編集履歴
| 日付 | 内容 |
|---|---|
| 2021/10/21 | 公式サイトの情報追加 |
背景
2020年12月になって、ようやく東日本と西日本の両リージョンに Azure Synapse Analytics がデプロイされました。
これまで他のリージョンで使うしか無かったですが、その資産を捨てるのは勿体ないですよね。
今後の複数インスタンスへの展開も見据えて、各リソースの移行ステップについてまとめてみます。
公式サイトにも情報があります。こちらを主としてください。公式サイトに更新後、このBlogの内容の検証をしていません😅
一方のリージョンから他方に Azure Synapse Analytics ワークスペースを移動する
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/how-to-move-workspace-from-one-region-to-another
必要なもの
- Azure Subscription
- GitHub のアカウント
前提
- 移行中はシステムの停止が出来る
直球で表現すると、プロダクションのシステムでの方法ではないし、Microsoft がサポートしてくれる手順でもない、という事です😊
戦略
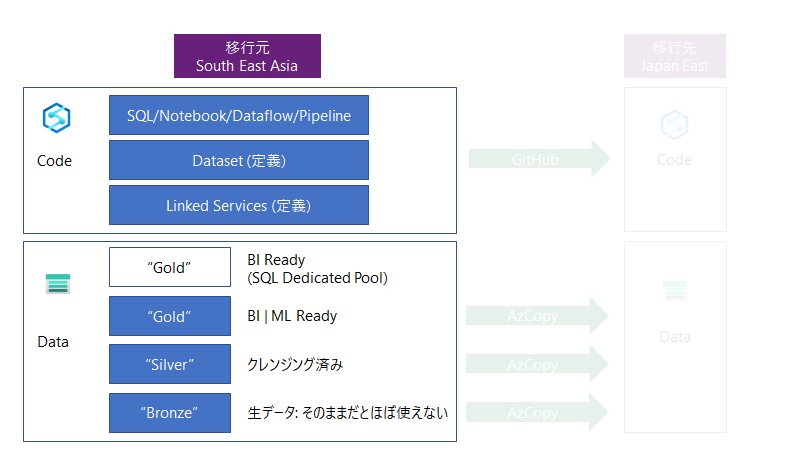
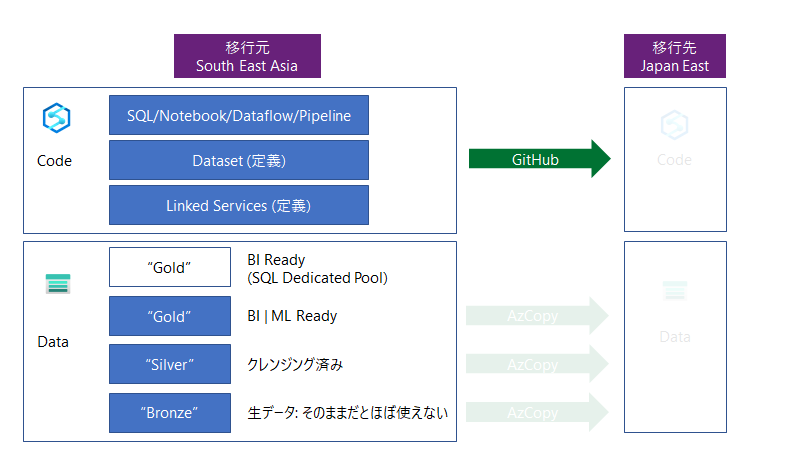
移行対象のリソースは以下になります。
- コード
- データ
とても重要な点を。
Azure Synapse Analytics はデータ分析用のサービスです。つまりデータが生まれる場所は別です。アプリケーションだったり、センサーだったりと。つまり、入力データは、元アプリケーション側でバックアップがあったりして、そこから ETL のジョブで流し込む事になります。
この図にある通り、データはもらってくるもの、という位置づけは肝に銘じましょう。
プロダクション環境でも移行時には既存・新規と2つのETLパイプラインジョブを動かした方がいいと思います。失敗しても戻せますし。
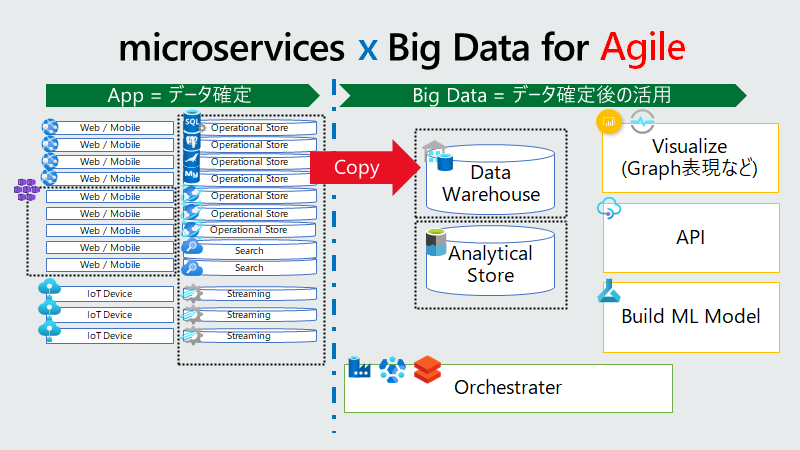
さて、以下の作戦で行きます
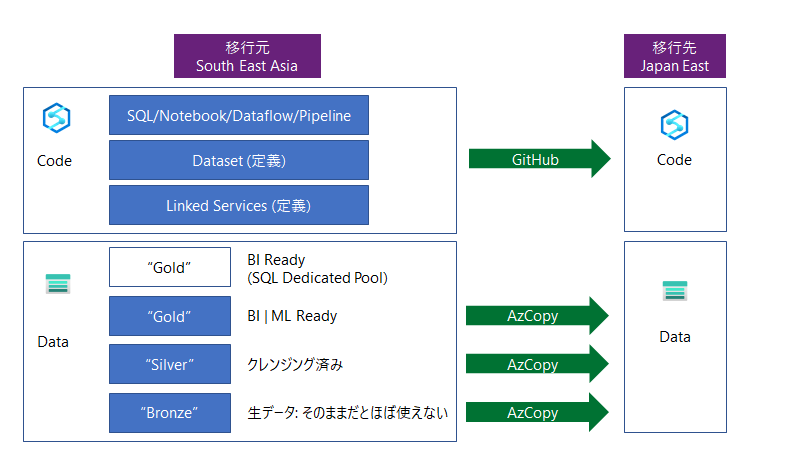
Data Lake Storage Gen 2 上のコンテナ (フォルダ) 構成の意味についてですが。
"Bronze", "Silver", "Gold" はデータが BI や AI で使える進行度をラベリングしたものです。

Bronze については、クレンジング後に捨てちゃっているものがあるかもしれませんね。
1. コード
Azure Synapse Analytics の管理ツールである Azure Synapse Studio は、コードベースが Data Factory と同じです。Data Factoryは、コードを Git もしくは AzureDevOps と連携させることができます。
ここでは、GitHub を利用します。多くの方が利用されているからです。
ちなみに、DDL文が無い場合、Azure Synapse Studio 上からでも作成してくれます。
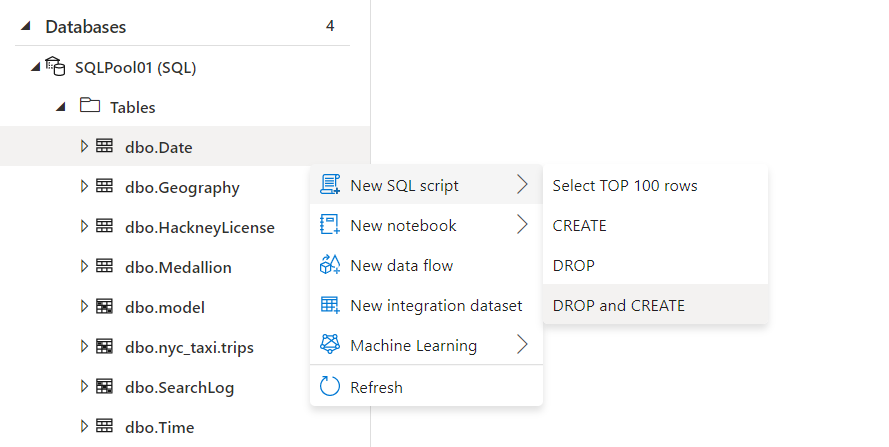
自動生成された Create Table 文の例:
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Date]
(
[DateID] [int] NOT NULL,
[Date] [datetime] NULL,
[DateBKey] [char](10) NULL,
[DayOfMonth] [varchar](2) NULL,
[DaySuffix] [varchar](4) NULL,
[DayName] [varchar](9) NULL,
[DayOfWeek] [char](1) NULL,
[DayOfWeekInMonth] [varchar](2) NULL,
[DayOfWeekInYear] [varchar](2) NULL,
[DayOfQuarter] [varchar](3) NULL,
[DayOfYear] [varchar](3) NULL,
[WeekOfMonth] [varchar](1) NULL,
[WeekOfQuarter] [varchar](2) NULL,
[WeekOfYear] [varchar](2) NULL,
[Month] [varchar](2) NULL,
[MonthName] [varchar](9) NULL,
[MonthOfQuarter] [varchar](2) NULL,
[Quarter] [char](1) NULL,
[QuarterName] [varchar](9) NULL,
[Year] [char](4) NULL,
[YearName] [char](7) NULL,
[MonthYear] [char](10) NULL,
[MMYYYY] [char](6) NULL,
[FirstDayOfMonth] [date] NULL,
[LastDayOfMonth] [date] NULL,
[FirstDayOfQuarter] [date] NULL,
[LastDayOfQuarter] [date] NULL,
[FirstDayOfYear] [date] NULL,
[LastDayOfYear] [date] NULL,
[IsHolidayUSA] [bit] NULL,
[IsWeekday] [bit] NULL,
[HolidayUSA] [varchar](50) NULL
)
WITH
(
DISTRIBUTION = HASH ( [DateID] ),
CLUSTERED COLUMNSTORE INDEX
)
GO
2. データ
Synapse の良いところは、全てのデータは Azure Data Lake Storage Gen2 にあるという事です。つまり、フォルダーとファイルののコピーをすれば良いわけです。
