Azure Synapse Analytics へ Azure Data Factoryの資産を移行する
-
Azure Synapse Analytics へ Azure Data Factoryの資産を移行する
- はじめに
- 参考
- 移行イメージ
-
移行手順
- 利用資材
- 1. 新規Synapseを準備
- 2. 既存ADF環境のコード準備
- 3. 既存ADF環境Git Repository切断
- 4. 新規Synapse環境Git Repository接続
- 5. 参照先、アクティビティ修正
- [6. Databricks Notebook移行、修正(オプション)](#6-databricks -notebook移行修正オプション)
- [Databricks Notebook移行](#databricks -notebook移行)
- [Databricks Notebook内容修正](#databricks -notebook内容修正)
- 補足
はじめに
GAおめでとうございます!
Git機能もついているということで、既存のAzure Data Factory (以下、ADF)のパイプライン移行手順を検証したいと思います。Databricks部分の移行も試してみます
今後、この移行はソリューションが提供されるかもしれませんが、いち早く移行したい方の参考になればと幸いです。
(2020年12月時点情報です)
参考
もうこれだけ見ればいいんじゃないかという良記事です。かなり参考にしてます。
Azure Synapse Analytics 日本上陸記念! Synapse リソースの移行ステップ 2020年12月バージョン
移行イメージ
こんな計画をたてました。Databricksはオプションです。
※Databricksで使っているNotebookはそのまま使えない場合が多いので、事前検証しましょう
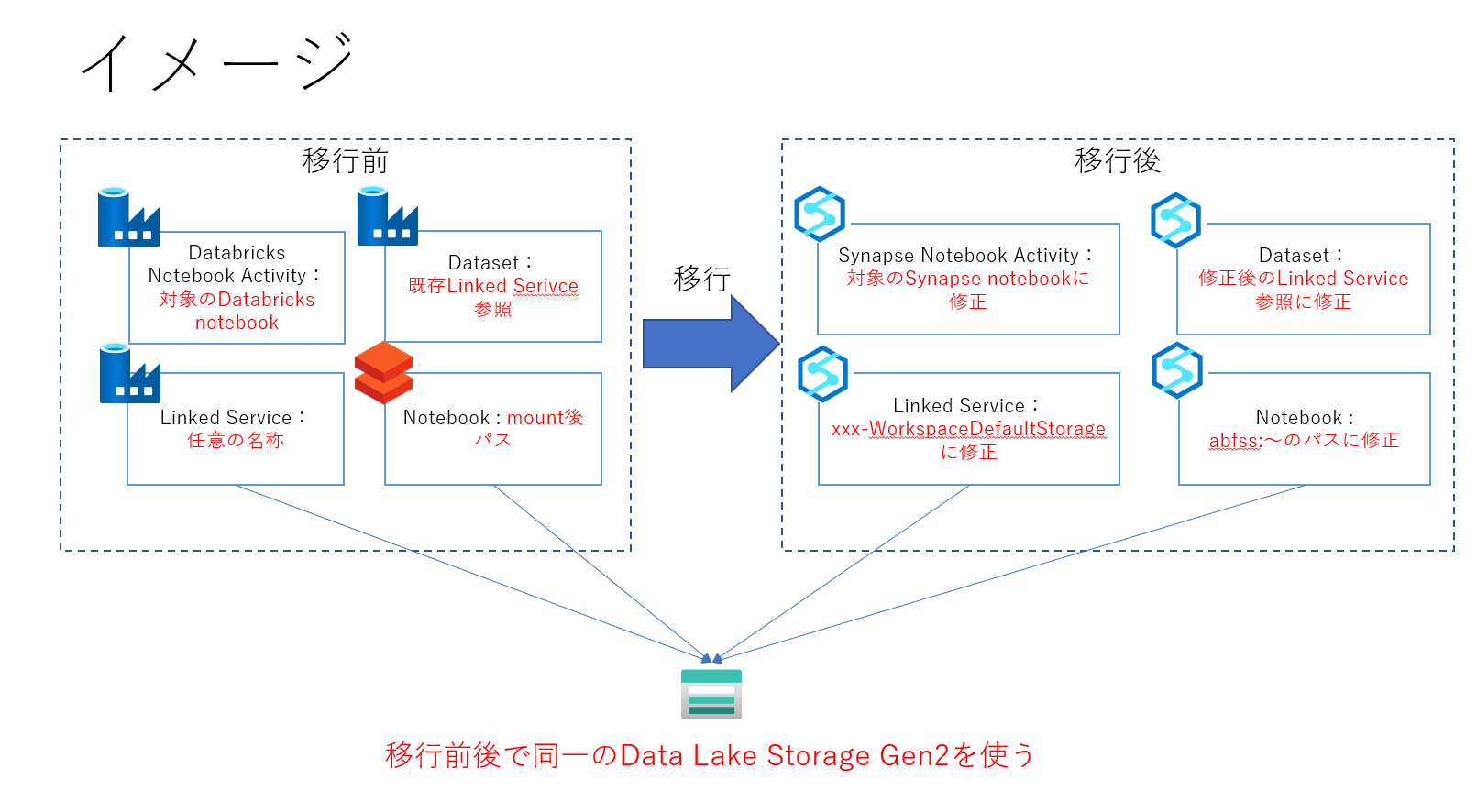
移行手順
DataFactoryはそこそこ楽ですが、Databricksはかなり地道です。
Databricks は新しいワークスペース機能の、プロジェクト単位でのGit連携がきたら楽になるかもですね
- 新規Synapseを準備
- 既存ADF環境のコード準備
- 既存ADF環境Git Repository切断
- 新規Synapse環境Git Repository接続
- 参照先、アクティビティ修正
