Azure Machine Learning Many Models Solution Acceleratorの紹介と利用方法
はじめに
Azure Machine Learning(以下、Azure ML)でMicrosoftが公開しているソリューション、
「Many Models Solution Accelerato」とその利用方法を紹介します。
(2020/12月の情報です)
多数のMLモデルが必要なケース
全体の予測ではなく、個別の予測が必要な場合に多数のモデルが必要となるケースがあります。
たとえば、店舗ごとの売上予測モデルを作成する場合、店舗自体をパラメータとしてもつような大きな一つのモデルは作成できると思いますが、モデルで利用されるアルゴリズムは単一となってしまい、個別の予測としては最適ではなくなってしまうかと思います。
そんなとき、個別で学習した多数のモデルが必要となります。
効率化と拡大を実現する自動機械学習
昨今では、自動機械学習というモデル開発方式が誕生しています。
ひとつひとつのモデルをMLエンジニアが全力でチューニングするような方式ではなく、ある程度の精度が出ればいいようなケースや、チューニング前のあたりをつけるステップを自動機械学習におまかせすることで、ML開発プロセスをスケールすることが可能です。
[自動機械学習 (AutoML) とは](https://docs.microsoft.com/ja-jp/azure/machine-
learning/concept-automated-ml)
多数のモデルが必要なケースでは特に自動機械学習が有効で、人間の試行錯誤時間をなくすことのメリットが大きく働きます。
しかし、Azure MLでは一定時間内でのAPI実行に上限があるためループなどで大量にAutoMLの実行命令を出すとAPI制限がきてしまいます。
Many Models Solution Acceleratorのご紹介
Many Models Solution AcceleratorではAutoMLの実行をmini batch化することで数十万規模の数のモデルを並列で学習することができます。(もちろんAutoML以外も並列化できます)
Microsoft技術ブログ
Train and Score Hundreds of Thousands of Models in Parallel - Microsoft Tech Community
要旨の引用
With the Azure Machine Learning service, the training and scoring of hundreds of thousands of models with large amounts of data can be completed efficiently leveraging pipelines where certain steps like model training and model scoring run in parallel on large scale out compute clusters. In order to help organizations get a head start on building such pipelines, the Many Models Solution Accelerator has been created. The Many Models Solution Accelerator provides two primary examples, one using custom machine learning and the other using AutoML. Give it a try today!
和訳
Azure Machine Learningサービスでは、大量のデータを持つ何十万ものモデルのトレーニングとスコアリングは、モデルトレーニングとモデルスコアリングのような特定のステップが大規模なアウトコンピュートクラスタ上で並行して実行されるパイプラインを活用して効率的に完了することができます。組織がこのようなパイプラインの構築にいち早く着手できるようにするために、Many Models Solution Acceleratorが作成されました。Many Models Solution Acceleratorは、カスタム機械学習を使用した例とAutoMLを使用した例の2つの主要な例を提供します。今すぐ試してみてください。
