はじめに
Snowflake Iceberg テーブルの作成を OneLake に対して行い、更に OneLake が Iceberg テーブルを自動的に読み替えてくれる機能がプレビュー開始しましたので、これを紹介します。
Snowflake のデータを Power BI で使いたい!
という声をよくお聞きします。実際に使われている方も多い構成です。
これを実現するための主な構成案として以下のパターンがありますが、 Fabric が登場したことで少し幅ができました。
- Power BI のみで構成
- Power BI のソースにする(Import / Direct Query)
- Snowflake の IP 制限がない状態場合では簡単だが、Public IP ホワイトリストなどを使用している場合には、以下のいずれかの構成が必要
- Power BI のリージョンで使用される Azure 全体の IP 許可
- オンプレミスデータゲートウェイ を使用する
- Snowflake の IP 制限がない状態場合では簡単だが、Public IP ホワイトリストなどを使用している場合には、以下のいずれかの構成が必要
- Power BI のソースにする(Import / Direct Query)
- Fabric (OneLake)を活用した構成
- Data Factory などの ETL ツールを使用して OneLake にデータを連携したうえで、Power BI のソースにする(Import / Direct Query / Direct Lake)
- オンプレミスデータゲートウェイを介したプライベートアクセスはできますが、ETL(ELT)が必要で、ニアリアルタイムに Snowflake データを Power BI に反映することはできません。
-
Fabric Mirroring を使用して OneLake に Snowflake 上のデータをニアリアルタイム同期する
- ニアリアルタイムかつ V-Order という Fabric の独自エンコーディング技術により、クエリ性能を向上させた状態で OneLake に書き込まれるという点で有力な構成ですが、同期中はStreamが実行されるため仮想 WH が起動することにより Snowflake 側のコスト増に注意が必要です。
- また、現時点で Snowflake 側で IP 制限などのネットワークセキュリティを十分にかけることはできません。(Azure 全体の IP 許可は可能)
- Data Factory などの ETL ツールを使用して OneLake にデータを連携したうえで、Power BI のソースにする(Import / Direct Query / Direct Lake)
Snowflake の Iceberg テーブルを通じた 相互運用性の向上
Snowflake の Iceberg テーブルの OneLake ショートカットの発表で、より協力な選択肢が生まれました。
- Snowflake、Microsoftとのパートナーシップを拡大し、Apache Icebergを通じて相互運用性を向上
- Snowflakeとショートカットを使用してOneLakeにIcebergデータを保存し、アクセスします
これにより、Snowflake のデータを 同期処理やデータ移動のために仮想ウェアハウスを立ち上げる必要なく、ニアリアルタイムに 、IPホワイトリスト設定を緩めることなく、Power BI を含む Fabric の分析機能で利用することができるようになります。
Iceberg とは?
Apache Iceberg は、 Databricks が開発し、 OneLake が標準として採用している Delta Lakeにならぶ、レイクハウスフォーマットの一つです。(もう一つ代表的なものは Uber の Apache Hudi)
レイクハウスフォーマットは、データレイク上でテーブルとしての構造化および ACID 特性を実現することで、データウェアハウスサービスのレイヤではなく、ストレージレイヤーに分析ストアを構築します。
これにより、ベンダーロックインのリスクを減らし、異なるプラットフォーム間でデータ活用をシームレスに行うことができるようになります。
参考:
- https://www.slideshare.net/slideshow/a-thorough-comparison-of-delta-lake-iceberg-and-hudi/236682124
- https://www.slideshare.net/slideshow/bigdata-storage-layer-software-nttdata/183323642
ウォークスルー
構成イメージ

1. レイクハウスの作成
まずはレイクハウスを作成し、Snowflake の外部ボリュームが参照するパスを取得します。
-
レイクハウスを作成する を参考に、レイクハウスを作成したら、Iceberg テーブルを作成するディレクトリを作成します。