- Databricks Notebook移行、修正(オプション)
利用資材
AzureCloudScaleAnalyticsHOLで作成されるコード資産、Data FactoryとDatabricks部分を使ってみます。
Githubのほうは閉域構成に対応させた内容にしていますが、この記事ではそのあたり無視して簡略化します。
このようなデータ移動→notebook実行のパイプラインと
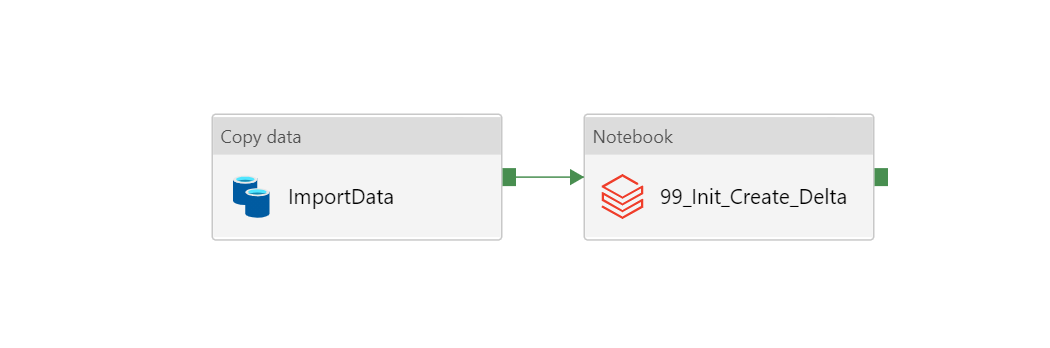
いくつかのノートブックが対象です。
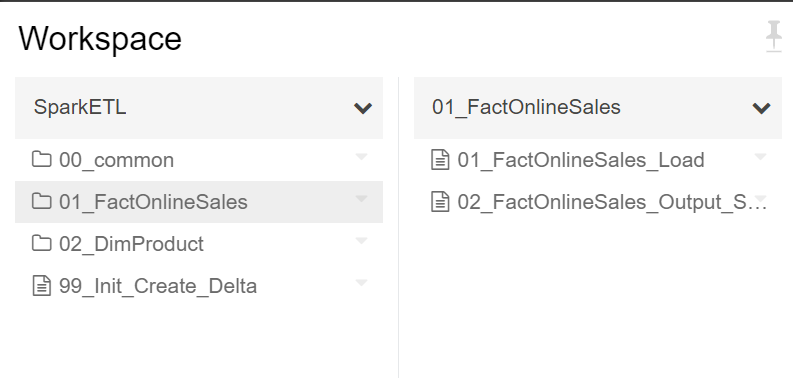
※抜粋
SQLPool,Data Lake Storage gen2 のDataの移行に関しては参考記事をご確認ください。
※その場合でもNW構成はあらためて設定が必要かと思います。
1. 新規Synapseを準備
Synapse ワークスペースの作成を実施します。
作成の際は既存のData lake Storage Gen2を選択して、
[Data Lake Storage Gen2 アカウント 'xxx' のストレージ BLOB データ共同作成者ロールを自分に割り当てます。]
にチェックをつけます。
