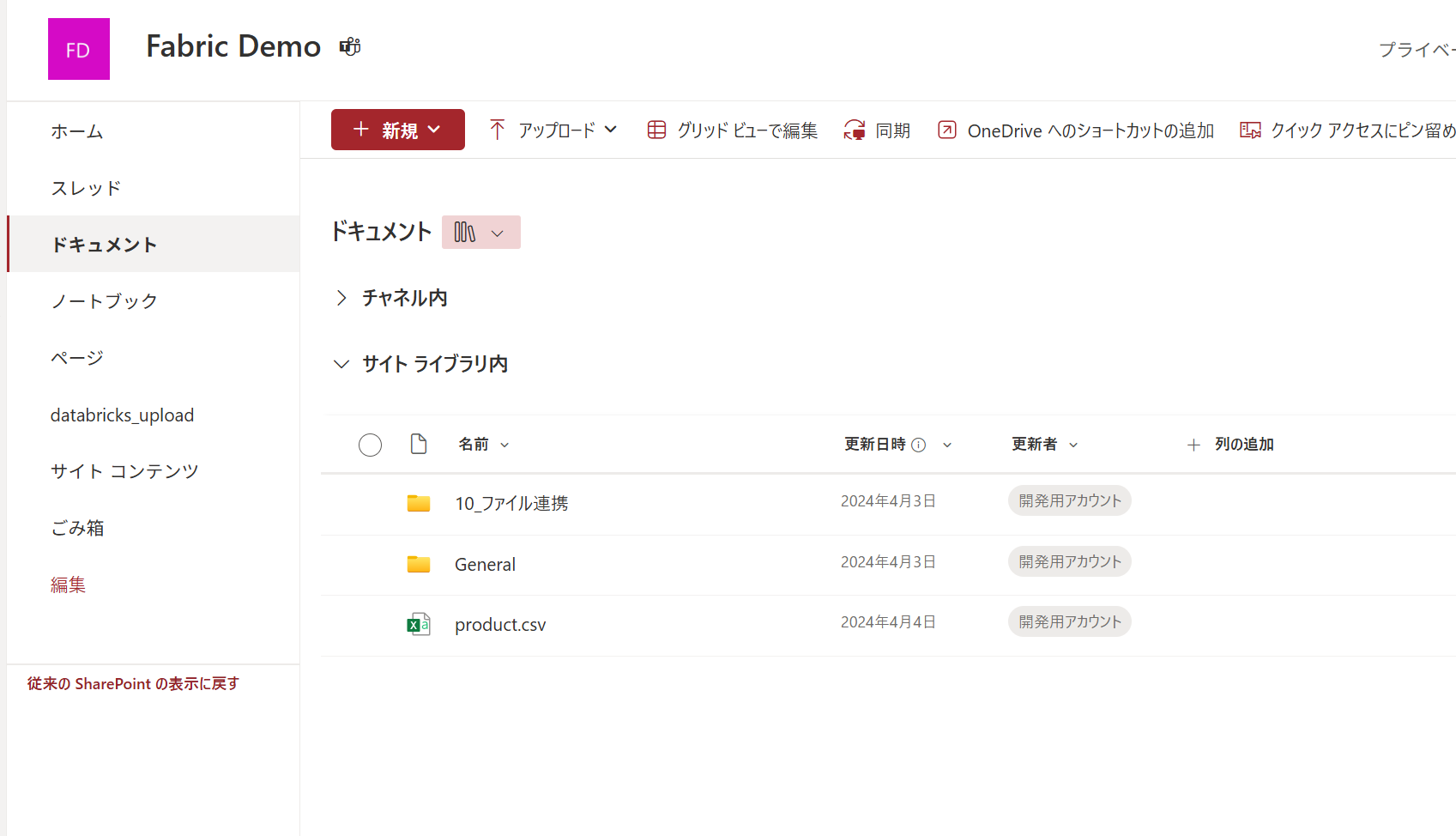
サイト ID は URLの中になく、システム内で利用されている ID を取得する必要があります。
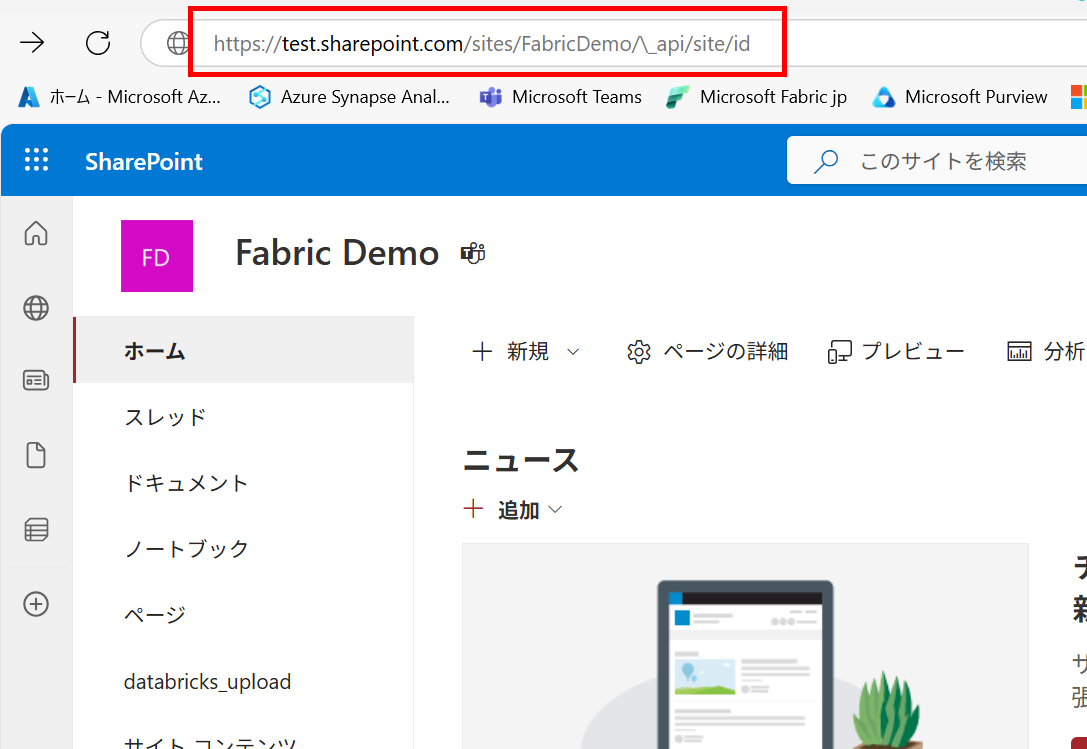
- サイトのホームの URL 末尾に
/\_api/site/idを追加してアクセスします。
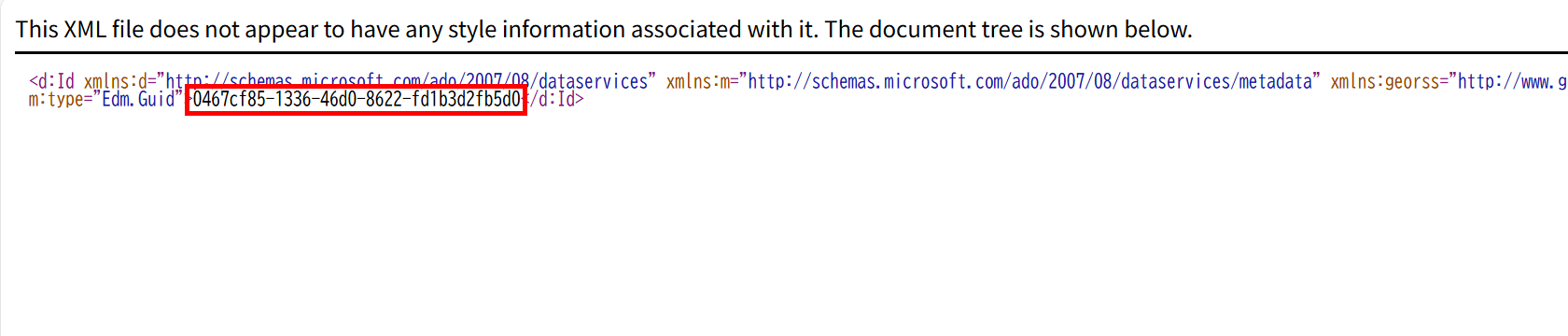
- このような画面が表示されるので、ID をメモします
2. サービスプリンシパルの作成(管理者側の作業)
-
Databriks instanec url を取得
Databricks ワークスペースの URL を取得します。

-
Entra ID 上でアプリを作成する際、リダイレクトURLを設定します。/login/oauth/sharepoint.html の形式となります。
