はじめに
Microsoft Fabric Semantic link での Power BI セマンティックモデルデータのファイルエクスポートを応用して、 利用状況レポート のデータを定期保存します。
手順
以下がセットアップされている状態から開始します。
- 利用状況レポート
- レイクハウス
利用状況レポートのモデルへの接続
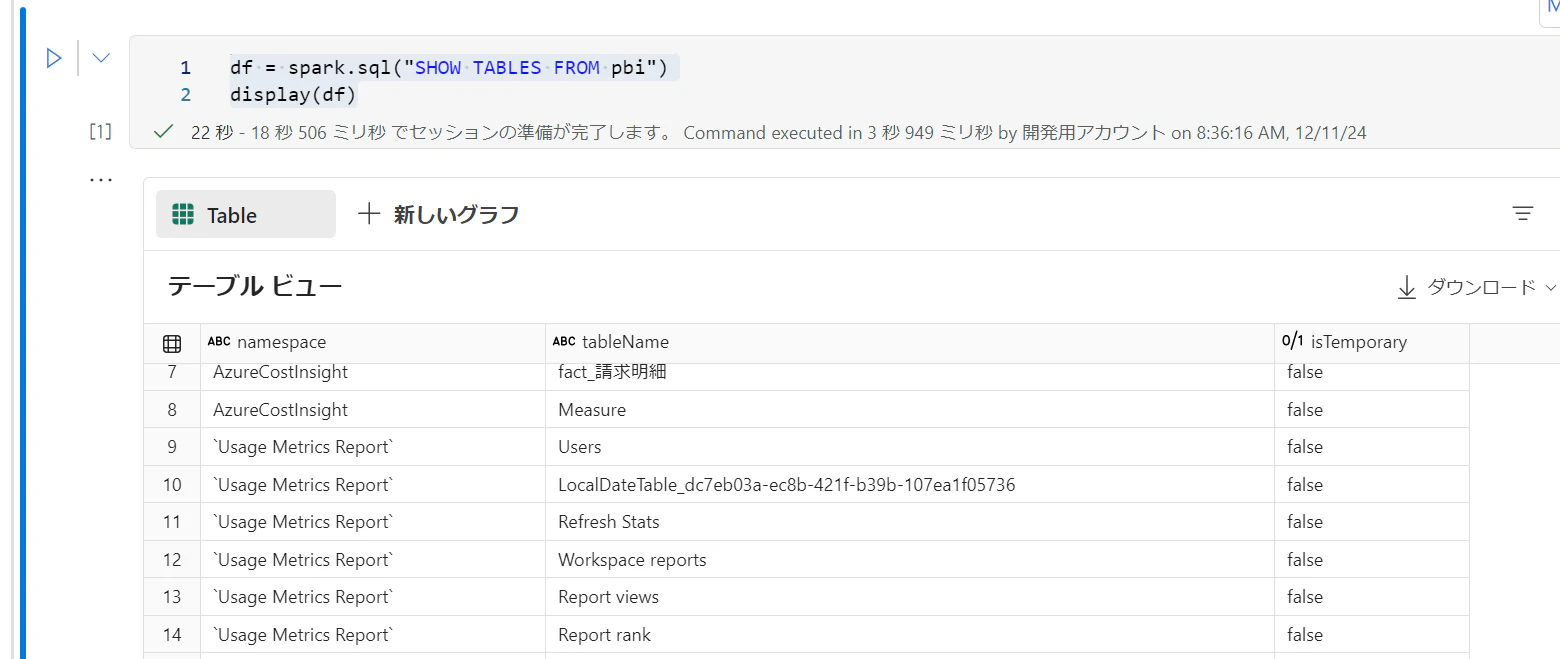
モデルを探し、対象テーブルのリストを取得します。
pyspark
df = spark.sql("SHOW TABLES FROM pbi")
display(df)
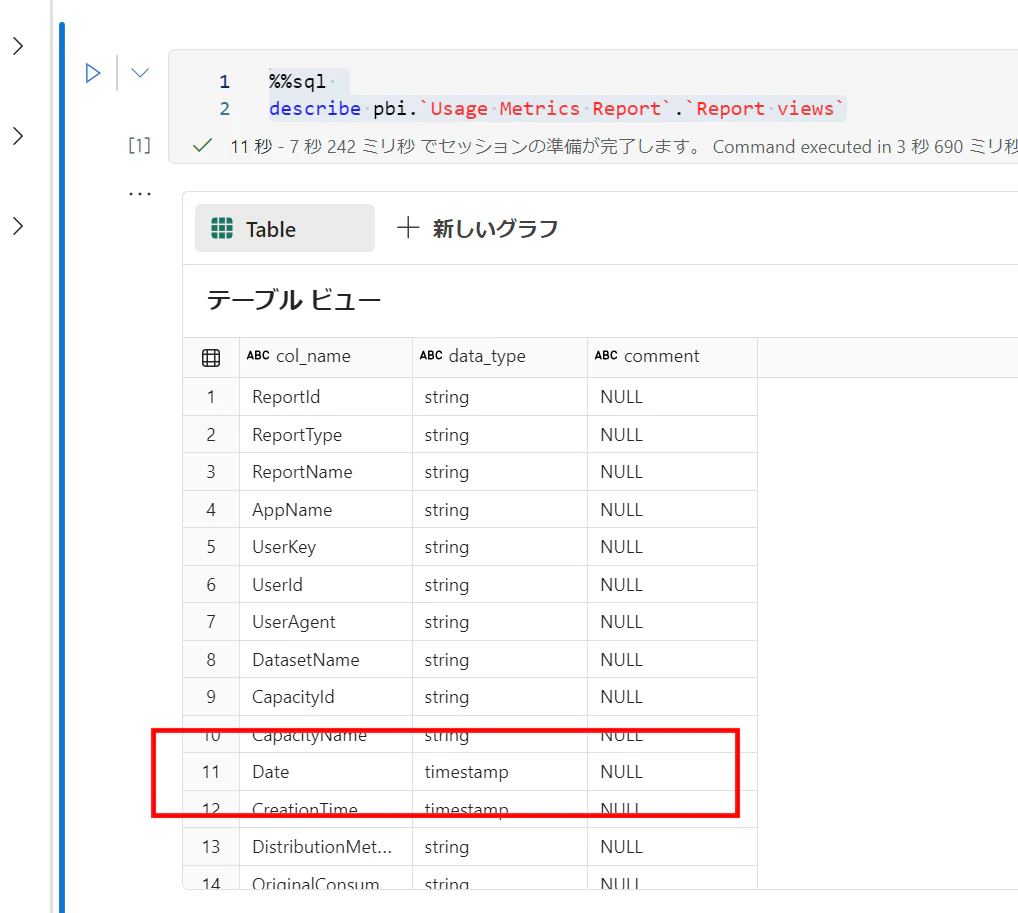
テーブルのスキーマなどを確認します。列を確認し、日付項目があることがわかります
pyspark
%%sql
describe pbi.`Usage Metrics Report`.`Report views`