ソースコードとサンプルがGitHubで公開されており、ご自分の環境ですぐに利用できる状態です。
GitHub
https://github.com/microsoft/solution-accelerator-many-models
実はMS Docsにもあります。
[https://docs.microsoft.com/ja-jp/azure/machine-learning/concept-train-machine-learning-model#many-models-solution-accelerator]
Many Models Solution Acceleratorのご利用方法
すぐに利用できるということで、その方法とtipsを紹介します。
利用方法
以下のMarkdownが用意されています。Azure ML をデプロイし、一通り動かすまでガイドされています。
それぞれのNotebookも割と親切に解説が載っています(英語です)
利用の補足
notebookの中にパイプラインを発行する以下のような文言がありますが、これを利用すると、Azure MLにPipelineエンドポイントが作成され、REST APIや、Azure Data Factory でのパイプライン実行が可能となります。
:
# published_pipeline = pipeline.publish(name = 'automl_train_many_models',
# description = 'train many models',
# version = '1',
# continue_on_step_failure = False)
Azure Machine Learning パイプラインを Azure Data Factory で実行する
Azure Data Factory の構成例
Azure Data Factory で実際に構成した例は以下の通りです

以下のような流れで作っています
- ML pipe lineの参照するフォルダ(sampleでは 既定のデータストアである、azureml-blobstore- 内の oj_sales_data_train および oj_sales_data_inference)のデータを削除します。
2.対象のデータセットを作成します。
たとえば、3年学習で1年予測なら4年分用意します。※なるべく最小の列数で生成することをお勧めします。
3.学習データと予測データに分割します。フォルダ内のファイルは学習の際に指定したグループごとに分割が必要です。(sample では"group_column_names": ['Store', 'Brand'])
フォルダは二つです。
- 学習データフォルダ:予測期間を含まないデータフォルダ
- 予測データフォルダ:学習期間より先の日付を持ったデータフォルダ。予測対象の列が含まれない状態で配置可能
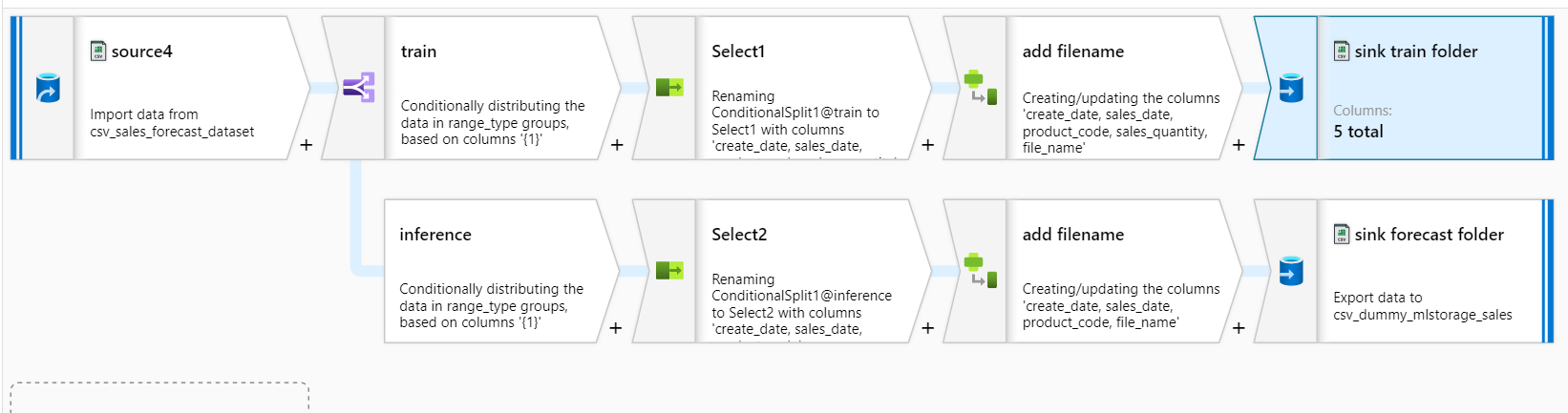
分割はMapping Data Flowで行いました。途中の加工でファイルのフルパスを格納するfilename列をもたせることでsinkの時にファイルを分割できます。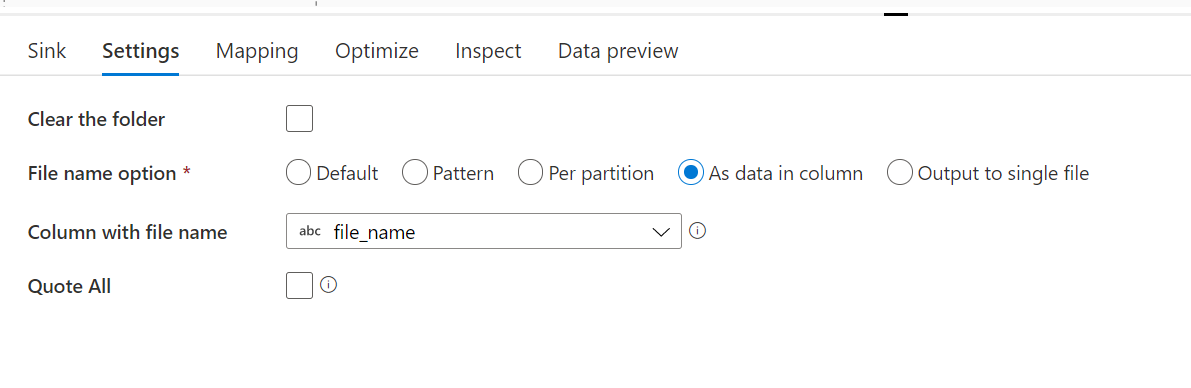
参考までに、Mapping Data Flowの流れも
4.学習と予測のoutputフォルダを削除します。
パイプライン実行時にはデータストアで指定されているコンテナにazuremlフォルダが作成され、その中に出力されます。
- training_output : 各実験のIDとモデルの対象となった製品名などの情報をもったヘッダーなしcsvが出力されます。
- forecasting_output : 予測データに予測結果の列が追加された形のヘッダーなしcsvが出力されます
outputフォルダ名は以下のコードが入力されたセルで指定されます※学習の場合
from azureml.pipeline.core import PipelineData
training_output_name = "training_output"
output_dir = PipelineData(name=training_output_name,
