はじめに
初めてQiitaに記事を投稿してみます。
私はさくら学院というアイドルグループが大好きです。さくら学院にはレギュラー番組があり、その番組にはメンバー全12人中4人が出演します。その4人は決まった組み合わせではないため、今日はどの4人が出るのかなと毎週なんとなく予想をするのですが、ふと、これは過去の出演データから機械学習で予測できるのではないかと思い付きました。
この記事は、機械学習についてほとんど知らないIT初級者が、機械学習で番組出演メンバーを予想しTweetするbotを作り上げるまでに考えたことや参考にしたことをまとめたメモです。
作ったもの
今週 登校するのは
— FRESHマンデー 登校メンバー予測bot (@fresh_predict) August 26, 2019
藤平華乃
有友緒心
田中美空
野崎結愛
と予想します#さくら学院 #FRESHマンデー pic.twitter.com/ypVlT8D0O2
さくら学院×機械学習
さくら学院
**さくら学院**とは、学校生活とクラブ活動をテーマにした女性アイドルグループです。メンバーは小学5年生から中学3年生で構成されており、中学3年生の3月末で義務教育を終えると同時にグループを卒業することが定められている「成長期限定ユニット」です。
学校生活というテーマに沿って、メンバーのことを「生徒」と呼び、ファンのことを「父兄」と呼ぶ。リーダーは「生徒会長」だし、専属MCは「担任の先生」。そんなユニークで楽しいグループとなっております。
「さくら学院の顔笑れ!!FRESH!マンデー」に誰が出演するか予測したい
さくら学院には「さくら学院の顔笑れ!!FRESH!マンデー」というレギュラー番組があります。放送回数は2019年8月時点で110回を超えている、FRESH LIVEの人気番組です。
毎週月曜日19時から生配信となっており、出演(登校)するのは基本的に生徒4人+担任の森ハヤシ先生。
さくら学院は毎年メンバーこそ入れ替わりがありますが、人数は基本的に全12人です。つまり番組に出演するのは12人中4人。特に決まったローテーションがあるわけではなく、出演メンバーの組み合わせは毎回異なります。我々父兄は毎週のように、今日は誰が出るとか出ないとか色々予想を立てるわけですが、なかなか傾向はつかめず、予想の当たらない日々が続いています。
そこで、私はふと思いました。
過去の出演データから、機械学習を用いて次回のメンバーを予想できるんじゃないか?
そしてその予想を毎週 自動でTweetしてくれるbotを作ったら面白いのでは?
私はPythonも機械学習もろくにやったことがなくbotも作ったことない、辛うじて基本情報技術者だけ持っているIT初級者ですが、良い勉強になりそうだからと思い、bot作成を検討し始めました。
機械学習にどう落とし込むか
「12人中どの4人が選ばれるか」という問題をどう機械学習に当てはめれば良いか。正直、機械学習をよく分かっていない私には適切な手法が分からなかったので......
12人中4人が選ばれるという問題ではなく、1人1人が出演するか否かという問題として妥協して考えることにしました。どうやらロジスティック回帰という手法を使えば、0or1となる確率が求められるらしいので、それでメンバー12人それぞれの出演確率を計算し、確率上位4人を予想メンバーとする、ということです。
このやり方だと、4人の相性(AさんとBさんがよく一緒に出演する、等)は全く考慮されないので、不完全ではありますが、まずはこのロジスティック回帰を使ったシンプルなやり方で考えてみることにしました。
過去の出演データ
学習に必要な過去の出演データですが、私が以前に趣味でこんな動画を作った経験が役に立ちそうです。このFRESHマンデー振り返り動画を毎年作るため、過去の出演メンバー等の情報をGoogleスプレッドシートにまとめているのです。ちなみにこの動画はGoogle Apps Scriptを駆使して半自動で作成したのですが、それはまた別のお話......