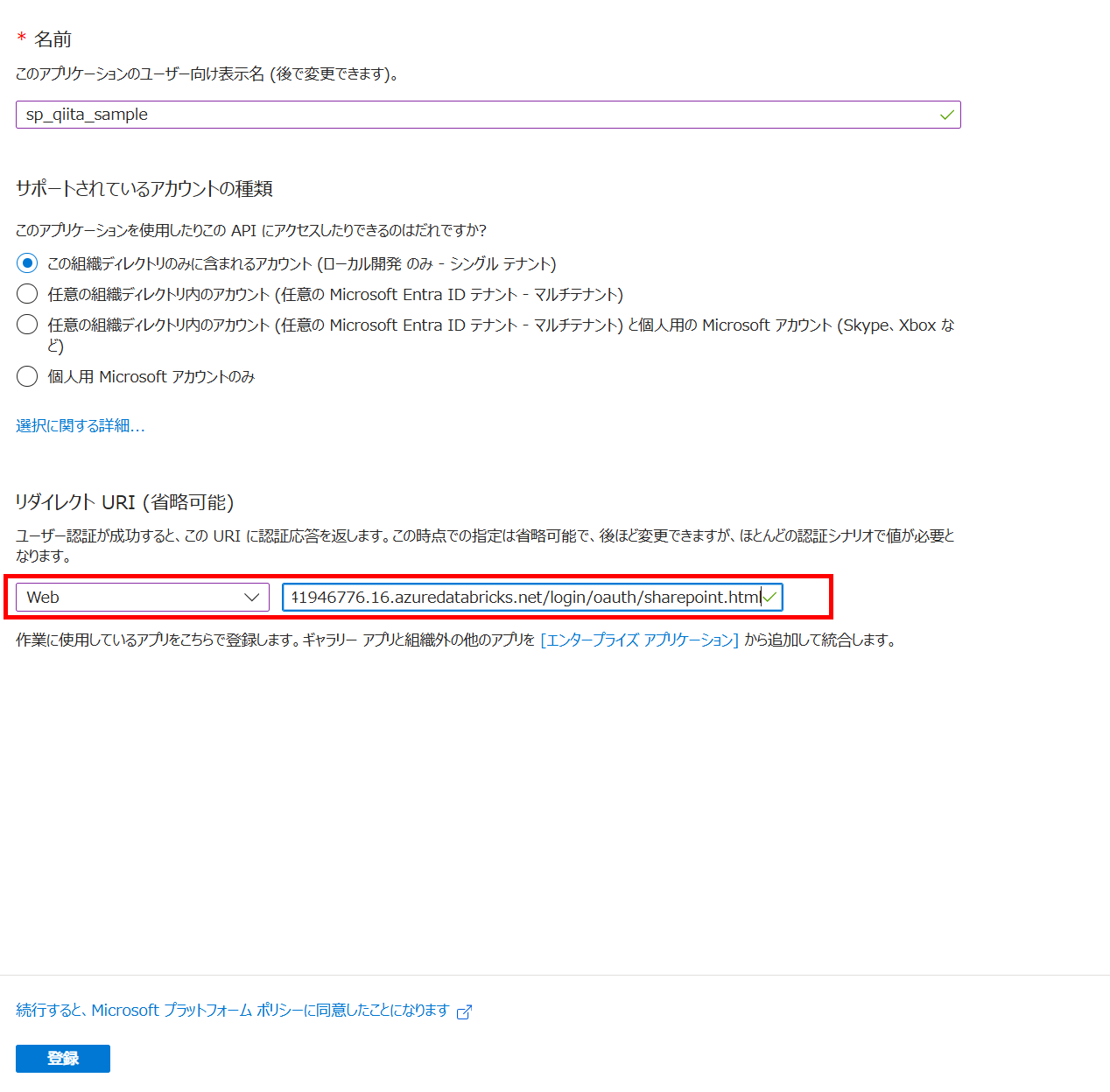
参考:設定後の値
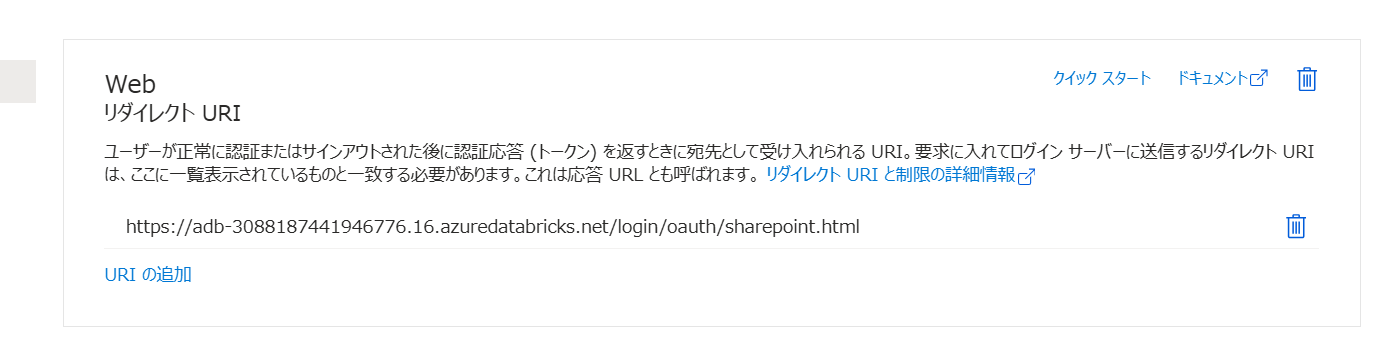
U2M認証を採用したため、サービスプリンシパルには権限を付与する必要はありません。ただし、後続手順で認証を行うユーザーアカウントの離任などに備える場合にはもう少し手順を変える必要があると思います。
あらかじめ Sharepoint にアクセスできる専用の Entra ID ユーザーを払い出しておくのが簡単だと思います。
UnityCatalog 上での接続オブジェクト作成(管理者側の作業)
マネージド インジェスト ソースに接続するに従って進めます。
ここに関してはあまり難しいところはないので参考のキャプチャのみを記載します。
-
名前などの設定
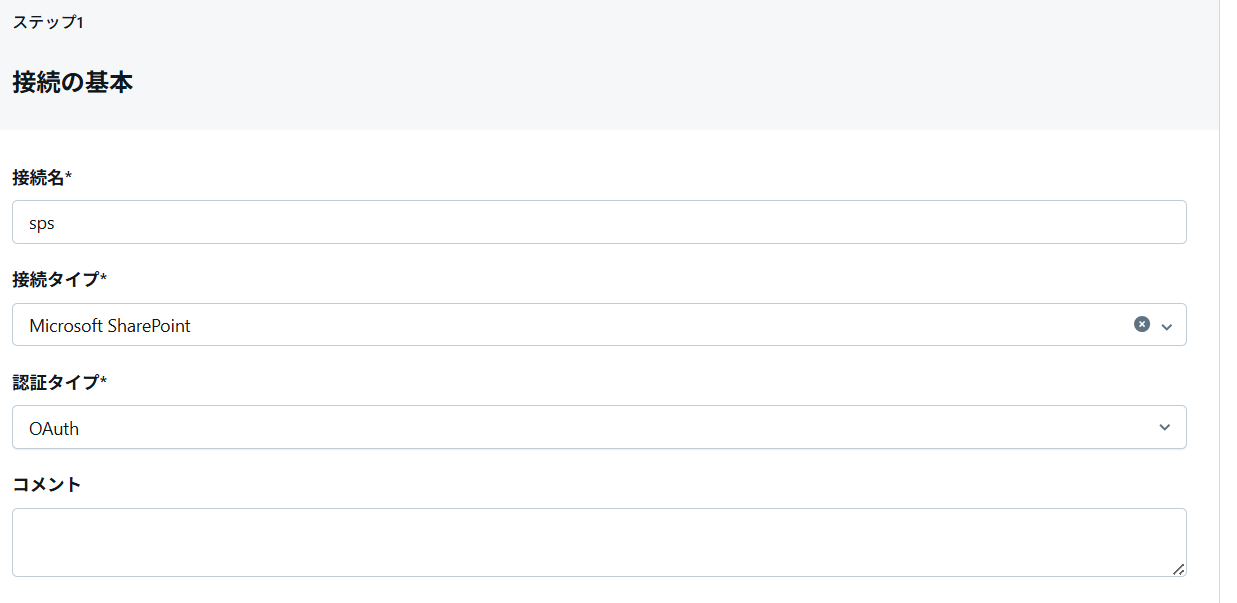
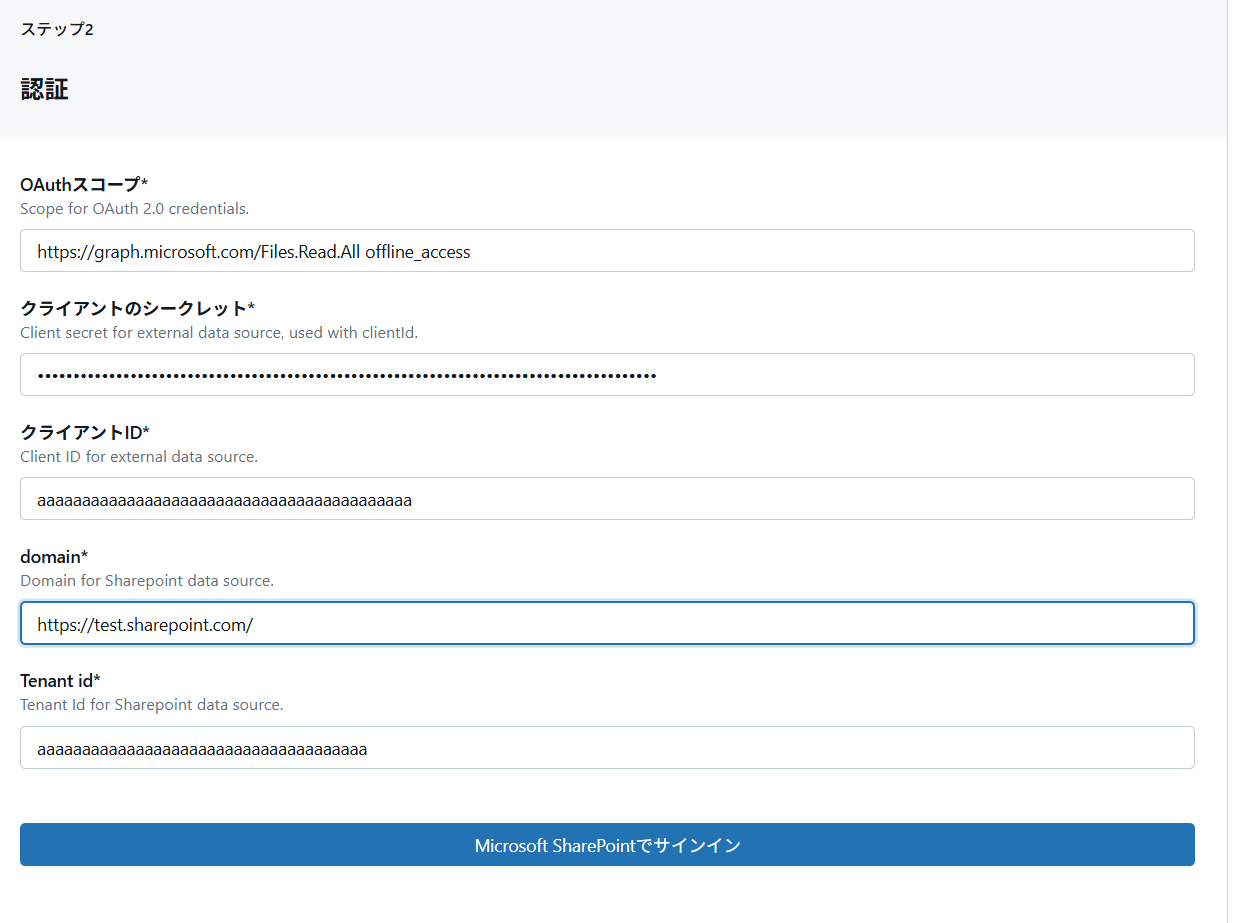
-
