はじめに
今回はQiitaに投稿された複数ユーザーの記事情報(View数等)を取得します。
Qiitaの記事情報(View数等)は各ユーザーのアカウントで確認することはできますが、複数ユーザー分のView数等を取得するとなると人数が増える分だけ手間になりますよね。
そこで、HULFT Squareを利用しREST接続や繰り返し(ループ)処理を用いて複数ユーザーの記事情報をCSVファイルに書き込み、一覧で確認できるスクリプトを作成していきます!
<Qiitaの設定>
①Qiita APIの確認
Qiita APIの公式ドキュメント](https://qiita.com/api/v2/docs)
使用するAPI:認証中のユーザーの記事の一覧を作成日時の降順で返してくれるAPI
GET /api/v2/authenticated_user/items
②Qiitaでアクセストークンを取得する
今回やること
<HULFT Squareの設定>
- ストレージの準備
- コネクションの設定
- プロジェクトの作成
HULFT Squareの設定
1.ストレージの準備
今回はHULFT Squareのストレージの所定ディレクトリーにView数の取得結果ファイルを保存していきます。
「ストレージ」から「新しいディレクトリー」をクリック。
指定のワークスペース/Qiita/Outputの階層のディレクトリを作成します。


2.コネクションの設定
HULLFT SquareからQiita APIへの接続設定である「コネクション」を作成していきます。
「HULFT INTEGRATE」-「コネクション」から「新規追加」をクリック。

「コネクター」-「REST」、「種類」-「REST接続」を選択し「次へ」をクリック。
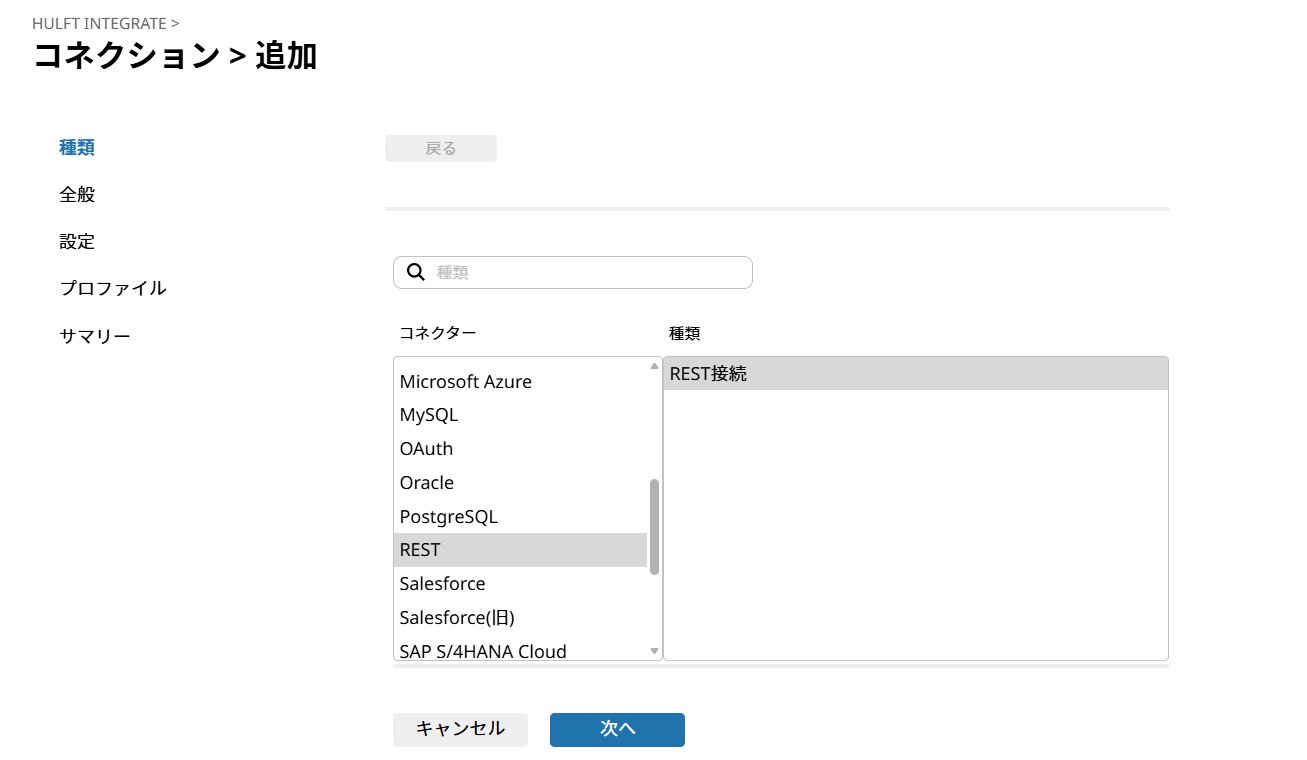
「名前」はREST接続_Qiitaとし「次へ」をクリック。
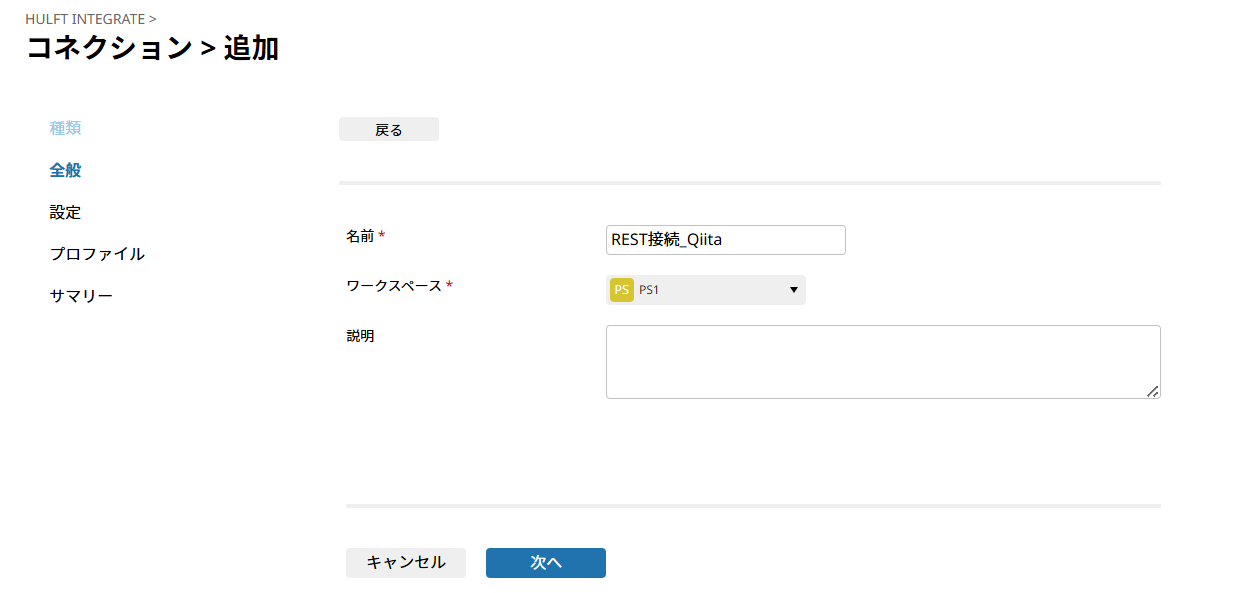
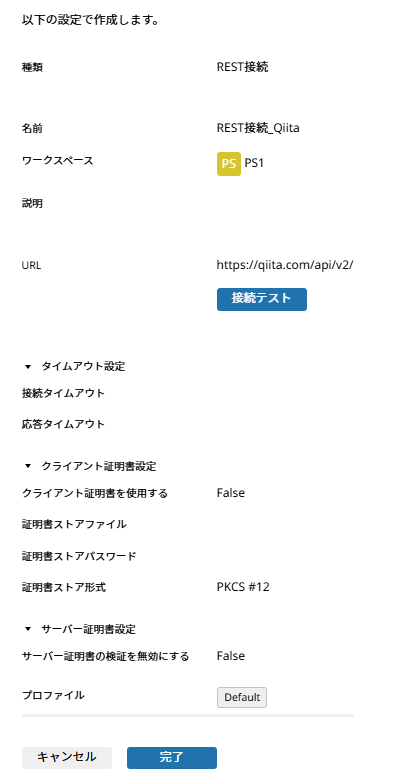
「URL」にhttps://qiita.com/api/v2/を設定し、「接続テスト」をクリック。
「接続テスト」の成功を確認後、「OK」をクリックし、「次」へをクリック。