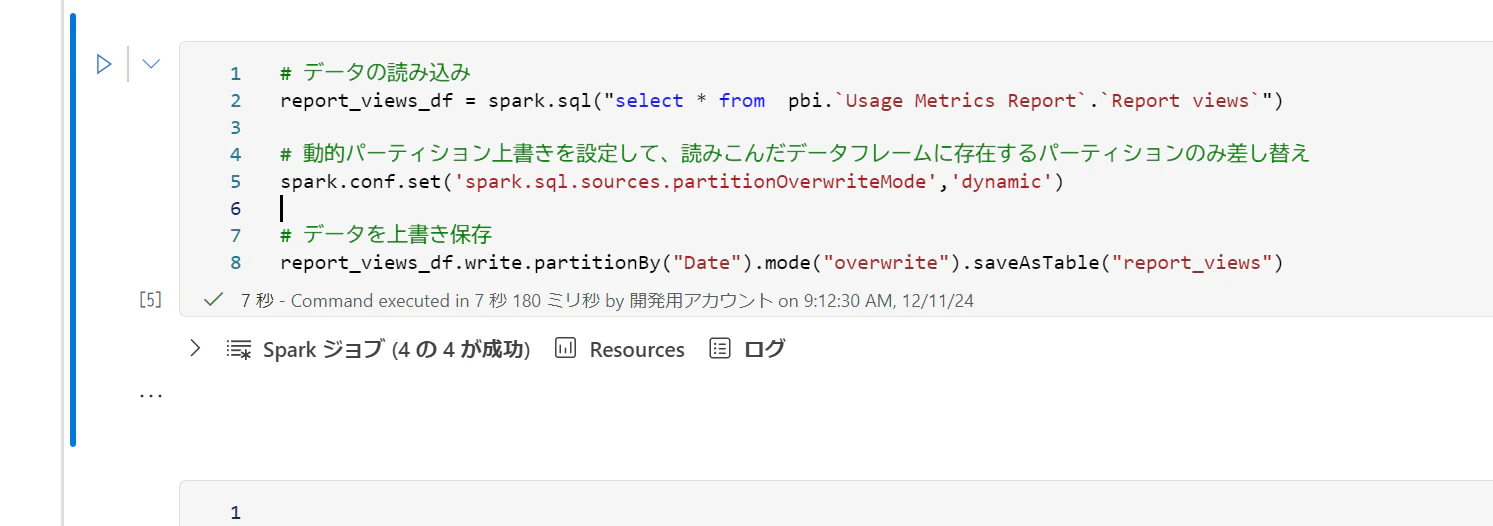
データの取込みと保存 (日付を含むデータ)
日付データはパーティションを使って増分更新するのが楽です。モデルで取得可能な直近30日間のデータを上書きます。
pyspark
# データの読み込み
report_views_df = spark.sql("select * from pbi.`Usage Metrics Report`.`Report views`")
# 動的パーティション上書きを設定して、読みこんだデータフレームに存在するパーティションのみ差し替え
spark.conf.set('spark.sql.sources.partitionOverwriteMode','dynamic')
# データを上書き保存
report_views_df.write.partitionBy("Date").mode("overwrite").saveAsTable("report_views")
レイクハウスに保存できました。
