はじめに
Unity Catalog が出たことで色々とアップデートが必要だったので Azure Databricks と Azure Data Lake Storage Gen2への接続のパターンについてまとめ
Azure Databricks と Azure Data Lake Storage Gen 2上のデータを扱ううえでは、アクセス方法、認証方法、ネットワーク構成方法の3点が重要となるためこれを解説する
Azure Data Lake Storage Gen 2 と Azure Blob Storage の表記の使い分けについて
- Azure Data Lake Storage Gen 2 はAzure Blob Storage の拡張機能となるので、Azure Blob Storage でも利用可能な部分に関しては、Azure Blob Storage と表記
アクセス方法
Databricks では、データへのアクセス方法はテーブルアクセス or ファイルアクセス と大きく二つの方法にわかれる
テーブルアクセス
テーブル名によるアクセスはレイクハウス上で標準的な方法となる
# 構文:spark.table("<table name>")
spark.table("default.mytable")
-- 構文:SELECT * FROM <table name>
SELECT * FROM default.mytable
テーブルが対象としているパスについてはマネージドテーブルかアンマネージドテーブルかに左右され、アンマネージドテーブルの時にはパスを指定することになる(参考)
- アンマネージドテーブル
/*
構文:
CREATE TABLE my_table LOCATION '<path>'
USING <format>
*/
CREATE TABLE my_table LOCATION 'abfss://container@storageAccount.dfs.core.windows.net/external-location/path/to/table'
USING DELTA
- マネージドテーブルでは、あらかじめ環境に指定されるストレージで自動的にディレクトリが形成されるため、ユーザーが意識することはない
- マネージドテーブル(非Unity Catalog 環境)であればDatabricksに既定で付属するストレージ上に保管される
- マネージドテーブル(Unity Catalog 環境)であればUnity Catalog で指定したメタストア用ストレージ内に保管される
CREATE TABLE my_table
USING DELTA
ファイルパスによるアクセス
投入対象など、テーブル化されていないデータにアクセスするのに利用する
※投入対象をアンマネージドテーブルとして管理する方法もとれる
# 構文:spark.read.format("<path>")
spark.read.format("abfss://container@storageAccount.dfs.core.windows.net/external-location/path/to/table")
-- 構文:SELECT * FROM <ファイル形式>.`<path>`
SELECT * FROM delta.`abfss://container@storageAccount.dfs.core.windows.net/external-location/path/to/table>`
ファイルパスに利用できるデータレイクのパス
クラウドストレージに一般的な方法である URL形式(ABFS URI) か、 マウント によりローカルファイルシステムのようにアクセスする
ABFS URI
Azure Blob Storage 上のデータを示すURIを直接記入する(推奨)
参考:Azure Data Lake Storage Gen2 の URI を使用する
