はじめに
Fabric Blog の RSS フィードを取得→サマリを翻訳&サマリ内容からワークロードの分類をしてレポートにしたい
実装
メダリオンアーキテクチャにしてみます
Bronze : 生データ保存
-
feed を取得した日を記録したいので、はじめにパラメータセルで run_date を設定
pysparkrun_date = '2024-12-13'
-
feedparser で RSS フィードを取得
pyspark!pip install feedparser import feedparser # RSSフィードのURL rss_url = "https://blog.fabric.microsoft.com/en-us/blog/feed/" # フィードを解析 feed = feedparser.parse(rss_url) feed -
bronze テーブルに entry を加工せずに保存
pyspark# bronze import pyspark.sql.functions as F import json entries = [] for entry in feed.entries: # エントリ全体をJSON形式で保存 entries.append({ "entry": json.dumps(entry) # エントリ全体をJSON文字列として保持 }) df_bronze = spark.createDataFrame(entries) df_bronze = df_bronze.withColumn("run_date", F.to_date(F.lit(run_date))) # 動的パーティション上書きを設定して、読みこんだデータフレームに存在するパーティションのみ差し替え spark.conf.set('spark.sql.sources.partitionOverwriteMode','dynamic') df_bronze.write.partitionBy("run_date").mode("overwrite").saveAsTable("10_bronze_feed") display(df_bronze)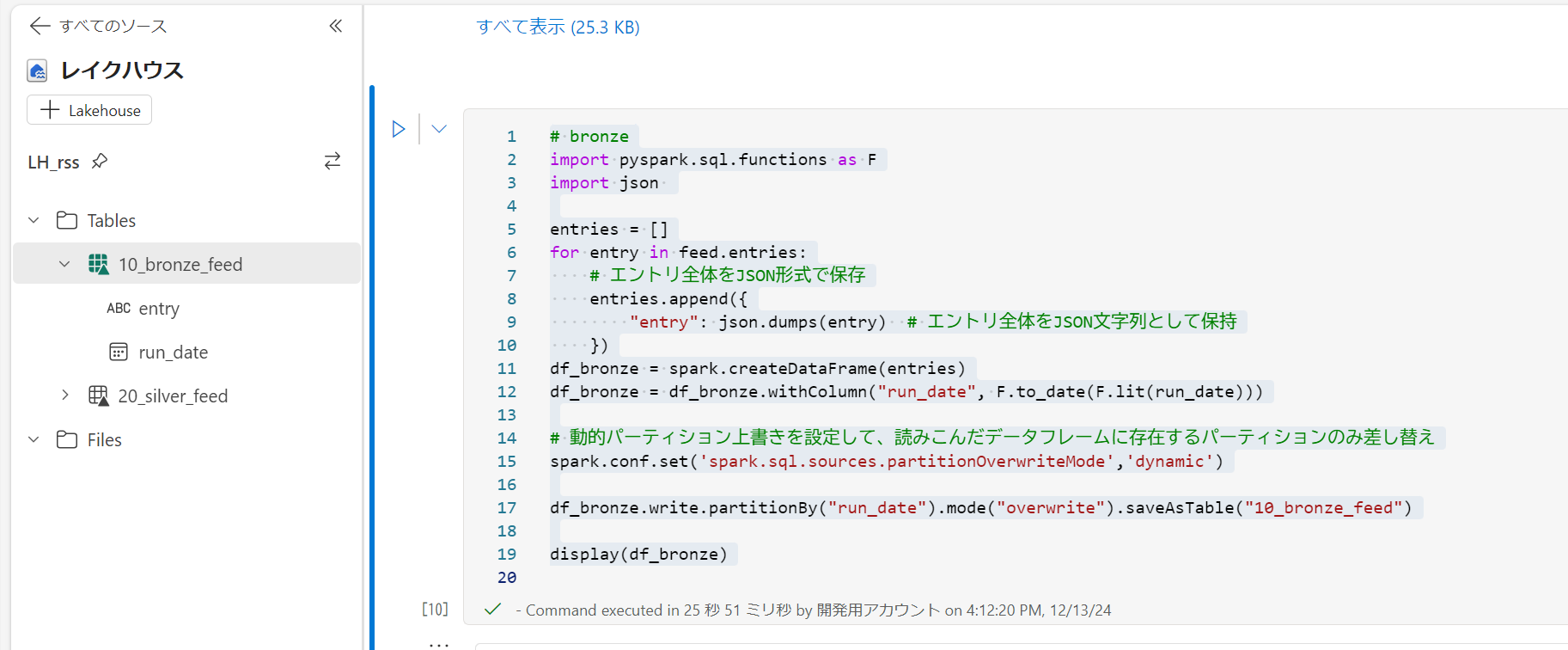
Silver : エントリーを展開して UPSERT 型で蓄積
-
エントリーを展開、データ型も整備します。
pyspark# silver from pyspark.sql.types import * json_schema = StructType([ StructField("id", StringType(), True), StructField("title", StringType(), True), StructField("link", StringType(), True), StructField("published", StringType(), True), StructField("summary", StringType(), True), ]) # JSON列を解析して必要な情報を追加 df_parsed = df.withColumn("entry_parsed", F.from_json(F.col("entry"), json_schema)) # <p> と </p> の間の内容を抽出する df_cleaned = df_parsed.withColumn( "summary", F.regexp_extract(F.col("entry_parsed.summary"), "<p>(.