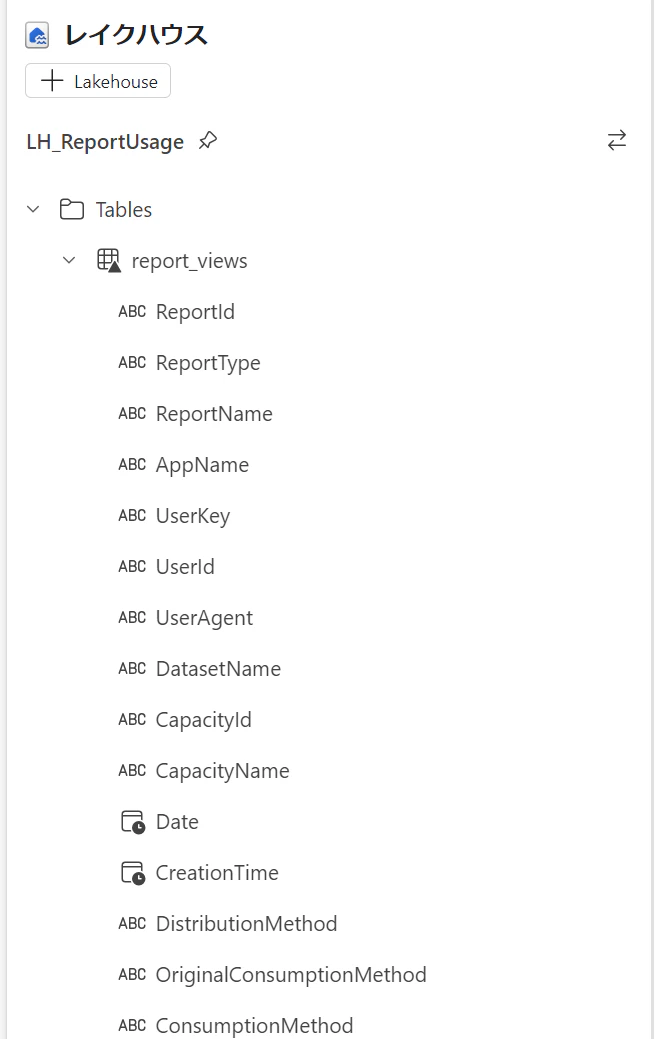
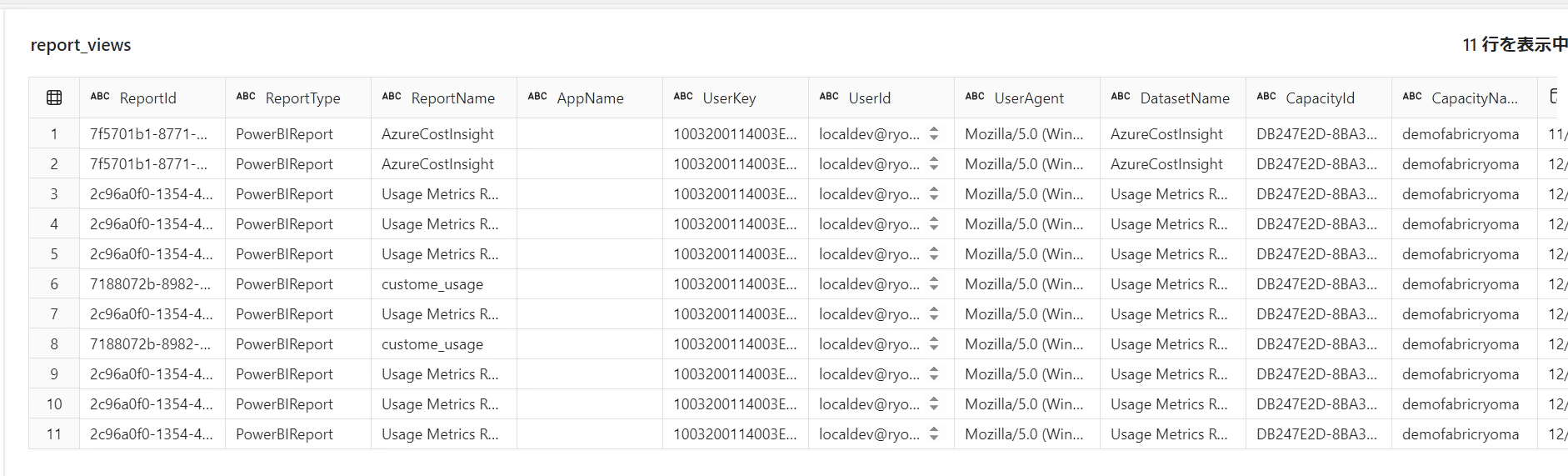
date列でパーティション分割されており、動的パーティション上書きを設定した Spark セッションではパーティション単位で更新がされます。
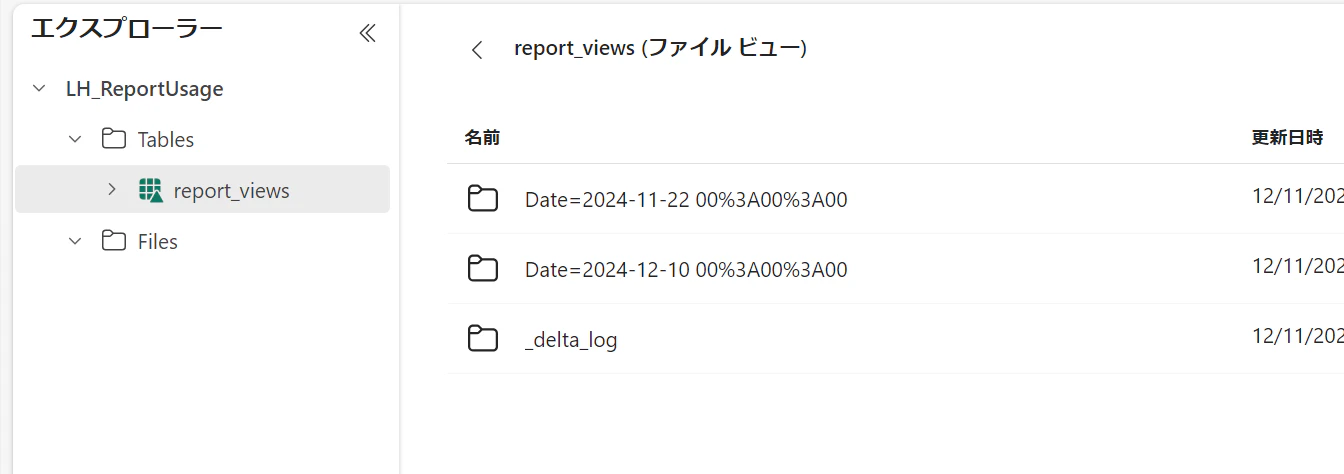
データの取込みと保存 (日付を含まないデータ)
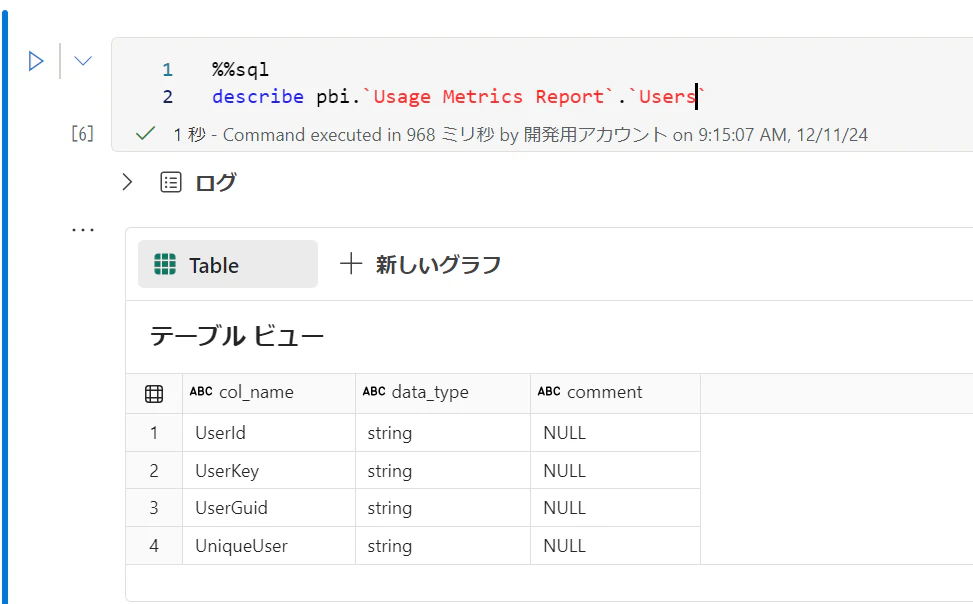
マスタ的な情報は日付を含まないので、履歴化の必要がなければパーティション分割せずにそのまま上書きします。
pyspark
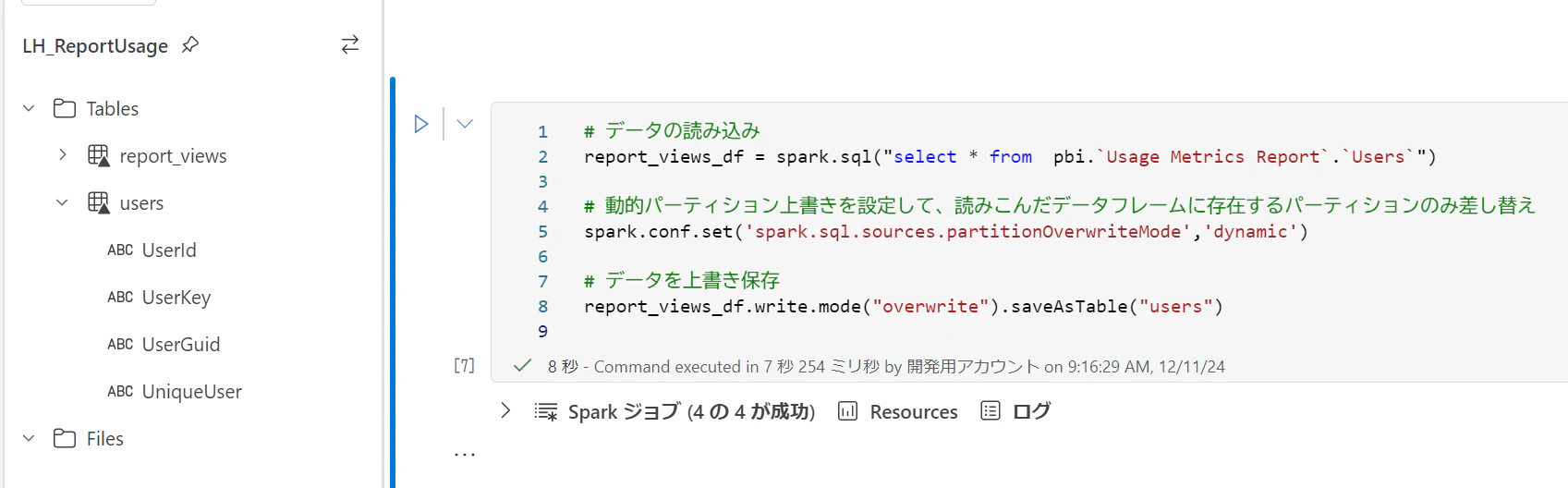
# データの読み込み
report_views_df = spark.sql("select * from pbi.`Usage Metrics Report`.`Users`")