# path構文:abfss://<container name>@<storage account name>.dfs.core.windows.net/<path>
spark.read.format("delta").load("abfss://container@storageAccount.dfs.core.windows.net/external-location/path/to/data")
Azure Blob Storage の場合、WASB URI として、wasbs://{container name}@{storage account name}.blob.core.windows.net/{path} と記載することになるが、Azure Databricks では現在 WASB URIを利用することは非推奨となった。
Microsoft は、Azure Blob File System ドライバー (ABFS) を優先することに伴って Azure Blob Storage 用の Windows Azure Storage Blob ドライバー (WASB) を非推奨にしました。
引用:WASB (レガシ) を使用した Azure Blob Storage への接続
DBFS マウントパス
あらかじめ Azure Storage 上のディレクトリをDatabricksファイルシステム上にマウントする。
これにより、ストレージアカウントを含めたURLや、認証情報などを spark のセッション内でコンフィグに設定したり把握せずにアクセスできる
現在Unity Catalog により、ストレージへの認証を一元管理し、監査を取得することが推奨の構成となったため、Unity Catalog の監査対象外となってしまうマウントパターンは非推奨。
Databricks では、マウントの使用からの移行と、Unity カタログを使用したデータ ガバナンスの管理を推奨しています。
引用:Azure Databricks へのクラウド オブジェクト ストレージのマウント
誰かが一度マウントすれば、ほかのユーザーはコンフィグ設定などが不要となるという点で取りまわしが楽になるため、非 Unity Catalog 環境ではマウント方式を利用するケースは多い。
ただし大きな欠点として、サービスプリンシパルが必要となり、サービスプリンシパルが用意できない場合、非推奨であるWASBドライバーでのマウントが必要。
## マウント構文
# dbutils.fs.mount(
# source = "abfss://<container name>@<storage account name>.dfs.core.windows.net/",
# mount_point = "/mnt/<path>",
# extra_configs = configs)
# マウント例
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
dbutils.fs.mount(
source = "abfss://data@storageAccount.dfs.core.windows.net/",
mount_point = "/mnt/adls/data",
extra_configs = configs)
# 読み取り
spark.read.format("delta").load("dbfs:/mnt/adls/data/mydir")
認証について
データ利用時のアクセス方式については以上の通りだが、それぞれの方式で認証方式がさらに選択可能
- Unity Catalog の External Location および、Storage Credentialsを利用する (推奨)
- 従来の方法
2-1. 資格情報を Spark Conf に設定する
2-2. マウント時に資格情報をマウント用のconfig として設定する
Unity Catalog の External Location および、Storage Credentialsを利用する
Unity Catalog 上で、External Location について権限をもつユーザーが資格情報を指定せずにアクセス可能とする方式
方式イメージ:
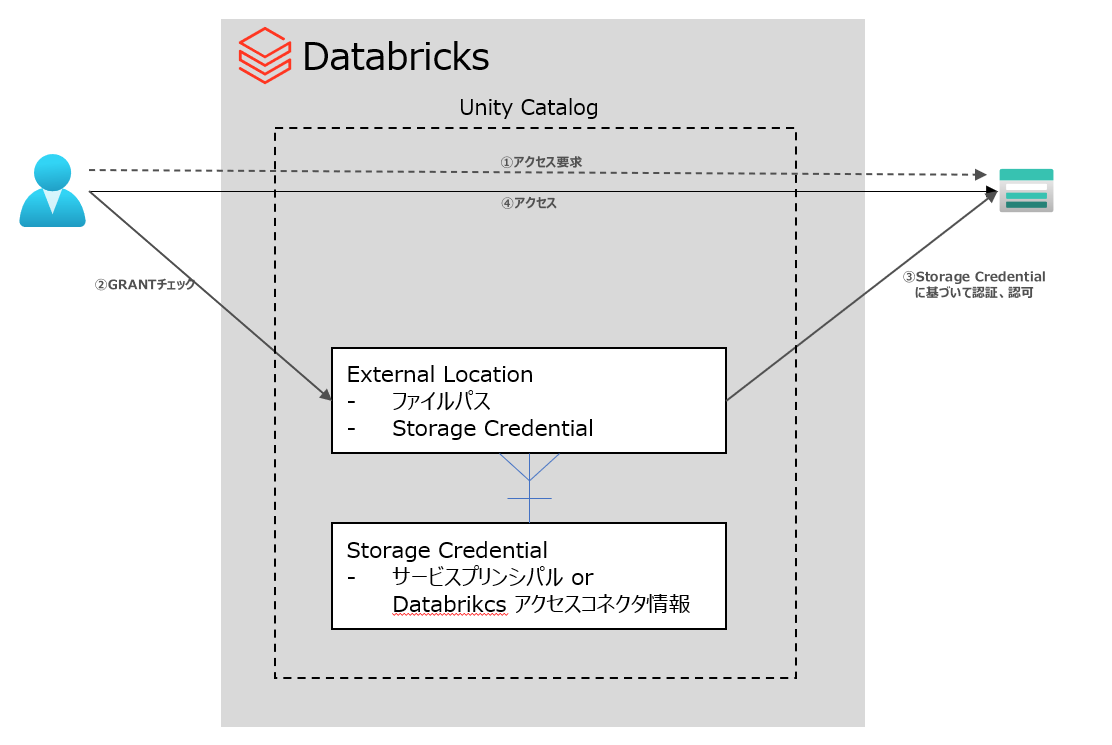
Pros:Unity Catalogによる完全なガバナンス