*?)</p>", 1) ) # extracted_summary の中の … を実際の '…' に変換する df_cleaned = df_cleaned.withColumn( "summary", F.regexp_replace(F.col("summary"), "…", "…") ) spark.conf.set("spark.sql.legacy.timeParserPolicy", "LEGACY") df_cleaned = df_cleaned.withColumn( "published", F.to_timestamp(F.col("entry_parsed.published"), "EEE, dd MMM yyyy HH:mm:ss 'Z'") ) # 必要なカラムを抽出 df_silver = df_cleaned.selectExpr( "entry_parsed.id", "entry_parsed.title", "entry_parsed.link", "published", "summary", "entry as raw_entry" ) display(df_silver) -
silver テーブルとして保存。初回のみ上書き。次回以降は MERGE で更新していきます。
pysparksilver_table_name = "20_silver_feed" table_exists = spark.sql(f"SHOW TABLES LIKE '{silver_table_name}'").count() > 0 if table_exists : print(f"MERGE") df_silver.createOrReplaceTempView("source_silver") spark.sql(f""" MERGE INTO {silver_table_name} AS target USING ( SELECT * FROM source_silver ) AS source ON target.id = source.id WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT * """) else : print(f"CREATE TABLE") df_silver.write.mode("overwrite").saveAsTable(silver_table_name)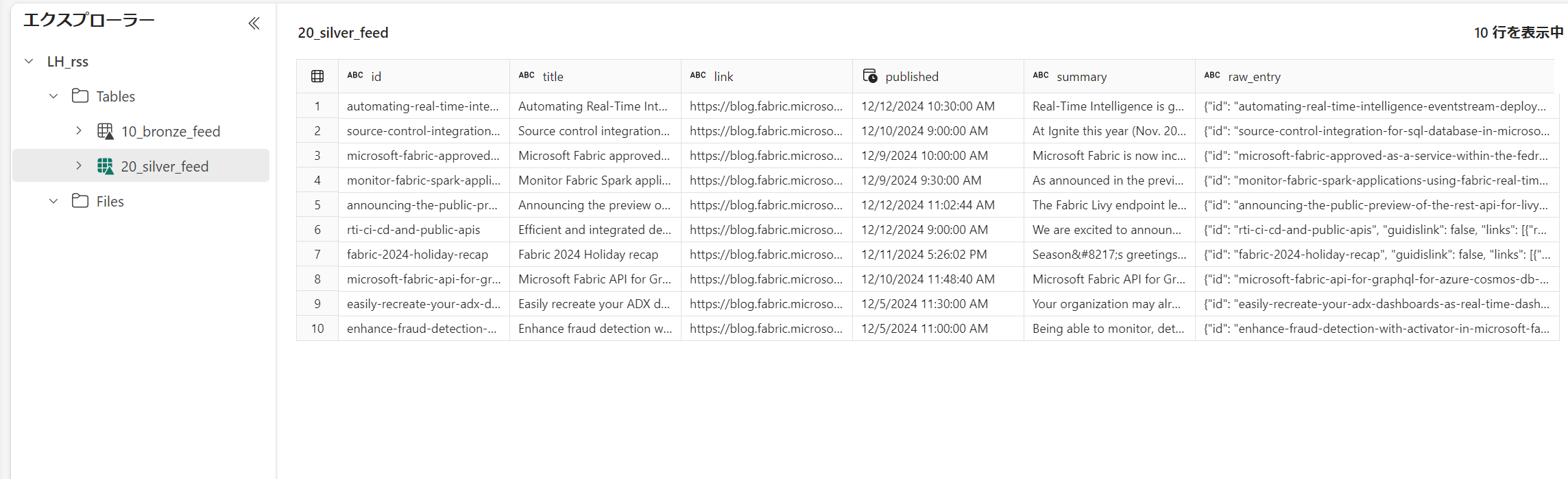
Gold : Fabric の AI 機能で翻訳と分類をしてみる
Microsoft Fabric の組み込みの AI モデルで自然言語に対する解析・分析をしてみる を発展させてみます。たぶんそのうちこんな風にしなくてもAI分類とかできます。チャレンジ。
F64 が必要になるので、 Azure Open AI などをデプロイしている場合には、Bring Your Own Key を使用する SynapseML での Azure AI サービス を参考に実装することになります。
レポート用に スタースキーマまでやるのが筋ですが、今回は フィードの蓄積と AI 処理が動機だったので割愛しました。