Qiita APIに接続するためのURL(エンドポイント)となります。使用するAPIに応じて、ここで設定した「URL」の後に続く部分を設定し、最終的なWeb APIのエンドポイントを設定します。
「接続テスト」はHULFT Squareからの接続ができるかどうかを確認するため実施しましょう。
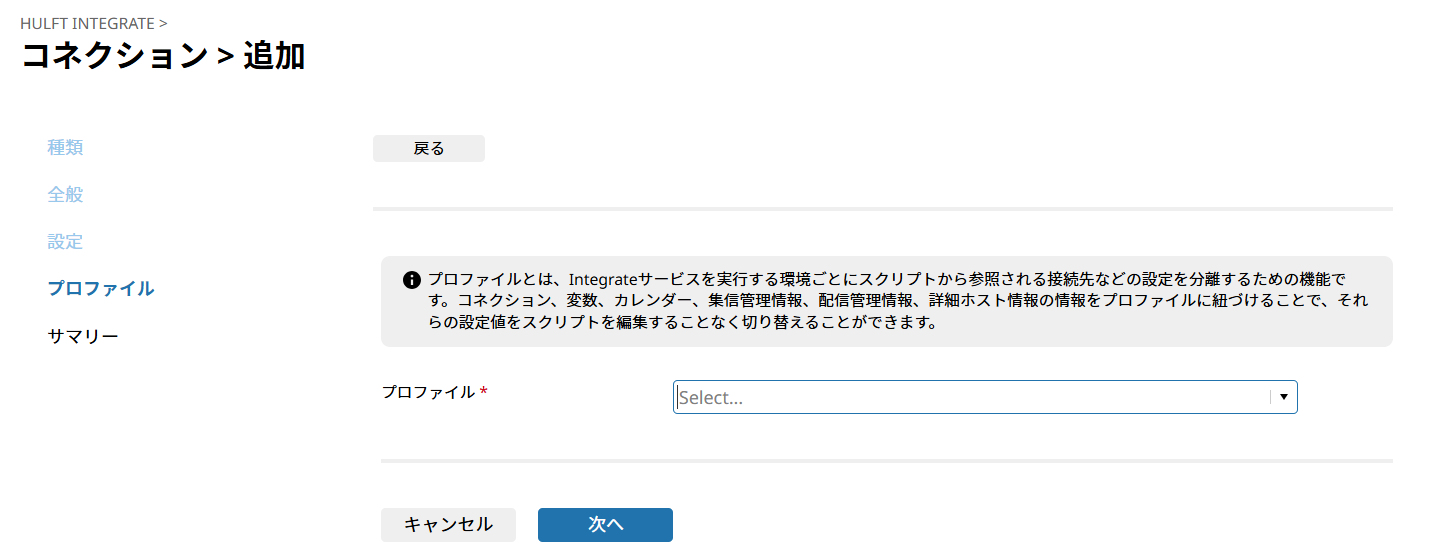
プロファイルは実行環境を定義する設定です。「開発用」「本番用」等適切な実行環境に紐付けるプロファイルを選択する必要があります。
3.プロジェクトの作成
1. 複数の執筆者のユーザー情報の読み取り処理(名前、URL、アクセストークン)
まず、複数ユーザーのアカウント情報を読み取るためにExcelシートを読み取ります。
「ファイル」>「Excel」>「シートから読み取り処理」をドラッグ&ドロップで配置し、
・名前 : アカウント情報読み取り
・ファイル名 : /設定した入力元のディレクトリー/Qiitaアカウント台帳.xlsx
を入力します。
※読み取るExcelファイルは事前にストレージにアップロードしておく必要があります。
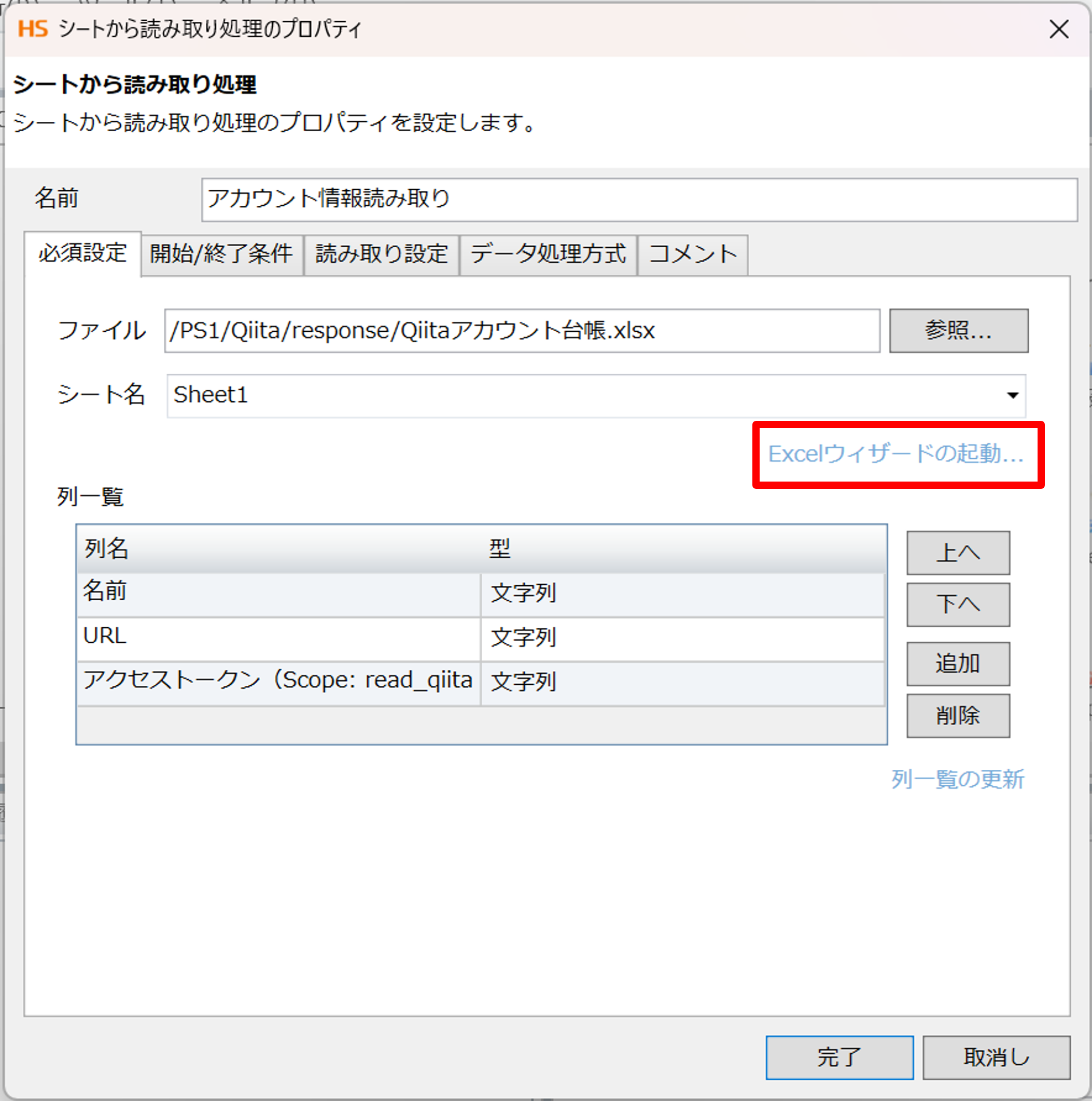
そして、Excelウィザードの起動を行い、読み取り範囲を設定します。
※ここでは列名は選択せず、読み取るデータのみを選択するようにしてください。
範囲選択した後、OKを押します。