- プロパティから このディレクトリを示す、OneLake の URL を取得します。

- 画面右上のユーザーアイコンからテナントIDも取得しておきます。

2. 外部ボリュームの作成
Snowflake 側で 外部ボリュームを作成します。
参考:https://docs.snowflake.com/en/user-guide/tables-iceberg-configure-external-volume-azure#step-1-create-an-external-volume-in-snowflake
-
先ほど取得した OneLake の URL を https -> azure に修正します。
例https://onelake.dfs.fabric.microsoft.com/iceberg_demo/sf_demo.Lakehouse/Files/snowflake_volume ↓ azure://onelake.dfs.fabric.microsoft.com/iceberg_demo/sf_demo.Lakehouse/Files/snowflake_volume -
CREATE EXTERNAL COMMAND を実行します。VOLUME名は後で使います。
sqlCREATE EXTERNAL VOLUME onelake_sf_demo_ext_volume STORAGE_LOCATIONS = ( ( NAME = 'onelake_sf_demo_location' STORAGE_PROVIDER = 'AZURE' STORAGE_BASE_URL = 'azure://onelake.dfs.fabric.microsoft.com/iceberg_demo/sf_demo.Lakehouse/Files/snowflake_volume' AZURE_TENANT_ID = '<テナントID>' ) ); -
DESC コマンドで、Snowflake クライアントアプリケーションを使用するための URL と アプリケーションの名前が確認できます。
sqlDESC EXTERNAL VOLUME onelake_sf_demo_ext_volume;
-
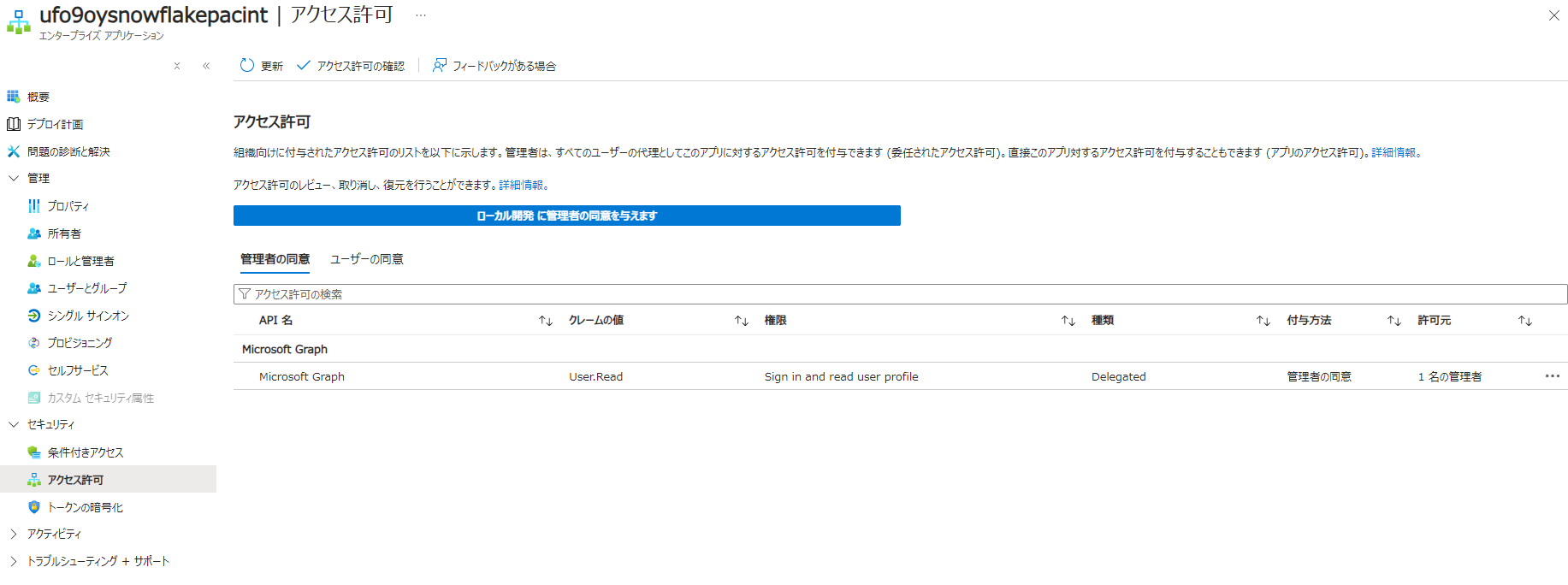
URL にアクセスして、Microsoft Graph API のアクセス許可を与えます。(テナントに対する特権が必要です)