Cons:Unity Catalogのセットアップが必要となり、構成の難易度が高い
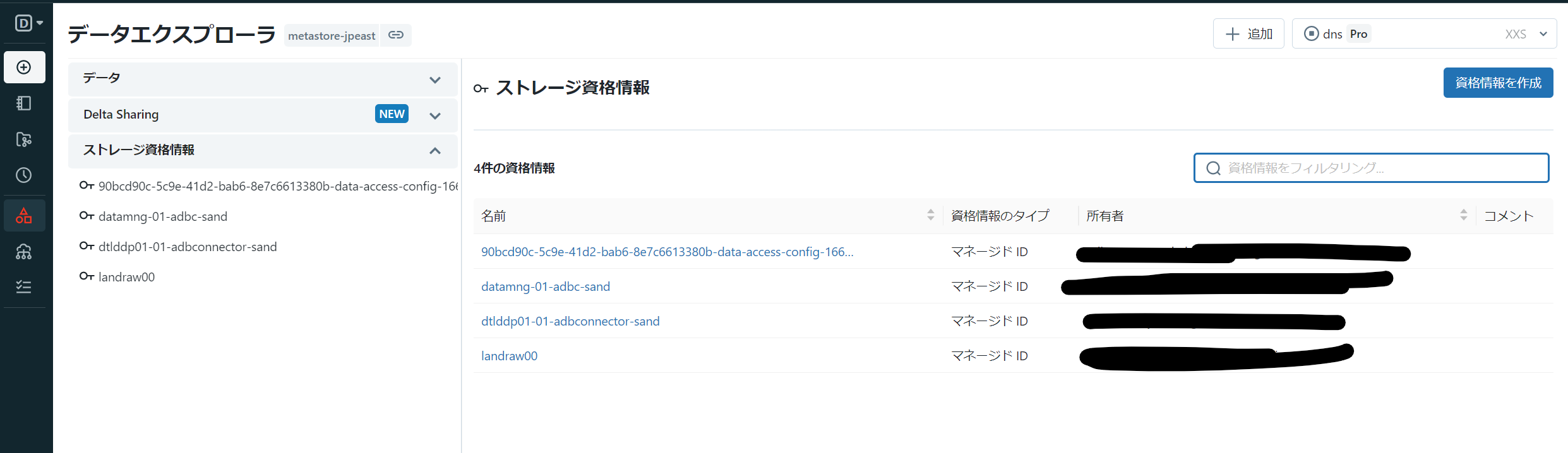
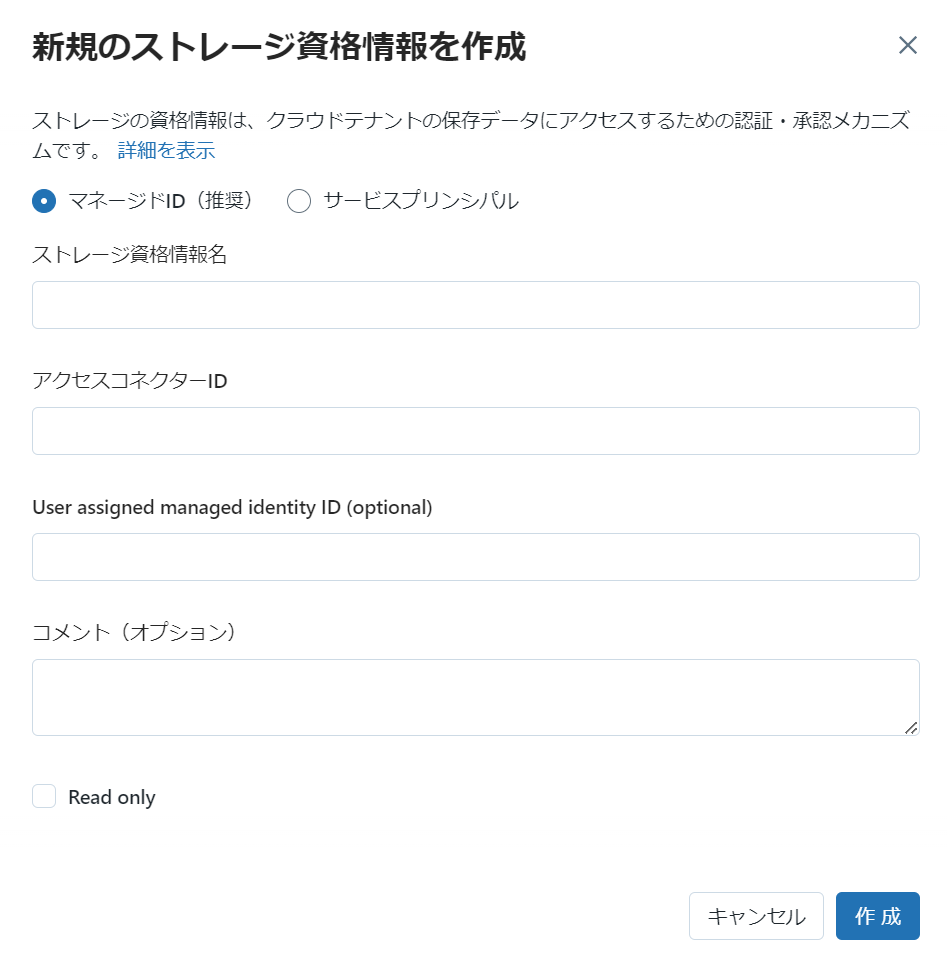
Unity Catalog メタストアに割当てられた Databricks では、このようにストレージ資格情報欄から資格情報を作成できる
資格情報が作成できたら、External Locationを作成する
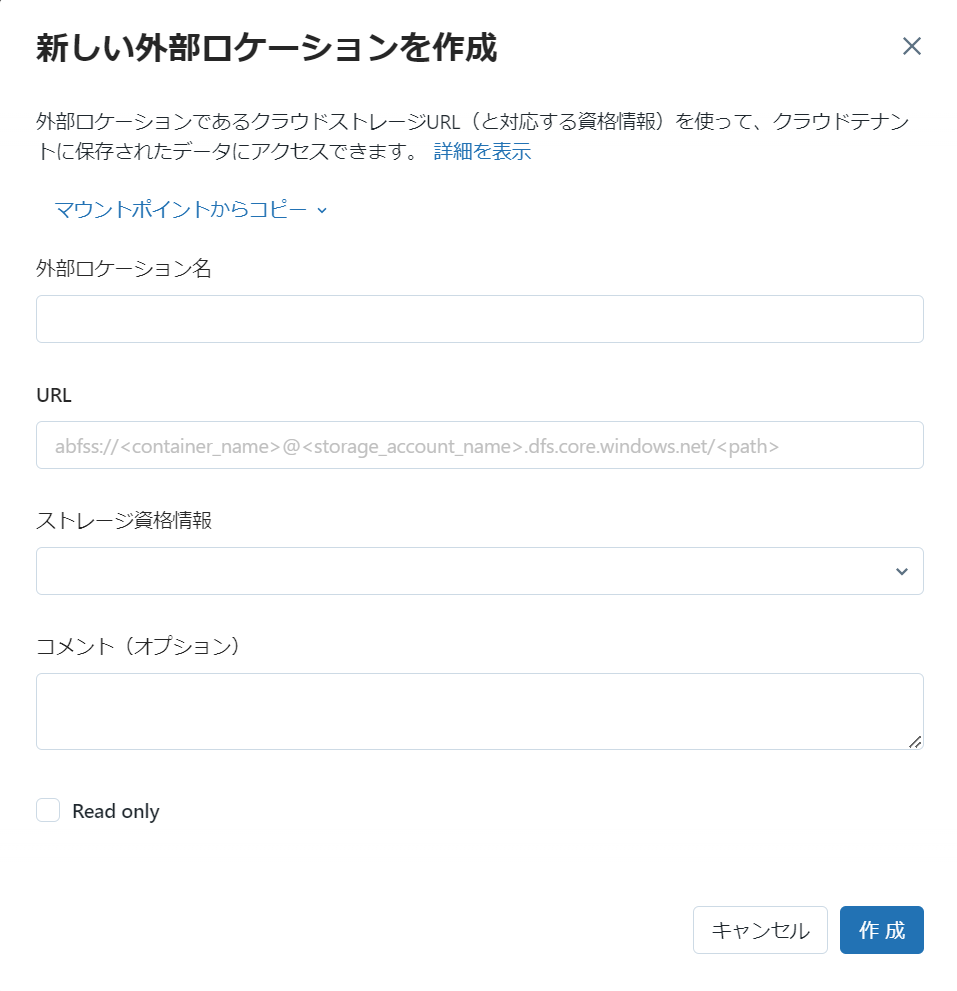
コードで実行する場合、構文は以下の通り
CREATE EXTERNAL LOCATION <location_name>
URL 'abfss://<container_name>@<storage_account>.dfs.core.windows.net/<path>'
WITH (STORAGE CREDENTIAL <storage_credential_name>);
各オブジェクトはGRANTにより、ユーザーに利用許可を与えられるが、Storage Credential を直接ユーザーに利用させるよりも、視覚情報とパスとの組み合わせとなる、External location をユーザーに利用させることが推奨となる
ストレージの資格情報に対してアクセス許可を直接付与できますが、Databricks では外部の場所でこれを参照し、代わりにアクセス許可を付与することをお勧めします。
External locationで権限が与えられたユーザーはストレージへの認証情報を構成することなくABFS URIでファイルアクセスが可能となります。
-- 外部の場所を使用してテーブルを作成するアクセス許可を付与する
GRANT CREATE EXTERNAL TABLE ON EXTERNAL LOCATION <location_name> TO <principal>;
-- 外部の場所からファイルを読み取るアクセス許可を付与する
GRANT READ FILES ON EXTERNAL LOCATION <location_name> TO <principal>;
従来の認証方法
従来の方法では、データレイクへアクセスするための構成情報をノートブックなどを通してUnity Catalog ではなくSpark Conf上などで定義することでアクセスする
※Unity Catalog 環境下では、External Location で管理している場所にABFS URI アクセスする場合、Spark Conf などで定義した認証用の構成情報は無視される
認証方式の違いで構成内容が分岐する
サービスプリンシパルを利用してアクセスする
サービスプリンシパルをデータアクセス用の代理IDとする方式
方式イメージ:
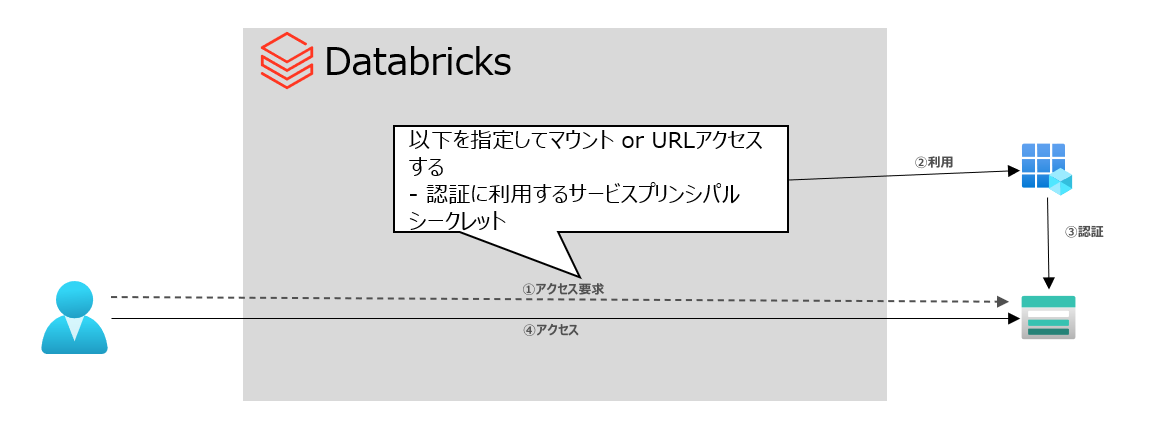
Pros:Azure AD認証およびAzure RBACでデータアクセス制御可能なため、Azure Data Lake Storage Gen2 のフォルダ、ファイル単位のアクセス制御を利用可能
Cons:ユーザー個々で認証されるわけではないので、データアクセスの監査はサービスプリンシパル単位となる
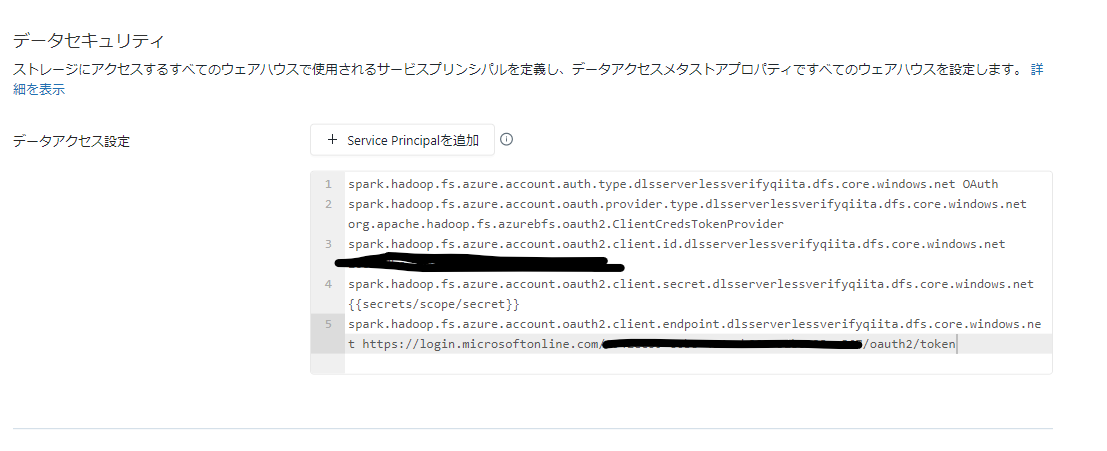
設定する構成情報
| 対象 ABFSアクセス の場合 | 対象 マウントの場合 | 値 | 備考 |
|---|---|---|---|
| fs.azure.account.auth.type.{storage-account名}.dfs.core.windows.net | fs.azure.account.auth.type.{storage-account名}.dfs.core.windows.net | OAuth | |
| fs.azure.account.oauth.provider.type.{storage-account名}.dfs.core.windows.net | fs.azure.account.oauth.provider.type.{storage-account名}.dfs.core.windows.net | org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider | |
| fs.azure.account.oauth2.client.id | fs.azure.account.oauth2.client.id | サービスプリンシパルのアプリケーションID | |
| fs.azure.account.oauth2.client.secret | fs.azure.account.oauth2.client.secret | サービスプリンシパルのシークレット | Databricksシークレットに格納することを推奨 |
| fs.azure.account.oauth2.client.endpoint | fs.azure.account.oauth2.client.endpoint | https://login.microsoftonline.com/{サービスプリンシパルの存在するテナントID}/oauth2/token |
あらかじめ、サービスプリンシパルの作成と、ストレージへの権限付与が必要。
参考:Azure Active Directory を使ってストレージにアクセスする
なお、SQL ウェアハウスの場合は類似の構成情報をSQL管理コンソールで登録することになる。
参考:データ アクセスの構成
SASトークン or アカウントキーを利用してアクセスする
ストレージアカウントで払出されるトークンかキーを使用して認証する方式
方式イメージ:
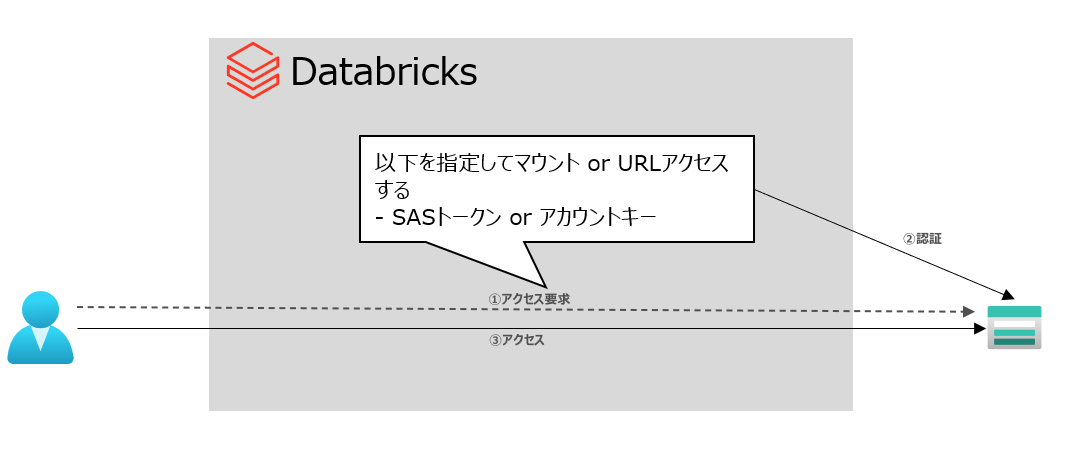
Pros:セットアップが簡単
Cons:Azure AD認証ではなく、ストレージ側での認証となり、ファイル、フォルダレベルのきめ細かいアクセス制御は不可となる。特にアカウントキーはストレージアカウント全体に対する全操作が可能なので注意。また、マウント時に非推奨のWASBドライバーを通してBlobを使う必要がある
SASトークンの場合
設定する構成情報
| 対象 ABFSアクセス の場合 | 対象 マウントの場合※blob利用 | 値 | 備考 |
|---|---|---|---|
| fs.azure.account.auth.type.{storage-account名}.dfs.core.windows.net | - | SAS | |
| fs.azure.sas.token.provider.type.{storage-account名}.dfs.core.windows.net | - | org.apache.hadoop.fs.azurebfs.sas.FixedSASTokenProvider | |
| fs.azure.sas.fixed.token.{storage-account名}.dfs.core.windows.net | fs.azure.sas.{コンテナ名}.{storage-account名}.blob.core.windows.net | SASトークンの値 |
アカウント キーの場合
設定する構成情報
| 対象 ABFSアクセス の場合 | 対象 マウントの場合※blob利用 | 値 | 備考 |
|---|---|---|---|
| fs.azure.account.key.{storage-account名}.dfs.core.windows.net | fs.azure.account.key.{storage-account名}.blob.core.windows.net | アカウントキーの値 |
Azure AD 資格情報パススルーを利用してアクセスする
方式イメージ:
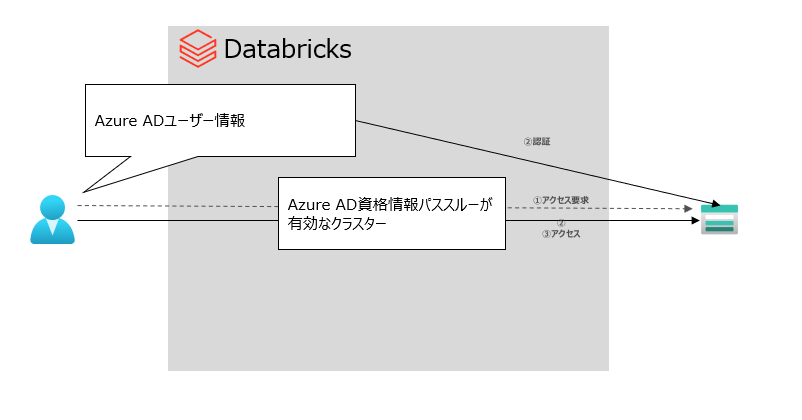
Pros:ユーザー個々にシークレットなどの構成情報を与える必要がなく、Azure AD 認証を使用しているので、ファイル、フォルダレベルのきめ細かいアクセス制御が可能
Cons:Azure Blob Storageでは、資格情報のパススルーはサポートされていない。