-
silver データ取得
pysparkdf_silver = spark.sql("SELECT * FROM LH_rss.20_silver_feed") display(df_silver)
-
AI処理は重めなので、Gold に存在しない ID を処理対象にします。
pysparkgold_table_name = "30_gold_feed" table_exists = spark.sql(f"SHOW TABLES LIKE '{gold_table_name}'").count() > 0 if table_exists: df_gold = spark.sql(f"SELECT * FROM {gold_table_name}") df_silver = df_silver.join(df_gold,(df_gold.id == df_silver.id) , "left_anti") if df_silver.count() != 0 : mssparkutils.notebook.exit("no update") -
SynapseML の Translate で翻訳
pysparkimport synapse.ml.core from synapse.ml.cognitive.translate import * from synapse.ml.services.openai import OpenAIChatCompletion from pyspark.sql import Row from pyspark.sql.types import * from pyspark.sql.functions import col, struct, array ,lit, flatten # サマリーを翻訳 translate = (Translate() .setTextCol("summary") .setToLanguage(["ja"]) .setOutputCol("translation") .setConcurrency(5)) df_translate = translate.transform(df_silver)\ .withColumn("translation", flatten(col("translation.translations")))\ .withColumn("translation", col("translation.text")[0]) display(df_translate)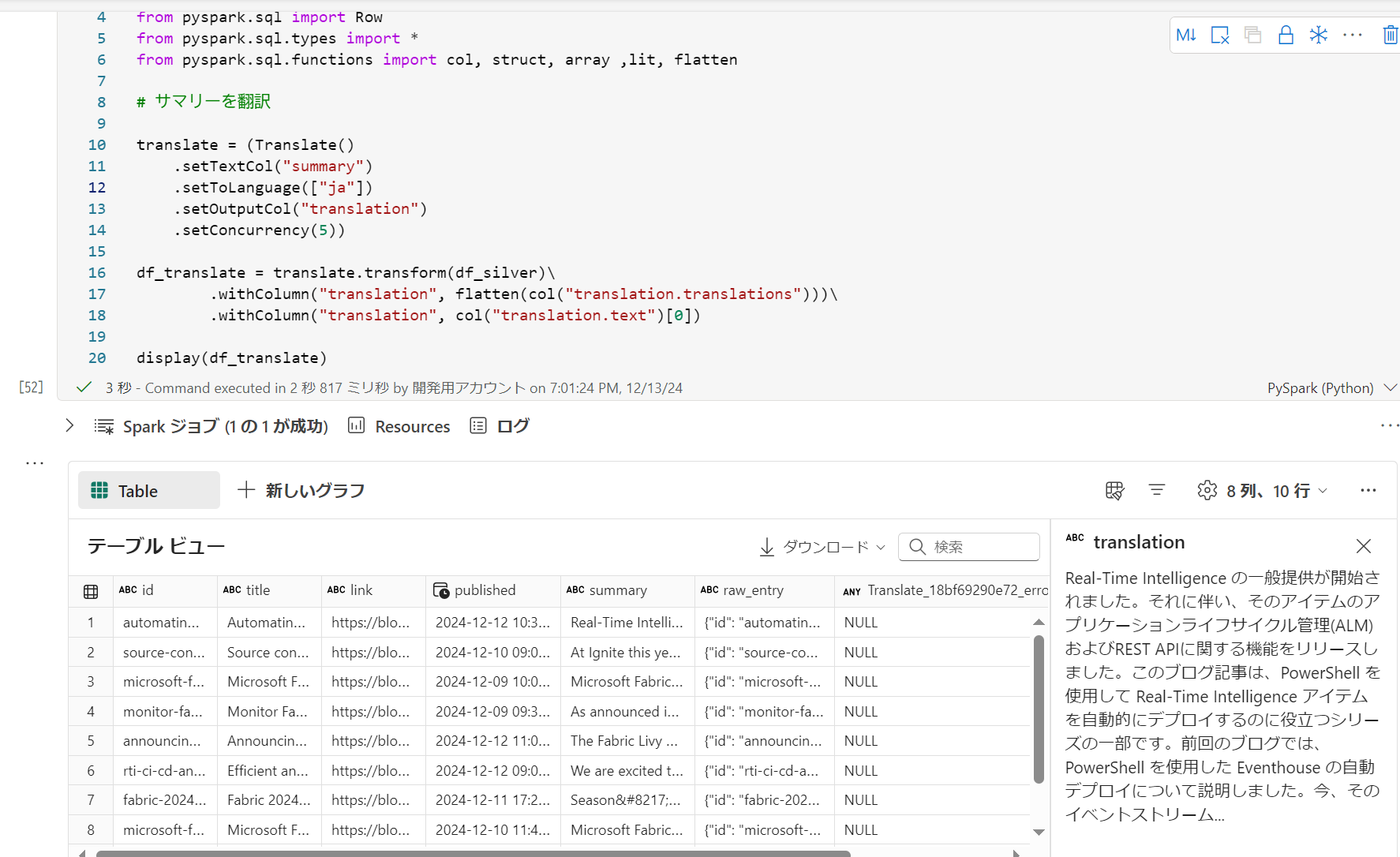
-
Chat Completion を応用して分類してみる。system_message にて、分類したいワークロードを記載してチャットでこれを聞いたというようなイメージ
pyspark# 分類 system_message= """Classify into one of the following categories. Data Factory , Data Warehouse , Data Science, Data Enginnering, Real-time Intelligence , Power BI , Other """ # Create messages column df_chat = df_translate.withColumn( "messages", array( struct(lit("system").alias("role"), lit(system_message).alias("content"),lit("system").alias("name")), struct(lit("user").alias("role"), col("summary").alias("content"),lit("user").alias("name")) ) ) # Define the OpenAIChatCompletion transformation chat_completion = ( OpenAIChatCompletion() .setDeploymentName("gpt-35-turbo-0125") # deploymentName could be one of {gpt-35-turbo-0125 or gpt-4-32k} .setMessagesCol("messages") .setErrorCol("error") .setOutputCol("chat_completions") ) # Apply the transformation to the summary DataFrame df_gold = chat_completion.transform(df_chat)\ .select("id","title","link", "published","translation", col("chat_completions.choices.message.content")[0].alias("workload")) display(df_gold)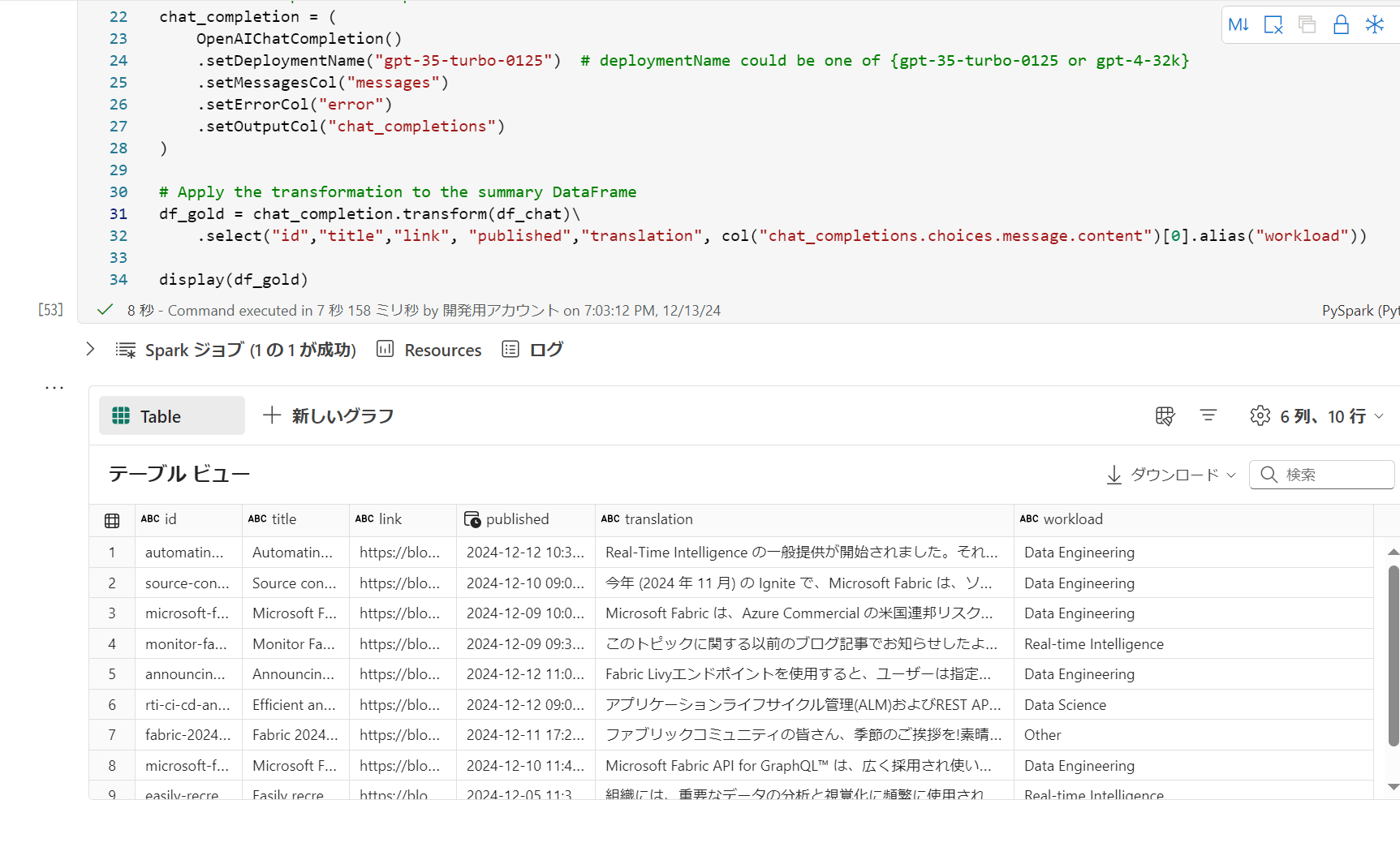
