はじめに
Spark 、難しいと思われがちですが、基本的なデータエンジニアリングをするだけであれば SQL で完遂できますので、SQL ユーザーに馴染みやすいお作法を紹介します。
(私の周りも SQLによる ETL 処理を開発して DWH を構築してきたエンジニアが多数派です)
データエンジニアリング例
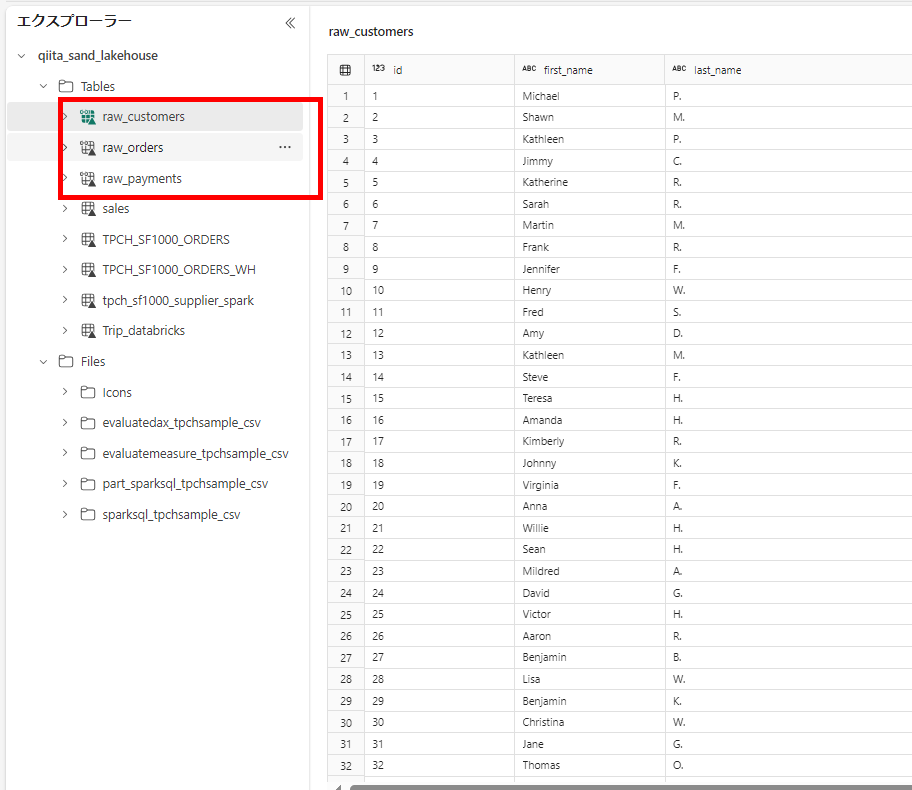
このような3つのテーブルを使ってデータエンジニアリングをする例で紹介します。
導出結果は顧客ごとの注文回数です。
基本のテーブル読み取りと結果の確認
-
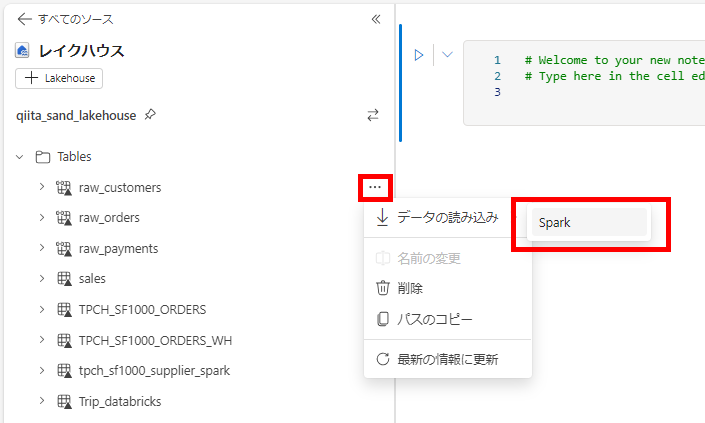
テーブルを読み取ってノートブック上にデータを読みこむには、テーブルのオプションからデータの読み込みを選択します。
-
SELECT 文を実行するため、spark.sql関数が入力されます。SQLの結果が変数dfに格納されます。変数名は任意ですがデータフレームをdfと表現して接頭辞か接尾辞として利用することが多いです。

-
display(df)を実行すると データが表示されます。
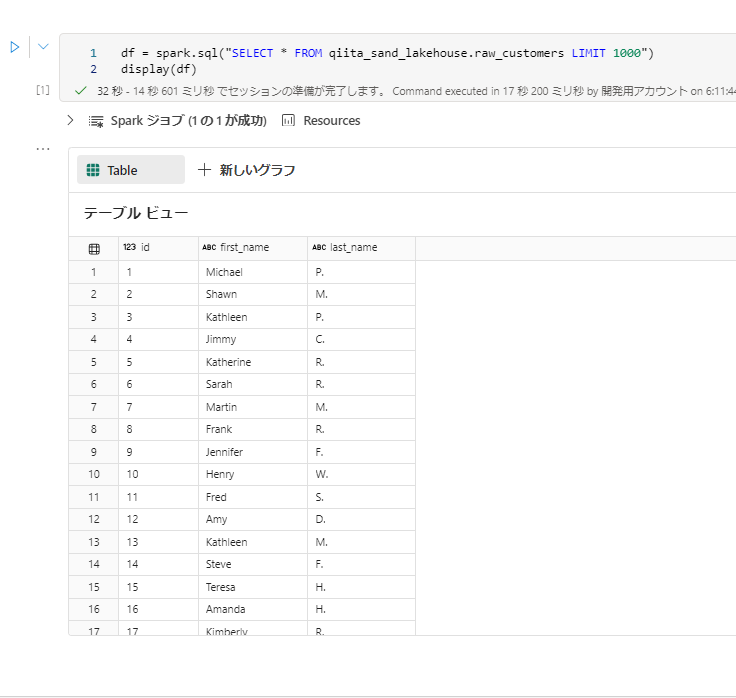
このように spark.sql と display が対話型の SQL 実行で重要な構文となります
WITH句を使用する
SparkSQLは WITH 句(CTE)に対応しているので、これを実行します。
-
SQL を実行したいだけの場合は、%%sql をセルの先頭に付与すると、SQLセルとして扱われます。
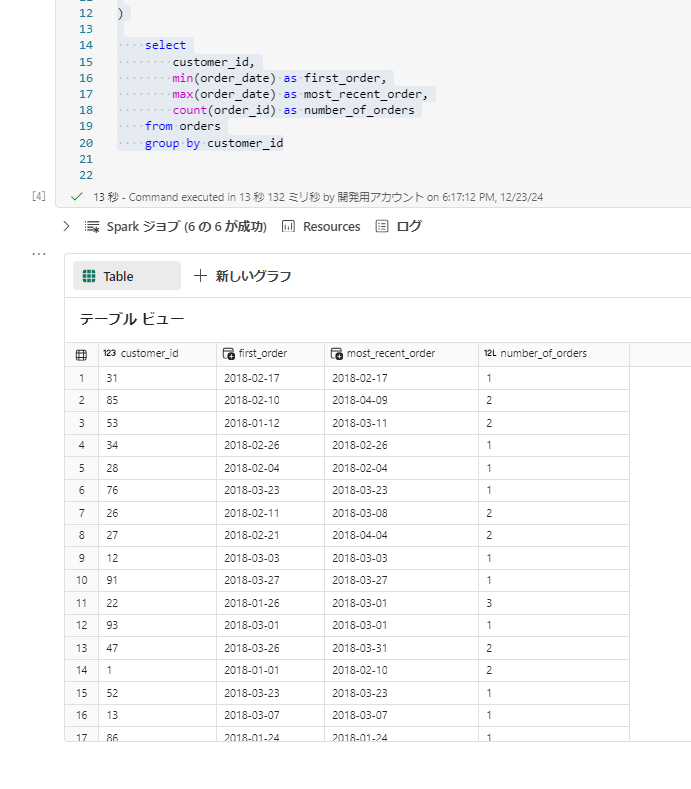
sql%%sql with orders as ( select id as order_id, user_id as customer_id, order_date, status from raw_orders ) select customer_id, min(order_date) as first_order, max(order_date) as most_recent_order, count(order_id) as number_of_orders from orders group by customer_id -