datastore=dstore)
5.Azure ML pipeline(train)を実行します。実験名を発行前の値から変更することも可能です。
6. 5の移動先のフォルダを消します。
7.training_outputフォルダ内のデータを必要に応じて移動します。 参考までにパスの指定例です。
8.Azure ML pipeline(forecast)を実行します。実験名を発行前の値から変更することも可能です。
9. 8の移動先のフォルダを消します。
10. forecasting_outputフォルダ内のデータを必要に応じて移動します、参考までにパスの指定例です。

tips
使ってみてはまった点を紹介します。
予測パイプラインが予測を出力しない
一度目はうまくいくのに連続でADFからキックさせても予測が出力されないことがありました。
allow_reuse=False,を設定しましょう。既定では過去の実行結果を再利用してしまい、予測が出ないようです。
こちらが
parallelrun_step = ParallelRunStep(
name="many-models-forecasting",
parallel_run_config=parallel_run_config,
inputs=[filedst_10_models_input],
#inputs=[filedst_all_models_input],
output=output_dir,
arguments=[
'--group_column_names', 'Store', 'Brand',
'--time_column_name', 'WeekStarting', #[Optional] # this is needed for timeseries
'--target_column_name', 'Quantity', # [Optional] Needs to be passed only if inference data contains target column.
# '--many_models_run_id', training_pipeline_run_id, # [Optional] many model training run id, this will fetch models registered during training run with specified. eg. '5906139c-e428-4502-88d6-efb6adaf8136'
])
こうなります。
parallelrun_step = ParallelRunStep(
name="many-models-forecasting",
parallel_run_config=parallel_run_config,
inputs=[filedst_10_models_input],
#inputs=[filedst_all_models_input],
output=output_dir,
allow_reuse=False, #ここです
arguments=[
'--group_column_names', 'Store', 'Brand',
'--time_column_name', 'WeekStarting', #[Optional] # this is needed for timeseries
'--target_column_name', 'Quantity', # [Optional] Needs to be passed only if inference data contains target column.
# '--many_models_run_id', training_pipeline_run_id, # [Optional] many model training run id, this will fetch models registered during training run with specified. eg. '5906139c-e428-4502-88d6-efb6adaf8136'
])
時系列タスクになっていない
現時点ではこのような措置が必要なようです。※次のSDKリリースで改修予定だとか
automl_settingsのリストに以下を追加しましょう。
"is_timeseries":True