設定する構成情報
資格情報パススルー対応クラスターでは、ABFSアクセスの場合にはspark confの構成は特に不要
| 対象 ABFSアクセス の場合 | 対象 マウントの場合 | 値 | 備考 |
|---|---|---|---|
| - | fs.azure.account.auth.type | CustomAccessToken | |
| - | fs.azure.account.custom.token.provider.class | spark.conf.get("spark.databricks.passthrough.adls.gen2.tokentaProviderClassName") |
※資格情報パススルー対応クラスターは以下のチェックボックスをオンにする
(チートシート)従来の認証用の構文と利用例
サービスプリンシパル
ABFS URI アクセス
構文:
service_credential = dbutils.secrets.get(scope="<scope>",key="<service-credential-key>")
spark.conf.set("fs.azure.account.auth.type.<storage-account>.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.<storage-account>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.<storage-account>.dfs.core.windows.net", "<application-id>")
spark.conf.set("fs.azure.account.oauth2.client.secret.<storage-account>.dfs.core.windows.net", service_credential)
spark.conf.set("fs.azure.account.oauth2.client.endpoint.<storage-account>.dfs.core.windows.net", "https://login.microsoftonline.com/<directory-id>/oauth2/token")
使用例:
service_credential = dbutils.secrets.get(scope="akv",key="hoge01-secret")
spark.conf.set("fs.azure.account.auth.type.hogeStorageAccount.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.hogeStorageAccount.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.hogeStorageAccount.dfs.core.windows.net", "hogeappid99009>")
spark.conf.set("fs.azure.account.oauth2.client.secret.hogeStorageAccount.dfs.core.windows.net", service_credential)
spark.conf.set("fs.azure.account.oauth2.client.endpoint.<storage-account>.dfs.core.windows.net", "https://login.microsoftonline.com/hogetenantid0000/oauth2/token")
df = spark.read.format("delta").load("abfss://data@hogeStorageAccount.dfs.core.windows.net/external-location/path/to/data/")
マウントによるアクセス
構文:
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "<application-id>",
"fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope="<scope-name>",key="<service-credential-key-name>"),
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/<directory-id>/oauth2/token"}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/<path>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
使用例:
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "hogeappid99009",
"fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope="akv",key="hoge01-secret")),
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/hogetenantid0000/oauth2/token"}
dbutils.fs.mount(
source = "abfss://data@hogeStorageAccount.dfs.core.windows.net/",
mount_point = "/mnt/adls/data",
extra_configs = configs)
df = spark.read.format("delta").load("dbfs:/mnt/adls/data/external-location/path/to/data/")
SASトークン
ABFS URI アクセス
構文:
spark.conf.set("fs.azure.account.auth.type.<storage-account>.dfs.core.windows.net", "SAS")
spark.conf.set("fs.azure.sas.token.provider.type.<storage-account>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.sas.FixedSASTokenProvider")
spark.conf.set("fs.azure.sas.fixed.token.<storage-account>.dfs.core.windows.net", "<token>")
使用例:
sas_token = dbutils.secrets.get(scope="akv",key="hoge01-sas")
spark.conf.set("fs.azure.account.auth.type.hogeStorageAccount.dfs.core.windows.net", "SAS")
spark.conf.set("fs.azure.sas.token.provider.type.hogeStorageAccount.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.sas.FixedSASTokenProvider")
spark.conf.set("fs.azure.sas.fixed.token.hogeStorageAccount.dfs.core.windows.net", sas_token)
df = spark.read.format("delta").load("abfss://data@hogeStorageAccount.dfs.core.windows.net/external-location/path/to/data/")
マウントによるアクセス
構文:
configs = {"fs.azure.sas.<container>.<storage-account>.blob.core.windows.net": <token>}