これで既存のストレージが流用できます。
2. 既存ADF環境のコード準備
もしDataFactoryのGit統合を設定していない場合は、Git リポジトリに接続するを実施してください。
Git環境にこのようなコードが保存されます。
self-hosted integration runtimeも利用している環境なのと、KeyVaultなんかもありますね。
このあたりは補足であつかっていきます。
DatalakeとSynapseへのLinked Serviceが移行対象です。
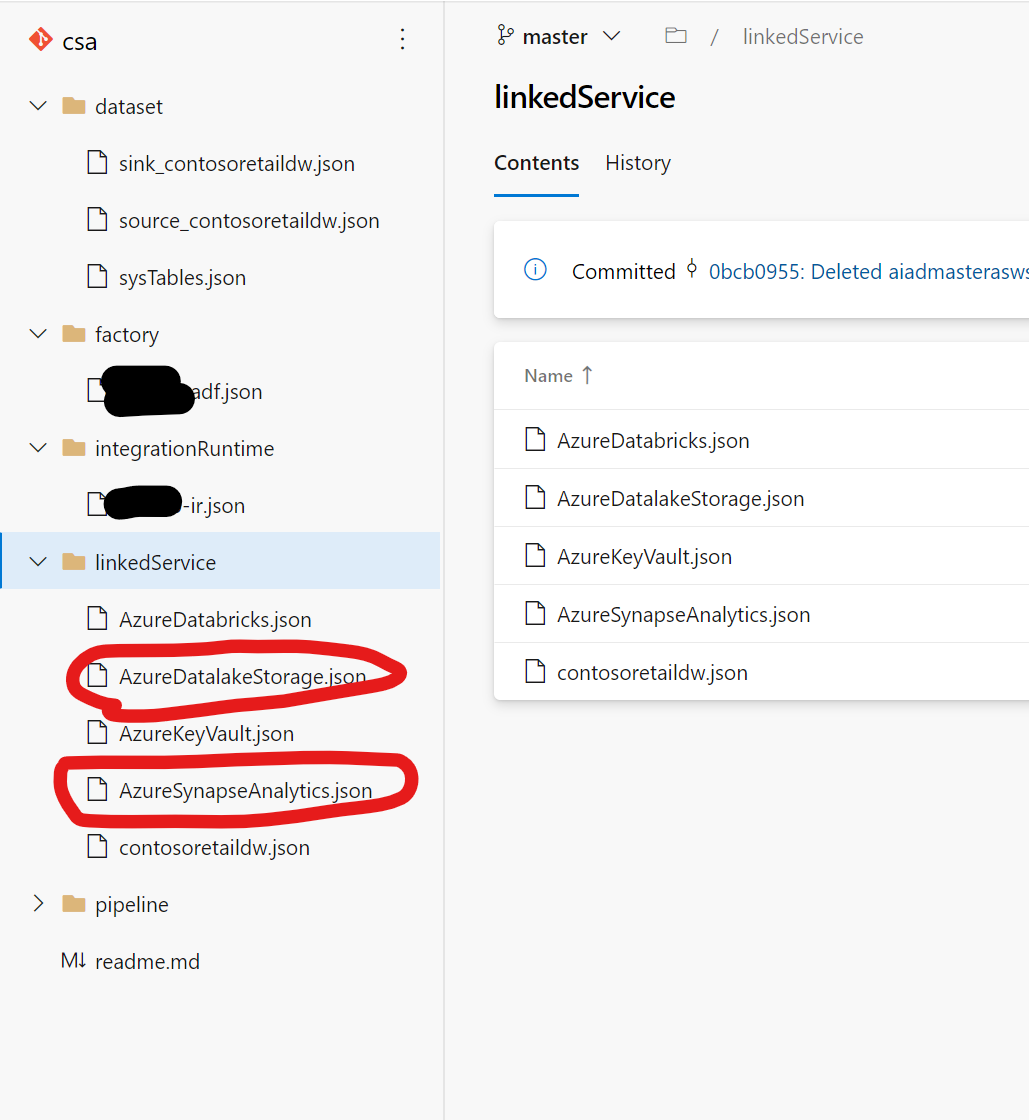
3. 既存ADF環境Git Repository切断
別のGit リポジトリに切り替えるを実施します。
4. 新規Synapse環境Git Repository接続
Synapse Studio で Git リポジトリを構成するを実施します。
全手順で切断したGit Repositoryを利用します。
このような形でコードが追加されます。
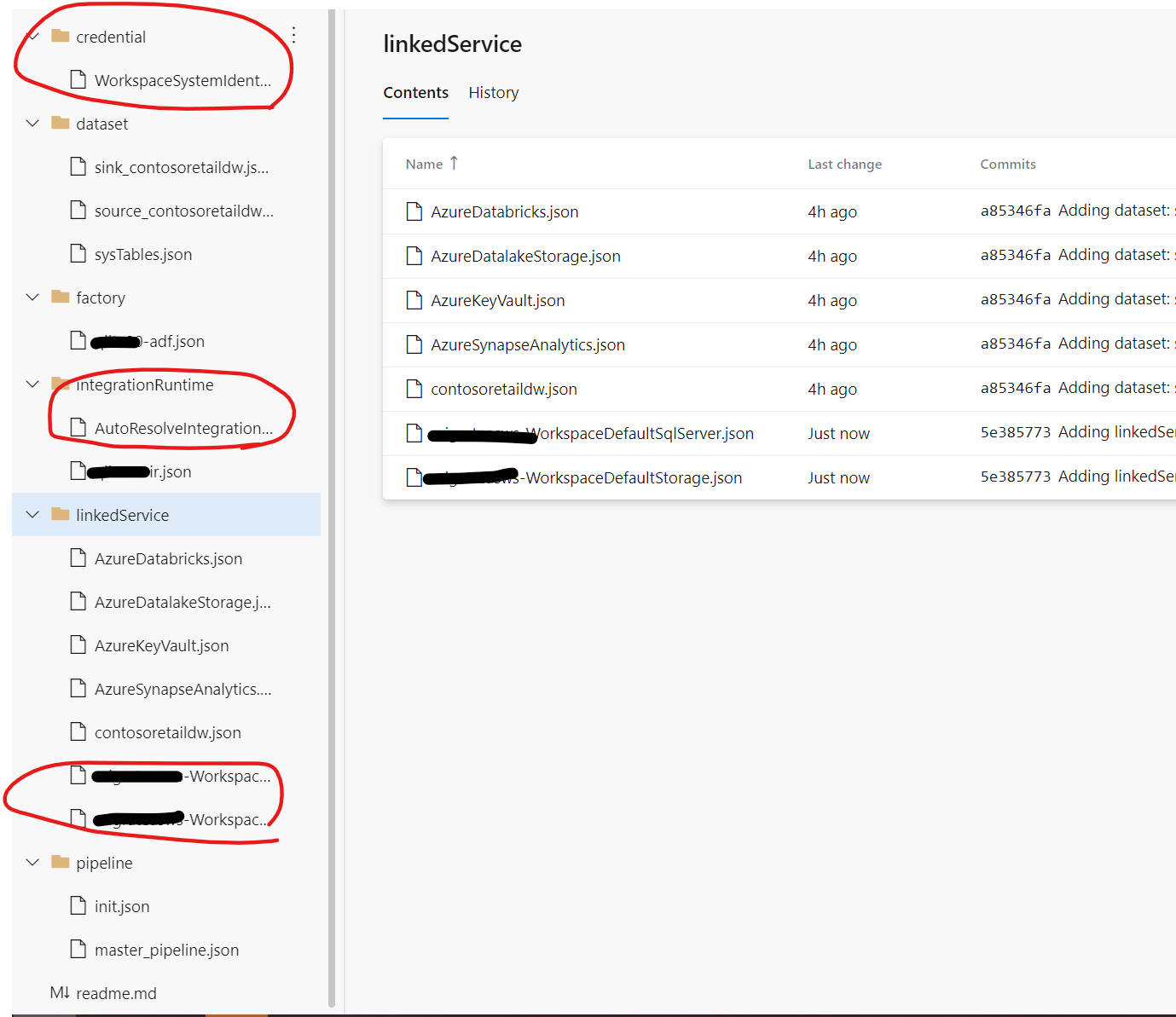
Synapse は初期状態では、Linked Serviceとして以下の二つと既定のAzure Integration Runtimeがコードで保存されています。