続きまして、このような画面が出てきます。
ここでは「列名の取得」を行います。
列名の取得から範囲を選択すると、列一覧に列名が入力されます。

以上でアカウント情報のExcel読み取りは完了です。
2. GET実行処理の設定
次に、RESTでQiitaの記事情報をGETするために「ネットワーク」>「REST」>「GET実行」をドラッグ&ドロップで配置します。
まずは、必須設定タブの設定をします。
先のセクションで作成したQiita接続用のコネクションであるREST接続_Qiitaを設定しましょう。「パス」には、使いたいAPIのエンドポイントの残りの部分である/atuthenticated_user/itemsを設定します。
<クエリパラメータ>
Qiita APIに記載がある通り、GET /api/v2/authenticated_user/items では、パラメータ設定が可能です。pageとper_pageの概念理解で他の方の記事やらも確認しましたが、1pageに100要素(=記事)を取得できるようで、私の設定だと1×100で、100記事分の情報が取得できそうです。
つまり最大設定値である100を両者に設定すると、100×100=10000記事取得できる、ということですね。
・page : 1
・per_page : 100

次は、レスポンス設定タブを設定します。下記の通り入力します。
・データ出力先 : JSON
・XMLとして不正な文字を削除する : ✓
・自動でリダイレクトする : ✓
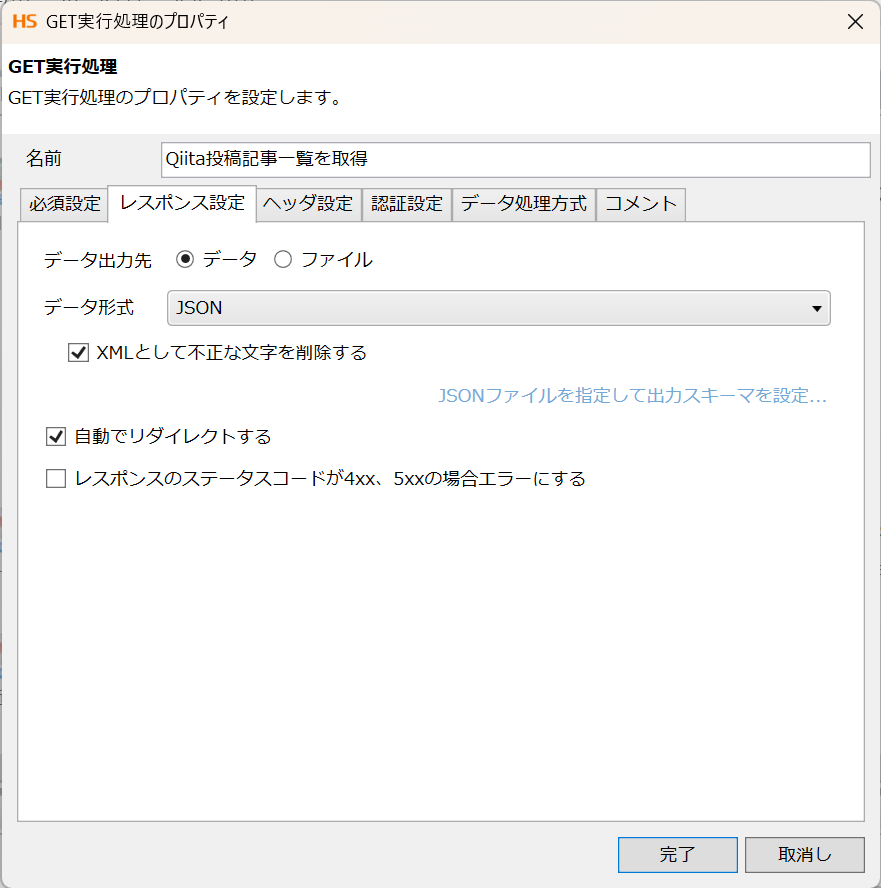
更に、「JSONファイルを指定して出力スキーマを設定」のリンクを押下して、レスポンスとして受け取るJSONファイル定義を指定します。

★レスポンス指定するJSONファイルの準備について★
下記2つのいずれかの方法で、私はJSONファイルを用意しています。
①使いたいAPI自体をCurlコマンドで事前に実行してみて、JSONファイルを作成。
②公式APIドキュメントに記載されたJSONファイルの例をコピーしてJSONファイルを手動作成。
今回は②で作成したファイルを指定しました。
[
{
"rendered_body": "<h1>Example</h1>",
"body": "# Example",
"coediting": false,
"comments_count": 100,
"created_at": "2000-01-01T00:00:00+00:00",
"group": {
"created_at": "2000-01-01T00:00:00+00:00",
"description": "This group is for developers.",
"name": "Dev",
"private": false,
"updated_at": "2000-01-01T00:00:00+00:00",
"url_name": "dev"
},
"id": "c686397e4a0f4f11683d",
"likes_count": 100,
"private": false,
"reactions_count": 100,
"stocks_count": 100,