セットアップで作成したサービスプリンシパル情報と接続先の Sharepoint ドメイン。冒頭に確認したサイトの URL 先頭ですね。
-
サインインすると、サービスプリンシパル(アプリケーション)に 自分の 認可情報に基づいて API を使用する許可に関する確認が発生します。
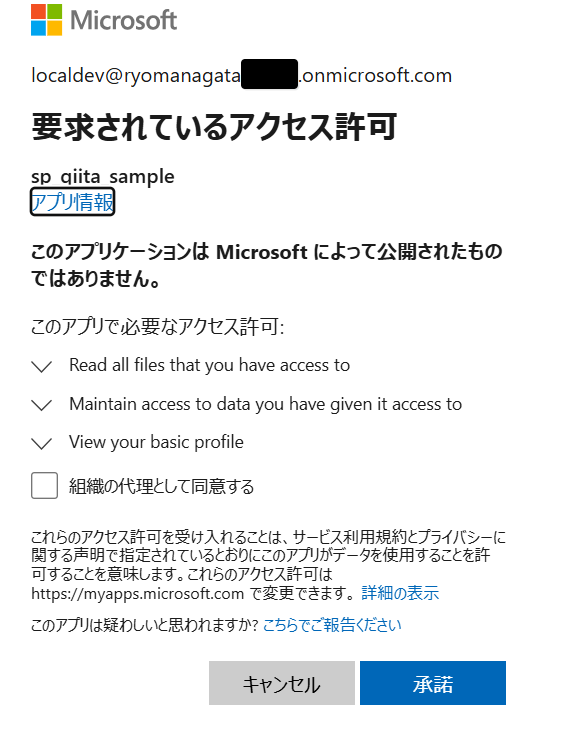
:::note warn
テナントの管理者以外が接続を作成する場合には、あらかじめサービスプリンシパルに API アクセス許可(委任)を許可してもらいましょう。
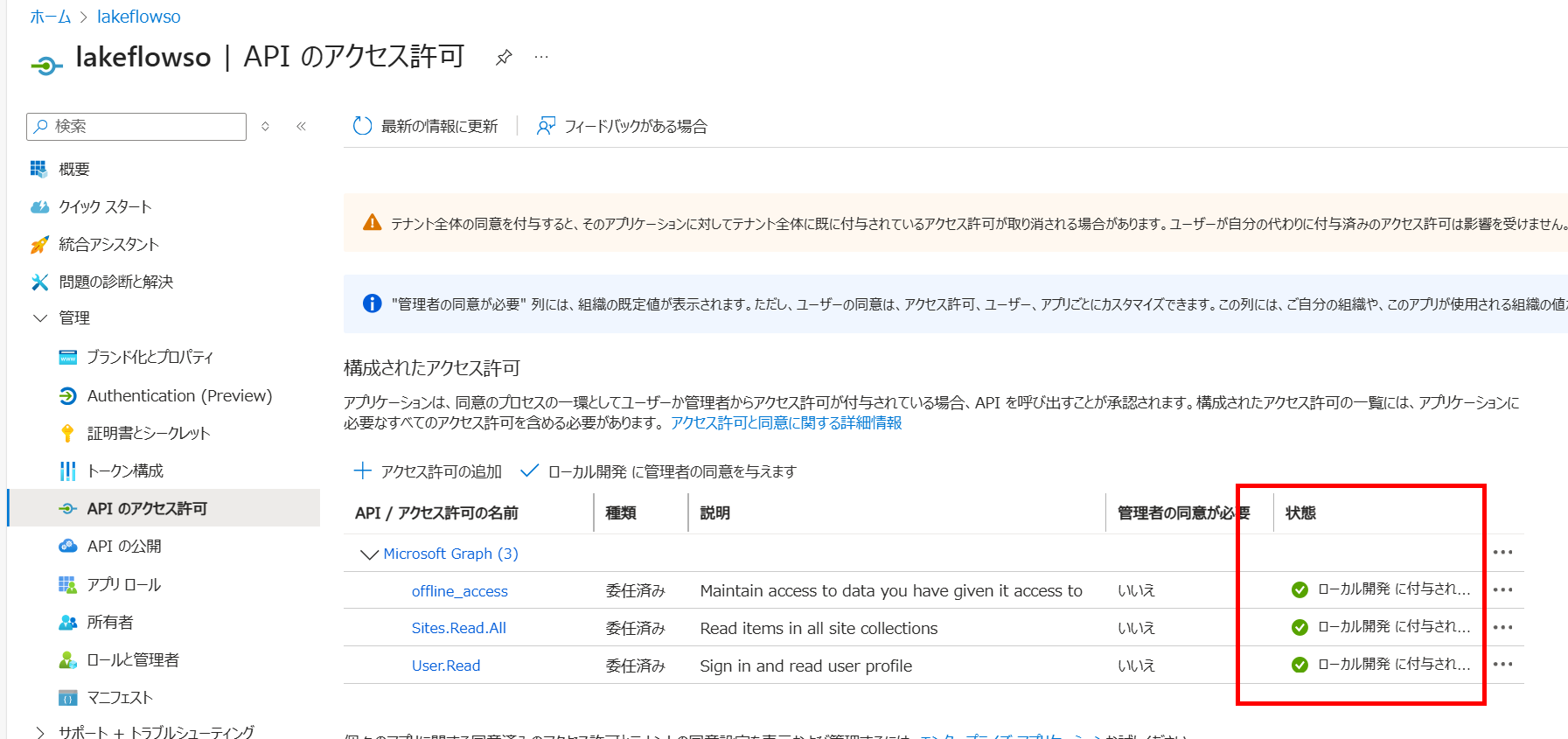
次の画面に進んだら接続の作成が完了します。
Ingest Pipeline の作成と実行
Microsoft SharePoint インジェスト パイプラインを作成する のノートブックをインポートする形で進めます。
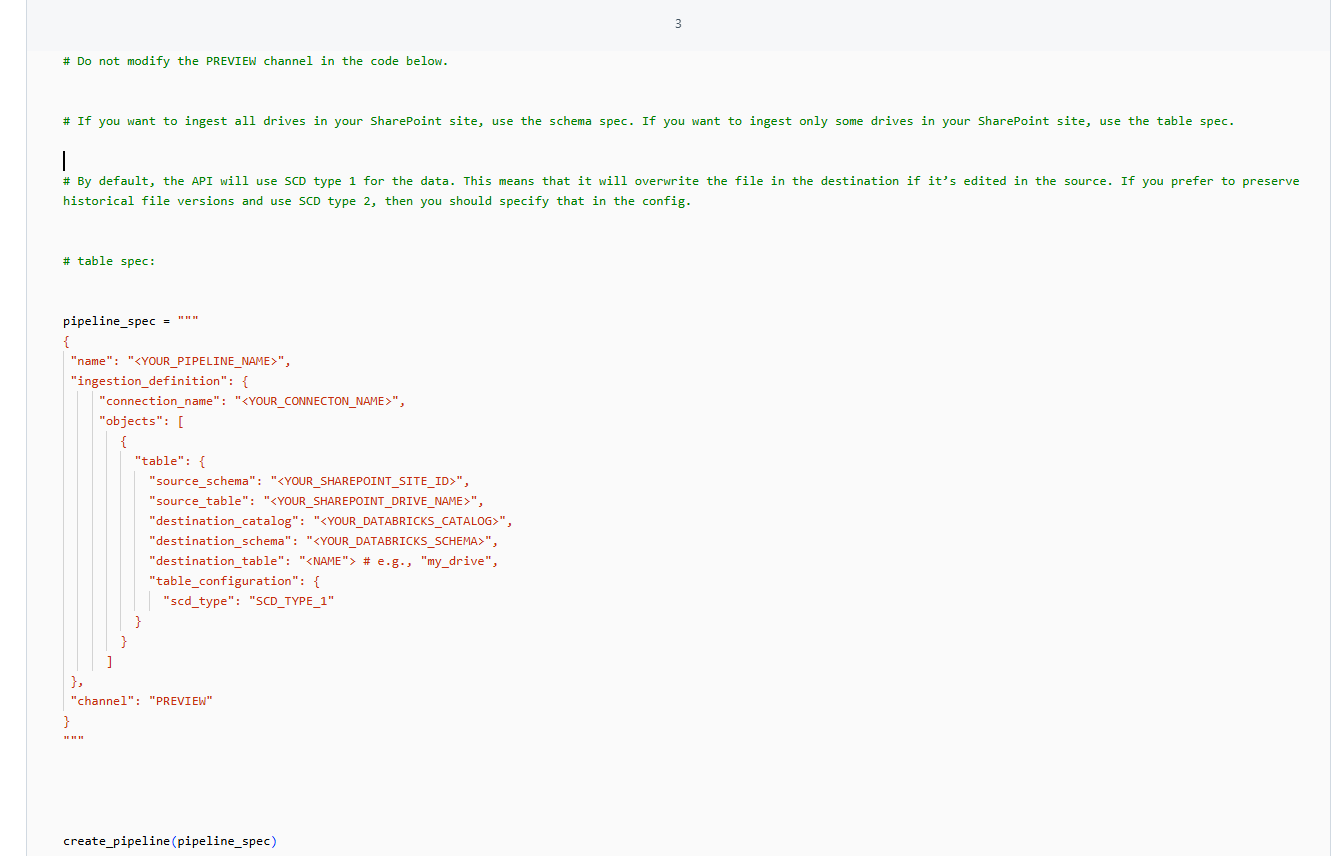