初期のLinked Serivice
- Synapseのリソース名-WorkspaceDefaultSqlServer
- 専用SQLプールへの接続です。パラメータに専用SQLプール名を入力することで、各種機能から専用SQLプールへ接続が可能です。
- Synapseのリソース名-WorkspaceDefaultStorage
- リソース作成時に指定したData Lake Storage
5. 参照先、アクティビティ修正
Datasetの参照先修正
地道な作業です。linked serviceのrelatedからリンクが張られているので、一つ一つ直していきます。
数が多い場合は一度localにcloneして、一括置換したほうがよいです。
対象はこの二つ
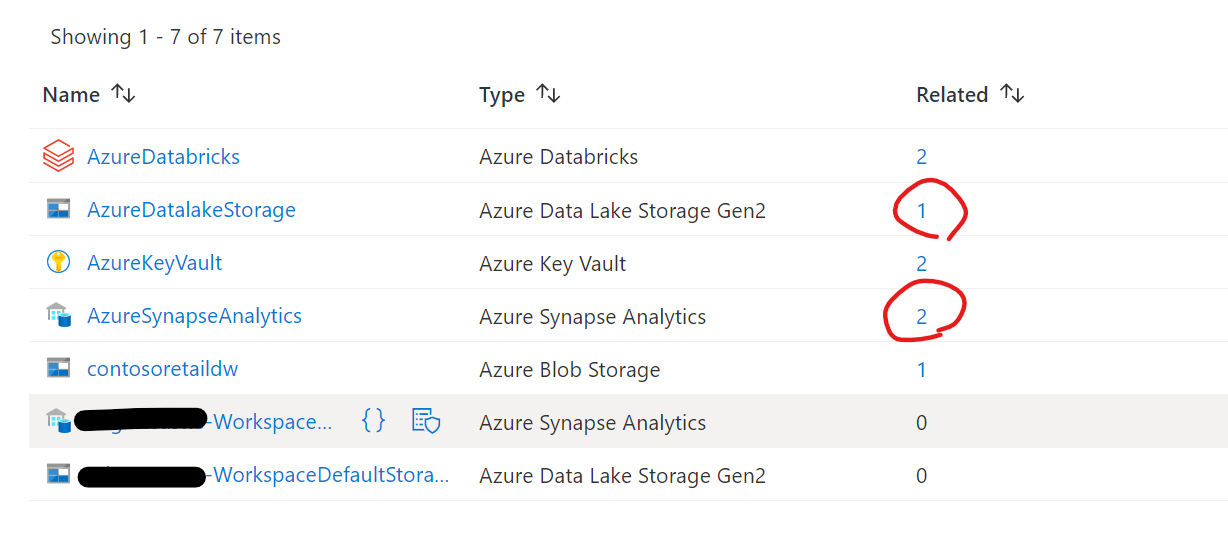
以下のように変更します。
Datalake用→Synapseのリソース名-WorkspaceDefaultStorage に変更
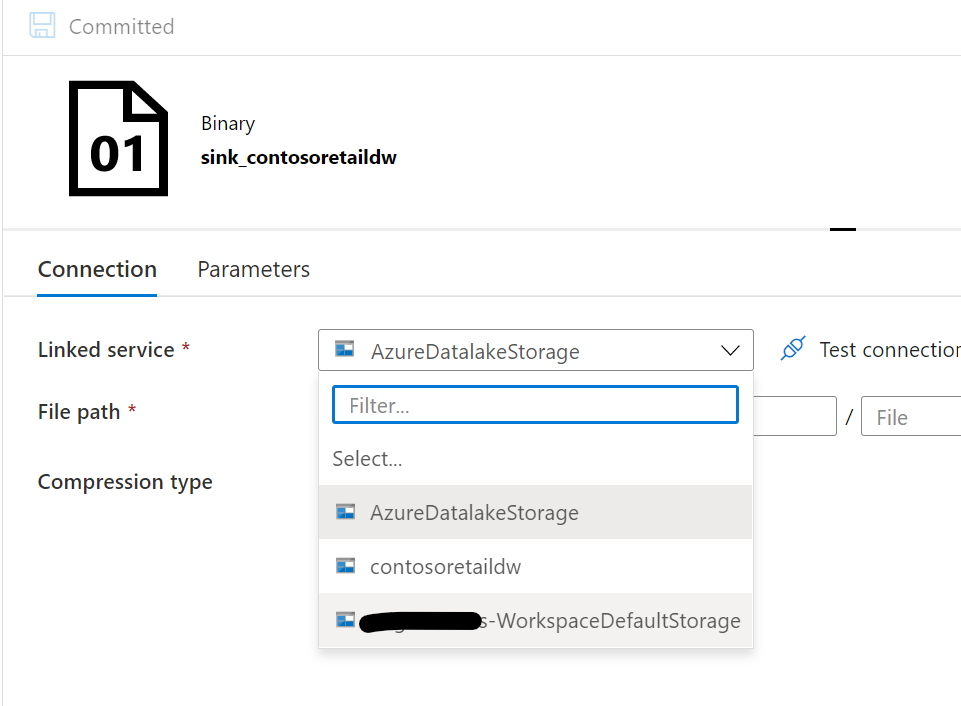
専用SQLプールSynapseのリソース名-WorkspaceDefaultSqlServerに変更