"tags": [
{
"name": "Ruby",
"versions": [
"0.0.1"
]
}
],
"title": "Example title",
"updated_at": "2000-01-01T00:00:00+00:00",
"url": "https://qiita.com/Qiita/items/c686397e4a0f4f11683d",
"user": {
"description": "Hello, world.",
"facebook_id": "qiita",
"followees_count": 100,
"followers_count": 200,
"github_login_name": "qiitan",
"id": "qiita",
"items_count": 300,
"linkedin_id": "qiita",
"location": "Tokyo, Japan",
"name": "Qiita キータ",
"organization": "Qiita Inc.",
"permanent_id": 1,
"profile_image_url": "https://s3-ap-northeast-1.amazonaws.com/qiita-image-store/0/88/ccf90b557a406157dbb9d2d7e543dae384dbb561/large.png?1575443439",
"team_only": false,
"twitter_screen_name": "qiita",
"website_url": "https://qiita.com"
},
"page_views_count": 100,
"team_membership": {
"name": "Qiita キータ"
},
"organization_url_name": "qiita-inc",
"slide": false
}
]
次に、ヘッダ設定タブの設定です。下記の通り、設定します。
・名前 : Content-Type ・値 : application/json
・名前 : Authorization ・値 : Bearer XXX(Qiita管理画面から発行したアクセストークン)
※通常は1人分のアクセストークンのみ必要であるが、今回は複数人の記事情報を取得したいのでアクセストークンをスクリプト変数アクセストークンを作成し、設定しています。
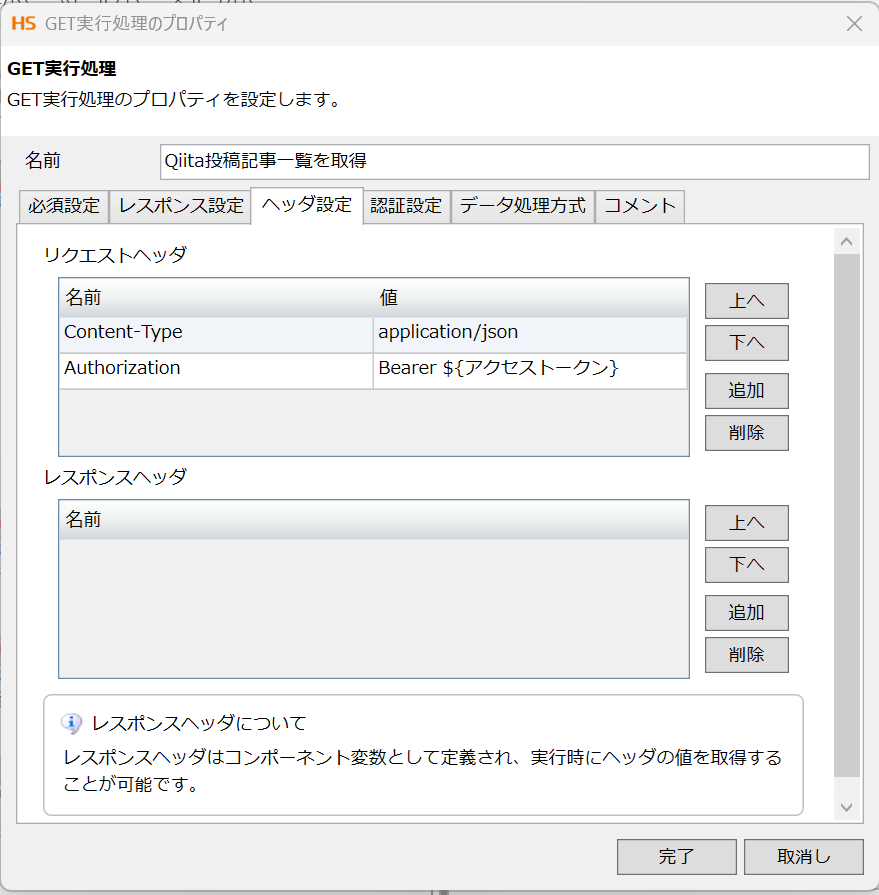
以上で、GET実行の設定は完了です。
3. マッピングの設定(入力元の確認)
デザイナ画面右側にある「ツールパレット」から「変換」>「基本」>「マッピング」をデザイナ中央部分にドラッグ&ドロップします。
処理アイコンをただ並べた状態だと下記のような状態です。
各処理アイコンを線でつなぎ、データと処理フローを作成しましょう。
「GET実行」アイコンをmappingアイコンにドラッグ&ドロップすると、下記のポップアップが表示されます。
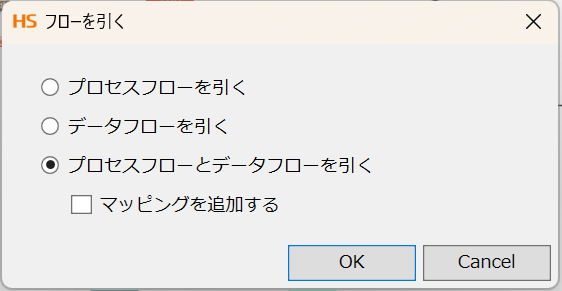
「プロセスフローとデータフローを引く」に✓してOKを押下すると、