注意したい点としては、SQL Dedicated Pool (DWH) があります。SQL Dedicated Pool は、それ専用のストレージに、それ専用のデータを保存しています。
そのファイルを持っていく事は可能な限り避けます。それよりは、既存のETLのパイプラインを流すことを選択します。そのパイプラインのテストにもなるからです。
Azure Data Lake Storage Gen 2 のファイル転送には、AzCopyが便利です。
無料の Azure Storage Explorer には、GUIでの操作と、AzCopy オプションがあります。
対象の数が少ないときは、これで十二分でしょう。今回がそうですね。
移行対象のもの
こちらの Microsoft Cloud Workshop で作成したものです。
このハンズオンコンテンツの中で、準備用の説明があります。ここで作ったものです。
幾つかは技術検証用に加えたものがあります。
ここで、Azure Synapse Analytics の用語を、乱暴にですが😅、一般化してみましょう。
| Azure Synapse Analytics 用語 | 一般的な用語 |
|---|---|
| Linked Services | データ・ファイル関係の場合は、元データ。 サービスの場合は呼び出し先 |
| Database | データベース |
| Linked | 主にファイルストレージ |
| Integrate | ETL ジョブ |
| Develop | クエリやプログラムコード |
元データからの流れを考慮すると、上記順番でみていきたいものです。
- Linked services
上記が機能するためには、Linked Service の定義が必須です。
機械学習のPrediction関数を試していましたので、Azure Machine Learning のインスタンス連携もあります。
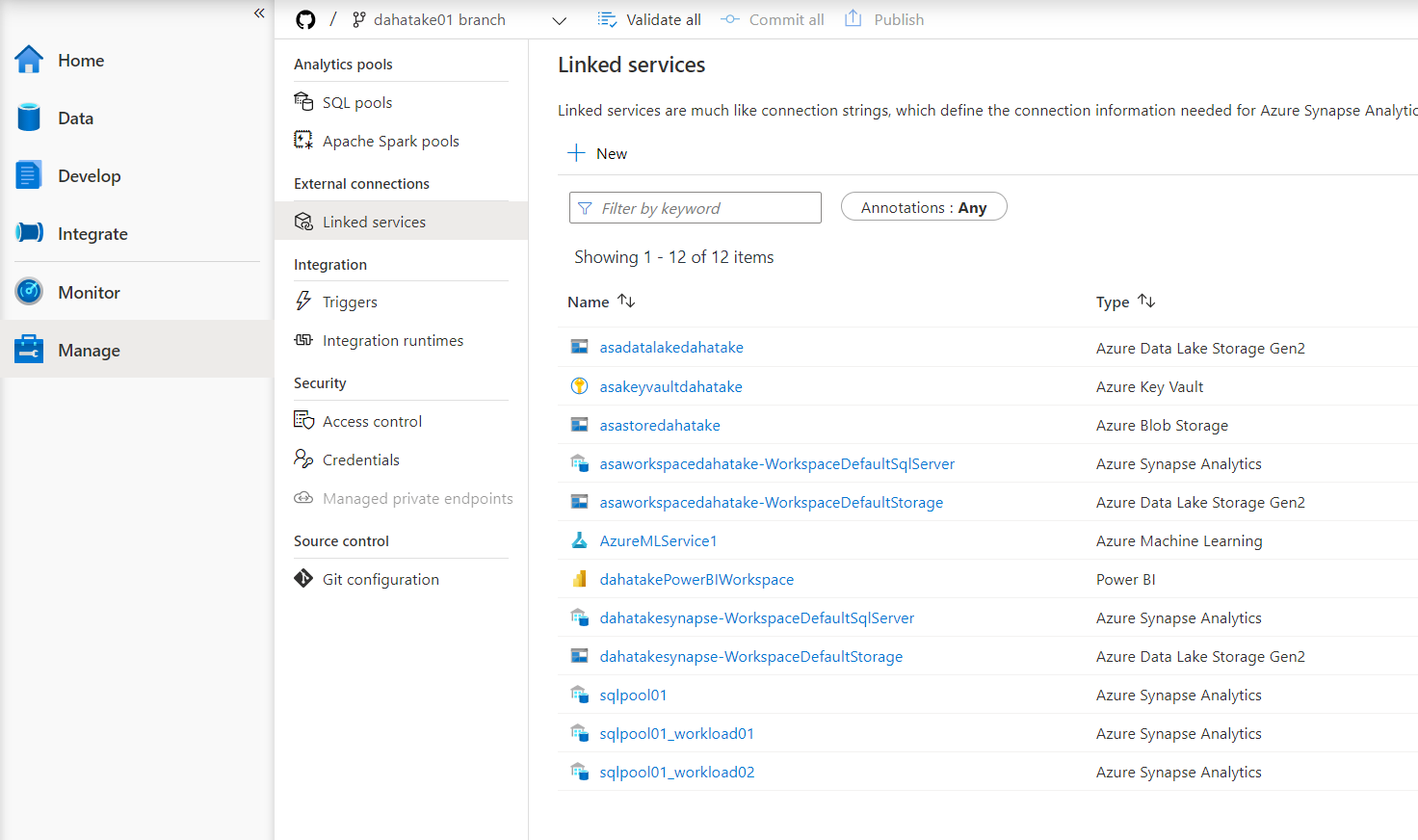
ちなみに、Azure Synapse Analytics と Azure Machine Learning のリンクをする手順はこちら:
- Database
最初が、SQL Dedicated Pool。
次は SQL Serverless のもの。Collation の UTF-8 設定をしたものですね。
下2つが Spark の Database です。

- Linked
主たるものは、Blob は使っていませんので、Azure Data Lake Storage Gen 2が対象です。
Dataset もあります。
実際のコンテナ構成は以下の通りです。数は少ないですね。
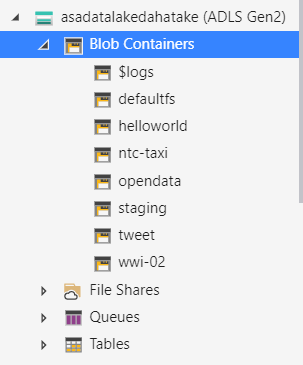
defaultfs は注意が必要です。Azure Synapse Analytics が使うストレージだからです。
本番環境では、所謂データのアカウントと、Synapse のシステムが使うストレージアカウントは別にしましょう。ストレージアカウント単位で、パフォーマンスに制限が設けられているためです。
パフォーマンス用に Azure Data Lake Storage Gen2 を最適化する:
https://docs.microsoft.com/ja-jp/azure/storage/blobs/data-lake-storage-performance-tuning-guidance
BLOB ストレージのパフォーマンスとスケーラビリティのチェックリスト:
https://docs.microsoft.com/ja-jp/azure/storage/blobs/storage-performance-checklist
- Integrate
ELT の処理ですね。Pipeline が幾つかあります。
- Develop
SQLクエリ や Spark のNotebook などのコードになります。
SQL スクリプトや Notebook は簡単にはいきません。
殆どの場合、直接 Data Source の場所を文字列で参照している事が多いと思います。
SQL スクリプトの例:
/*This sample uses COPY command to load data. You can either modify parameters or use BulkCopy utility by right clicking data from storage account to generate this script for loading your own data */
IF NOT EXISTS (SELECT * FROM information_schema.tables WHERE table_name = 'Weather')
CREATE TABLE [dbo].[Weather](
[usaf] [nvarchar](200) NULL,
[wban] [nvarchar](200) NULL,
[datetime] [datetime] NULL,
[latitude] [float] NULL,
[longitude] [float] NULL,
[elevation] [float] NULL,
[windAngle] [int] NULL,
[windSpeed] [float] NULL,
[temperature] [float] NULL,
[seaLvlPressure] [float] NULL,
[cloudCoverage] [nvarchar](200) NULL,
[presentWeatherIndicator] [int] NULL,
[pastWeatherIndicator] [int] NULL,
[precipTime] [float] NULL,
[precipDepth] [float] NULL,
[snowDepth] [float] NULL,
[stationName] [nvarchar](200) NULL,
[countryOrRegion] [nvarchar](200) NULL,
[p_k] [nvarchar](200) NULL,
[year] [int] NULL,
[day] [int] NULL,
[version] [float] NULL,