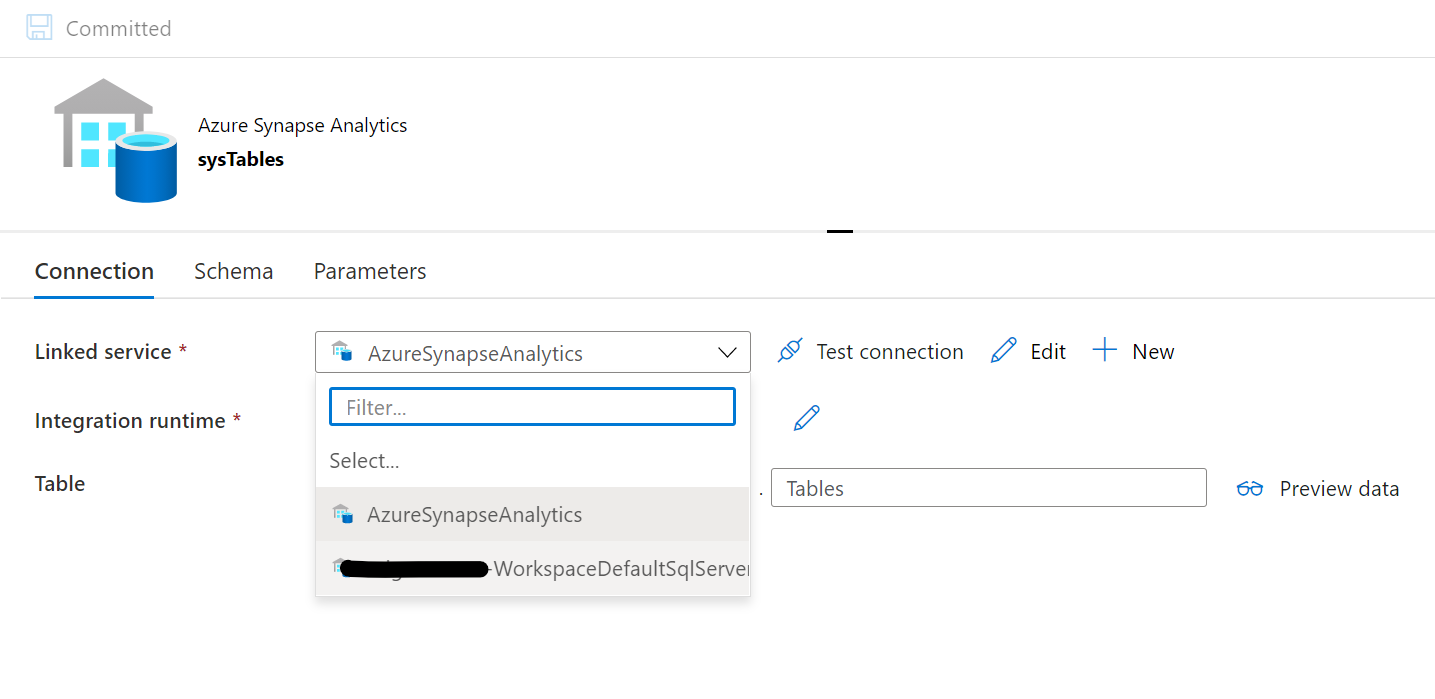
結果
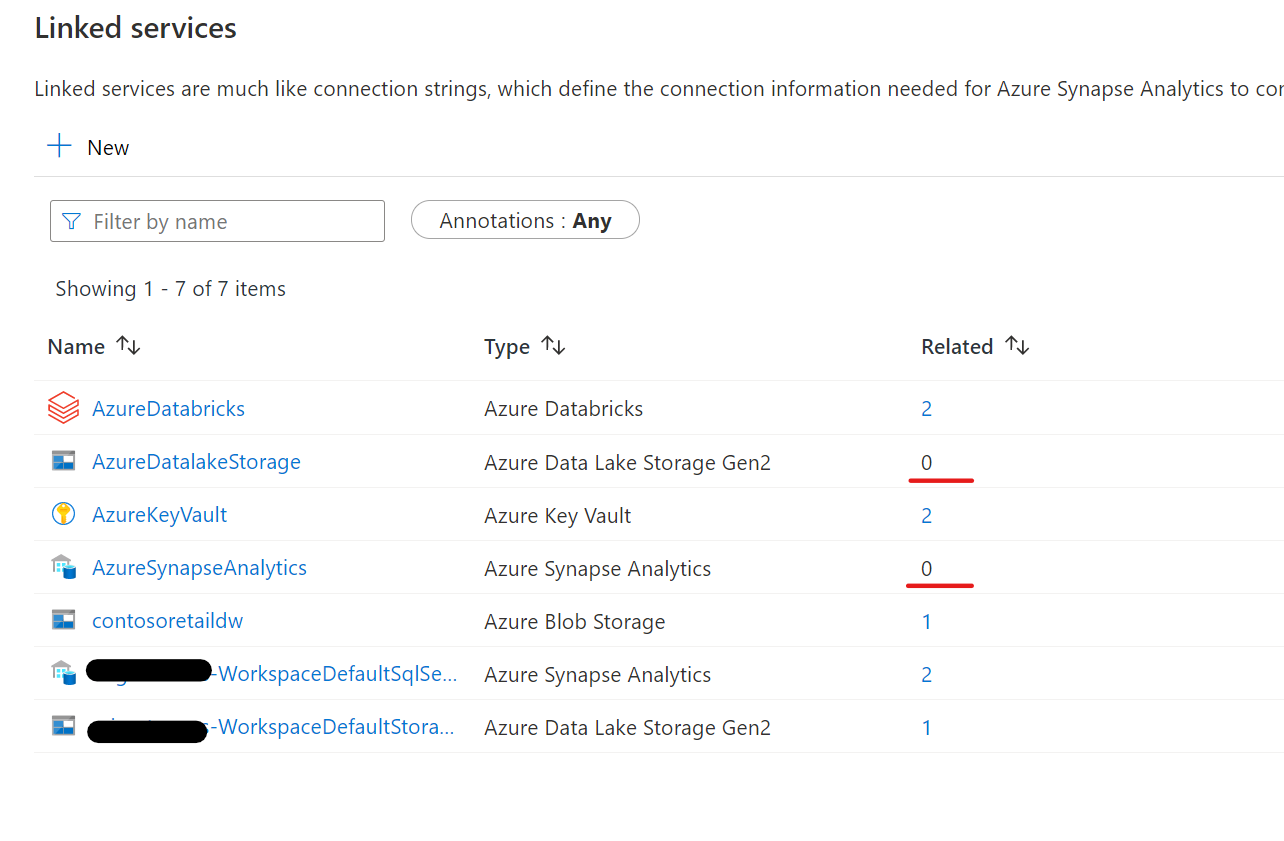
不要なlinked Serviceは削除しておきましょう。
もし、sas トークンの認証をしていた場合など認証情報をDataFactoryに保持していた場合は設定しなおしてください。
アクティビティの参照先修正
databricksアクティビティをsynapseのnotebookアクティビティに変更して、実行するnotebookを選択します。
Synapse notebookに変更します。
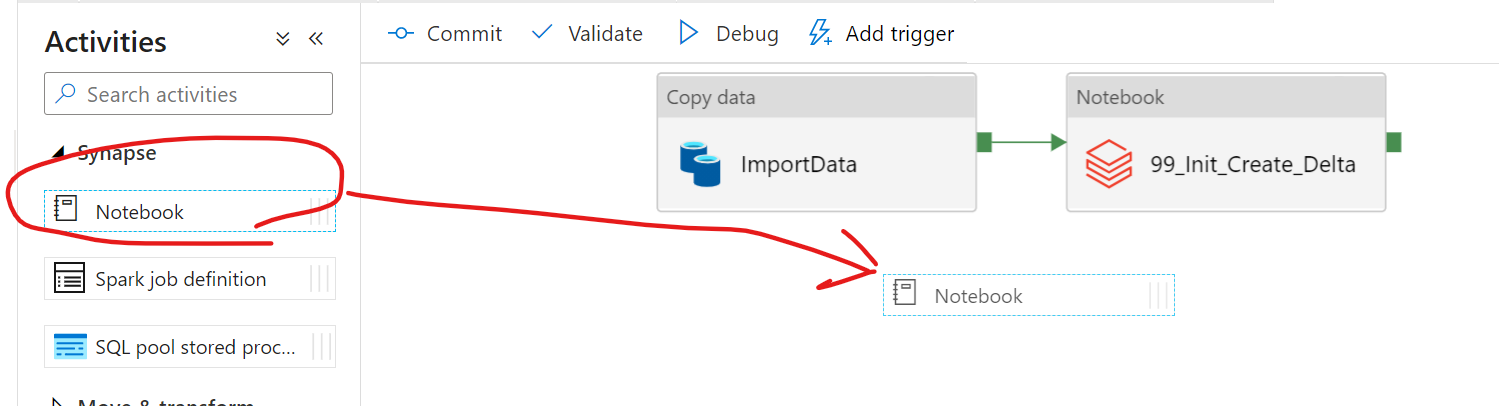
notebookの内容を選択しておきます。
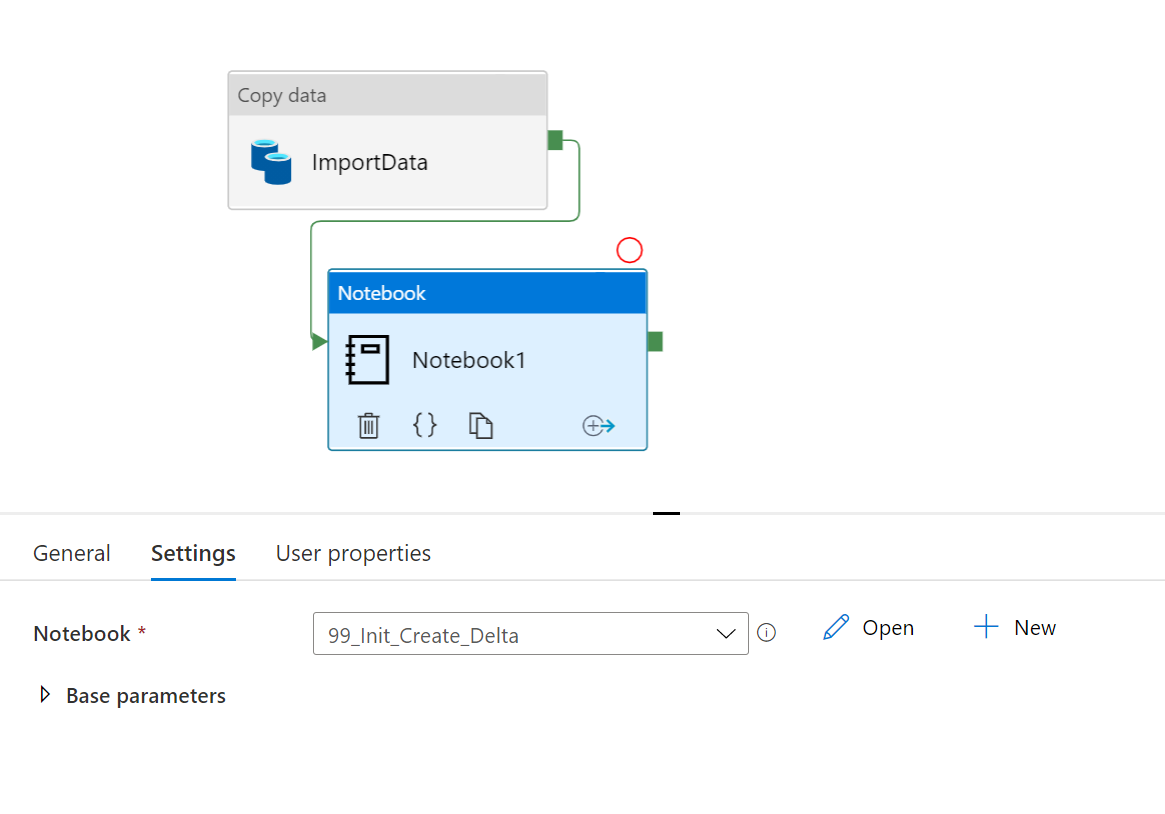
6. Databricks Notebook移行、修正(オプション)
Databricks Notebook移行
地道にipynb形式でノートブックをダウンロードします。
Databricks CLIを利用すれば少し楽です
ワークスペースフォルダーをローカルファイルシステムにエクスポートする