処理アイコンがつながりました。mappingアイコンをダブルクリックしてみましょう。
「入力元」の赤枠部分にJSON定義が作成されていることがわかります。

JSONファイルとして取得した記事情報の中のそれぞれの項目については、Qiita APIドキュメントに記載があるので、ここから必要な情報を選択して、右側の「出力先」に渡す設定をしていきます。
4. CSVファイルの書き込み処理の設定
APIで取得した記事情報の中から必要な項目を選択して、CSVファイルを作成します。
デザイナ画面右側のツールパレットから「ファイル」>「CSV」>「CSVファイル書き込み」アイコンをデザイナ中央にドラッグ&ドロップします。
そして、マッピングアイコンからフローをつなぎます。

まずは、必須設定タブです。下記の通りに設定します。
・名前 : 記事情報をCSVに出力
・入力データ : mapping
・ファイル : /設定した出力先のディレクトリー/${集計年月}_Qiita記事.csv
<列一覧>
「追加」を押下して、「列名」に出力したい必要項目の定義をします。今回は下記の8項目を出力してみます。
・記事URL
・作成年月日
・執筆者
・記事タイトル
・View数
・いいね数
・ストック数
・タグ

ファイル名に、「集計年月」と「記事件数」を付与するために、「集計年月」と「記事件数」というスクリプト変数を作成しておきます。スクリプト変数への値の設定は、次のmapping設定(出力先の設定)の中でします。
スクリプト変数を使って、ファイル名に「処理日時」や「データ件数」などを付与できます。スクリプト変数は、あらかじめ必要なものを作成しておきます。
次に、書き込み設定タブです。
「上書き」と「1行目に列名を挿入」に✓を入れます。
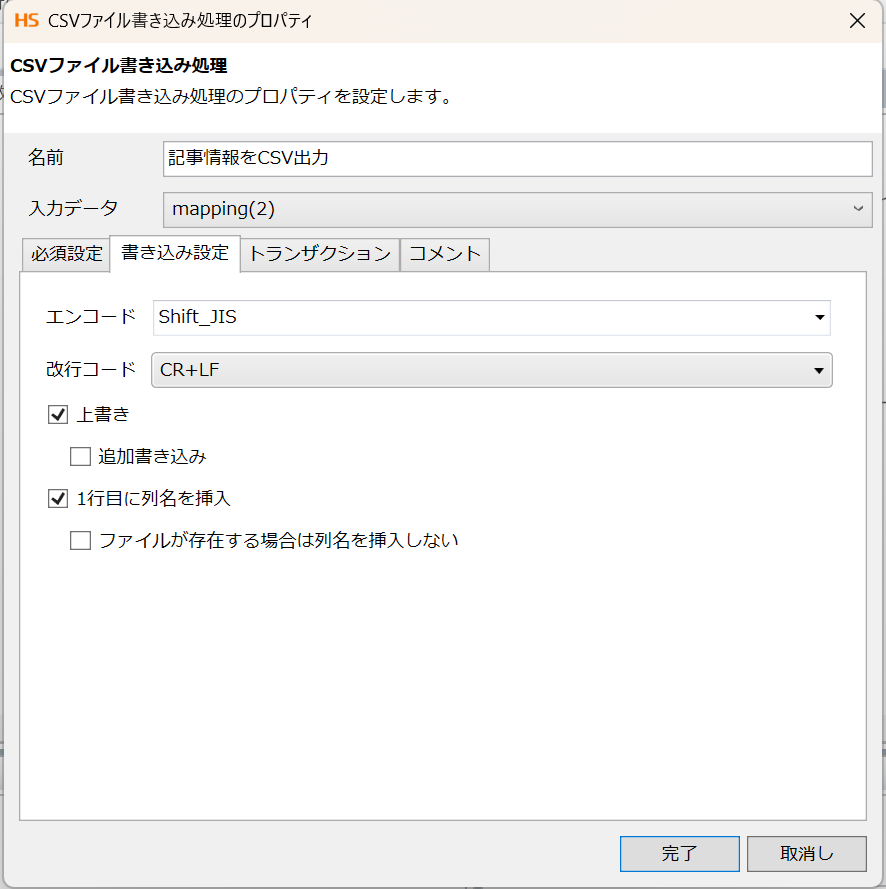
以上で、CSV書き込みの設定は完了です。
5. マッピングの設定(出力先の設定)
今回のマッピング設定は下記の通りです。
(細かい!ように見えますが、基本的なアイコンなど簡単な設定のみです。)