[month] [int] NULL
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
GO
COPY INTO Weather FROM 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=2018/month=2/'
WITH (
FILE_TYPE = 'PARQUET',
CREDENTIAL=(IDENTITY= 'Shared Access Signature', SECRET='""')
) OPTION (LABEL = 'COPY: Getting started');
Spark Notebook の例:
%%pyspark
df = spark.read.load([
'abfss://wwi-02@asadatalakedahatake.dfs.core.windows.net/product-json/json-data/product-1.json'
], format='json')
df.write.mode("overwrite").saveAsTable("default.product")
フォルダー構成が決まっているが故に、べた書きですね。変数をうまく使えていればこの辺りも解消するでしょう。
パイプラインからパラメーター値を割り当てる:
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/spark/apache-spark-development-using-notebooks?tabs=classical#assign-parameters-values-from-a-pipeline
リファクタリングも、Sprint の中で是非。
ステップ
戦略が決まり、その準備が出来たら作業に入りましょう。
1. 新規 Azure Synapse Analytics インスタンスの作成
特に迷わないと思います。
作成後は、2つありますね。

2. GitHub のリポの準備
新規の作成をお勧めします。失敗しても容易に再作成がやりやすいです。
Synapse の各サービスへのクリデンシャル情報の設定次第ですが。Private が使える場合は、Private で作成する事を強くおススメします。
今回使うリポです。

... 空だと寂しいっすね。
3. 現 Azure Synapse Analytics のクレンジング
データもですが、特にコードです。
使っていないコードや、連携サービスも削除しましょう。
この機会に。
4. コードの移行
4.1. 現 Synapse に GitHub の設定
執筆の少し前まで (2020/12/8) 、Azure Synapse Analytics では Git 対応していませんでした。早くから使っていただいている方には、この手順が必要かと思います。
- [Manage] - [Git Configuration] へ。
- [Set up code repository] から、GitHub へのセットアップをします。
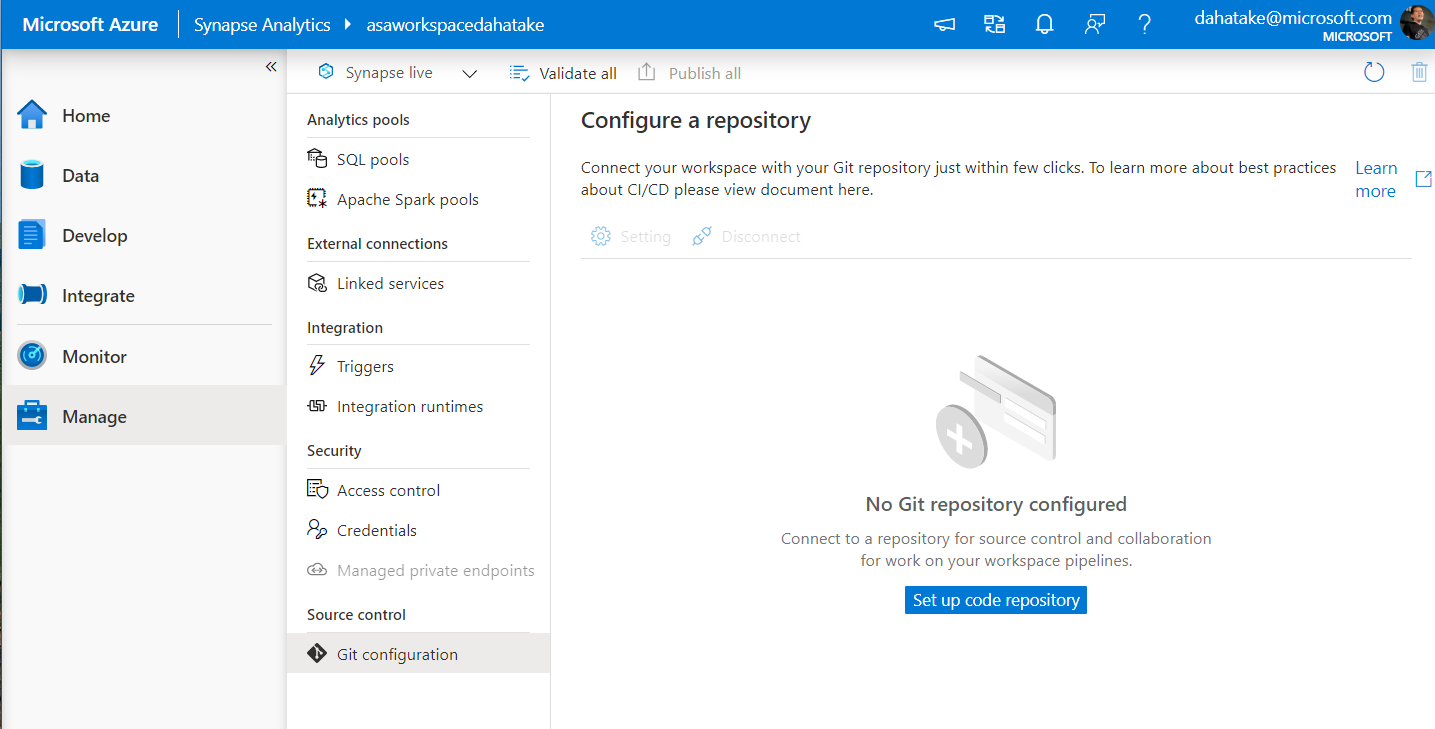
空のリポなので、ブランチは [main] しかありません。今回はこのままで行きます。
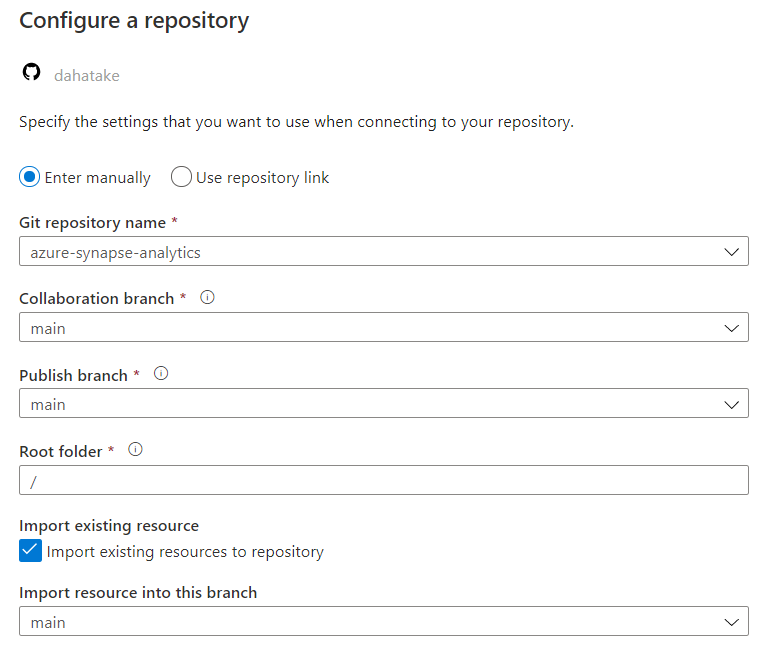
[Apply] 後、2-3分程度待ちます。時間は、恐らくですが、お持ちのコードの量で変わるかと思います。Git Clone などしていると思いますので。
諸々終わると、GitHub のリポにファイルがコピーされます。
時間があったら眺めてみると面白いかと思います。
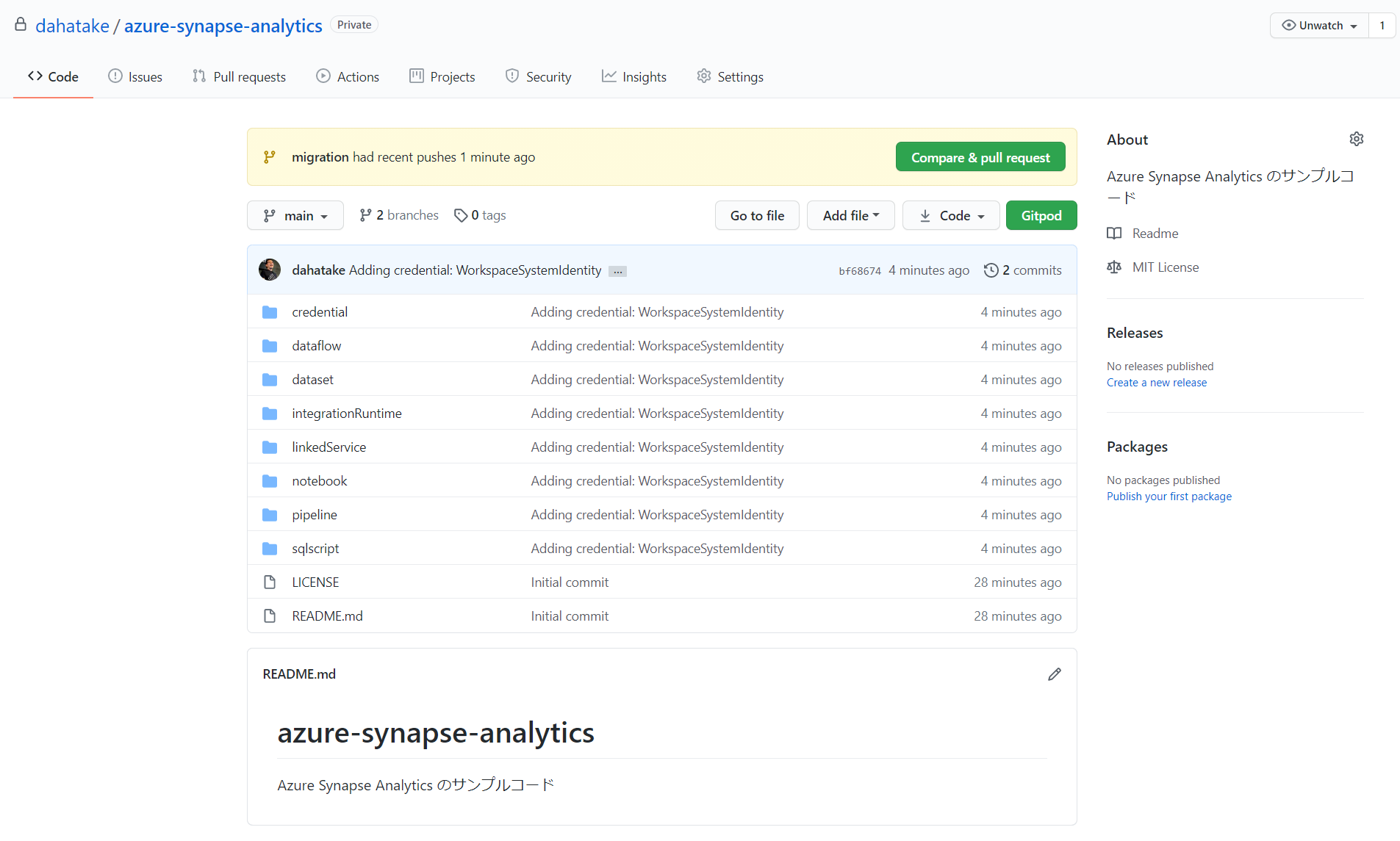
Source control in Azure Synapse Studio:
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/cicd/source-control
4.2. 現 Synapse で、GitHub 連携の削除 - Disconnect
塩漬けにしたいので、元のファイルはそのままに。GitHub 連携を絶ちます。
- [Manage] - [Git Configuration] から [Disconnect] をします。
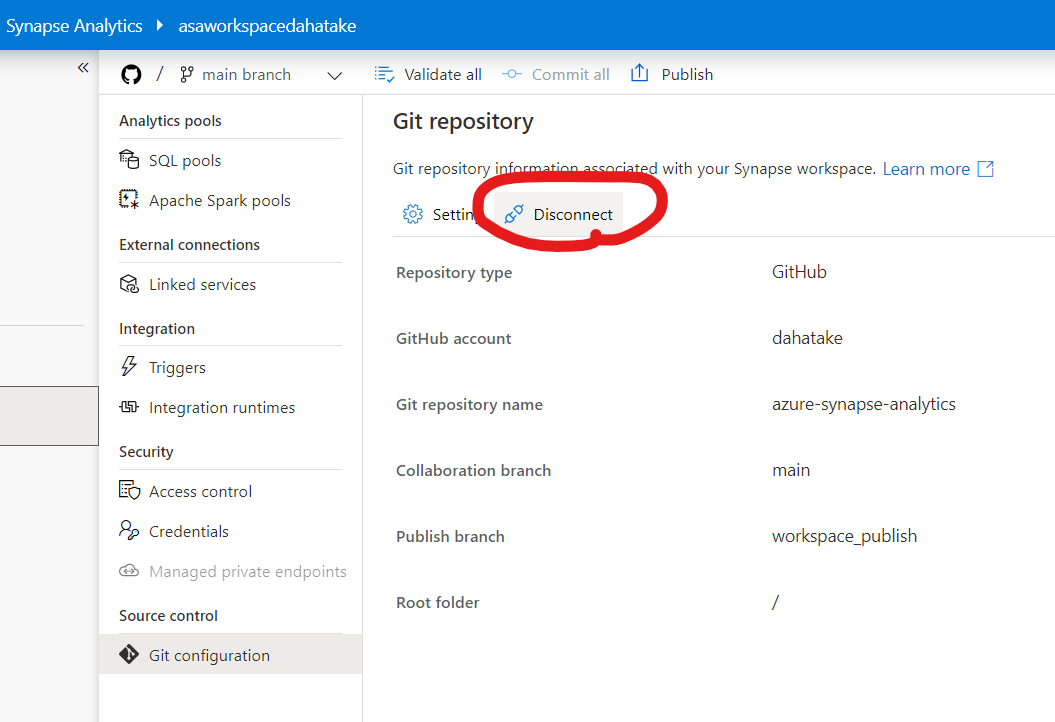
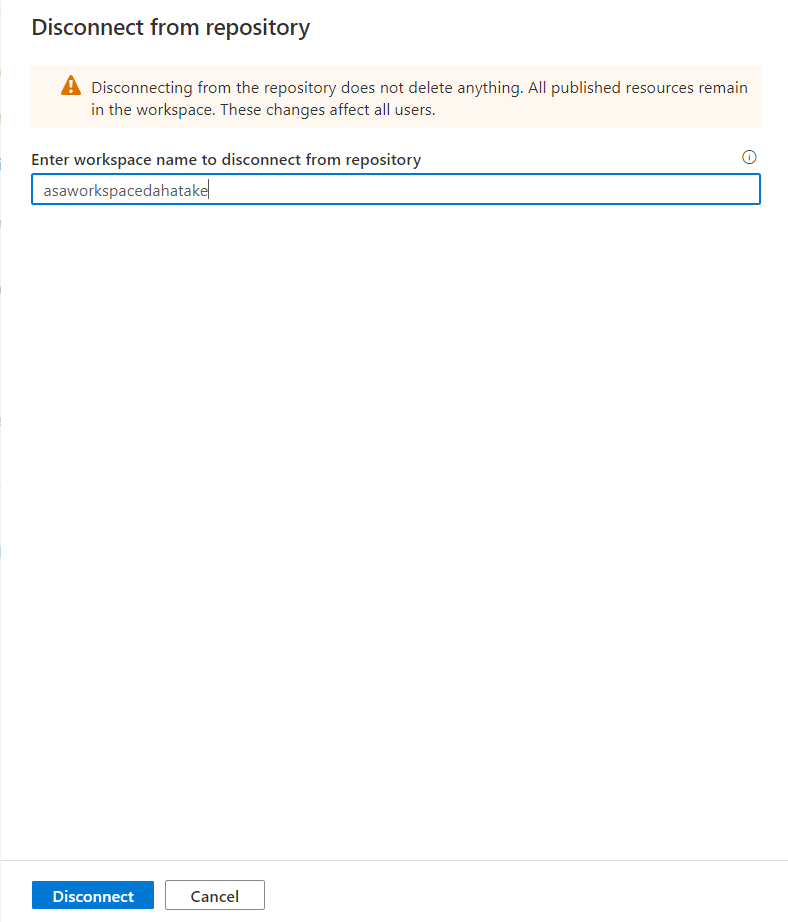
諸々、消えていない事を確認します。
4.2. 新 Synapse に GitHub の設定
4.1. と同じ手順を、移行先の Azure Synapse Analytics で行います。
ちなみに、Azure Synapse Studio で、ワークスペースの切り替えも出来ます。ですが、おススメは、2つのブラウザーで双方常時見られるようにしておくことです。何かと双方を見ます。作業中は。
同じく2-3分程度で GitHub 連携が完了します。
終わったら、Azure Synapse Studio で、それぞれがコピーされている事を確認します。
Database だけ空であることに注意してください。
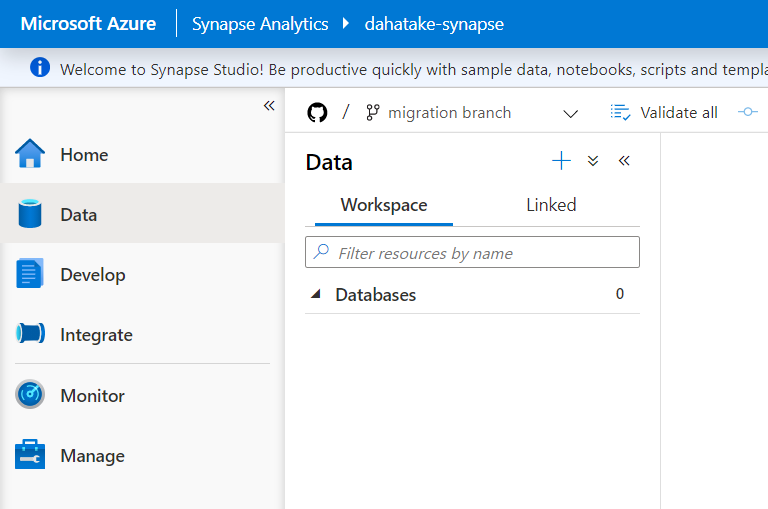
これで、新 Synapse に対応した GitHub リポが出来ました!
何かと安心ですね!
実はこの作業中に、Azure Synapse Analytics のソースコード連携の機能の理解が浅くて、何度もリソースを誤って削除したりしました... 作業を戻せる環境は、やってみる! という気持ちにさせてくれますね😊
注意点:
- GitHub 連携を止める、つまり、Disconnect すると、全てが元に戻ってしまいます。つまり、初期状態。ご注意ください。
- この注意書きもご一読ください。


5. ファイルのコピー
Azure Storage Explore で地道にコピーします。マジで地道です。
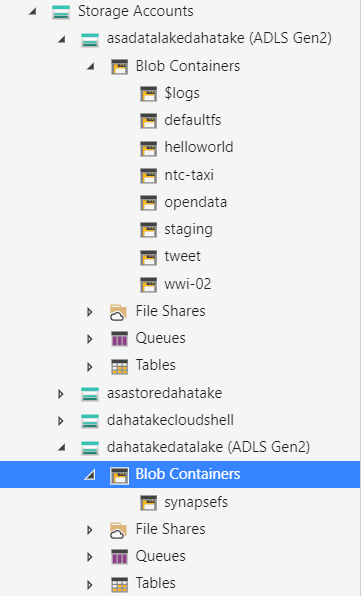
5.1. コンテナ作成
これは手作業です!😊
ちょっとリファクタリングしちゃいました!