1. ライブラリを指定して取込むパイプラインの作成と実行
cell 3 の定義により作成します。
-
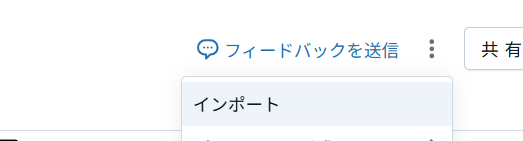
ノートブックのインポートにて URL を入力してインポートします。
-
ノートブックの修正
インポートしたノートブックをあらかじめ一部修正しておきます。
pythondef create_pipeline(pipeline_definition: str): - response = requests.post(url=api_url, headers=headers, data=pipeline_definition) + response = requests.post( + url=api_url, + headers=headers, + data=pipeline_definition.encode('utf-8') + ) check_response(response)また、json の崩れを補正します。
pythonpipeline_spec = """ { "name": "<YOUR_PIPELINE_NAME>", "ingestion_definition": { "connection_name": "<YOUR_CONNECTON_NAME>", "objects": [ { "table": { "source_schema": "<YOUR_SHAREPOINT_SITE_ID>", "source_table": "<YOUR_SHAREPOINT_DRIVE_NAME>", "destination_catalog": "<YOUR_DATABRICKS_CATALOG>", "destination_schema": "<YOUR_DATABRICKS_SCHEMA>", "destination_table": "<NAME"> # e.g., "my_drive", "table_configuration": { "scd_type": "SCD_TYPE_1" + } } } ] }, "channel": "PREVIEW" } """
既存のサンプルノートブックのままだとエラーとなります。
-
日本語文字列のエンコーディング漏れ
日本語環境では ライブラリの名前は "ドキュメント" など日本語になるので、前処理が必要です。
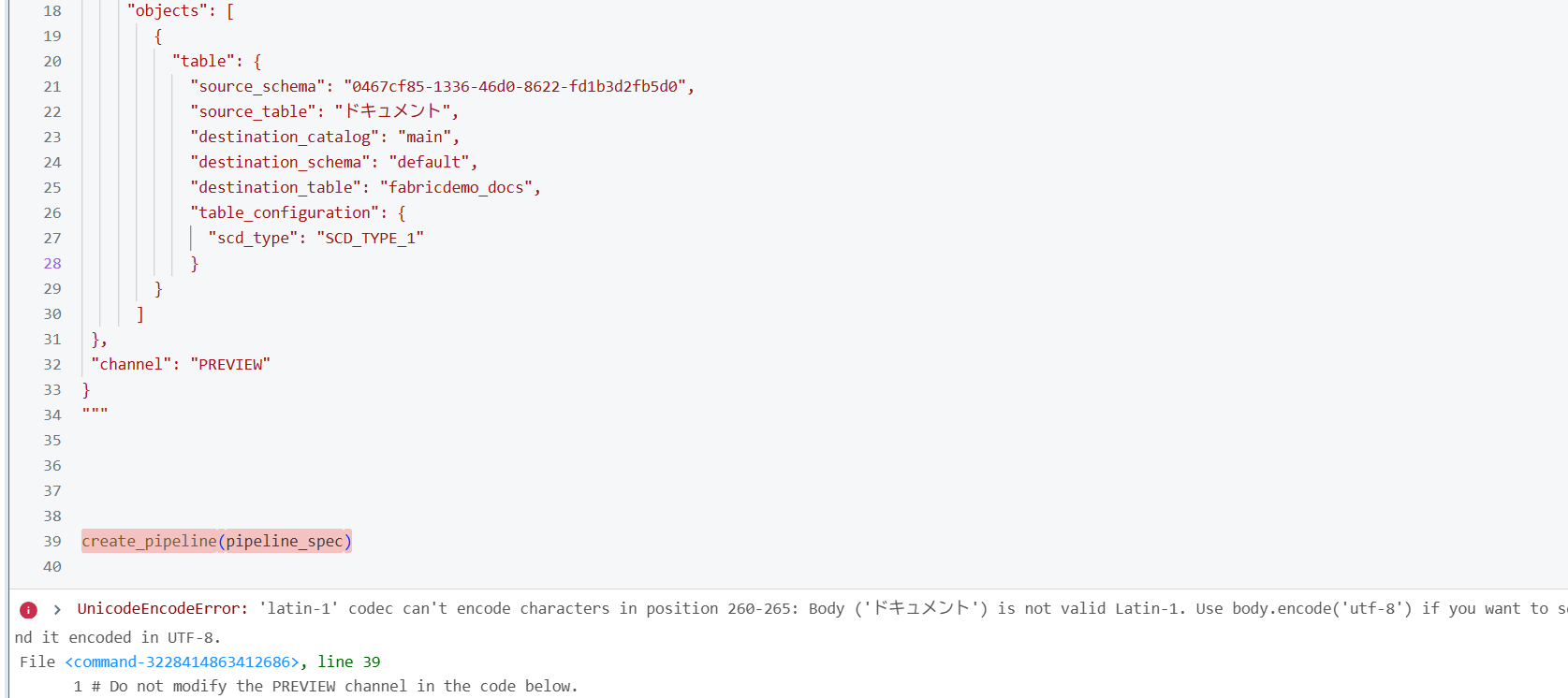
-
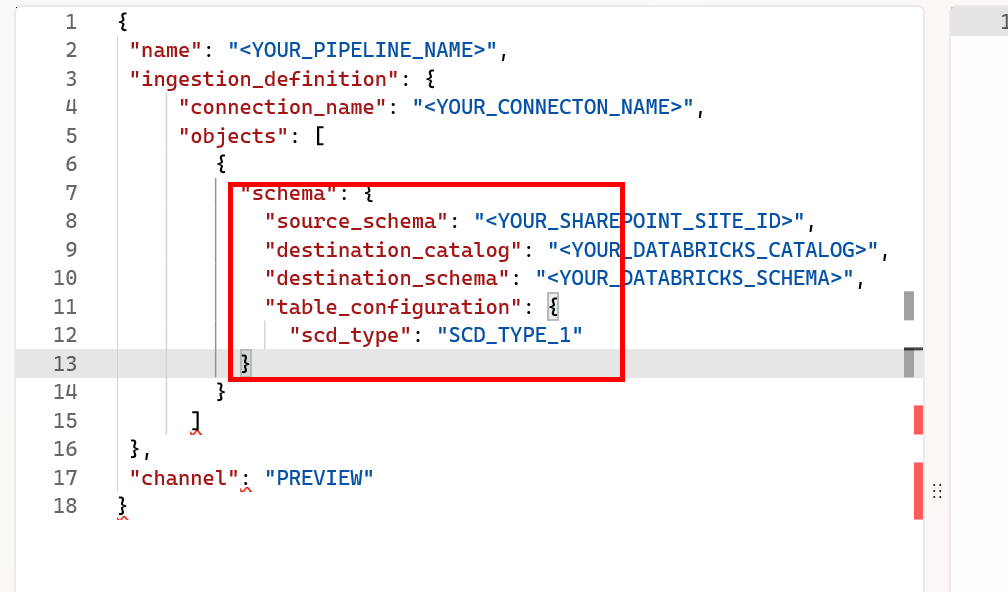
json のフォーマット崩れ
table_configrationのプロパティが閉じてません
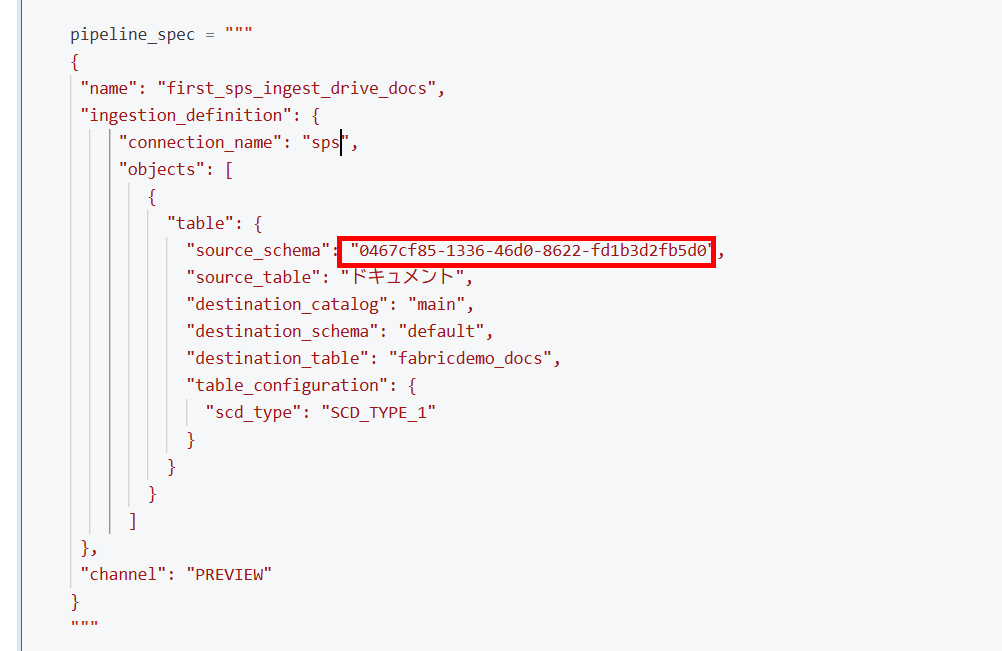
3.定義を設定します。ここでサイトIDを使用します。
2. 取り込み結果の確認
-
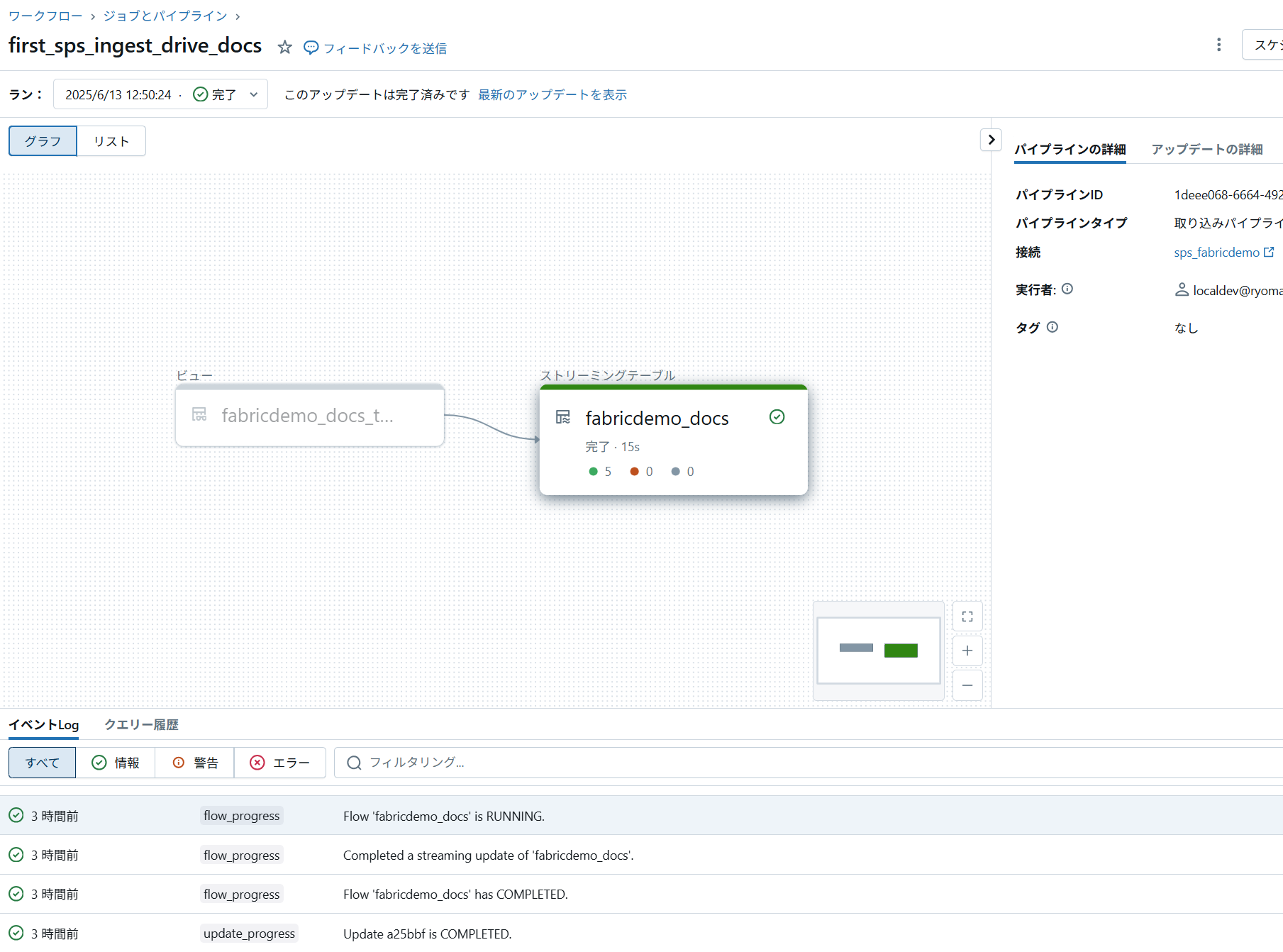