組織の代理としてのチェックは任意です。後日チェックはつけなくても動作することが確認できました。
-
許可をすると自動実行可能なアクセス許可をもったアプリケーションが Entra ID に登録されます。
3. Snowflake クライアントアプリケーションに対してレイクハウスへの書込み権限を付与
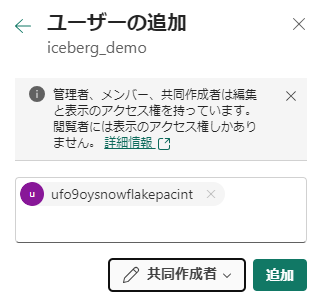
作成されたアプリケーションに権限付与を行います。
-
ワークスペースへのアクセスを許可する を参考に、共同作成者以上のロールを付与します。表示されない場合は、後述の制限事項を参考に、テナント設定などを確認してください。外部アクセスを許可するテナントスイッチ なんかは既定で無効なので、対処が必要です。
-
Volume が機能することを確認します。
sqlSELECT SYSTEM$VERIFY_EXTERNAL_VOLUME('onelake_sf_demo_ext_volume');
エンタープライズアプリケーションへのアクセス許可設定の事前準備として、サービス プリンシパルは Fabric API を使用できますを有効化することが必要です。

4. Iceberg テーブルの作成
Snowflake 側で Iceberg テーブルを作成します。
参考:https://docs.snowflake.com/en/user-guide/tutorials/create-your-first-iceberg-table
-
DDL文を発行します。VARCHARなどは STRING に置き換えます
sqlCREATE OR REPLACE ICEBERG TABLE ICEBIRG_DEMO.PUBLIC.LINEITEM ( L_ORDERKEY NUMBER(38,0), L_PARTKEY NUMBER(38,0), L_SUPPKEY NUMBER(38,0), L_LINENUMBER NUMBER(38,0), L_QUANTITY NUMBER(12,2), L_EXTENDEDPRICE NUMBER(12,2), L_DISCOUNT NUMBER(12,2), L_TAX NUMBER(12,2), L_RETURNFLAG STRING, L_LINESTATUS STRING, L_SHIPDATE DATE, L_COMMITDATE DATE, L_RECEIPTDATE DATE, L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING ) CATALOG = 'SNOWFLAKE' EXTERNAL_VOLUME = 'onelake_sf_demo_ext_volume' BASE_LOCATION = 'icebirg_demo/public/lineitem'; -
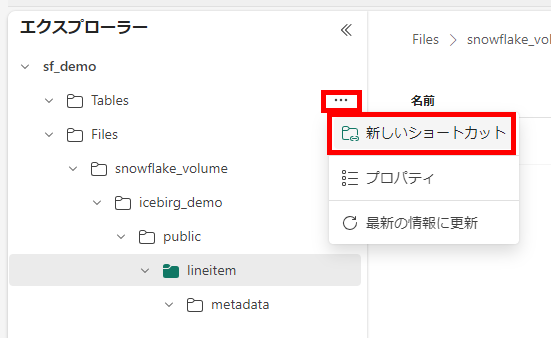
レイクハウスを確認すると、Iceberg 形式でディレクトリが作成されています