5.2. フォルダーとファイルのコピー
Azure Storage Explore では、コピーと貼り付けのアクションで、裏側で AzCopy を使ってコピージョブを作成してくれます。
コピー:
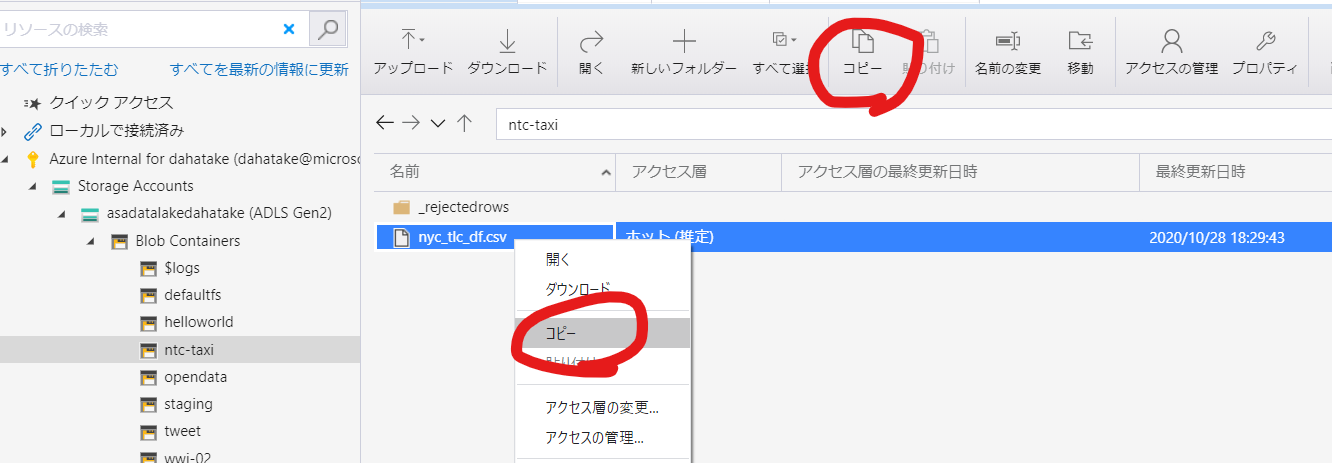
貼り付け:

コピージョブの状況:

作成された AzCopy コマンド:
./azcopy.exe copy "https://asadatalakedahatake.blob.core.windows.net/ntc-taxi/nyc_tlc_df.csv?sv=2019-12-12&st=2020-12-04T08%3A49%3A41Z&se=2020-12-11T08%3A49%3A41Z&sr=c&sp=rl&sig=Rs2E7VqRg1hdAsE5m2dKH%2BzGWGHzYSUHpGcmOsDX5sE%3D" "https://dahatakedatalake.blob.core.windows.net/nyx-taxi/nyc_tlc_df.csv?sv=2019-12-12&se=2021-01-03T09%3A04%3A55Z&sr=c&sp=rwl&sig=DdI%2BnXRo37jMys3N0NuG0z4mJHAi0J4S4nw3ptWE2xg%3D" --overwrite=prompt --s2s-preserve-access-tier=false --recursive;
これは素晴らしいですよね!
ちなみに、フォルダーとその配下のファイルも1度のアクションで全部一気にやってくれます。
3つのフォルダーを選択:

コピージョブの状況:

./azcopy.exe copy "https://asadatalakedahatake.blob.core.windows.net/tweet/*?sv=2019-12-12&st=2020-12-04T08%3A53%3A12Z&se=2020-12-11T08%3A53%3A12Z&sr=c&sp=rl&sig=UCRBzq1kR2seQ5wKJKtG4ypBycoPih12tM0gSVcvLY8%3D" "https://dahatakedatalake.blob.core.windows.net/tweet/?sv=2019-12-12&se=2021-01-03T09%3A08%3A16Z&sr=c&sp=rwl&sig=HpTL2Q9E%2BiheG%2FkOgjn5%2BVq0dOlv4r2mPCGFechI8Ac%3D" --overwrite=prompt --s2s-preserve-access-tier=false --list-of-files "C:\Users\dahatake\AppData\Local\Temp\stg-exp-azcopy-7a22cc20-ad46-4a9d-946d-9c32b385a36a.txt" --recursive;
なぜなら AzCopy で --recursiveをつけているから!
ディレクトリの内容をアップロードする:
https://docs.microsoft.com/ja-jp/azure/storage/common/storage-use-azcopy-blobs#upload-the-contents-of-a-directory
すべてのサブディレクトリのファイルをアップロードするには、--recursive フラグを追加します。
もう説明不要でしょう。
- もし、数が多い場合、先のAzCopyコマンドをスクリプト化
- もし、リトライなどをしたい場合、AzCopyn のパラメーターを追加
AzCopy - Option:
https://docs.microsoft.com/ja-jp/azure/storage/common/storage-ref-azcopy-copy#options

6. Link の移行
新旧の Data Lake Storage Gen 2 がある事を確認できます。
ここで、Azure Synapse Studio では、コピーも出来ちゃうと良いのですが...
6.1. Integration dataset の更新
参照先を変更します。
手作業だと手間なので、GitHub上のソースを直接編集します。
接続先毎に、それぞれが文字列で設定を保存していることがわかります。
例えばこれは SQL Dedicated pool の参照例。
properties - linkedServiceName - referenceName が、SQL Dedicated Pool の名前ですね。
typeProperties - schema が、SQL Dedicated Pool の Schema ですね。dbo の様な。
Visual Studio Code など JSONのフォーマットや、各種メタデータを理解した上での編集ツールで、定義の意味を理解すると良いかと思います。
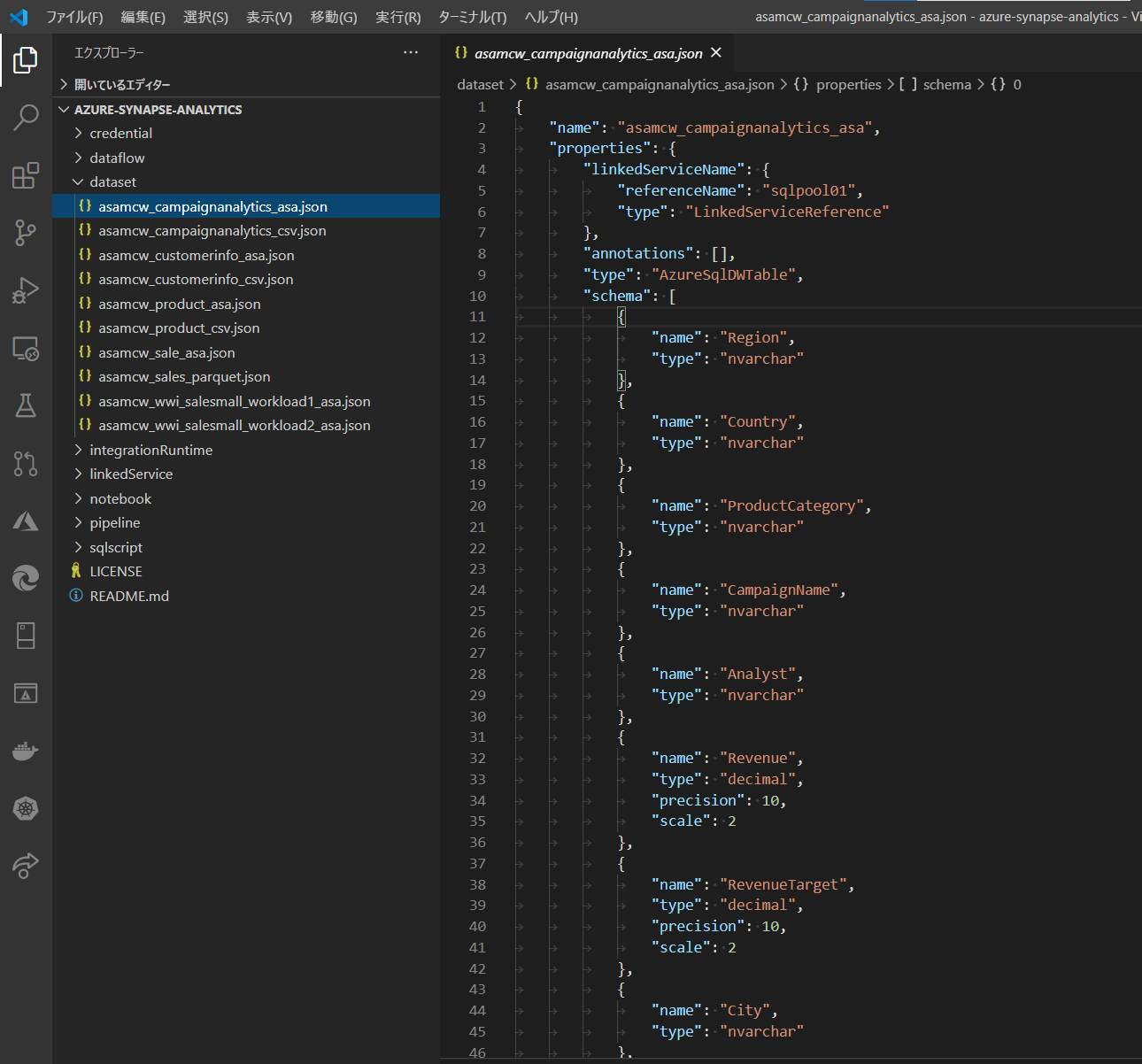
新旧のリソース名の対応に注意しながら編集します。
{
"name": "asamcw_campaignanalytics_asa",
"properties": {
"linkedServiceName": {
"referenceName": "sqlpool01",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "AzureSqlDWTable",
"schema": [
{
"name": "Region",
"type": "nvarchar"
},
{
"name": "Country",
"type": "nvarchar"
},
{
"name": "ProductCategory",
"type": "nvarchar"
},
{
"name": "CampaignName",
"type": "nvarchar"
},
{
"name": "Analyst",
"type": "nvarchar"
},
{
"name": "Revenue",
"type": "decimal",
"precision": 10,
"scale": 2
},
{
"name": "RevenueTarget",
"type": "decimal",
"precision": 10,
"scale": 2
},
{
"name": "City",
"type": "nvarchar"
},
{
"name": "State",
"type": "nvarchar"
}
],
"typeProperties": {
"schema": "wwi_mcw",
"table": "CampaignAnalytics"
}
},
"type": "Microsoft.Synapse/workspaces/datasets"
}
- GitHub のリポを、自身のPCにクローンします。
- Visual Studio Code など好みのエディターで編集します。
リファクタリングも含めて、全て更新ですね。
リポにコミットして、GitHub にプッシュします。
正しく構成できれいれば、Datasetの内容を確認できます。
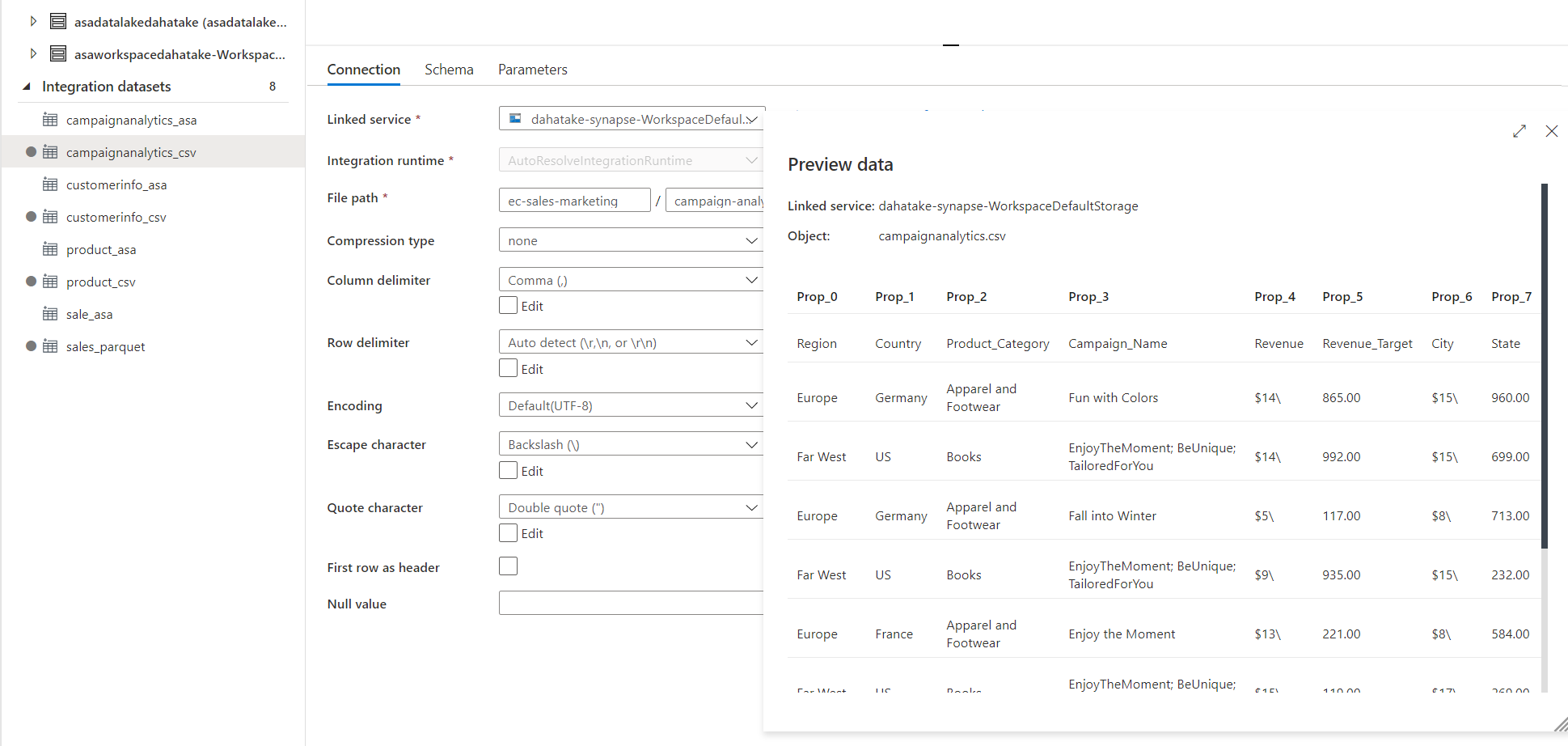
Tips. 1.