分類できた感じがします。 -
保存。
gold テーブルに存在しないレコードで処理しているので Append で。pysparkdf_gold.write.mode("append").saveAsTable(gold_table_name)
レポート
スタースキーマもなにもないテーブルですが、リンクで飛べるようにデータモデルの設定をしてから可視化します。
- リンクで飛べるようにモデルを修正
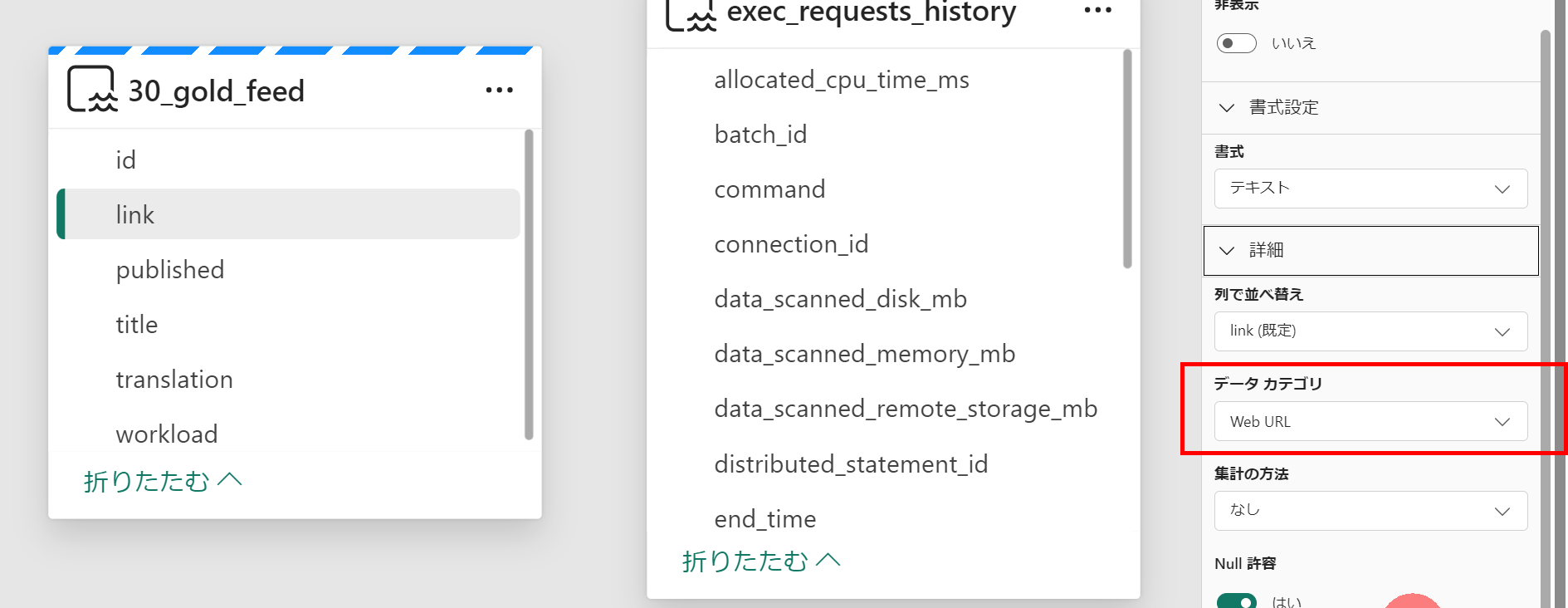
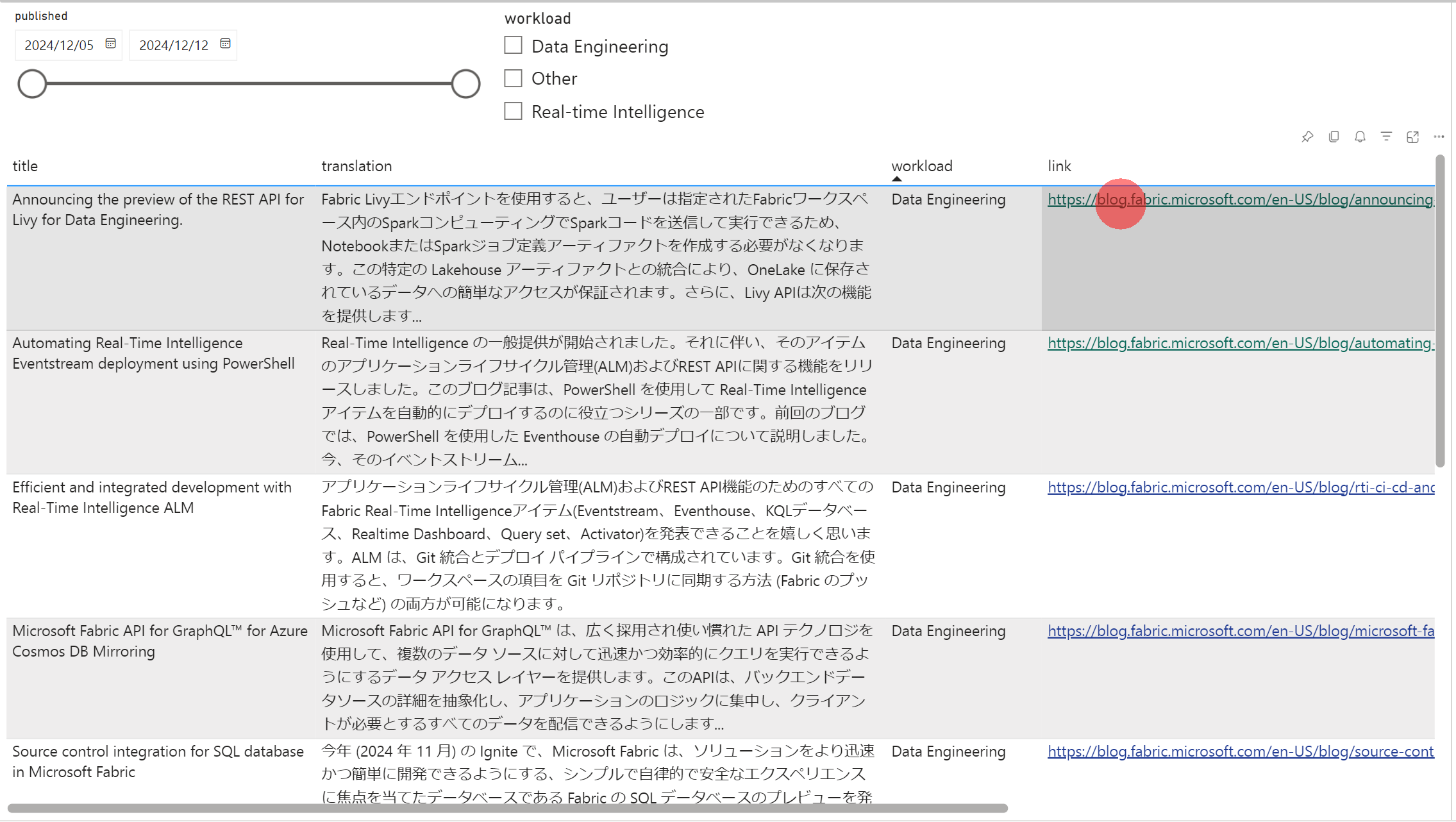
- レポート完成
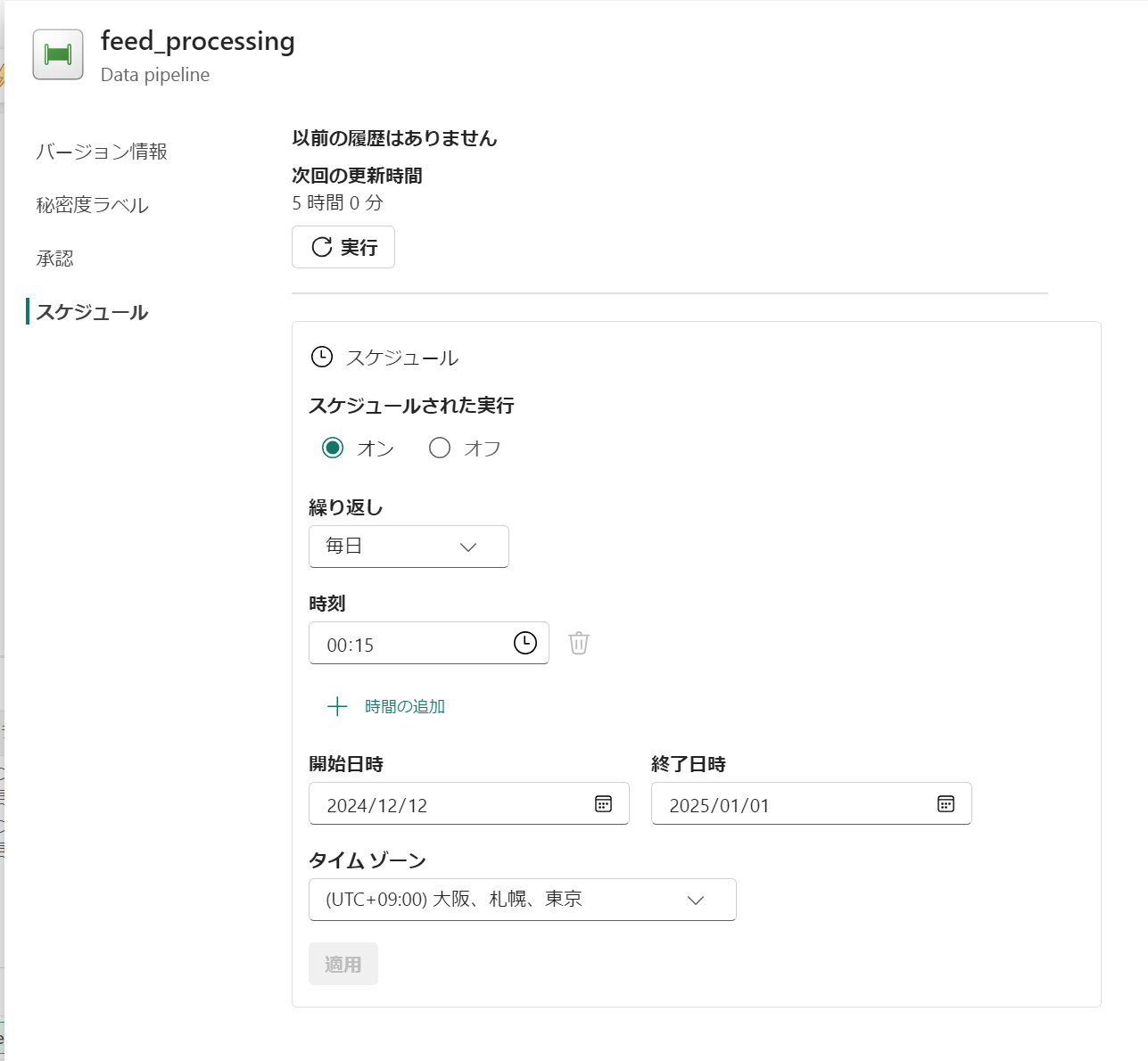
ジョブ化
-
ジョブ化する場合には、 ノートブックセッションでの !pip install は使えないので、環境を作成してライブラリを仕込みます。
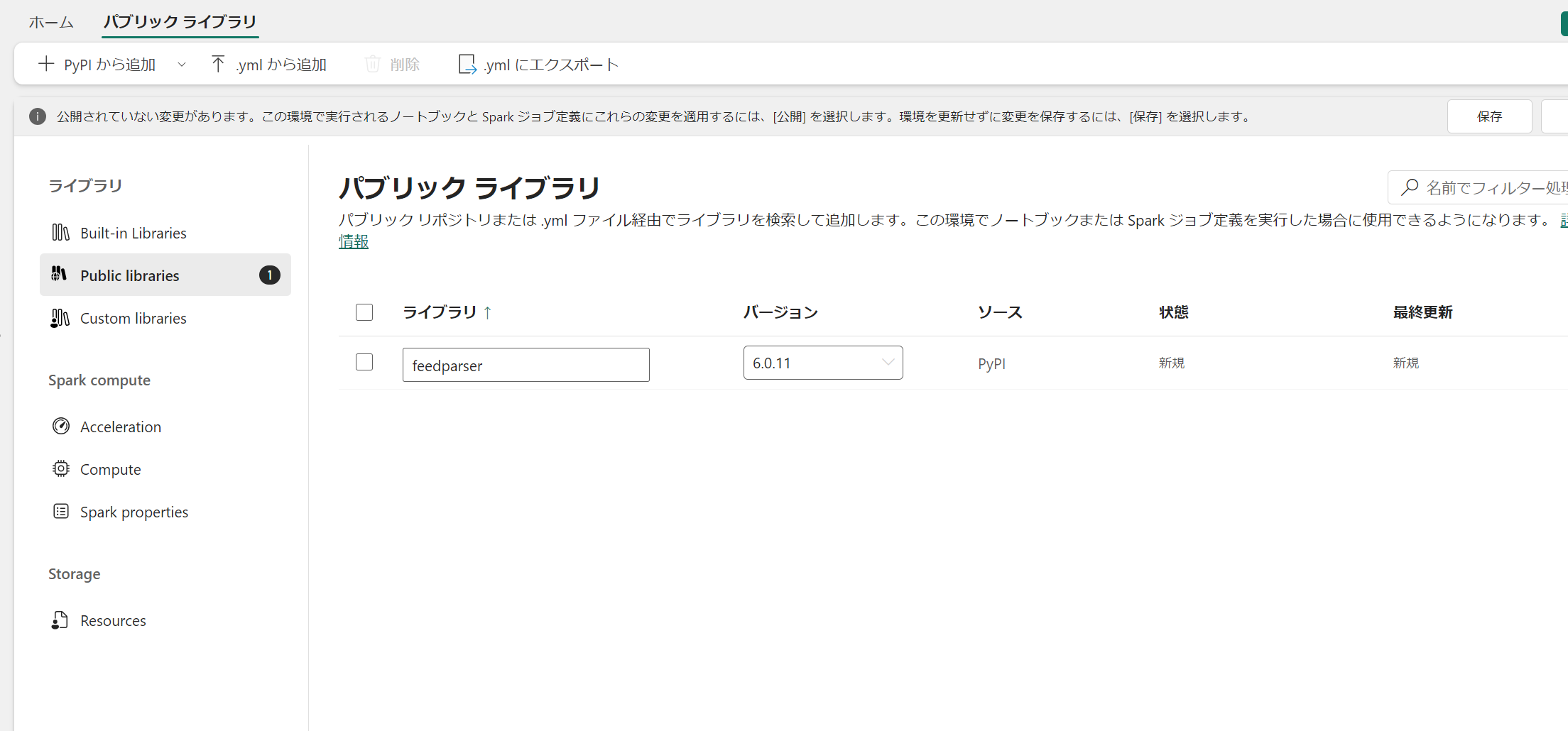
-
ノートブックからは install を削除して、環境を設定
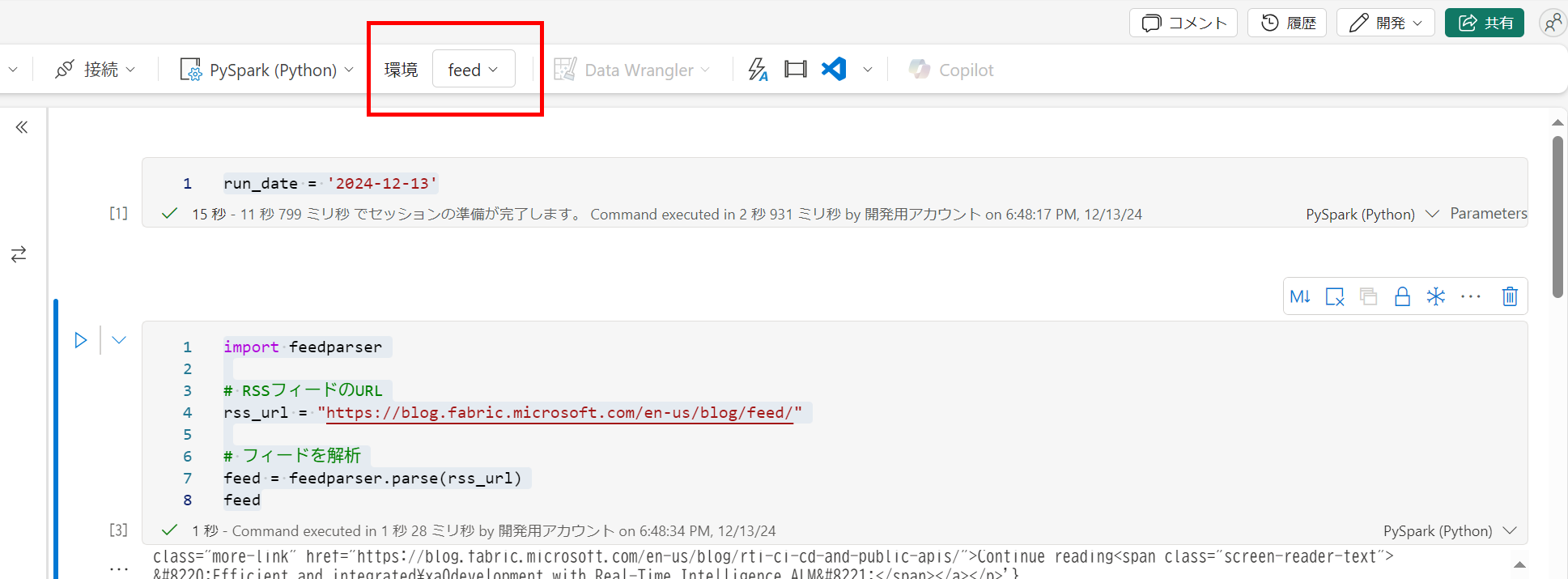
-
パイプラインでノートブックを呼び出すようにします。
-
run_date を設定できるようにします。
formatDateTime(convertFromUtc(utcnow(),'Tokyo Standard Time'),'yyyy-MM-dd')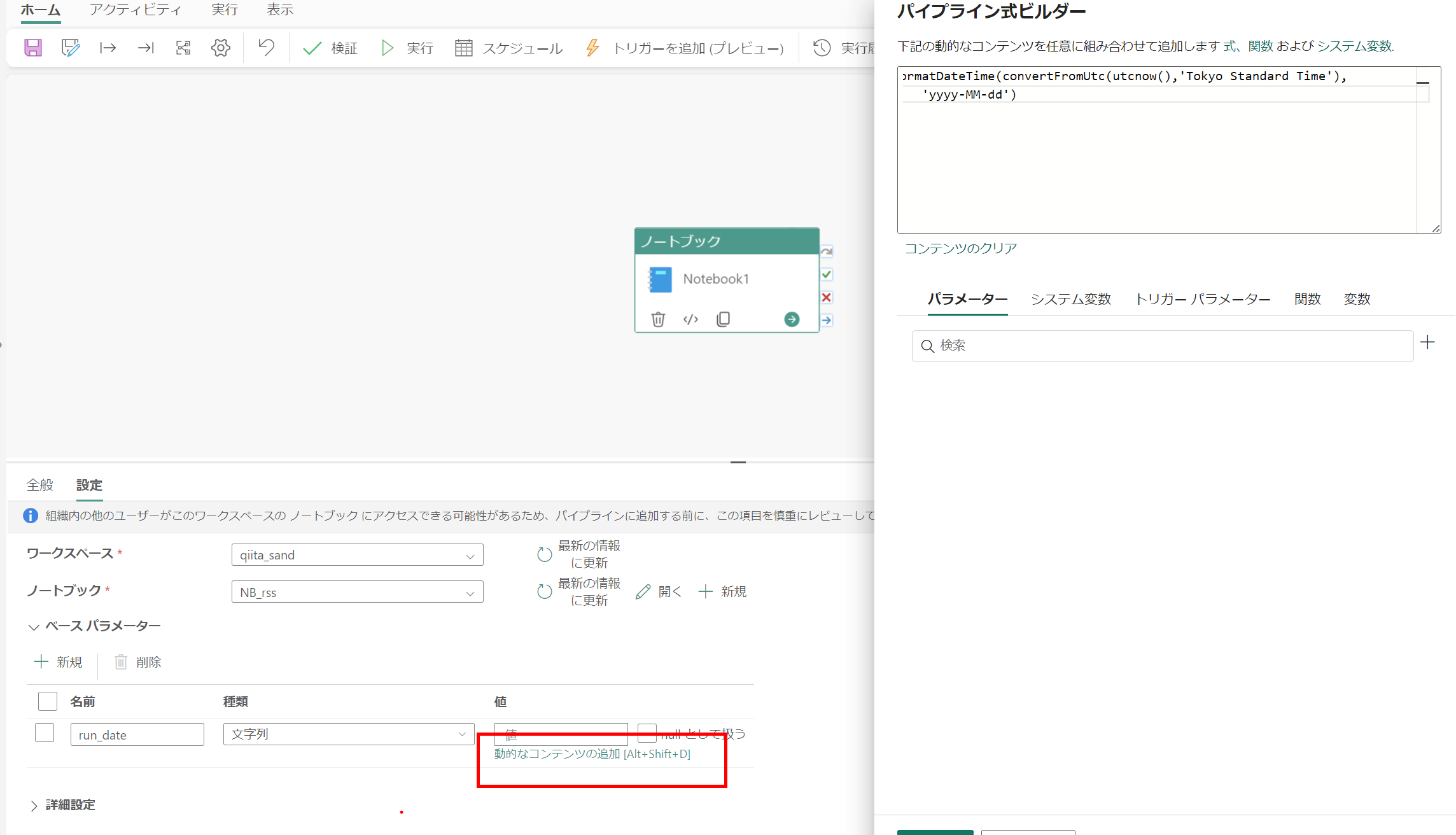
-
スケジュール設定をしたら完成