-
この Iceberg ディレクトリにテーブルショートカットを作成します。
-
OneLake ショートカットを作成するを参考にして、テーブルを示すフォルダをショートカット先にします。
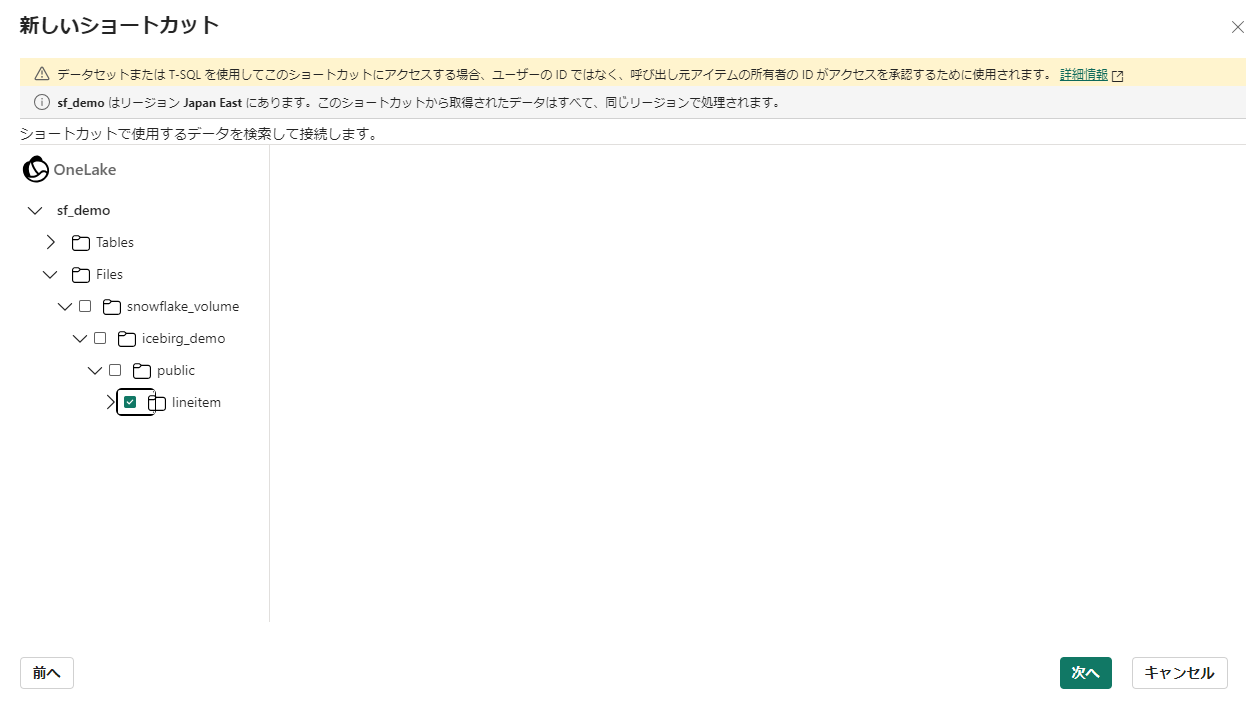
-
データがない状態ではエラー表示されていますが、列情報を parquet から取得しているように感じますので、放置してファイルの内容を見ると delta log が生成されていることがわかります。
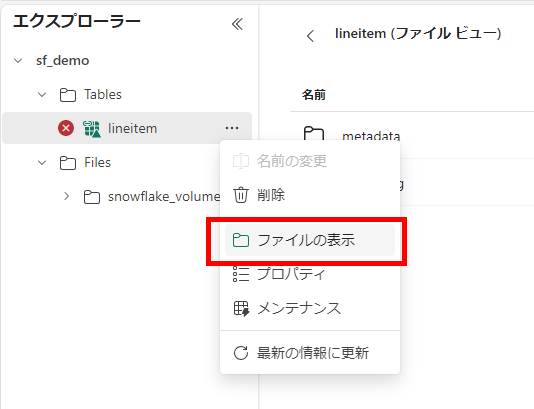
iceberg_conversion_log.txt が生成されてました。がこれはエラー。Azure Function が動いているっぽいのが興味深い