まずは、取得した記事情報の分だけ、処理を読み取り書き込む繰り返しの処理を行う設定です。
ツールパレットの「繰り返し」>「基本」>「単純な繰り返し」アイコンを中央にドラッグ&ドロップします。入力元の「element」と出力先の「row」を線でつなぎ、"入力データ件数分"書き込み処理を繰り返す設定をします。

次に、それぞれの出力先の項目への設定をみていきましょう。
■集計年月日
いつ集計された記事情報なのかを認識するために、集計時の年月日を出力します。
そこで、スクリプト変数「集計年月日」に、現在日時値を設定したいと思います。
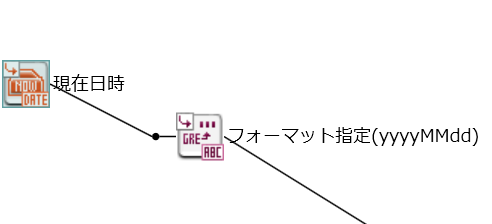
ツールパレットの「日付」>「基本」>「現在日時」アイコンと「文字列」>「日付」>「日時フォーマッティング」アイコンに繋げます。
日次フォーマティングには年月日を指定したいので、「yyyyMMdd」を入力します。

最後に、スクリプト変数「集計年月日」に線をつないで完了です。

■作成年月日
記事を作成した日時情報「created_at」を出力先のスクリプト変数「作成年月日」につなげます。Qiita APIドキュメントの記載例に「Example: "2000-01-01T00:00:00+00:00"」と書いてあったので、「先頭10文字yyyy-MM-dd」を使います。ツールパレットから「文字列」>「関数」>「左文字列」で「10」を指定します。

入力元「created_at」→「左文字列」アイコン→出力先の項目「作成年月日」に線をつなぎます。

下記項目はそのまま入力元から出力先に情報を渡すよう、線をつなぎます。
| 入力元 | 出力先 |
|---|---|
| url | 記事URL |
| user > name | 執筆者 |
| title | 記事タイトル |
| page_views_count | View数 |
| likes_count | いいね数 |
| stocks_count | ストック数 |
| tags > name | タグ |
以上でマッピング設定は完了です。
6. 繰り返し処理の設定
改めて、今回は複数ユーザーの記事情報を取得します。
そのため、アクセストークンをユーザー数分繰り返す必要があります。
そこで、「基本」>「フロー」>「繰り返し(データ件数)」を用いてループ処理を作成します。
現在のスクリプトはこのようになっていると思います。

上記に「基本」>「フロー」>「繰り返し(データ件数)」と「基本」>「フロー」>「変数代入」を加えます。
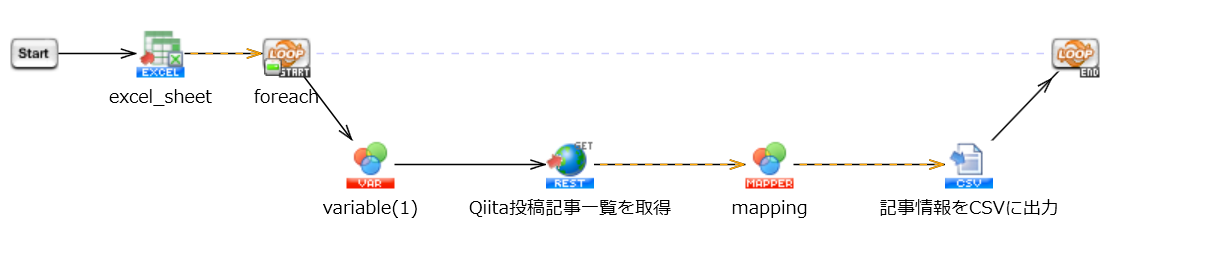
繰り返しアイコンに関しては初期設定から変更せず、GET実行、mapping、CSVファイルの書き込みのアイコンを挟む形で配置して下さい。
変数代入に関してはあらかじめ作成しておいたスクリプト変数「アクセストークン」と「執筆者」にそれぞれ対応するデータをつなげます。
これにより、全員分の記事情報を集め終わるまで繰り返し処理が回り続け、取得した記事情報がCSVファイルに書き込まれる処理が完成となります。

以上で繰り返し処理は完了です。
7. CSVファイル読み取り処理
先ほど、4. CSVファイルの書き込み処理 で作成したファイルは執筆者ごとに記事が書き込まれています。
そのため、次の処理で8. 作成日降順にソート の加工を行うためにファイルを読み込みます。
まずは、必須設定タブです。下記の通りに設定します。
・名前 : 記事情報読み取り
・ファイル : /設定した出力先のディレクトリー/${集計年月}_Qiita記事.csv