# データを上書き保存
report_views_df.write.mode("overwrite").saveAsTable("users")
ただし、上記の初回ロードを実行するコードは以下のようにUPSERT の処理に差し替えます。
これで長期間データを蓄積した場合のユーザーなどの増減にも対応できます。
pyspark
%%sql
MERGE INTO users AS target
USING (
SELECT * FROM pbi.`Usage Metrics Report`.`Users`
) AS source
ON target.UserId = source.UserId
WHEN MATCHED THEN
UPDATE SET *
WHEN NOT MATCHED THEN
INSERT *
あとはこの処理をパイプラインか、ノートブックのスケジュール設定で自動実行されるようにすればOKです。
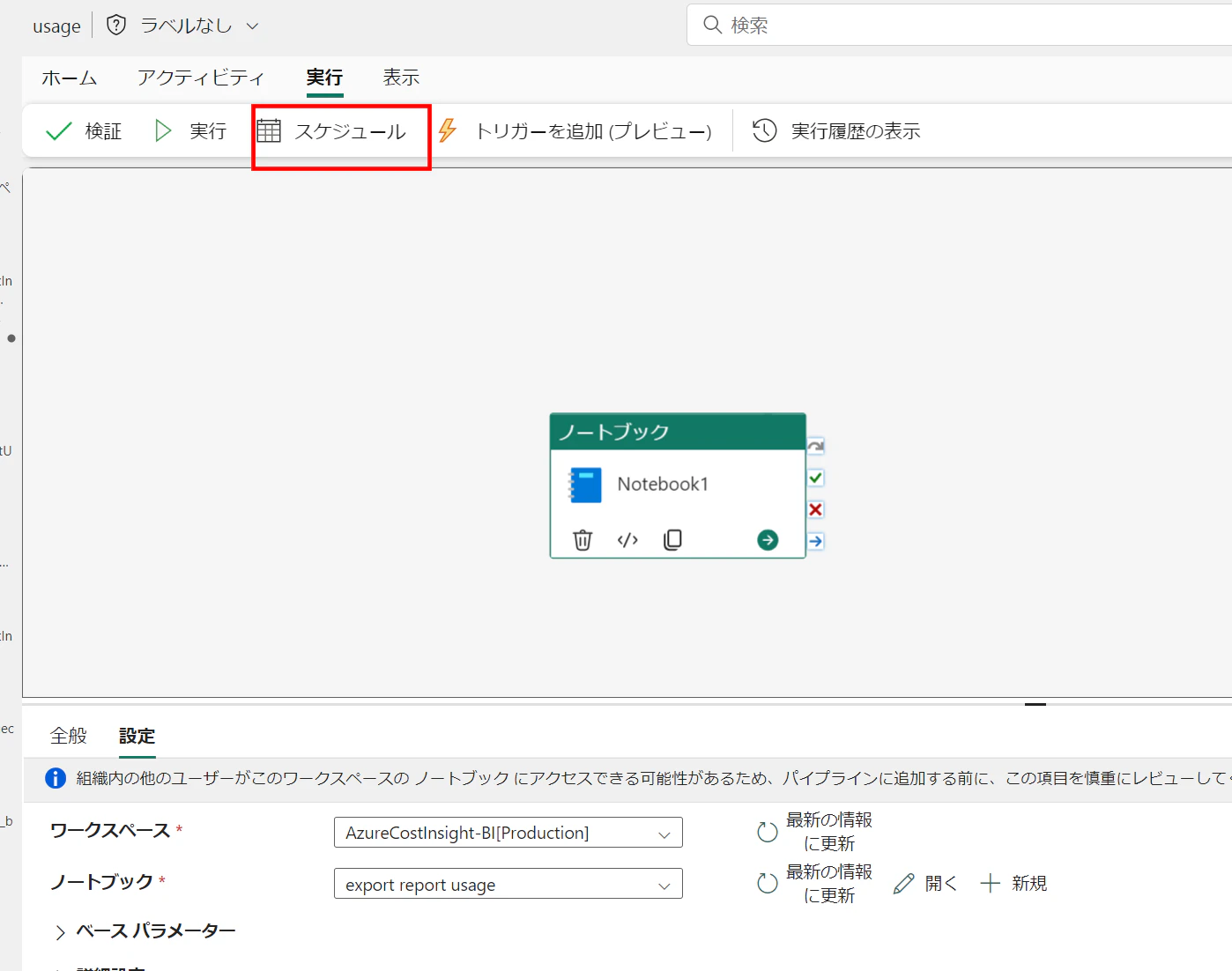
補足