実行すると display の時と同様に結果が表示されます。
SQL での書き込み
テーブルの同時作成(saveAsTable)は CREATE TABLE AS SELECT (CTAS)、
テーブルへの書き込みは INSERT INTO または INSERT OVERWRITE (全件上書き)や、UPDATE, MERGE INTO にて行います。
-
CTASの場合、以下のように記述可能です。
sql%%sql create table customer_orders using delta as with orders as ( select id as order_id, user_id as customer_id, order_date, status from raw_orders ) select customer_id, min(order_date) as first_order, max(order_date) as most_recent_order, count(order_id) as number_of_orders from orders group by customer_id -
テーブルが存在する場合は、DML が利用可能です。
sql%%sql with orders as ( select id as order_id, user_id as customer_id, order_date, status from raw_orders ) insert overwrite customer_orders select customer_id, min(order_date) as first_order, max(order_date) as most_recent_order, count(order_id) as number_of_orders from orders group by customer_id
pyspark の処理とSQLでの処理を織り交ぜる
ノートブックの中では二つの言語を行き来することができます。
-
sqlの処理結果にpython処理を加えたい場合
pysparkdf = spark.sql(""" with orders as ( select id as order_id, user_id as customer_id, order_date, status from raw_orders ) select customer_id, min(order_date) as first_order, max(order_date) as most_recent_order, count(order_id) as number_of_orders from orders group by customer_id """) import pyspark.sql.functions as F df_add_column = df.withColumn("add_column1",F.lit("追加列")) display(df_add_column)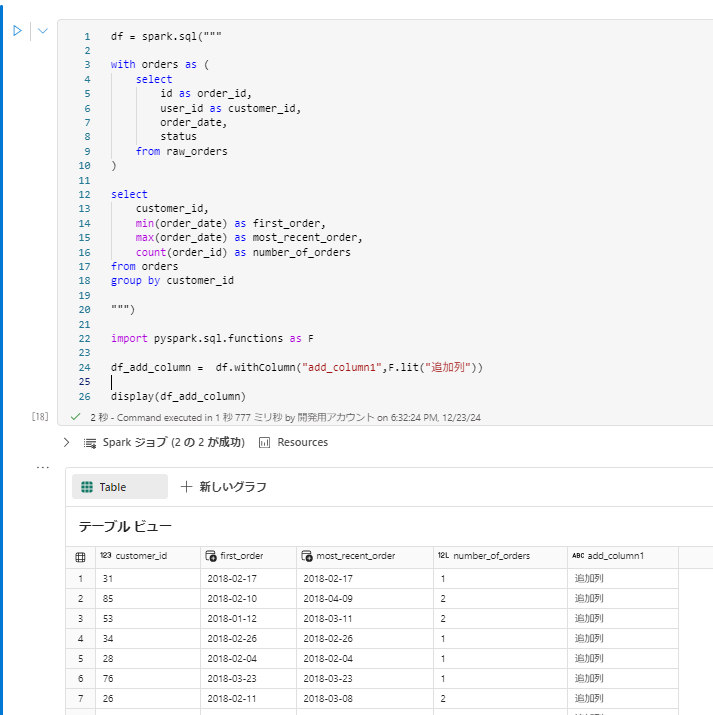
-
pyspark の処理結果をSQLで読みたい場合, createOrReplaceTempView を使用すると簡単です。
pysparkdf_add_column.createOrReplaceTempView("sql_tempview")sql%%sql select * from sql_tempview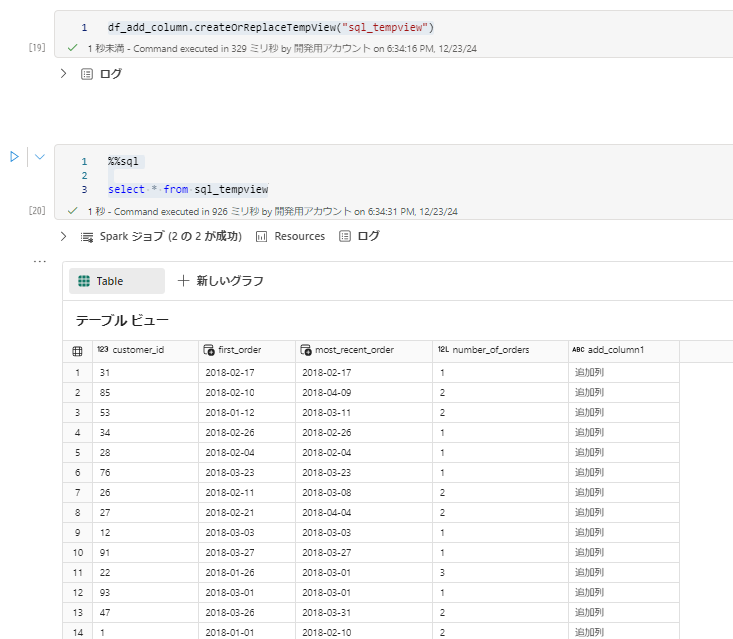
with句の代わりにcreateOrReplaceTempView をチェーンする
createOrReplaceTempViewを CTEのように使うことができます。
ch1 = spark.sql("""
select
id as order_id,
user_id as customer_id,
order_date,
status
from raw_orders
""")
ch1.createOrReplaceTempView("temp_orders")
ch2 = spark.sql("""
select
customer_id,
min(order_date) as first_order,