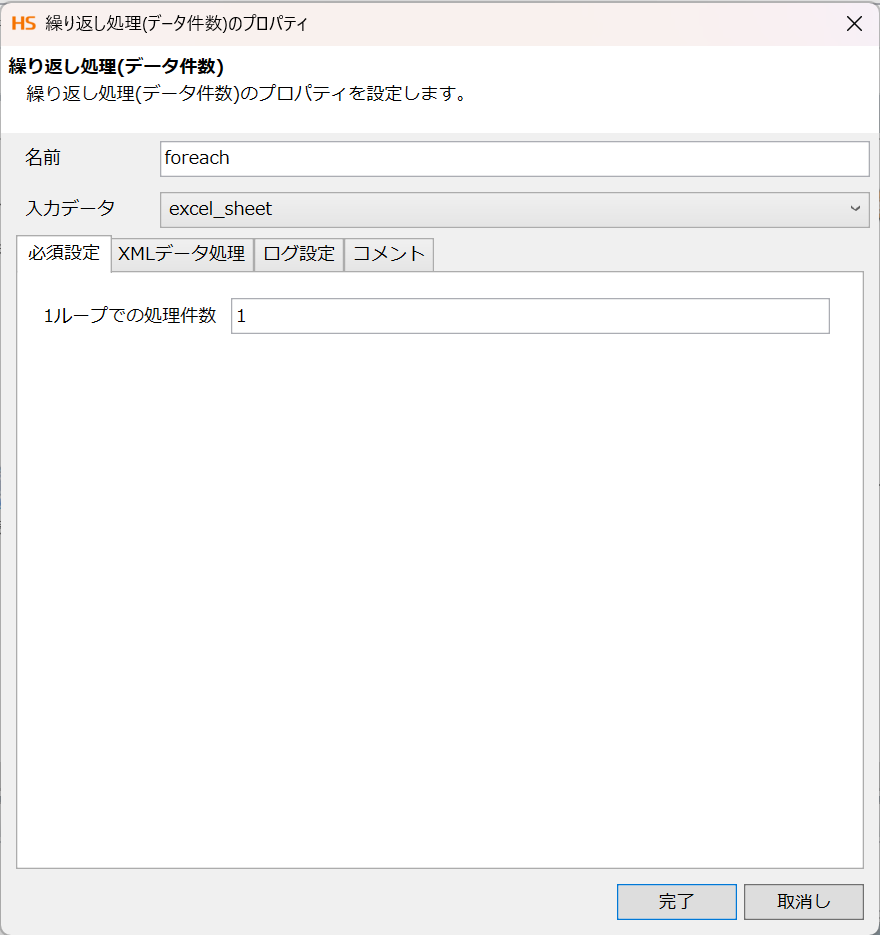
8. 作成日降順にソート
「変換」>「基本」>「ソート」をドラック&ドロップで配置し、下記を入力・設定します。
・名前 : 作成日降順に並び替え
・入力データ : 記事情報読み取り
・列名 : 作成年月日
以上でソート処理は完了です。
9. マッピング設定
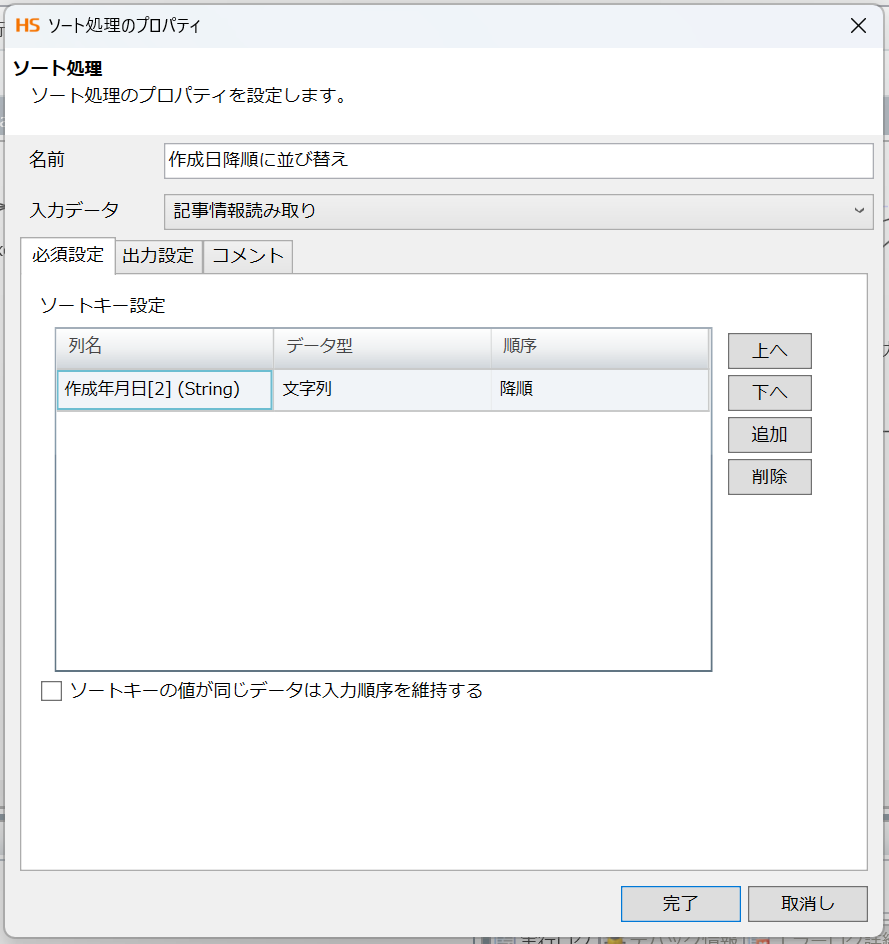
ここでは、限定公開中の記事を省く処理と作成年月日のフォーマットを定めています。