-
データを入れてやると正常に動作します。
sqlINSERT INTO ICEBIRG_DEMO.PUBLIC.LINEITEM SELECT * FROM snowflake_sample_data.tpch_sf1.lineitem LIMIT 1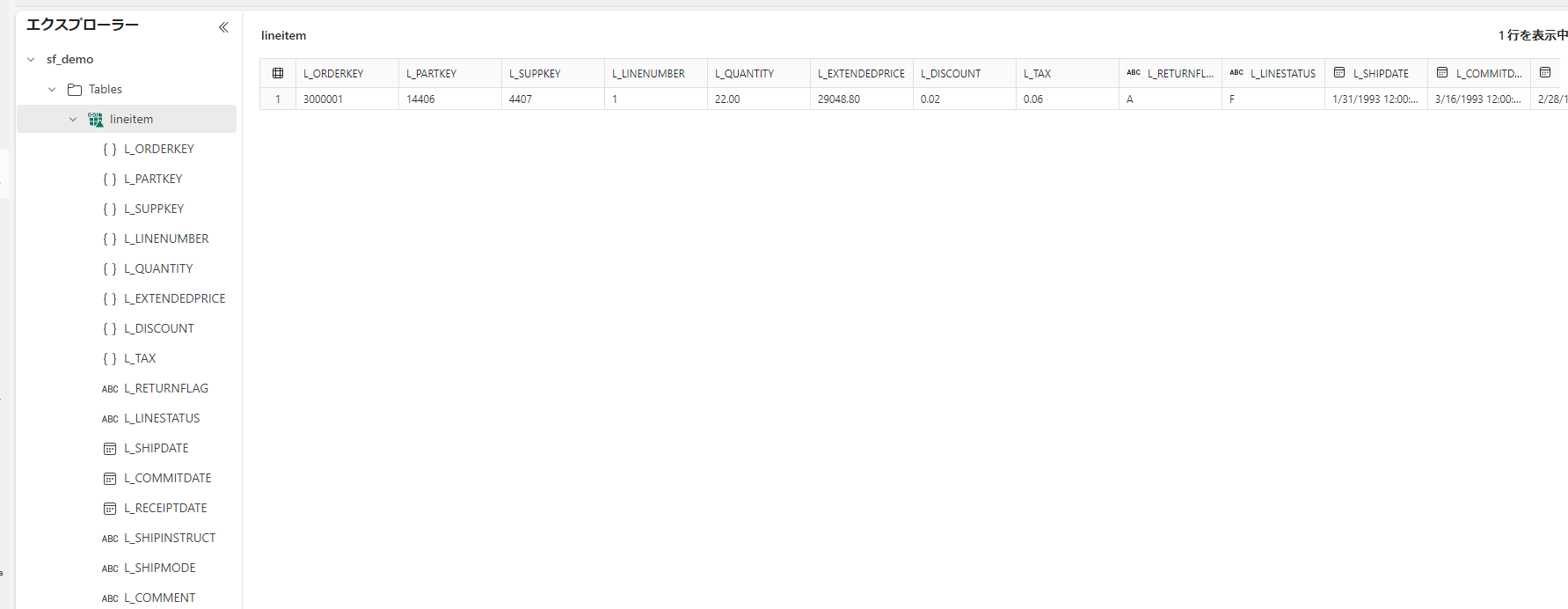
データフォルダも確認できます。

conversion ログも成功となっています。

5. Power BI でのリアルタイム性の確認
まずは Power BI レポートで確認してみます。 Direct Lake を利用可能なので、即座にデータ反映されるかも試していきます。
-
SQL分析エンドポイントに切り替えて、レポートを作成します。

