本記事の目的
Azure Databricksで学習済のword2vecを使った処理を実行したい。
これまでローカル環境でPythonからword2vecを使っていたが、コピペで動くかと思いきや意外とハマったので書き残しておく。
先に結論を書くと、
・学習済モデルをアップロードしたBLOBをdatabricksにマウントしてloadすればよい
・loadするときにwith openコマンドを使わないと「ファイルが見つからない」エラーが出るので注意
word2vec概要
word2vecで単語の類似度を数学的に扱える
その名の通り、単語をベクトルに変換する。自然言語処理をするのであれば必須の超重要技術。
単語というただの文字列を、数学的に扱えるようにするためにベクトルに置換する。
「ごはん」「機械学習」「ディープラーニング」
↓ ↓ ↓
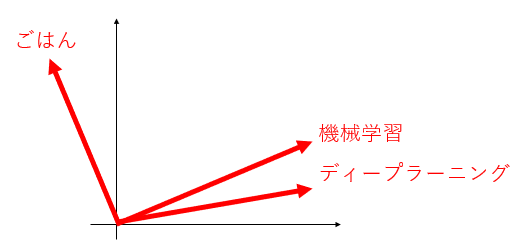
これによって、空間上の距離として単語間の類似度を数学的に計算することができる。
「機械学習」という単語と「ディープラーニング」という単語の意味は近い、ということが数学的に定義できる。
自分で学習させるのは大変
word2vecのベースとなる前提は「単語の意味は周囲の単語によって形成される」という考え方。
これを「分布仮説」という。
平たく言えば、単語の意味はその周辺の単語を見れば推測できるだろう、ということ。
例えば、以下のような文があったとする。
・人工知能の実現のためには【機械学習】の技術が欠かせない。
もし【機械学習】という単語が未知だったとしても、これが人工知能に関係がある技術であろうことが推測される。
同様に、以下のような文もあるかもしれない。
・【ディープラーニング】という技術は、人工知能の研究を飛躍的に加速させた。
このように大量の文を学習していけば、未知語に対してもその意味を予測できるようになる。
同じような単語が周辺に出現する【機械学習】と【ディープラーニング】はどうやら意味的に近そうだ、ということも分かる。
ただしこれらの学習には大量のドキュメントを読ませる必要があり、学習のコストが高い。
したがってまずは学習済のモデルを使うのが基本になる。
Azure Databricksでword2vecを使う手順
<前準備>
- Azure Databricksのリソースを作成
- Storage Accountでコンテナを作成
- 学習済モデルをダウンロードしてコンテナに格納する
<実行>
- Azure databricks上でコンテナをマウントする
- gensimでモデルを読み込ませる
- word2vecを実行する
前準備
1. Azure Databricksのリソースを作成
特段気を付けることはない。普通にazure portalから作成すればよい。
2. Storage Accountでコンテナを作成
これも特に気を付けることはない。コンテナまで作成しておく。パブリックアクセスレベルはプライベートでよい。
3. 学習済モデルをダウンロードしてコンテナに格納する
以下の記事を参考に、学習済モデルをダウンロードする。(ちなみにfastTextを使った)
いますぐ使える単語埋め込みベクトルのリスト
https://qiita.com/Hironsan/items/8f7d35f0a36e0f99752c
ダウンロードした「model.vec」ファイルを作成済のコンテナにアップロードしておく。
実行
ここからはDatabricksのノートブック上の操作。
1. Azure databricks上でコンテナをマウントする
この記事がとても分かりやすかった。
Blobに入ってるデータをクエリで分析しよう!
https://tech-blog.cloud-config.jp/2020-04-30-databricks-for-ml/
mount_name= "(任意のマウント先ディレクトリ名)"
storage_account_name = "(ストレージアカウント名)"
container_name = "(コンテナー名)"
storage_account_access_key = "(ストレージアカウントアクセスキー)"
mount_point = "/mnt/" + mount_name
source = "wasbs://" + container_name + "@" + storage_account_name + ".blob.core.windows.net"
conf_key = "fs.azure.account.key." + storage_account_name + ".blob.core.windows.net"
mounted = dbutils.fs.mount(
source=source,
mount_point = mount_point,
extra_configs = {conf_key: storage_account_access_key}
)
2. gensimでモデルを読み込ませる
※ gensimを利用するため、事前にクラスタでPyPIでインストールをしておく。
import gensim
word2vec_model = gensim.models.KeyedVectors.load_word2vec_format("mount_name/container_name/model.vec", binary=False)
上記で実行すると、なぜかエラー。マウントはちゃんとできているのになぜ。
(ちなみにローカルだとこれでちゃんと動く。)
FileNotFoundError: [Errno 2] No such file or directory:
ということで、以下のようにwith openコマンドを使って、一度f_readで受けてからloadする。
import gensim
with open("mount_name/container_name/model.vec", "r") as f_read:
word2vec_model = gensim.models.KeyedVectors.load_word2vec_format(f_read, binary=False)
Databricks ファイル システム (DBFS) - ローカルファイル api
https://docs.microsoft.com/ja-jp/azure/databricks/data/databricks-file-system#local-file-apis
今度は成功。
3. word2vecを実行する
試しに実行。「日本人」と最も近い単語を出してみる。
word2vec_model.most_similar(positive=['日本人'])
Out[3]: [('中国人', 0.7151615619659424),
('日系', 0.5991291999816895),
('外国', 0.5666396617889404),
('邦人', 0.5619238018989563),
('コリアン', 0.5443094968795776),
('華僑', 0.5377858877182007),
('在日', 0.5263140201568604),
('華人', 0.5200497508049011),
('在留', 0.5198684930801392),
('留学生', 0.5194666981697083)]