まず、限定公開中の記事のURLにはprivateという文字列が入っているためこれを含まないロジックを作成しています。
ツールパレットの「条件」>「文字列」>「含む」を選択し、判定文字列にprivateを入力。
そして、「文字列」>「真偽」>「Not演算」を選択し、「繰り返し」>「条件指定」>「条件による抽出」まで線をつなぎます。

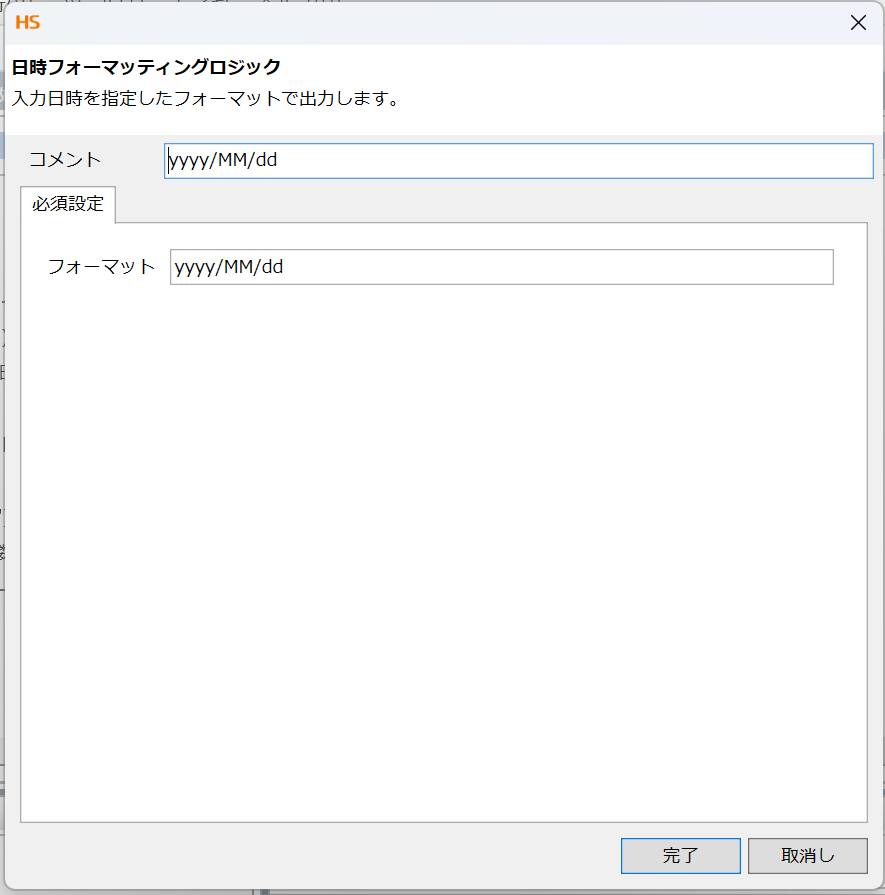
次に作成年月日のフォーマット定義はツールパレットの「文字列」>「日付」>「日時フォーマッティング」を選択し、ヘルプのフォーマットに則りyyyy/MM/ddを入力します。
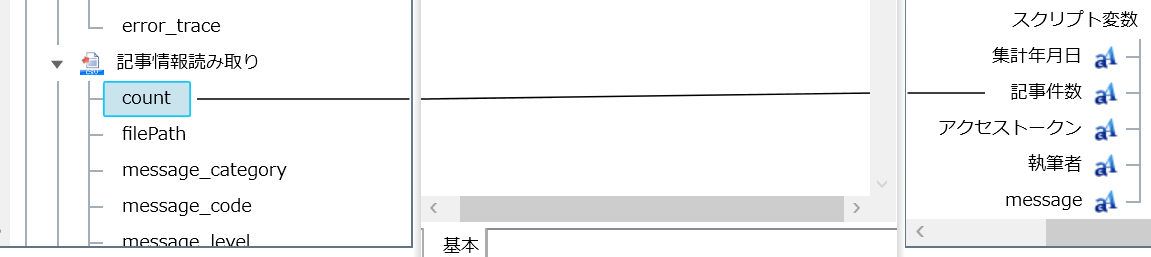
ファイル名に指定しているスクリプト変数「記事件数」に記事情報読み取りの「count」を出力し、投稿記事の合計数がファイル名に記入されるように設定しています。
以上でmapping処理は完了です。
10. CSVファイルの書き込み処理
作成日降順に並び替えた記事のCSVファイルを作成します。
デザイナ画面右側のツールパレットから「ファイル」>「CSV」>「CSVファイル書き込み」アイコンをデザイナ中央にドラッグ&ドロップします。
まずは、必須設定タブです。下記の通りに設定します。
・名前 : ソート後の記事情報をCSVに出力
・入力データ : mapping
・ファイル : /設定した出力先のディレクトリー/${集計年月}_Qiita記事_${記事件数}.csv
<列一覧>
「追加」を押下して、「列名」に出力したい必要項目の定義をします。今回は下記の8項目を出力してみます。
・記事URL
・作成年月日
・執筆者
・記事タイトル
・View数
・いいね数
・ストック数
・タグ

次に、書き込み設定タブです。
「上書き」と「1行目に列名を挿入」に✓を入れます。

以上で、CSV書き込みの設定は完了です。
4.検証結果確認
これまで設定したすべての処理アイコンをつないだスクリプトは以下です。

処理を実行して、出力ファイルの結果をみてみましょう。
スクリプトが正常終了し、指定したディレクトリーに指定した名前でファイルが作成されています。

ファイルの中身を確認すると、指定した項目がすべて出力されていることがわかります。
執筆者やView数、いいねも正しく取得できていました。

最後に
今回は、HULFT SquareのREST接続で複数ユーザーのView数を含むQiita投稿記事に関する情報が取得できました!
HULFT Squareでは日次のスケジュールジョブの設定で毎月1日に前月分の取得結果を自動取得することやSlacKやメール等に通知を送ることも実現可能です。
ここまで読んでいただきありがとうございました!