はじめに
マルチプロトコルアクセスによりPolybaseがAzure Data Lake Storage Gen2で実施可能になったのですが、ドキュメントのサンプルコードだとストレージキー認証での例しかなかったので、サービスプリンシパルによる認証の方法を残します。
以下、Azure Synapse AnalyticsはDWと記載します。(Azure Synapse Analyticsってなんて略せばいいんだ。。)
仕組み
ドキュメントから転載
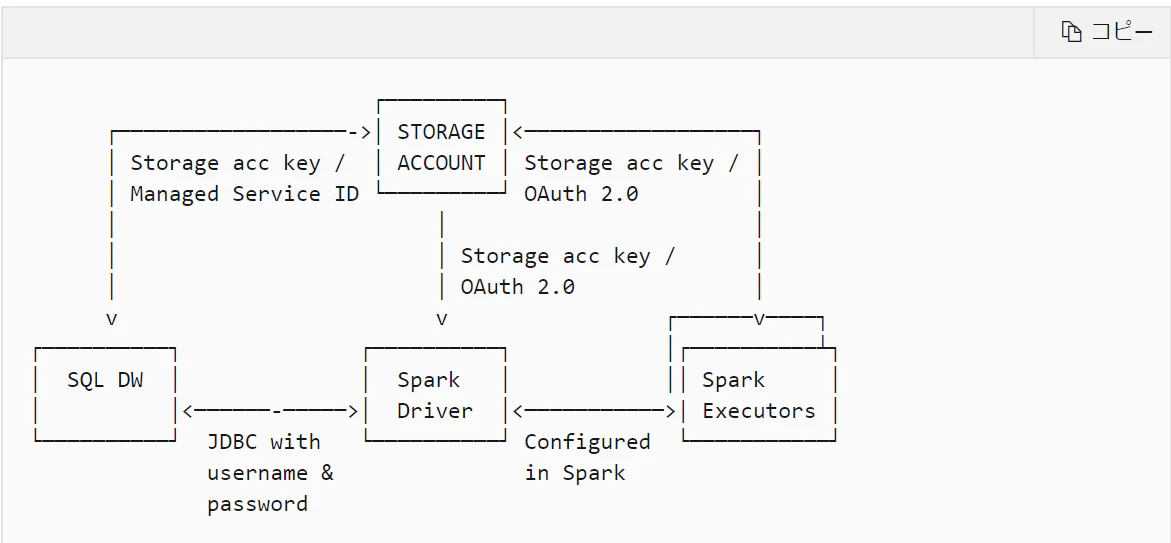
※めっちゃAAずれるのでスクショ
Managed Service IDとOAuth 2.0を使います。
上述通り、ドキュメントのサンプルコードだとStorage Account アクセスキーの例しかありません。
手順
サービスプリンシパルを準備~Storage AccountのBLOBデータ共同作成者ロールに割り当てる
マウントと同じですね。ドキュメントにもまとまっているので、割愛します。
Create Master Keyを実行する
DW上で実行してください
CREATE MASTER KEY
SQL ServerをAADに登録して、Managed IDを発行する
コード
Connect-AzAccount
Select-AzSubscription -SubscriptionId <subscriptionId>
Set-AzSqlServer -ResourceGroupName <your-database-server-resourceGroup> -ServerName <your-SQL-servername> -AssignIdentity
SQL ServerのManaged IDをStorage AccountのBLOBデータ共同作成者ロールに割り当てる
上記のコード発行で SQL Serverのリソース名でManaged IDが選択できるようになります。することはサービスプリンシパルと同様です。割愛。
Databricksのコード
pythonで書きます。Scalaもほぼ一緒です。
まず、PolybaseにはURIでアクセスできるStorageが必要です。spark.confで認証設定を作成しましょう
ドキュメントだと、fs.azure.account.auth.type.acctname.とか書いてあってはまりました。
accctnameは変更する箇所なんです。
filesystem = <FileSystem名>
storageaccount = <ストレージアカウント名
tenantID = <テナントID>
app_id = <サービスプリンシパルのアプリケーションID>
app_secretkey = <サービスプリンシパルのキー>
spark.conf.set("fs.azure.account.auth.type."+storageaccount+".dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type."+storageaccount+".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id."+storageaccount+".dfs.core.windows.net", app_id)
spark.conf.set("fs.azure.account.oauth2.client.secret."+storageaccount+".dfs.core.windows.net",app_secretkey )
spark.conf.set("fs.azure.account.oauth2.client.endpoint."+storageaccount+".dfs.core.windows.net", "https://login.microsoftonline.com/"+ tenantID +"/oauth2/token")
次にSQL Serverのjdbc接続文字列を生成します。
ここもほんとはサービスプリンシパルの認証でいきたいですが、わかりませんでした。scalaなら探せばありそうかも?
(※サポートの回答では現時点ではサポートされていませんでした 2020/01時点)
servername = <SQL Serverのリソース名>
databasename = <SQL DWのリソース名>
password = <SQL Server認証のパスワード>
username = <SQL Server認証のユーザID>
sql_dw_connection_string = "jdbc:sqlserver://{}.database.windows.net:1433;database={};user={}@{};password={};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;".format(servername, databasename, username,servername, password)
dataframeを作成後、DWにPolybaseロードします。(dataframe作成は割愛。)
target_table_name = <テーブル名>
temp_dir_url = "abfss://"+filesystem+"@"+storageaccount+".dfs.core.windows.net/" #Polybase用領域のURI
df.write \
.format("com.databricks.spark.sqldw") \
.option("url", sql_dw_connection_string) \
.option("useAzureMSI", "true") \
.option("dbtable", target_table_name) \
.option("tempdir", temp_dir_url) \
.mode("overwrite") \
.save()
ポイントは
.option("useAzureMSI", "true")
ここです。これによりSQL DW -> ADLSの部分がManaged IDで認証されます。
ドキュメントでは
.option("forwardSparkAzureStorageCredentials", "true")
となっており、これは資格情報を自動的に検出するらしく、DW側で作ったスコープをURIから検出して実行されるように感じます。このオプションが有効だとManaged IDに権限あててもURIにアクセスできません。
おわりに
Azure Synapse Analyticsの登場でDatabricksがどうなるかわかりませんが、SparkクラスタによるDWへのロードはなかなか威力があり、およそ1億レコードのロードも30分ほどで完了しました。
サービスプリンシパルによるjdbcの認証はわかり次第アップします~
備考
SQLDW の MSI認証によるpolybase