max(order_date) as most_recent_order,
count(order_id) as number_of_orders
from temp_orders
group by customer_id
""")
ch2.createOrReplaceTempView("v_customer_orders")
ch3 = spark.sql("""
select
orders.customer_id,
sum(amount) as total_amount
from raw_payments as payments
left join temp_orders as orders on
payments.order_id = orders.order_id
group by orders.customer_id
""")
ch3.createOrReplaceTempView("v_customer_payments")
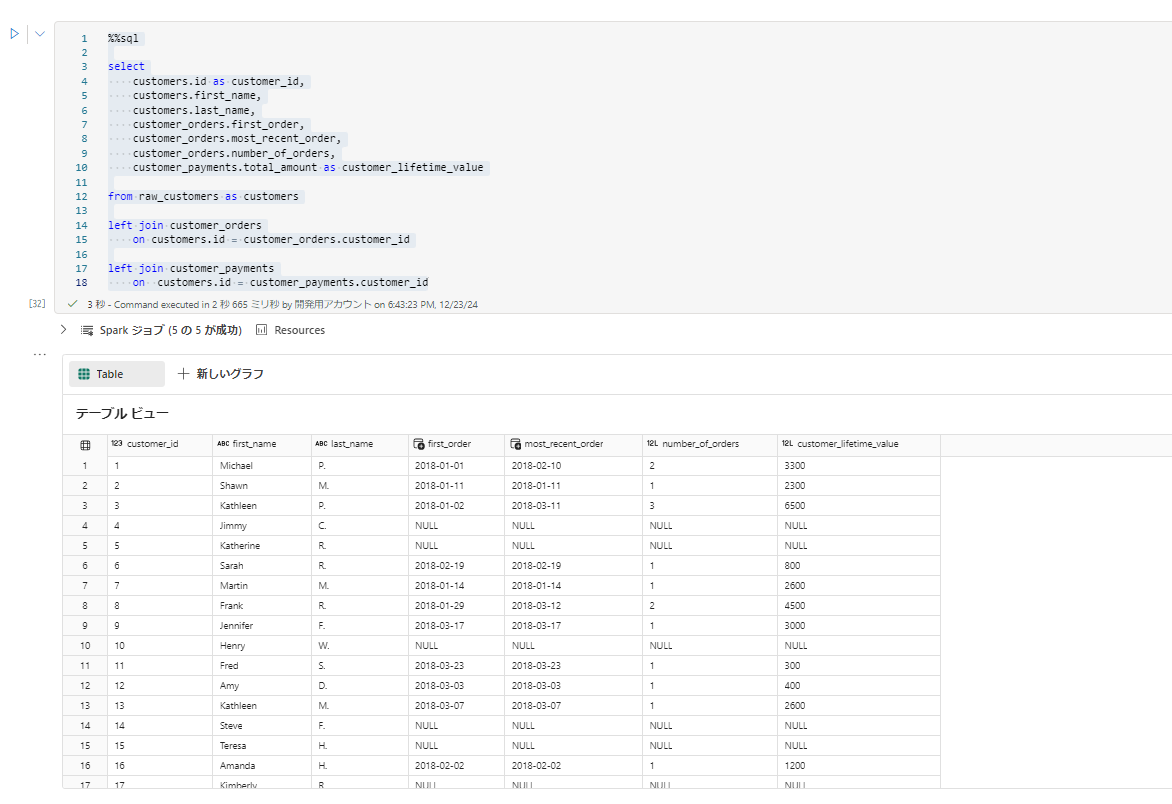
%%sql
select
customers.id as customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order,
customer_orders.most_recent_order,
customer_orders.number_of_orders,
customer_payments.total_amount as customer_lifetime_value
from raw_customers as customers
left join v_customer_orders as customer_orders
on customers.id = customer_orders.customer_id
left join v_customer_payments as customer_payments
on customers.id = customer_payments.customer_id
コードスニペット
pyspark の処理に困ったらコードスニペットの例も確認してみましょう。