-
細かい手順は割愛して、レポートができました。
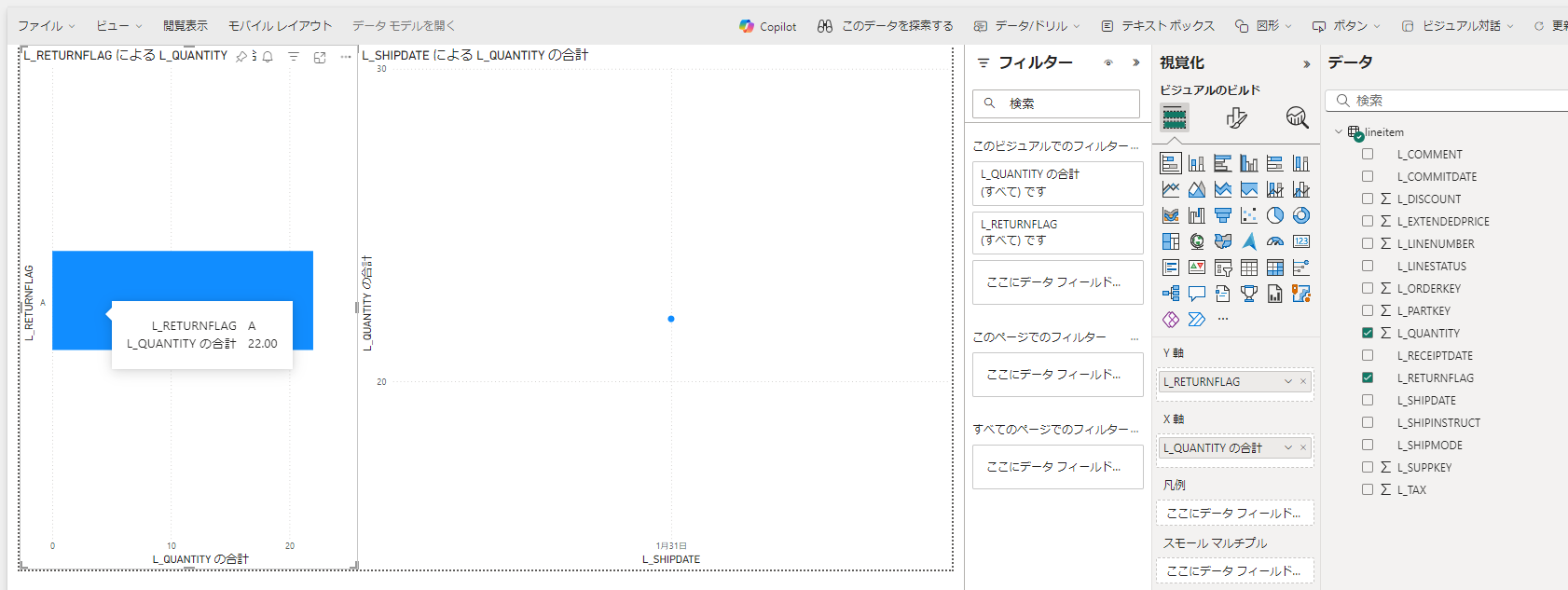
-
データの反映時間の確認もやってみます。※ 時間短縮のため Snowflake 側は最高スペックで動かしました。
6億行のデータが1分未満で Power BI に反映されました!
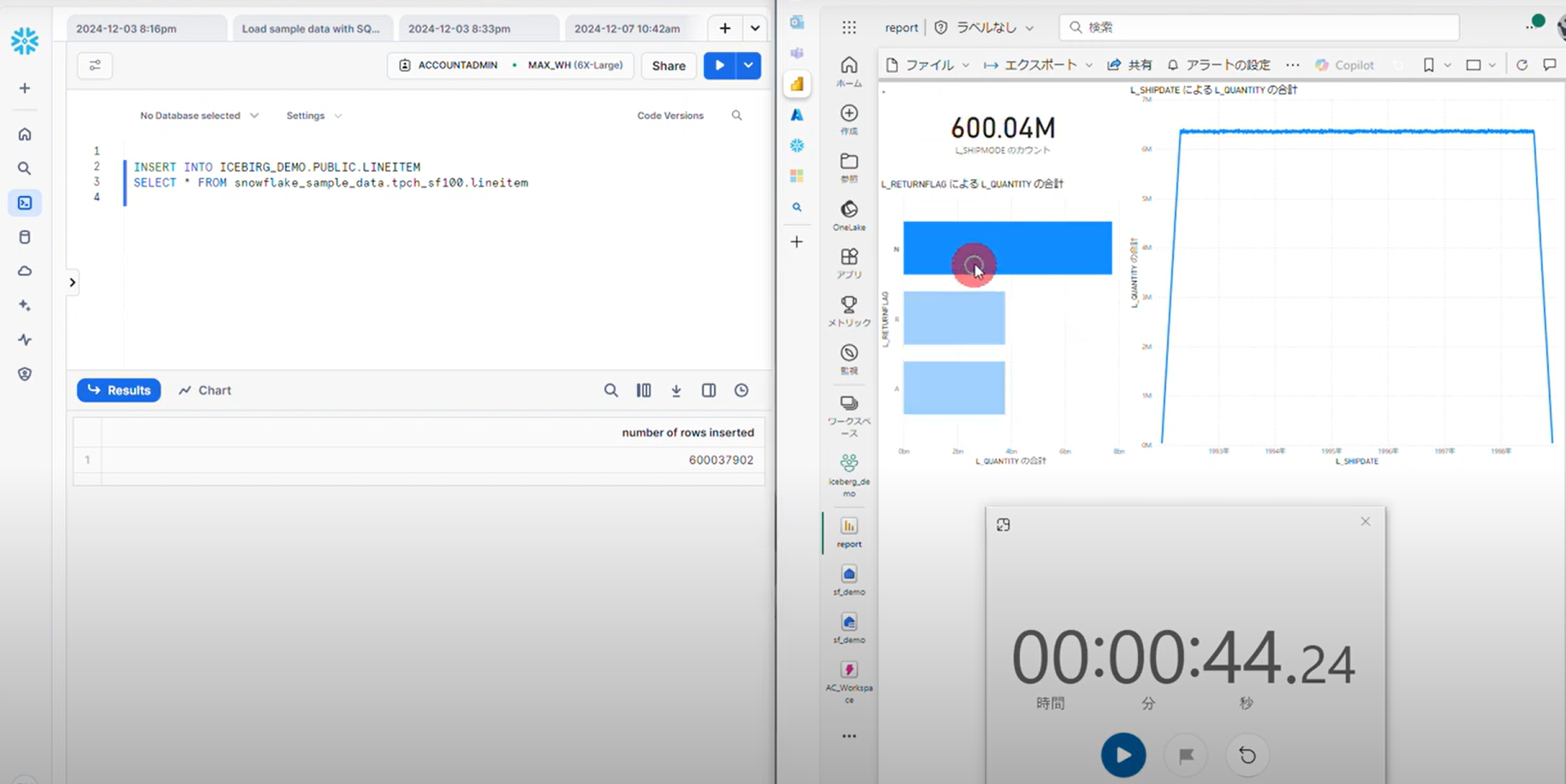
https://www.youtube.com/watch?v=_JMeDyYqTIESnowflake が書き込んだ Iceberg データを参照しているだけなので、V-Order は適用されていませんが、問題なく動きます