dbutils.fs.mount(
source = "wasbs://<container>@<storage-account>.blob.core.windows.net/<path>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
使用例:
sas_token = dbutils.secrets.get(scope="akv",key="hoge01-sas")
configs = {"fs.azure.sas.data.hogeStorageAccount.blob.core.windows.net": sas_token}
dbutils.fs.mount(
source = "abfss://data@hogeStorageAccount.dfs.core.windows.net/",
mount_point = "/mnt/adls/data",
extra_configs = configs)
df = spark.read.format("delta").load("dbfs:/mnt/adls/data/external-location/path/to/data/")
アカウント キー
ABFS URI アクセス
構文:
spark.conf.set("fs.azure.account.key.<storage-account>.dfs.core.windows.net","<storage-account-access-key>")
使用例:
key = dbutils.secrets.get(scope="akv",key="hoge01-key")
spark.conf.set("fs.azure.account.key.<storage-account>.dfs.core.windows.net",key)
df = spark.read.format("delta").load("abfss://data@hogeStorageAccount.dfs.core.windows.net/external-location/path/to/data/")
マウントによるアクセス
構文:
configs = {"fs.azure.account.key.hogeStorageAccount.blob.core.windows.net": "<storage-account-access-key>"}
dbutils.fs.mount(
source = "wasbs://<container>@<storage-account>.blob.core.windows.net/<path>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
使用例:
key = dbutils.secrets.get(scope="akv",key="hoge01-key")
configs = {"fs.azure.account.key.hogeStorageAccount.blob.core.windows.net": key}
dbutils.fs.mount(
source = "wasbs://data@hogeStorageAccount.blob.core.windows.net/",
mount_point = "/mnt/adls/data",
extra_configs = configs)
df = spark.read.format("delta").load("dbfs:/mnt/adls/data/external-location/path/to/data/")
Azure AD 資格情報パススルー
ABFS URI アクセス
Spark conf 設定などの構文はない
使用例:
df = spark.read.format("delta").load("abfss://data@hogeStorageAccount.dfs.core.windows.net/external-location/path/to/data/")
マウントによるアクセス
構文:
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