データ取得前に手動で更新する場合には以下のコードを実行します。
pyspark
import sempy.fabric as fabric
workspace_id = "workspace の id を入力" #URLのgroups/~ にて取得
datasets_df = fabric.list_datasets(workspace_id)
display(datasets_df) #確認
pyspark
dataset_id = datasets_df[datasets_df['Dataset Name'] == "Usage Metrics Report"]['Dataset ID'].values[0]
dataset_id #確認
pyspark
import time
# セマンティックモデル更新
refresh_request_id=fabric.refresh_dataset(dataset_id,workspace_id)
# 初期ステータスと終了時間を設定
status = ''
end_time = None
# ステータスが 'Completed', 'Failed', 'Disabled', 'Cancelled' になるまでループ
while status not in ['Completed', 'Failed', 'Disabled', 'Cancelled'] or end_time is None:
# リフレッシュの実行詳細を取得
refresh = fabric.get_refresh_execution_details(dataset_id, refresh_request_id, workspace_id)
status = refresh.status
end_time = refresh.end_time
# ステータスと終了時間を表示
print(f"Current status: {status}, End time: {end_time}")
# 少し待機してから再度チェック
time.sleep(5)
# ステータスに応じたメッセージを表示
if status == 'Completed':
print("Refresh completed successfully!")
elif status == 'Failed':
print("Refresh failed. Please check the logs for more details.")
elif status == 'Disabled':
print("Refresh was disabled by selective refresh.")
elif status == 'Cancelled':
print("Refresh was canceled successfully.")
else:
print("Refresh status is unknown. Please check the logs for more details.")
次回
この状態だとレポートで利用されている メジャーの結果などが保存されないので次回はメジャー結果で保存してみます。