フォーマットオプションに関する参考:https://forums.databricks.com/questions/38399/databricks-cli-export-dir-to-save-ipynb-files-not.html
次に、Synapse Notebookとしてimportします。
複数ファイル選択してアップロード後、フォルダ構成などを修正します。
インポートから、すべてのファイルを一括アップしましょう
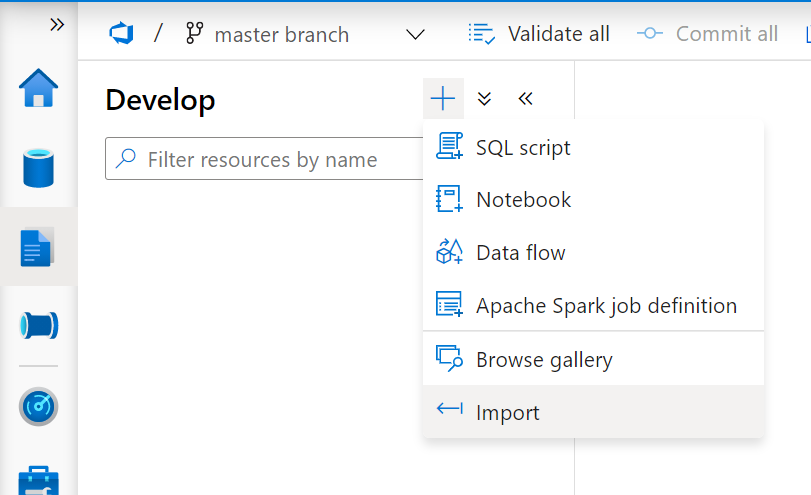
フォルダ作成まで実施します。
Databricks Notebook内容修正
参照しているパスは変えていきましょう。
マウントパスを指定している箇所をabfss:~ではじまるパスに書き換えます。
もし別のノートブックを呼び出しているパートがあったら、preview機能をオンにして、コードを書き換えます。
たとえば、
databricksでは「datalake」という名称のコンテナを「mnt/datalake」という名称でマウントしていた場合、
root_path = "dbfs:/mnt/datalake/contoso/"
と書いていましたが、
Synapseではこうなります。
# primary の場合
root_path = "/contoso/"
delta テーブルはdatabricksでこういう形式での定義(列名を事前定義して、空のテーブルを作る)ができましたが、こちらはSynapseでは対応していない記法なので注意
spark.sql(
"""
CREATE TABLE FactOnlineSales
(
OnlineSalesKey integer not null ,
~~~~~~~~~~~~~~~~~~~~~~~~~~~
)
USING delta
LOCATION '{}'
""".format(FactOnlineSales_delta_silver_path)\
)
Spark テーブルの挙動に関してはこちらの記事を参考にどうぞ
AzureSynapseAnalyticsのメタデータ共有についてわかったこと
補足
linked serviceに関して、以前のDatabricksアクティビティではData Factory->Databricksの認証設定が必要でしたが、Synapseでは不要となっています。
認証の管理オーバヘッドが低減されるのはSynapse Analyticsの良さのひとつですね