パイプラインを実行します。
-
取込結果は以下のようになりました。
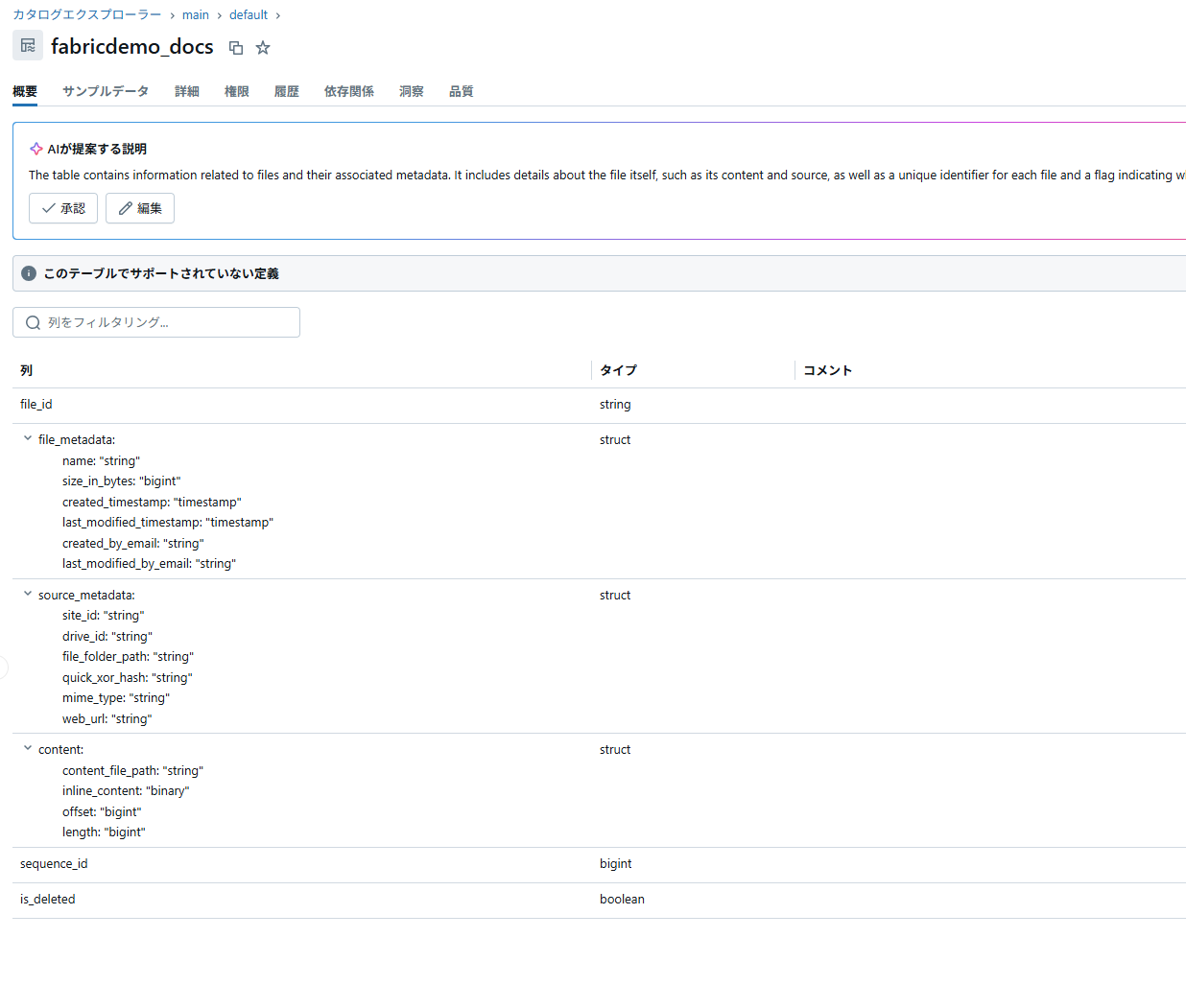
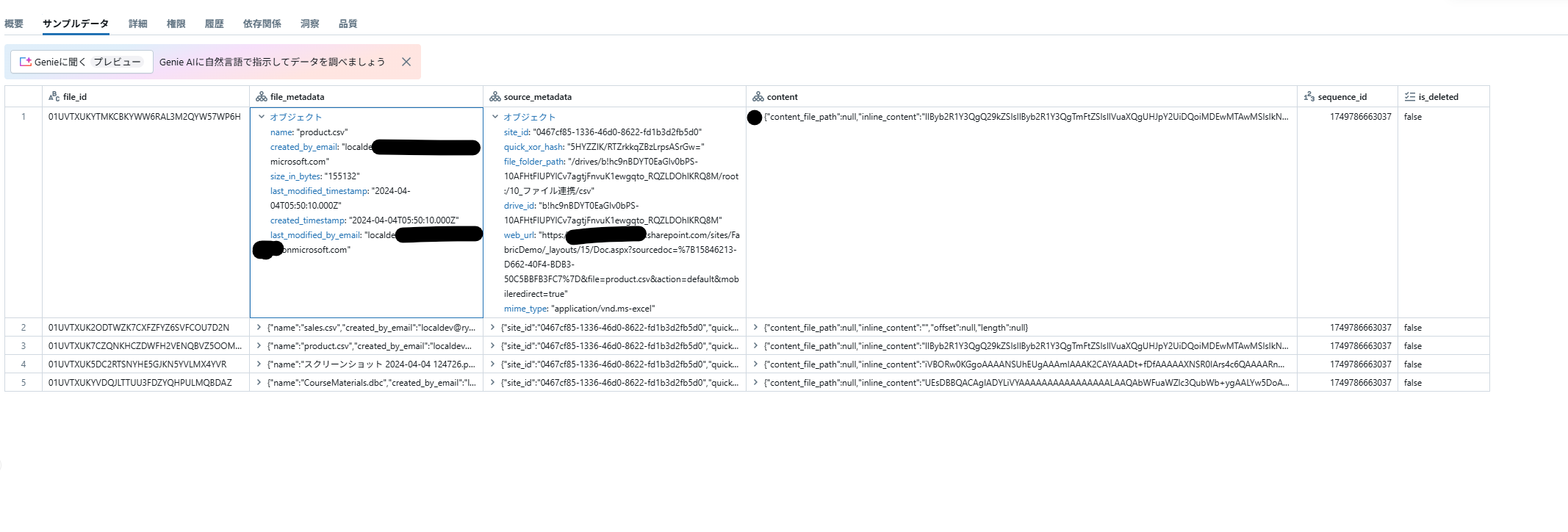
ファイルパスは、soure_metadata.file_folder_path に Sharepoint API (Get driveItem) で利用される
/drives/{drive-id}/root:/{item-path}の形式のスキームとなり、
ファイルの内容は、バイナリの値がcontent.inline_content に格納されるようです。
ファイルの内容については、ダウンストリームRAGの使用例 のように UDF 経由でアクセスすることが推奨されます。ここについてはまた次回。
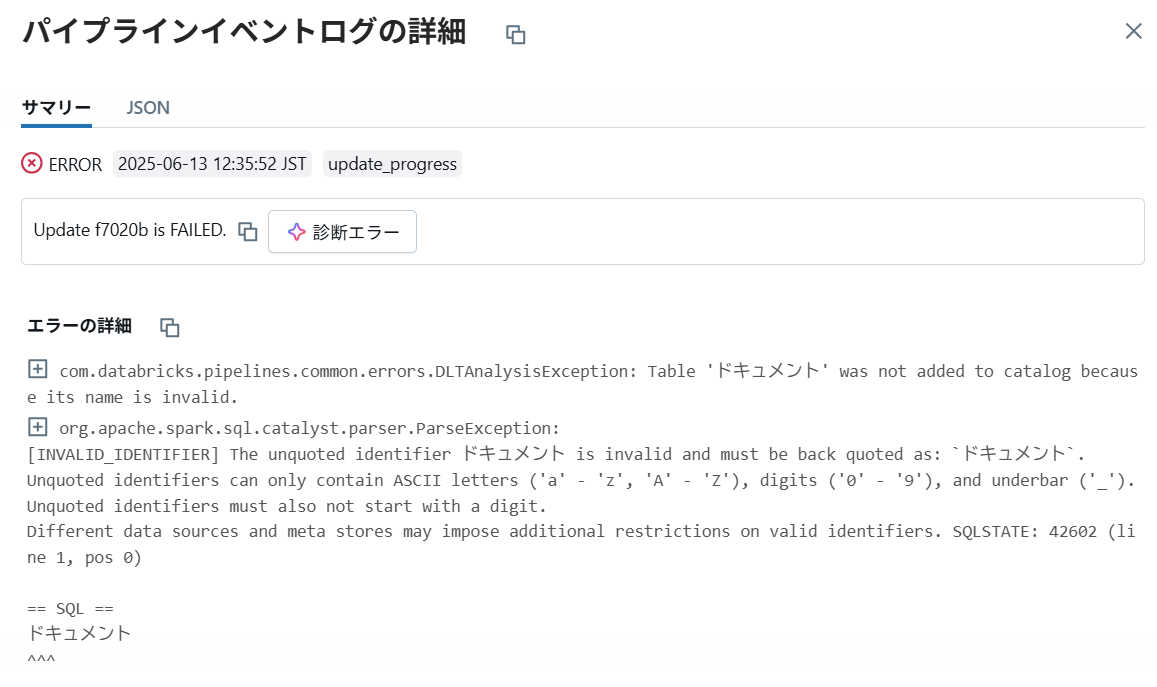
(日本語環境では不可)サイト全体を取込むパイプライン
ライブラリ名を指定しない cell 2 の定義を使用する場合、日本語環境では以下のようなエラーとなります。
ライブラリ名に基づいてテーブル名を作成しようとして、バッククォートなしで日本語を入力していると思われます。
所感
圧倒的に簡単で、なによりサービスプリンシパルに対してあらかじめ権限を与えるのではなく、ユーザーの権限で委任する仕組みが推奨として採用されているのが非常に扱いやすいと感じました。
Sharepoint ライブラリの連携は、Fabric/ADF データパイプラインでの取得などありますが、現在Graph API によるセットアップに関する情報公開が追い付いていないため、Lakeflow Connect が第一におすすめできるソリューションだと思いました。
日本語環境での対応と、そうした細かい取り回しについて内部実装を確認できないことは少し気になりますが、 GA の際には改善されることを期待しています。