データさえ新 Data Lake にあれば、Azure Synapse Studio の画面から、様々なリソースの作成は容易です。
上記パラメータの内、何を設定して良いか曖昧なものがあれば。新 Azure Synapse Analytics の方で一つでもGUIで作成して、JSON文字列を参照するのも手です。
6.2. Linked services の削除
これで、旧 Blob および Data Lake Storage Gen 2 の参照先が無くなりましたので、リンク設定を削除します。
超すっきりしました!
7. Pipeline の実行
既存のPipelineを実行して、ETLジョブが正しく動くことを確認します。
8. SQL Dedicated Pool の移行 (オプション)
クエリ実行を優先したい!
SQL Dedicated Poolから移行した!
などの場合は、こちらがオプションです。
一回限りなので、Copy ツールを使います。
DDL文が失われた場合のためでもあります。DDLがある場合は、Create Table して、ETL処理、つまり Migration された Pipeline を実行してください。
8.1. 新 Azure Synapse Snalytics で Copy Data Tool を設定および実行
[Integrate] から Copy Data Tool を起動します。
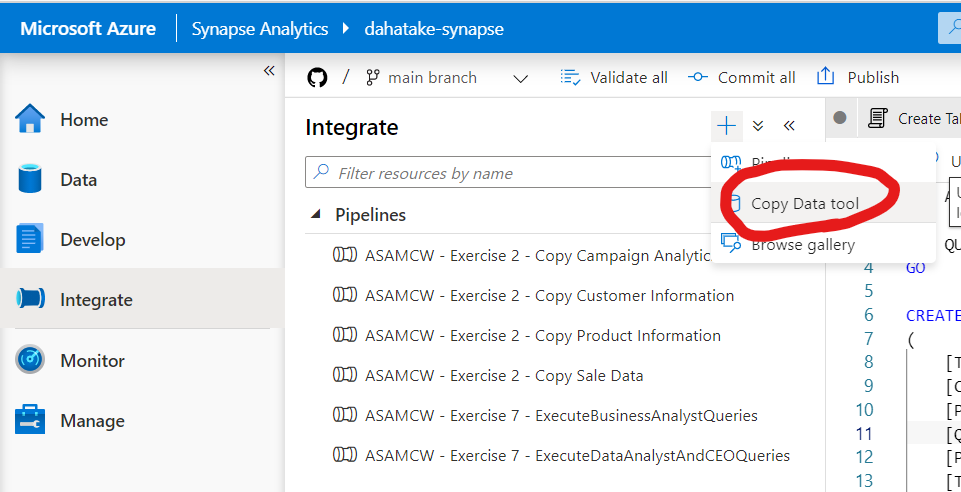
後は、ウィザードの通り。
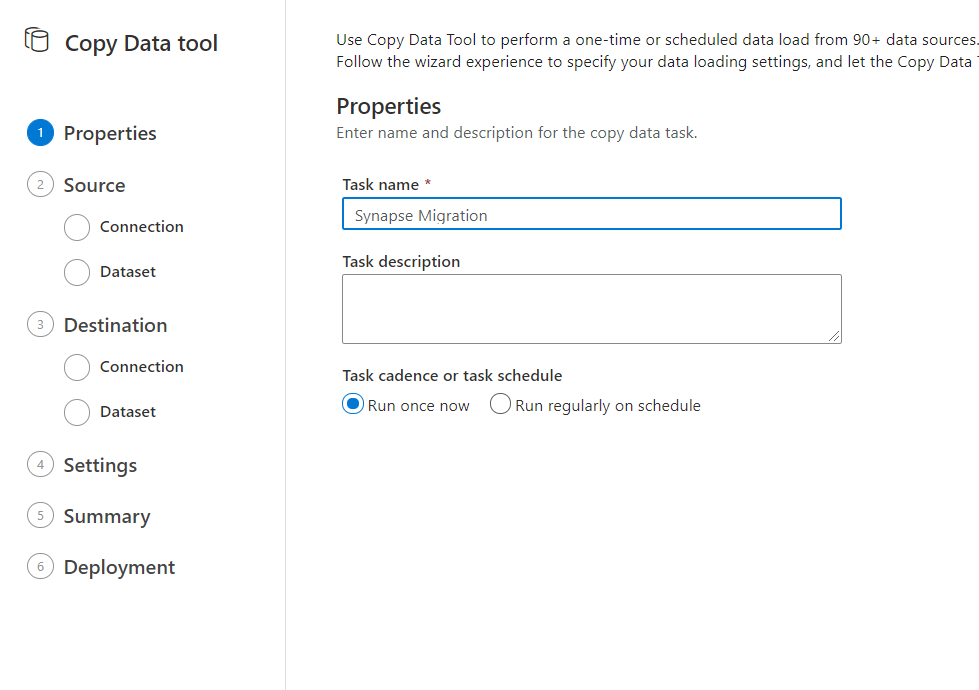
Azure Synapse Analytics を選択します。SQL Dedicated Pool に接続する際はこちらで。
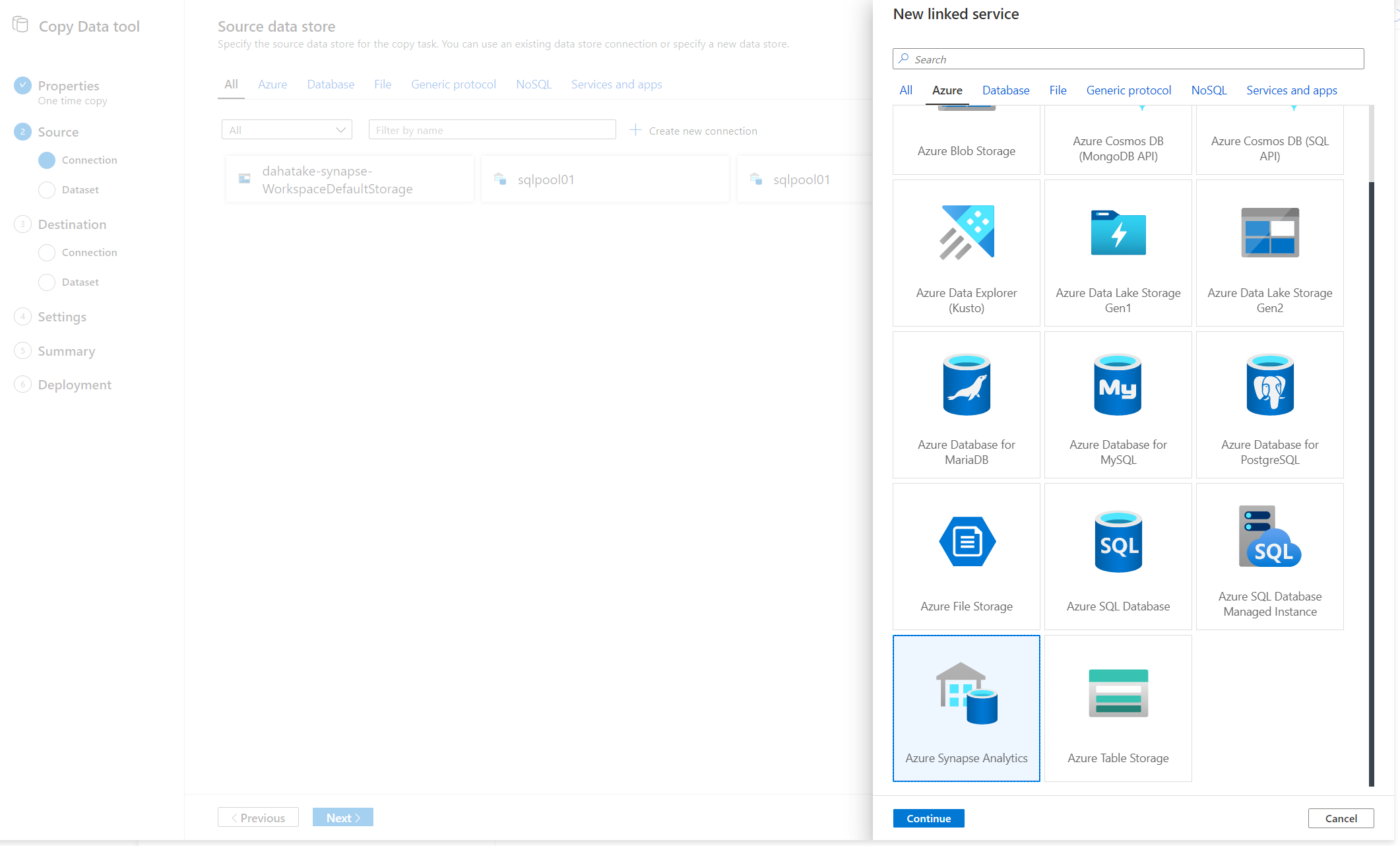
旧 Azure Synapse Analytics への認証。
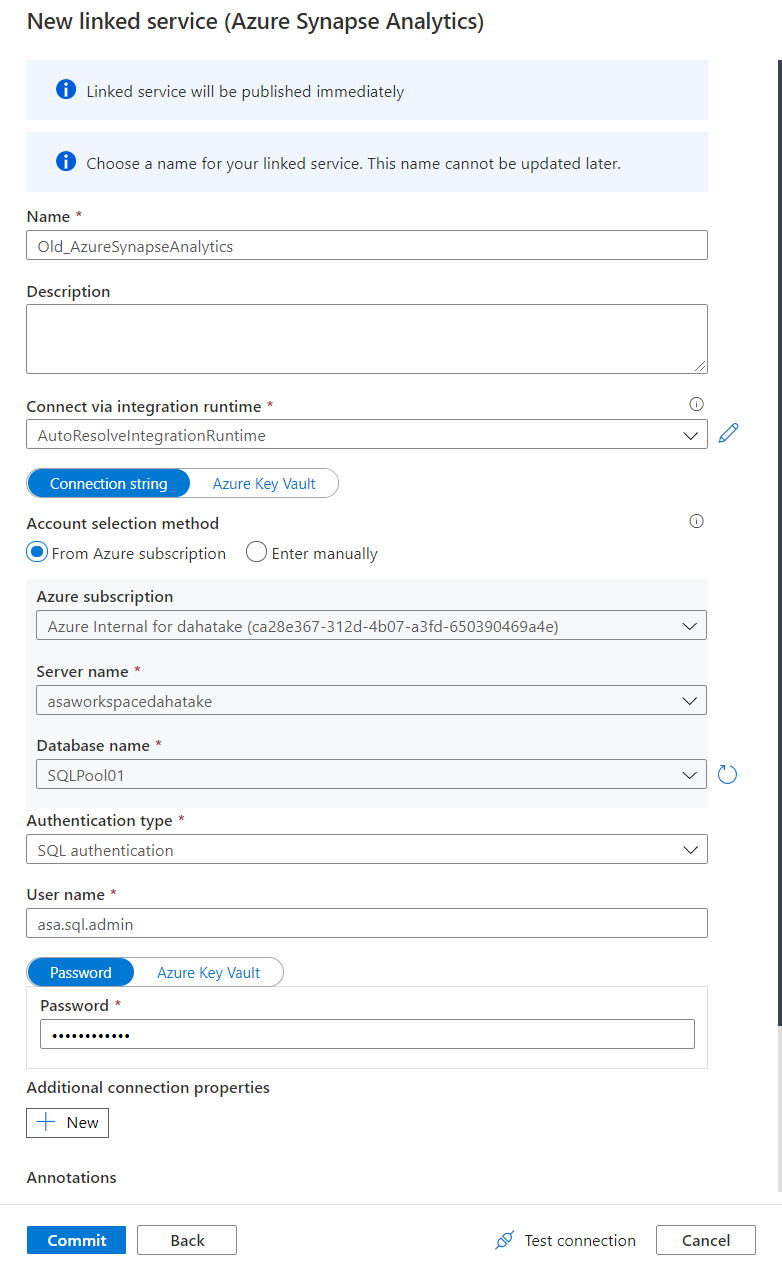
ここでログインはしていませんので、[Test Connection] で接続・認証確認を必ずしましょう。
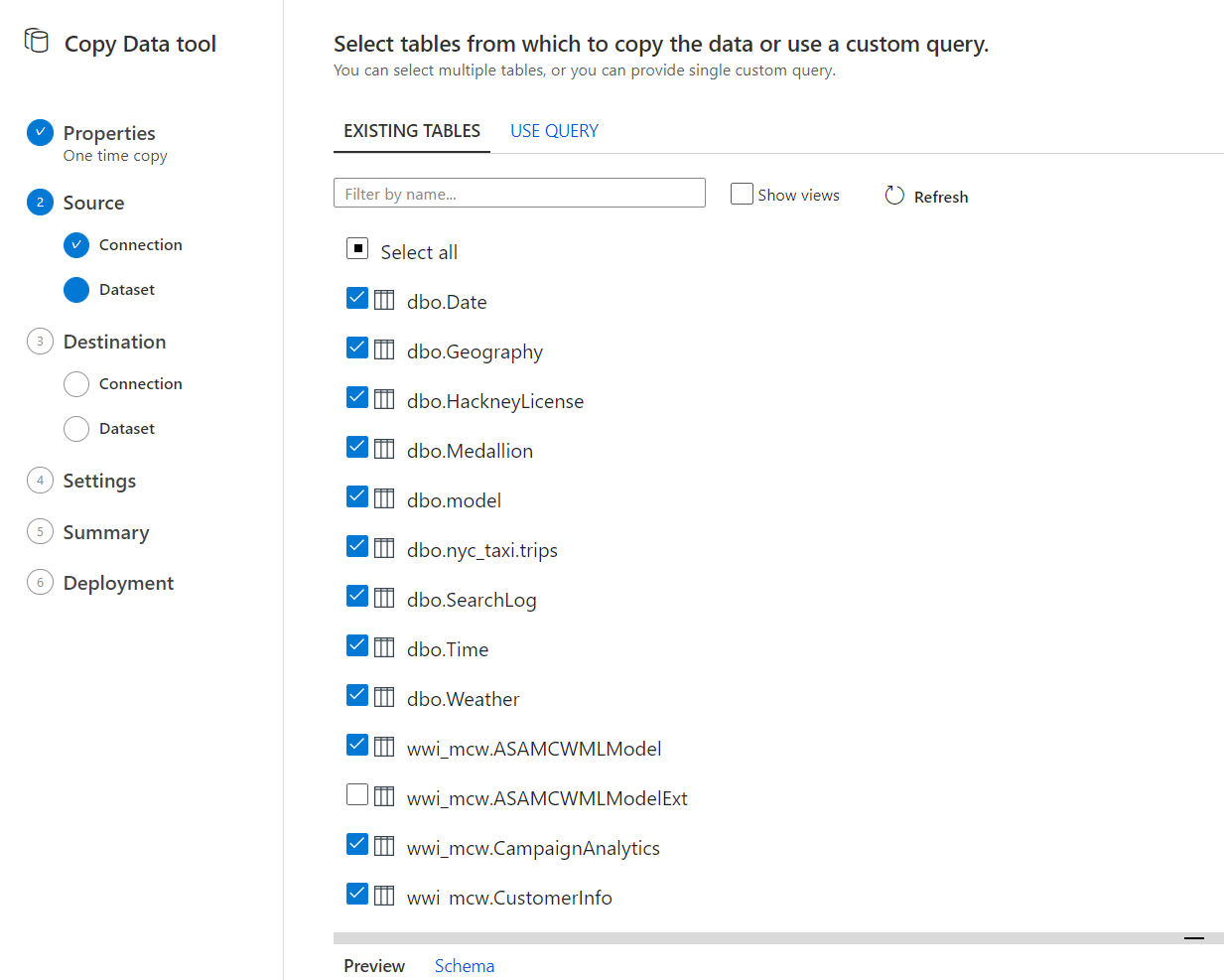
テーブルを選択します。
フィルター適用は、お好みで。
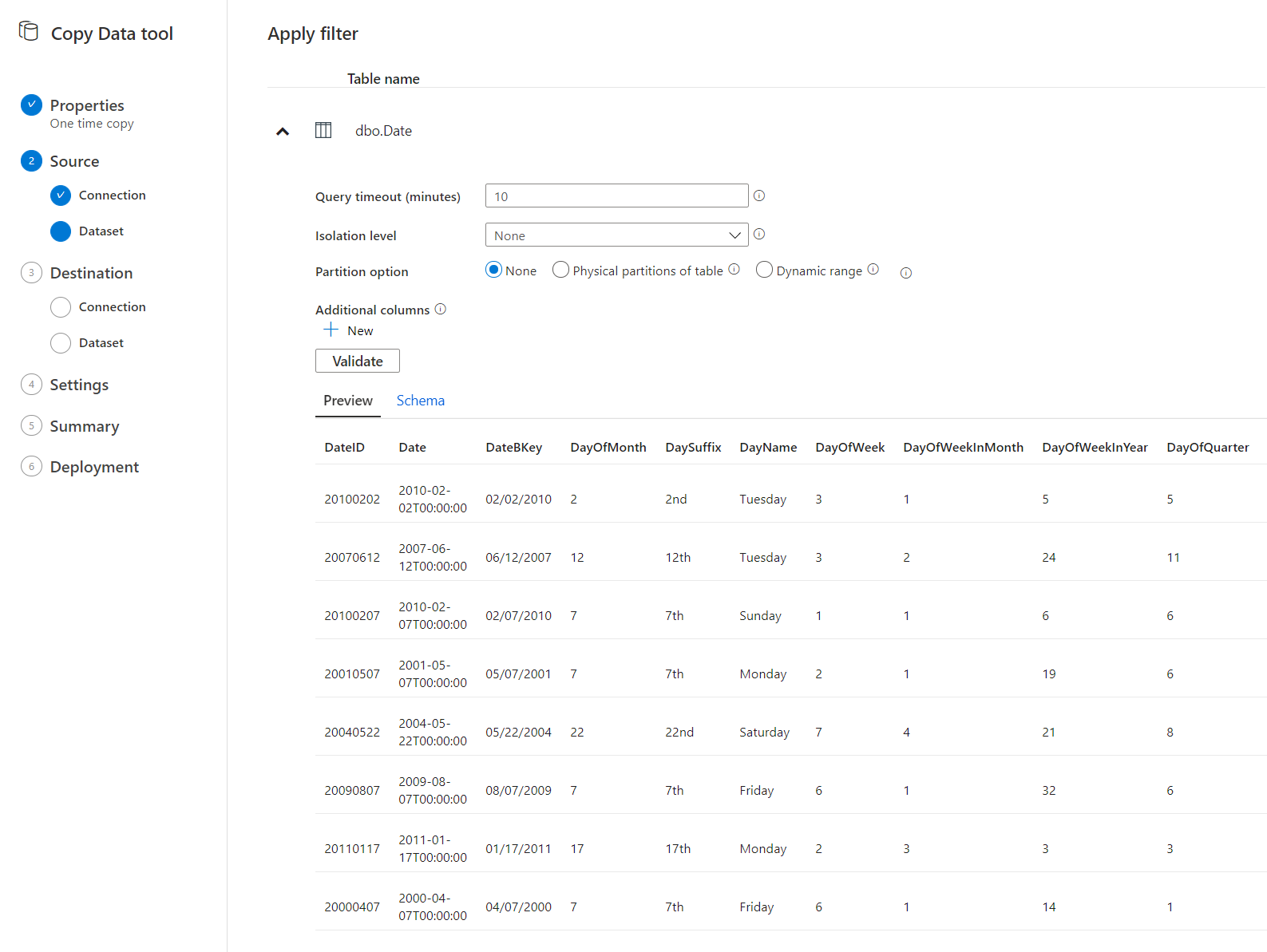
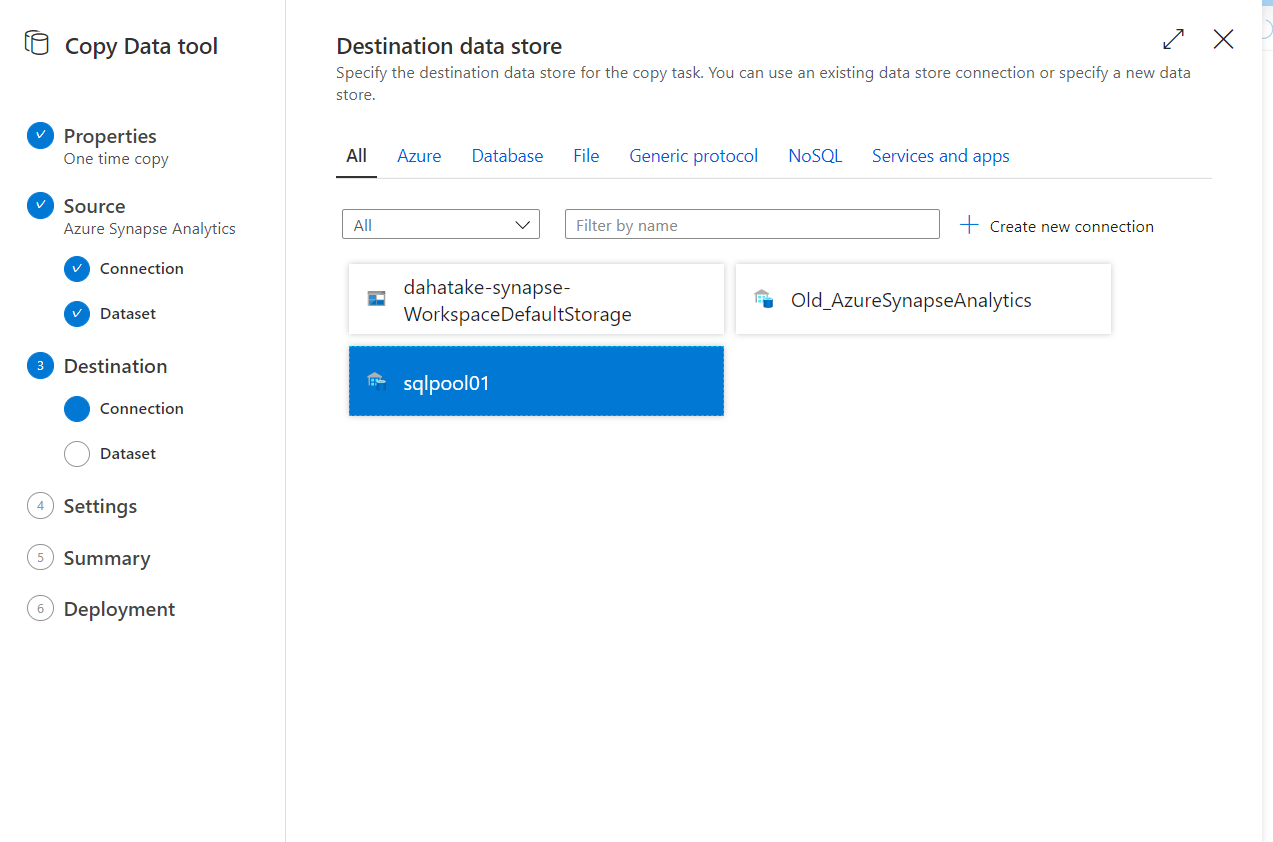
コピー先。つまり 新 SQL Dedicated Pool を選択します。
これが嬉しい部分!