使用例:
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
dbutils.fs.mount(
source = "wasbs://data@hogeStorageAccount.dfs.core.windows.net/",
mount_point = "/mnt/adls/data",
extra_configs = configs)
df = spark.read.format("delta").load("dbfs:/mnt/adls/data/external-location/path/to/data/")
ネットワーク構成について
対象のStorage Account がファイアウォールの背後にある場合、Azure Databricks のクラスターからのネットワークアクセスを構成する必要がある
Vnet インジェクション
通常、Azure Databricks は自動生成されるマネージドリソースグループ内のVnet でクラスタを動作させるが、Vnetインジェクションを用いることで、クラスターが動作するVnetを変更管理することが可能となる
参考:仮想ネットワークの管理
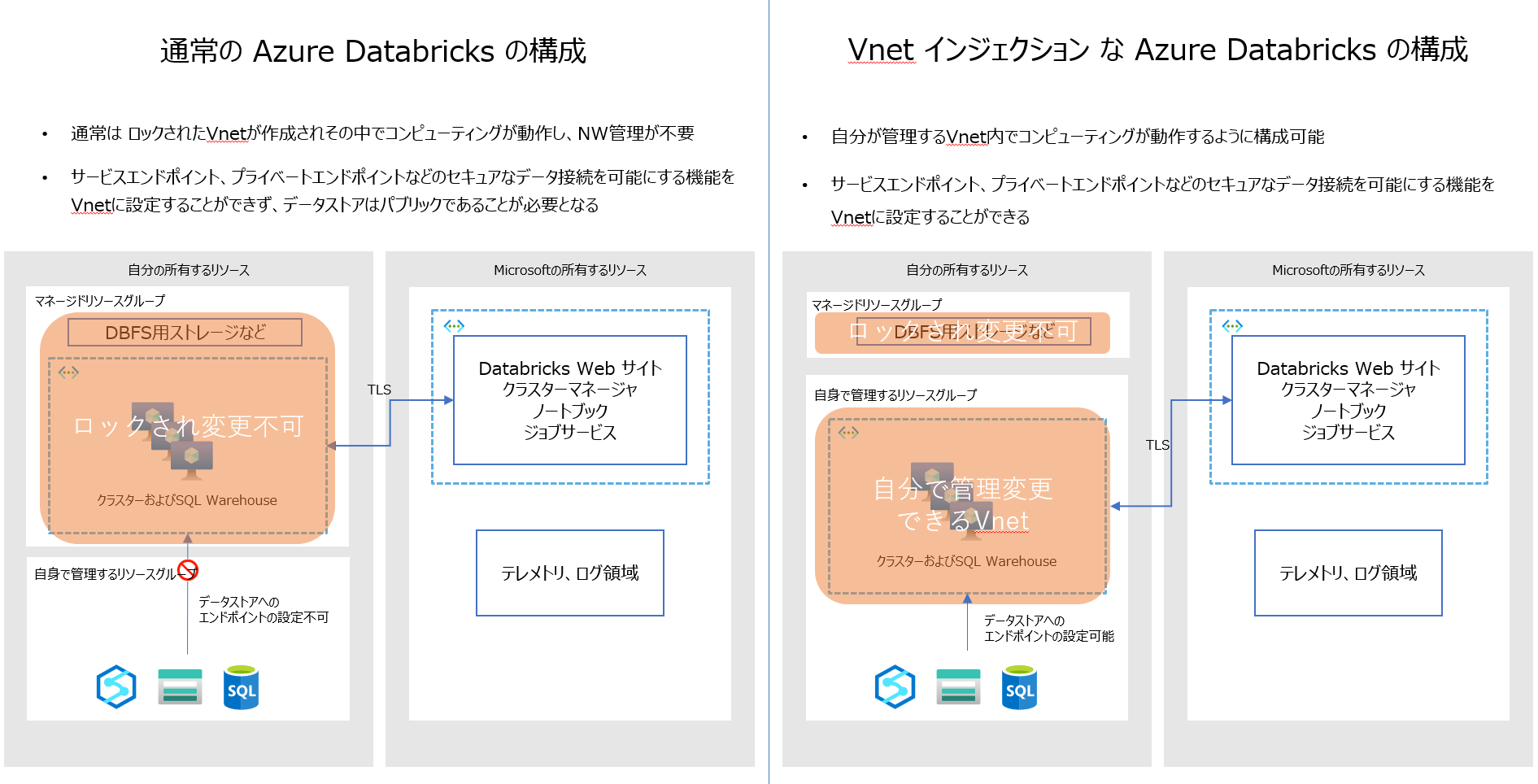
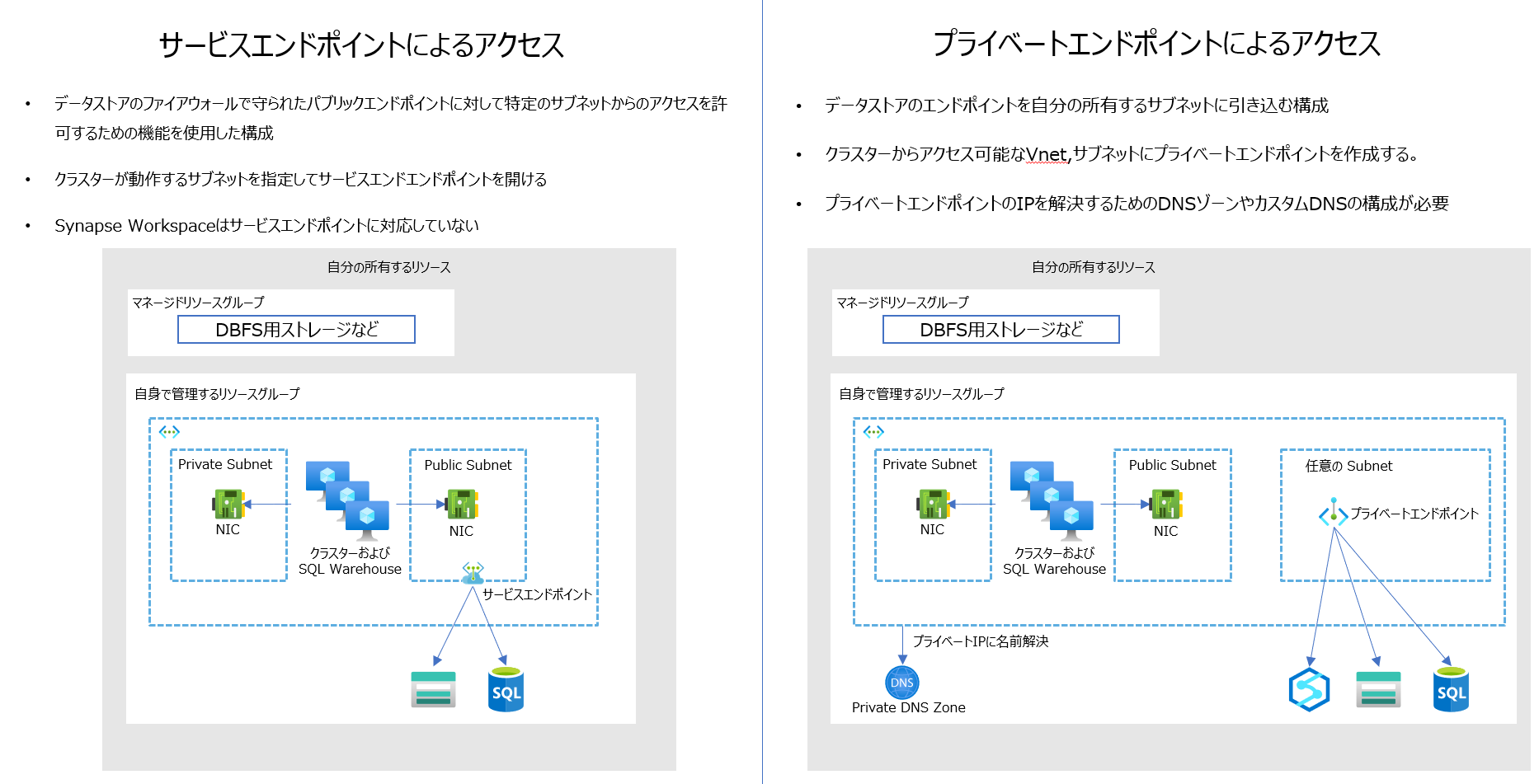
データストアにアクセスするための構成
Vnet インジェクションで Azure Databricks をデプロイした後は、データストアにアクセスさせる方式により、サービスエンドポイントか、プライベートエンドポイントを構成することでファイアウォールの背後のデータにアクセスすることが可能
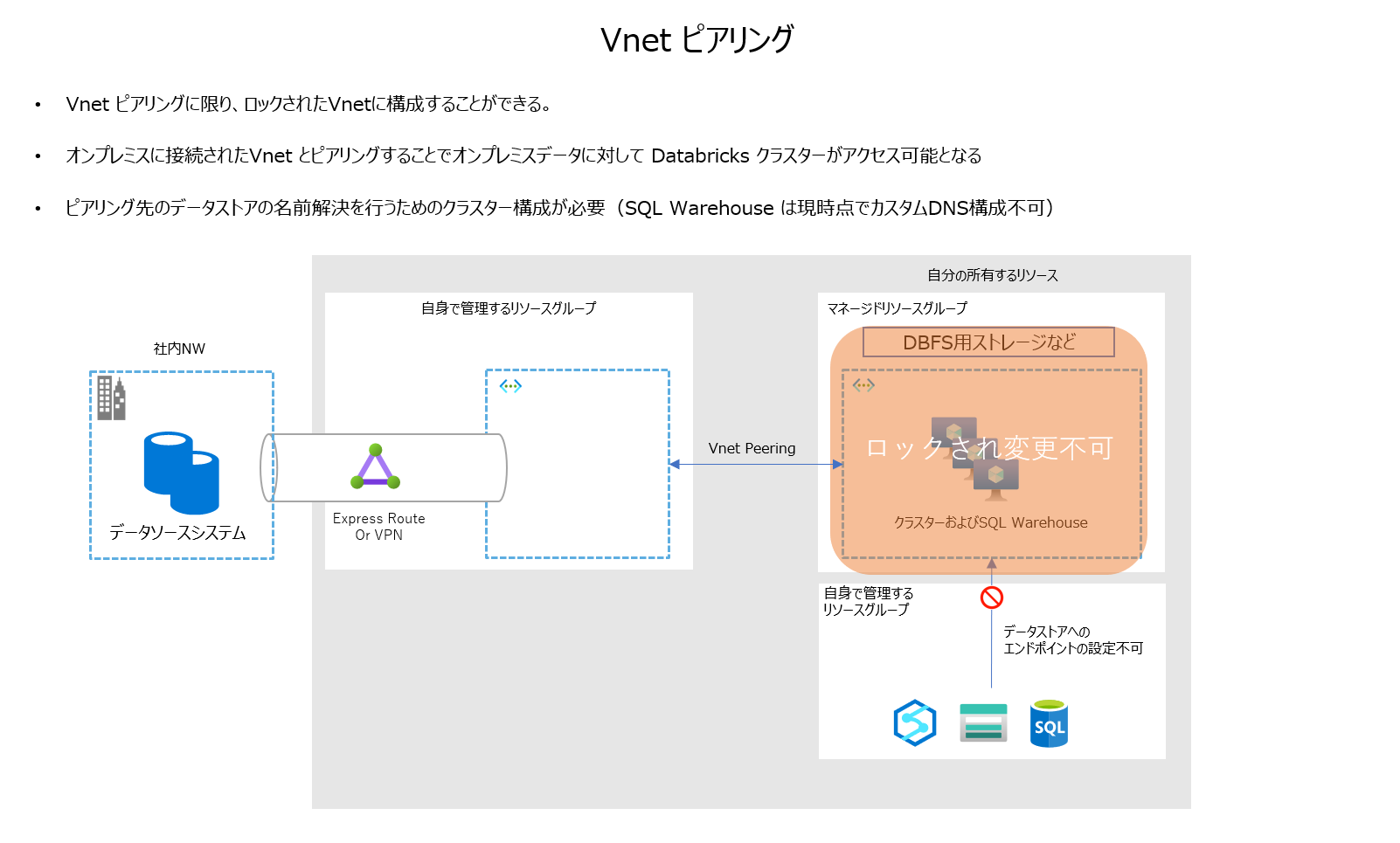
Vnet ピアリング
通常はロックされているVnetだが、ピアリング設定のみ可能。VNet インジェクションを構成していない場合にはこちらが利用可能
ただし、基本的に閉域網へのアクセスはVnet インジェクションの構成が推奨される。
また、ピアリング先のNW内の資産へのアクセスにはDNS構成を設定する必要がある
なお、Vnet の管理をしたくないが、ファイアウォールの背後のデータストアにアクセスしたい場合には、この構成でピアリングされたNWに、Azure Private DNS Resolver と対象のデータストアプライベートエンドポイントを配置し、以下のようなinit スクリプトでクラスタを起動することでアクセスができることを確認済み。
#!/bin/bash
mv /etc/resolv.conf /etc/resolv.conf.orig
echo nameserver <Private DNS Resolver の受信エンドポイントIP>| sudo tee --append /etc/resolv.conf
実際にやってみた記事はこちら:https://qiita.com/ryoma-nagata/items/1dbf250125bc9b767392
サーバーレス SQL ウェアハウスからのアクセスの許可
サーバーレス SQL ウェアハウスは Microsoft サブスクリプション内のマルチテナントなクラスターからのアクセスとなるので、このクラスターの存在するサブネットからのアクセス許可を設定することで、疎通させる。
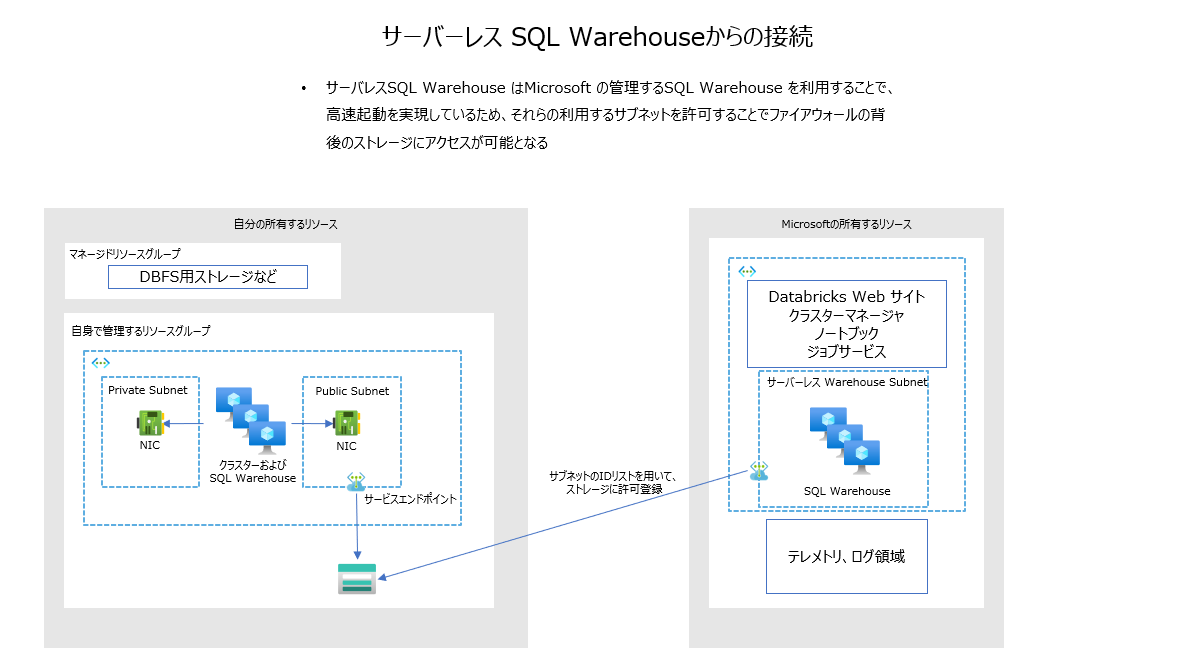
実際にやってみた記事はこちら:https://qiita.com/ryoma-nagata/items/5cc56db7aa355ffe5ff5
その他参考リンク集
クラスター UI の変更とクラスター アクセス モード
Azure Data Lake Storage Gen2 と Blob Storage にアクセスする
Unity Catalog のベスト プラクティス
クラスター構成オプションの管理
クラスター ノード初期化スクリプト
Data Exfiltration Protection with Azure Databricks