同期速度の秘訣は、Iceberg テーブル自体のデータの変換は発生していないことです。
あくまで Iceberg で管理されている Parquet ファイルを Delta Lake として読み替えるためのメタデータ(Delta Log ファイル)を生成することでフォーマットの読み替えを実現しています。
テーブル内のデータを格納している Parquet とは異なり、メタデータは大きなデータではないので高速に処理が可能となっています。
6. その他の分析エンジンでのデータ利用
T-SQL
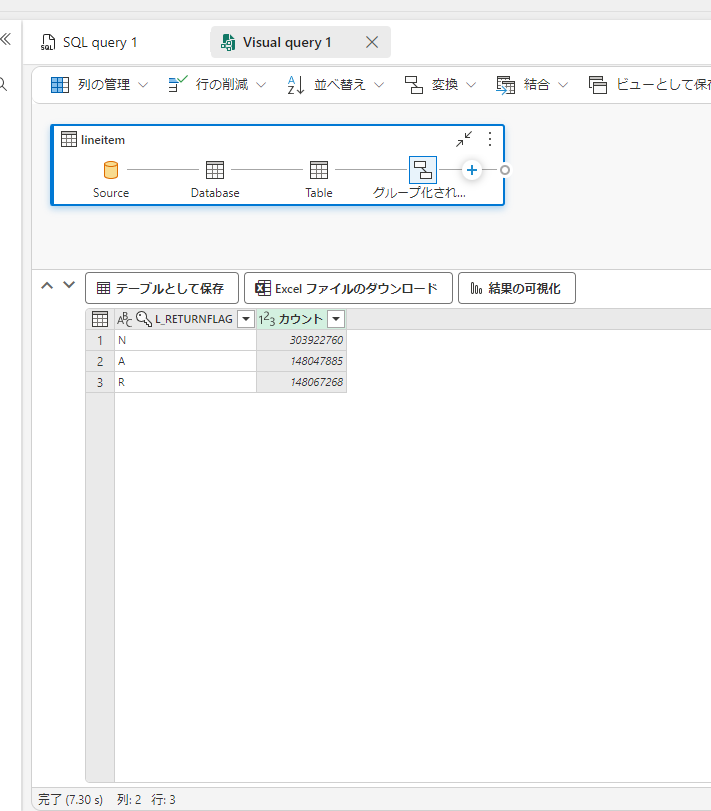
ショートカットされたテーブルはそのまま Fabric 上の T-SQLエンジンで分析が可能です。

ビジュアルクエリを使えば ローコードで SQL 作成も可能です。
Spark
ノートブックを使用して Pyspark による分析も可能です。現時点ではデータ型精度の問題が発生する場合があり、オプションをセットする必要があります。

制限事項
まだ多くの制限事項がある点に注意ください。