新 Synapse Analytics にテーブルが無い場合は、[Auto-Create a destination table with the sorce data] をクリックします。

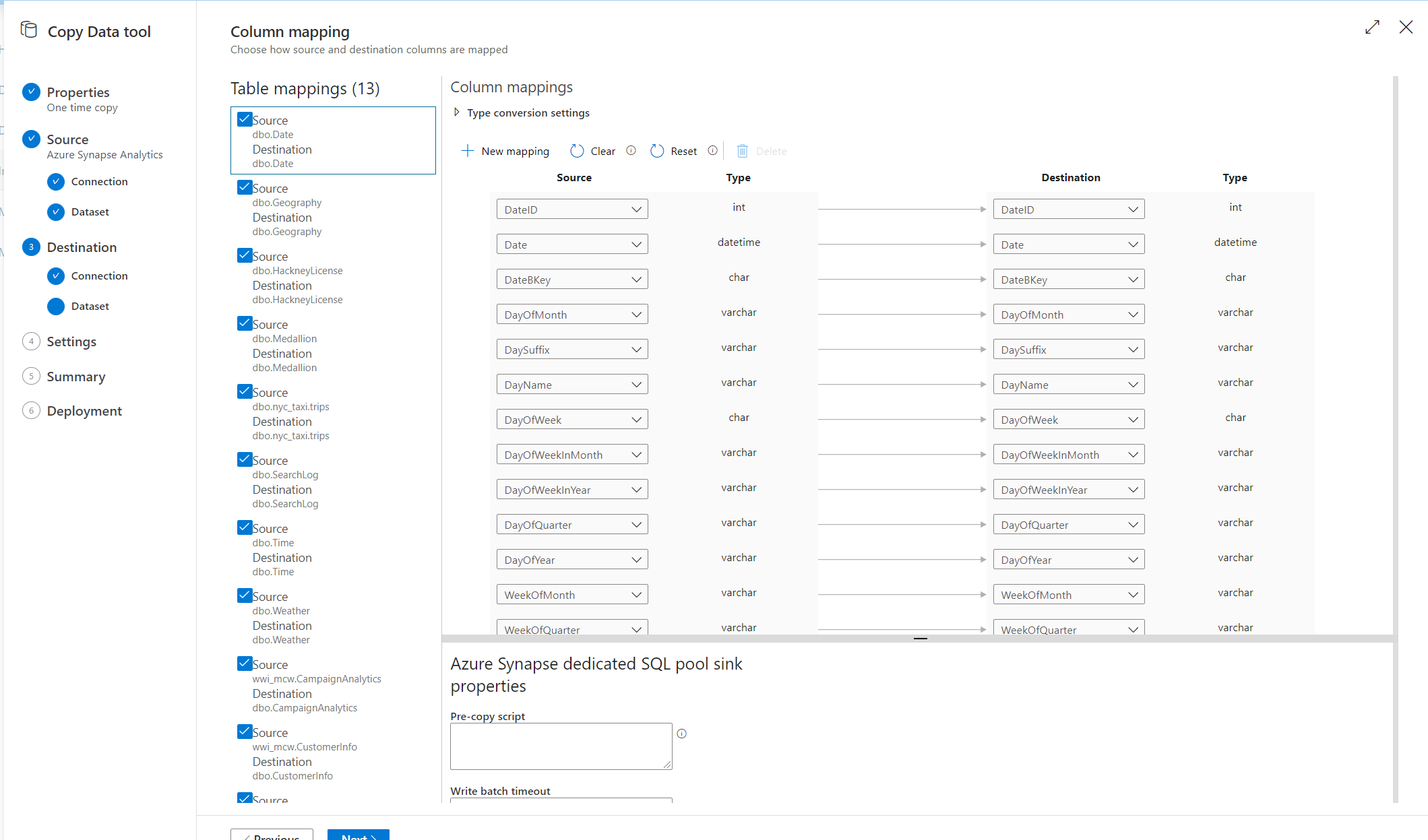
テーブルの先の列のマッピングです。
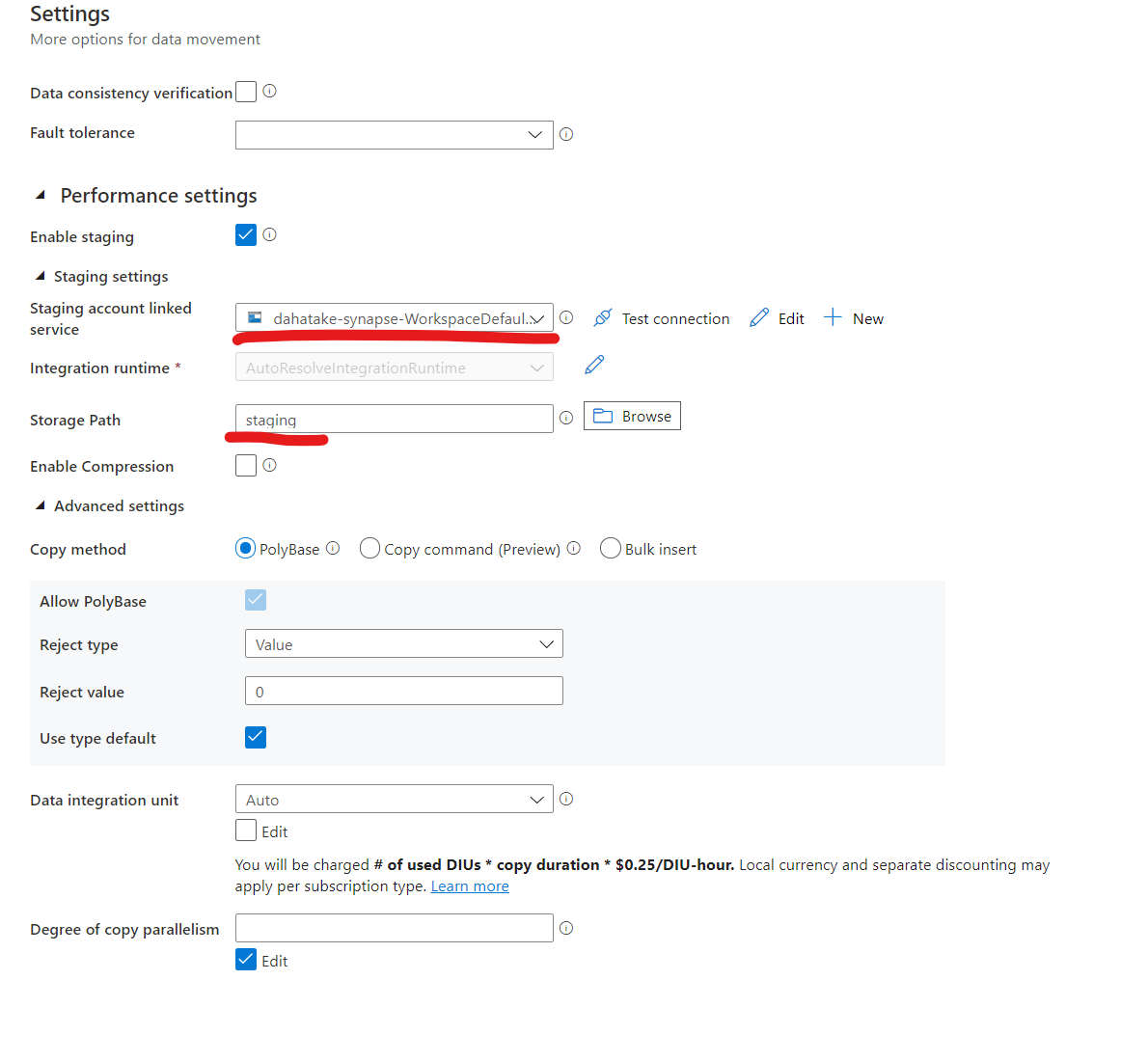
ジョブの設定です。
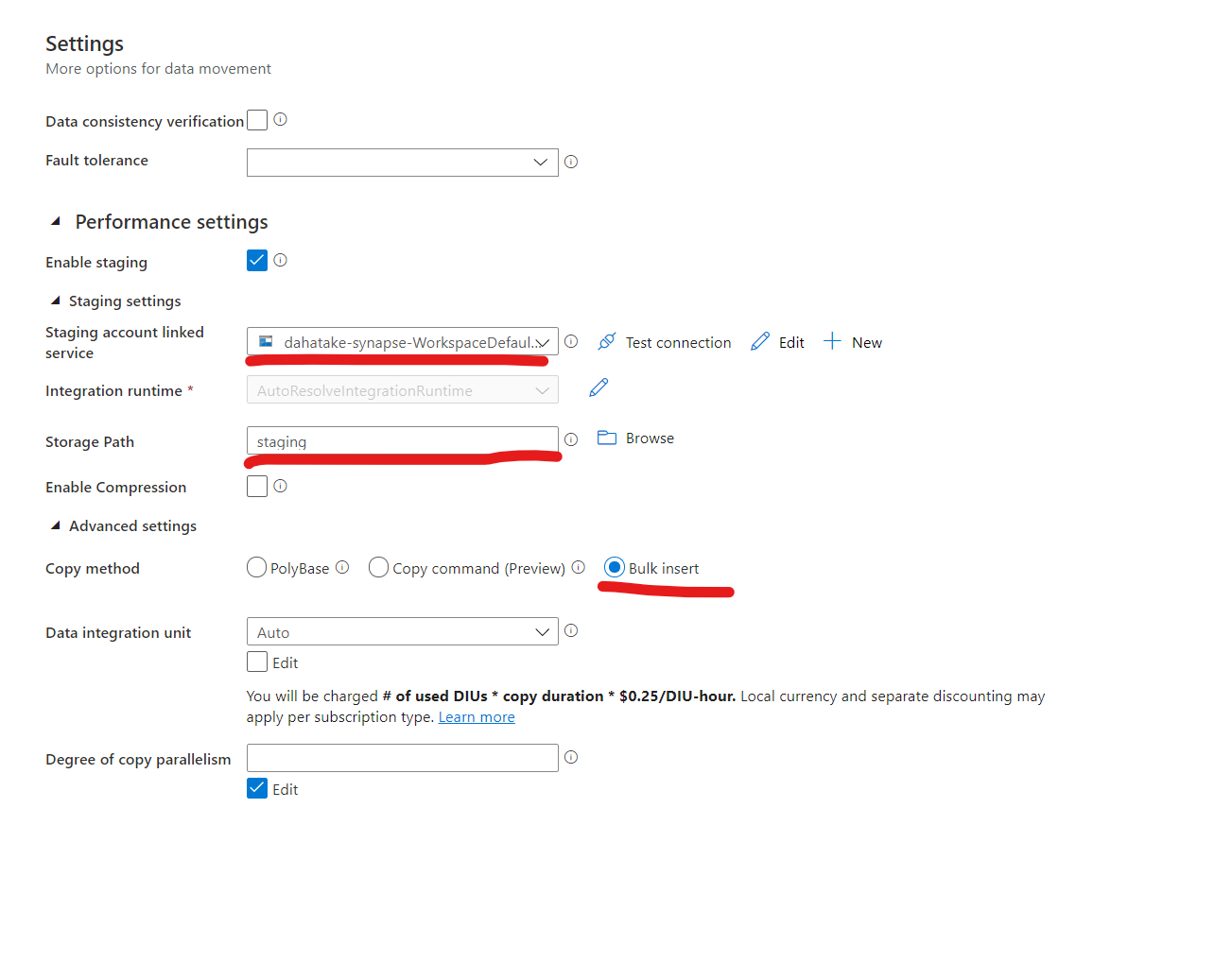
-
Stagingで、Data Lake Storage Gen 2 上のフォルダーを指定します。 - [Copy Method] を
Bulk Insertにします。
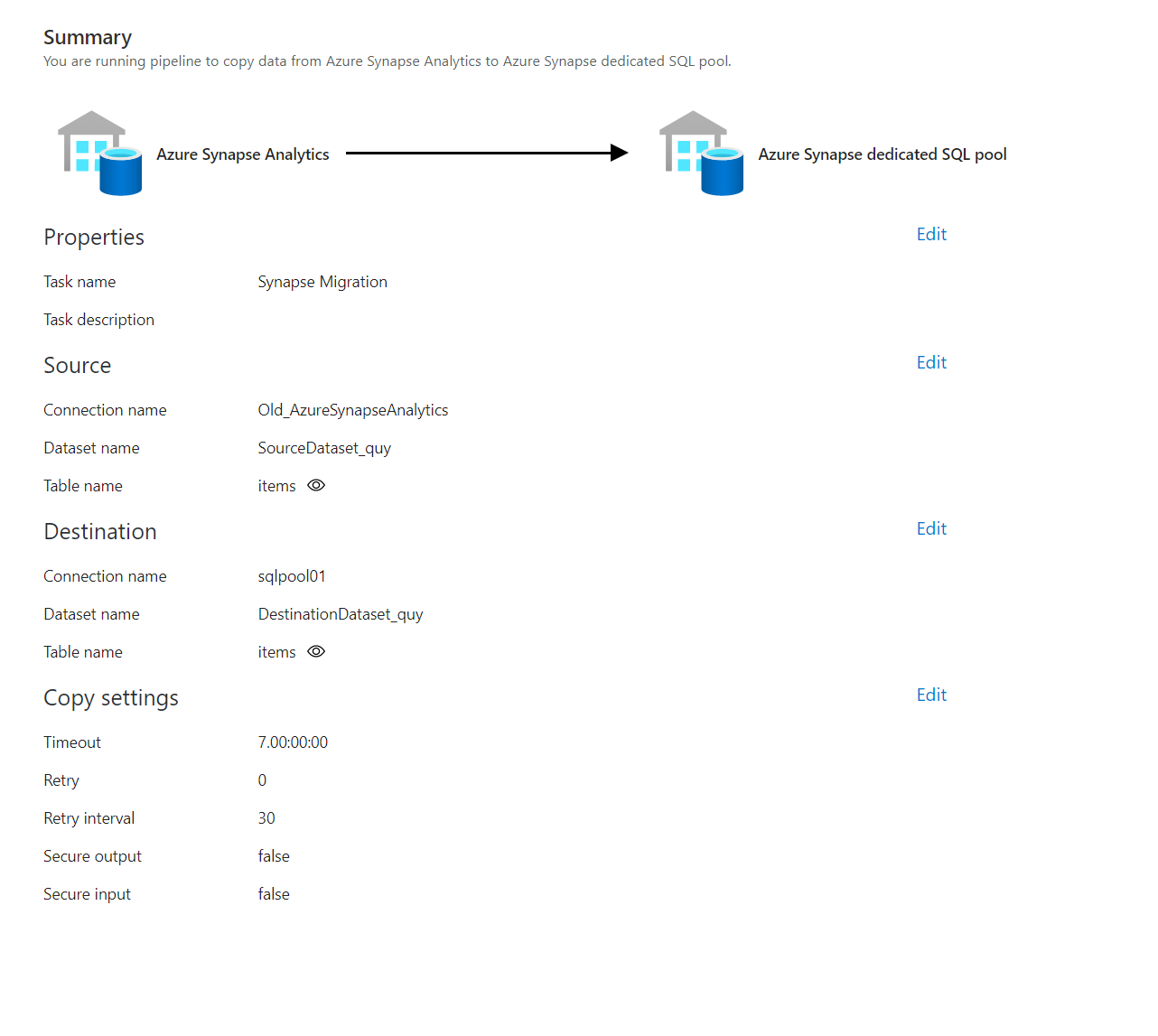
コピージョブのサマリーです。

これでパイプランが出来ました!