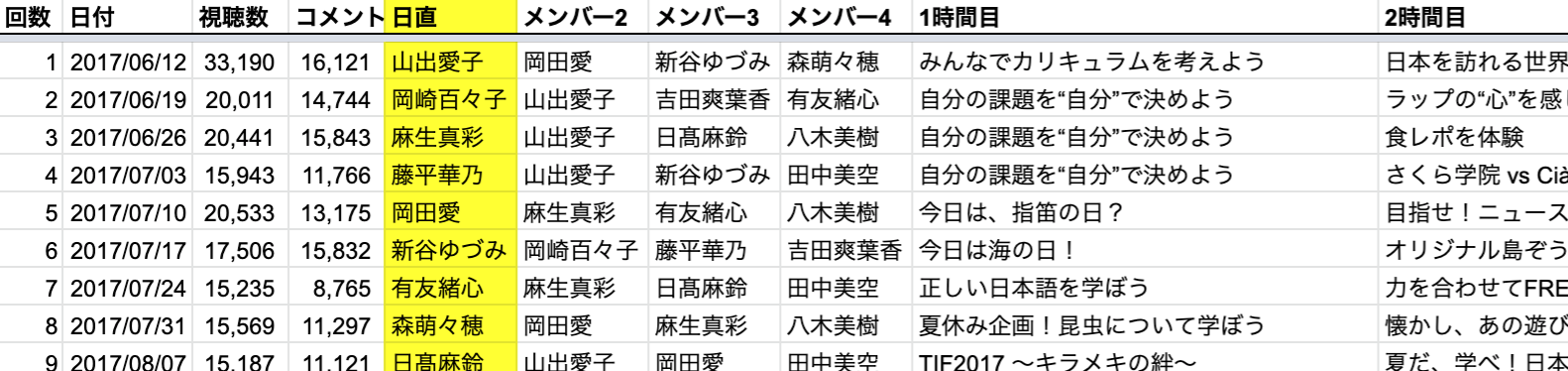
このスプレッドシートを基に学習データを生成できそうです!
学習データの生成
目的変数は、「番組に出演するか否か」です。
説明変数、つまり、ある生徒が番組に出演するか否か に影響を与える情報 については、色々考えられますね。。。
ここの選定が重要だと思うのですが、今回は父兄の勘で以下の5つとし、学習データを生成してみました。
- ・学年
- 小5〜中3。学年が上がるほど出演メンバーに選ばれやすそう
- ・何年目か
- 何年生の時にさくら学院に入ってきた(転入してきた)か生徒によって異なる。
これも、年数を重ねるにつれ出演しやすくなるのでは - ・地方組か否か
- 地方在住の生徒は番組出演のため寮に泊まる必要があるので負担が大きく、選ばれにくいかも
- ・最後に出演してから何回出演していないか
- 連続して出演する生徒・出演しない生徒がなるべく生じないように出演メンバーが組まれてそう
- ・生徒会役職
- 中3を始めとする主要メンバーには役職が与えられる。
役職ありの方が出演しやすそう。特にトーク委員長は選ばれやすいのでは。
トーク委員長:3、生徒会長:2、その他の役職:1、役職なし:0 とした
番組の過去の放送回数が約110回、そのうち全員出演等の特殊な回を除くと、有効なのは約100回。
サンプル数は 100回×12人で約1200件となりました。
学習
データが生成できたので、実際に学習していきます。
以下の記事を参考にscikit-learnを使ってやってみました。
import numpy as np
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
def train_test(x_data, y_data):
# データの前処理
processed_x_data = preprocessing.minmax_scale(x_data)
processed_y_data = preprocessing.minmax_scale(y_data)
# 学習用データとテスト用データに分離
x_train, x_test, y_train, y_test = train_test_split(processed_x_data, processed_y_data, test_size=0.3)
# ロジスティック回帰で学習
reg = LogisticRegression()
reg.fit(x_train, y_train)
print("正解率:", accuracy_score(y_test, reg.predict(x_test)))
print("係数:", reg.coef_)
正解率: 0.7066666666666667
# 学年 何年目か 地方組か否か 出演していない回数 生徒会役職
係数: [[ 0.15242256 0.3830712 0.02913343 2.73521717 0.4863149 ]]
うーん、微妙な正解率...
そして係数にはだいぶ偏りがありますね。
「出演していない回数」だけとても重みがあって、他はあんまり...
これは良いモデルとは言えなさそうです。改善の余地ありですが、今回はこれで進めたいと思います。
予測
このモデルに12人のデータを入力して予測した結果が、以下のとおりです。
[['野崎結愛' 0.6477108380859807]
['田中美空' 0.5905543535501439]
['有友緒心' 0.5842086388298547]
['藤平華乃' 0.48404946550903316]
['森萌々穂' 0.3408375302299693]
['戸高美湖' 0.3104867241028989]
['八木美樹' 0.2829065308365626]
['吉田爽葉香' 0.2802710177070232]
['木村咲愛' 0.2669743575711794]
['白鳥沙南' 0.2610382271602451]
['野中ここな' 0.20348298254456978]
['佐藤愛桜' 0.1906150976495476]]
全員の出演確率を出せました!出演人数は4人なので、この場合は上位4人の
['野崎結愛' '田中美空' '有友緒心' '藤平華乃']が出演する、という予想になります。
bot作成
機械学習部分の目処が立ったので、ここからはbot作成について書いていきます。
AWS Lambda
まずbotをどこに構築するか。ただの趣味である以上、なるべくお金がかからないことが第一条件でした。Pythonを簡単にデプロイできてお金がかからないとなると......仕事で使ったことのある**AWS Lambda**を最初に思いつきました。
少し調べてみると、今回私がやろうとしている「週に1回、機械学習でモデルを作って予測してツイートする」というのが、Lambdaの無料枠に十分収まりそうなので、Lambdaを使うことに決定。
「週に1回」という定期実行も、CloudWatch Eventsのcron式で簡単に設定できることを知っていたので安心でした。
- 参考: AWS Lambda 料金
Serverless
Lambdaで外部モジュールを使用するには、そのモジュールを含めたデプロイパッケージのzipファイルをAWSへアップロードする必要があります。コード変更のたびにそんな面倒なことはやってられないので、何か無いか調べてみたところ、**Serverless**が便利とのこと。今回はこれを使いました。
Lambdaの開発環境構築〜デプロイについては以下の記事がとても参考になりました。
Google API
過去の出演データはGoogleスプレッドシートから取得してくる必要があるので、GoogleAPIを使います。
以下のリンクを参考に、gspreadを用いてシート1枚全てのデータを取得しました。
- 参考・引用:PythonでGoogleスプレッドシートを編集
import gspread
from oauth2client.service_account import ServiceAccountCredentials
def get_sheet():
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name('<JSONファイル名>.json', scope)
gc = gspread.authorize(credentials)
# スプレッドシート「sakura」のシート「FRESH」の全ての値を取得
attendance_list = gc.open('sakura').worksheet('FRESH').get_all_values()
画像生成
せっかくなのでTwitterに投稿する時に、出演すると予想した4人の画像を繋げた1枚の画像を作って添付しようと思いました。
以下の記事を参考に、OpenCVを使って、4枚の画像を連結して1枚の画像を生成します。
Twitter API
予測結果をTwitterにツイートするため、Twitter API を使います。
以下の記事を参考に、画像付きツイートをします。
import json
from requests_oauthlib import OAuth1Session
CK = 'XXXXXXXXXXXXXXXXXXXXXX' # Consumer Key
CS = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' # Consumer Secret
AT = 'XXXXXXXXX-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' # Access Token
AS = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' # Accesss Token Secert
url_media = 'https://upload.twitter.com/1.1/media/upload.json'
url_text = 'https://api.twitter.com/1.1/statuses/update.json'
# OAuth認証 セッションを開始
twitter = OAuth1Session(CK, CS, AT, AS)
# 画像投稿
files = {'media' : open('image.jpg', 'rb')}
req_media = twitter.post(url_media, files = files)
# Media ID を取得
media_id = json.loads(req_media.text)['media_id']
# Media ID を付加してテキストを投稿
params = {'status': '画像投稿テスト', 'media_ids': [media_id]}
req_media = twitter.post(url_text, params = params)
完成!
Lambda にデプロイし、botが完成しました!
2019.8.26より予想ツイートを開始。記念すべき初ツイートがこちら。
そして、結果は...今週 登校するのは
— FRESHマンデー 登校メンバー予測bot (@fresh_predict) August 26, 2019
藤平華乃
有友緒心
田中美空
野崎結愛
と予想します#さくら学院 #FRESHマンデー pic.twitter.com/ypVlT8D0O2
登校したのは、**有友緒心**、八木美樹、**野崎結愛**、**藤平華乃**。 4人中3人正解!なかなかの出だしでした。遅くなってしまいましたが、昨日もFRESHマンデーありがとうございました!24日のライブをたーっぷり振り返りました♪2日9日は2週に渡って、特別編・林間学校の放送になります✨笑いあり、涙あり、喧嘩あり?な展開になっておりますので、こちらもお楽しみください!#FRESHマンデー pic.twitter.com/ucS4VH7EZK
— さくら学院 職員室 (@sakura_shokuin) August 27, 2019
おわりに
IT初級者が色々な記事を参考にしながら、なんとか機械学習を使ったbotを作成することが出来ました。
形にはなったもののとりあえず「やってみた」だけで、改善の余地は大いにありますので、これからも機械学習を勉強して、より精度を上げられるよう顔笑りたいと思います!