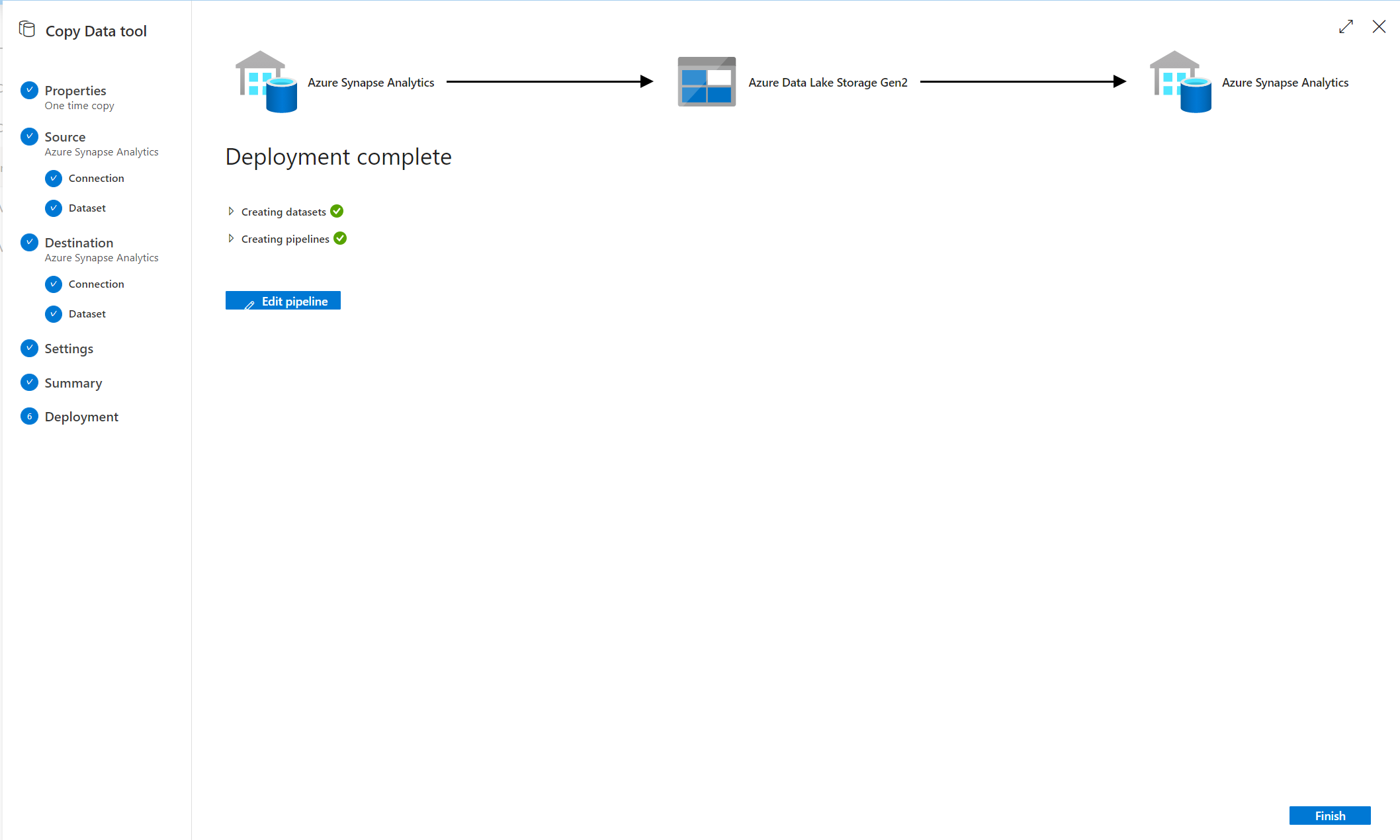
この様に!
後は、通常のPipeline ジョブとして実行します。
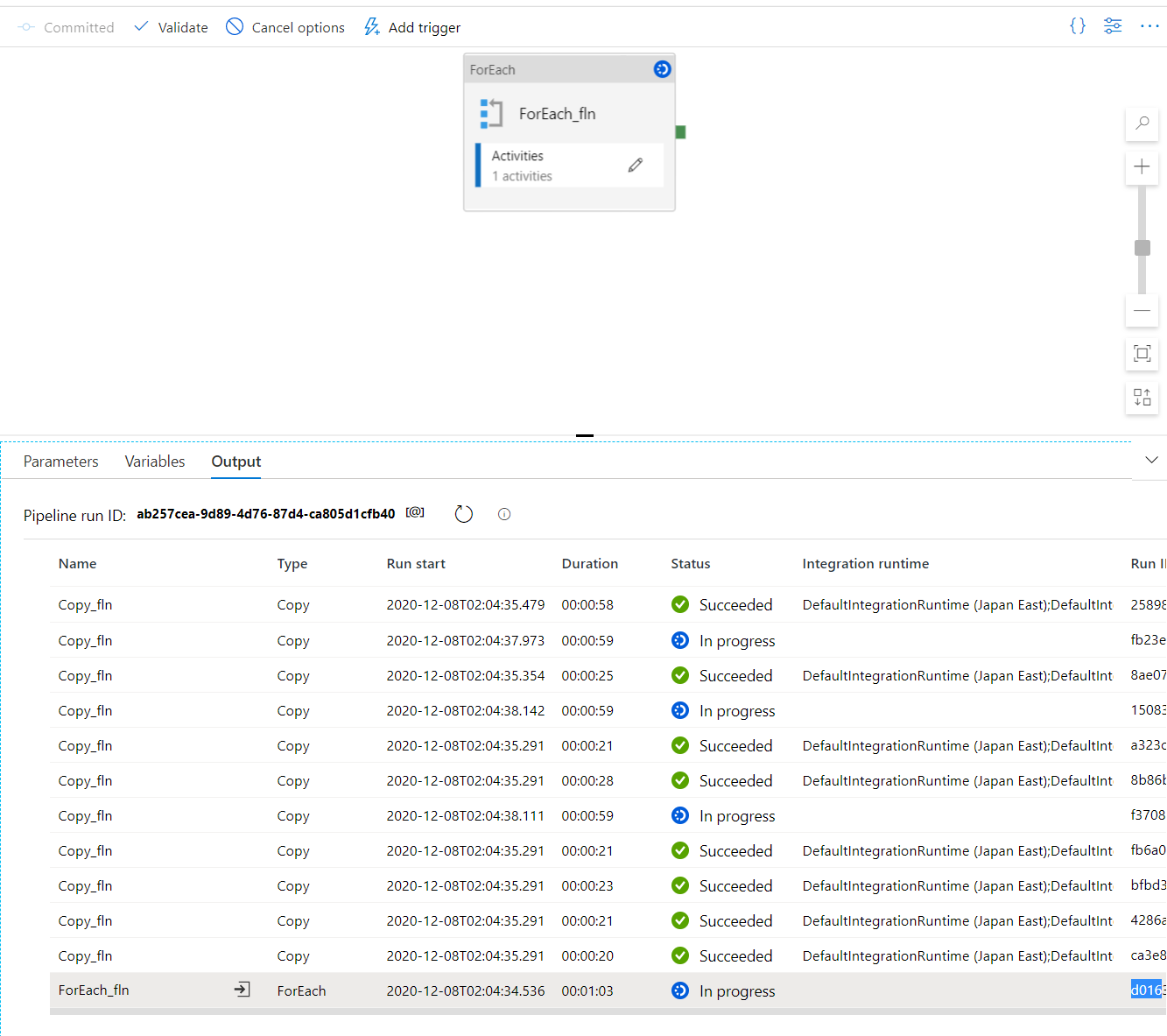
ジョブ実行中。
===========================
9. クエリのコードの修正
主にリファレンスしているサービスのものを修正していきます。
ETLを行う順番に実行をしていきます。その過程で、デバッグも、データも作成されます。
順番の管理、大事ですね。
数が少なければ、実行もできる Azure Synapse Studio で行うのが良いです。
数が多い場合は、1-2個を Azure Synapse Studio で修正、実行し、その後 Git経由で Visual Studio Code などで修正します。
特に MLやBI用のデータセットの確認 (Validation) をしているクエリの実行を確実に行います。
まとめ
Azure Synapse Analytics のデータは、コードはJSONでの定義。データは Azure Data Lake Storage Gen 2 上に存在しているため、再帰性が非常に高いです。Git技術との連携によって、複数インスタンスへの展開もやりやすくなっています。
とはいえ、その複数 Azure Synapse Analytics の管理は、それなりに「慣れ」も必要だと思います。
そして、上記を加味すると、移行ツールが比較的容易に作成できそうですね。執筆時点 (2020/12/8)では、結構手作業でしたが。
是非アーキテクチャを理解の上、Synapse を楽しんでいただければと思います。
参考:
Azure Synapse Analytics ドキュメント:
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/