経緯
いつまで経っても英語が話せないのにsp⚪︎ak課金を渋る僕のために、現在英会話学習のスマホアプリをFlutterで開発しています。時代は自作自足。
その中で課題になったのが音声入力です。
今の音声入力は精度が高くてすごいなと思うのですが、高すぎるがゆえに微妙な発音とかだと正しく認識してくれなかったり、フィラー(「あ〜」とか「えーっと」みたいな)が入った瞬間めちゃくちゃな文章になったり、なんか使い勝手悪いな〜と感じていました。
そんなある日Qiitaを見ていたら「音声認識APIを使ってみよう!」の文字が見えました。
でも開発段階でそんなお金かかるの嫌なんだよな〜見るだけ見るか
「無料クーポンを配布します」
なんだって!?やるしかねぇ!
作りたいもの
今回は機能検証が目的なので、簡単に画面で音声入力ON/OFFを切り替えて、
話した内容をテキストで表示する、という簡単なつくりにしてみます。
事前確認
そもそも実装できそうなのか確認しておきましょう。
とりあえずチュートリアルを覗いてみます。

なるほど、音声入力をwavで保存するところさえできちゃえば十分そうですね。
都度音声ファイルとして出力しないで済む方法もありそう(PCMでもOKっぽい)だけど、ちょっと試した感じ苦戦したので今回はflutter_soundを使ってwav出力させることにします。
進め方
とりあえずの進め方はざっくり
1.AmiVoice APIを試しに使ってみる
2.flutter_soundを使ってwavで保存
3.AmiVoice APIを使って音声データを送信する
4.応答を表示する
こんな感じでいきます。
最後に英語の発音が微妙でも認識してくれるのか検証してみます。
実装
1.AmiVoice APIを試しに使ってみる
とりあえずcurlを投げてみます。
公式のマニュアルにあるこちらを利用
curl -X POST https://acp-api.amivoice.com/v1/recognize \
-F d=-a-general \
-F u={APP_KEY} \
-F a=@test.wav
音声ファイルはこちらのサイトから拾ってきたtest.wavを使います。いざ
{
"results": [
// 長いので省略
],
"utteranceid": "20240417/17/018eeb29de1f0a301ee294c5_20240417_172613",
"text": "\u660e\u65e5\u306e\u95a2\u6771\u5730\u65b9\u306e\u5929\u6c17\u306f\u6674\u308c\u3001\u3068\u3053\u308d\u306b\u3088\u308a\u306b\u308f\u304b\u96e8\u3067\u3057\u3087\u3046\u3002",
"code": "",
"message": ""
}
textの部分をデコードしたらちゃんと「明日の関東地方の天気は晴れ、ところによりにわか雨でしょう。」ってなってました。おお〜
省略したresultsの部分はこんな感じです。
"results": [
{
"tokens": [
{
"written": "\u660e\u65e5",
"confidence": 0.60,
"starttime": 0,
"endtime": 384,
"spoken": "\u3042\u3059"
},以下略
これは発話区間で区切っているらしく、
・starttimeやendtimeは、発話区間で始めに認識された単語の話し始めと、最後に認識された単語の話し終わりの時刻を表します。送信した音声の先頭を0としたミリ秒単位の時間です。詳細は発話の開始時間を参照してください。
・textはこの発話区間の音声認識の結果を表しています。
・confidenceは信頼度です。0から1の値をとり1に近づくほど、より確からしい結果であることを表します。
・tags、rulenameは、常に空ですので無視してください。
・resultsは配列形式ですが、常に 1 つの要素しか持ちません。
という事らしいです。発話検出プロセスを通して抽出しているんだとか。かっこいい。
どれくらい背景音入っててもいけるんだろうとか気になるところですが、
ちょっと本題から逸れてしまうのと出来上がったもので試してみればOKだと思うので、さっさと作っていきましょう。
2.flutter_soundを使って音声データを保存
とりあえずflutter_soundを使ってみます。
まず最初にパッケージのインストールをします。pubspec.yamlにパッケージ追記して
dependencies:
flutter:
sdk: flutter
http: ^0.13.3
# 以下追加
permission_handler: ^11.0.0
flutter_sound: ^9.2.0
パッケージをインストール
flutter pub get
次に画面を作成していきます。
audio_streamerのexampleでいい感じのレイアウトが用意されていたので使わしてもらって、
処理をflutter_soundで実装する方針でいきます。
import 'package:flutter/material.dart';
import 'package:flutter_sound/flutter_sound.dart';
import 'package:path_provider/path_provider.dart';
import 'package:permission_handler/permission_handler.dart';
import 'dart:async';
import 'dart:io';
class AudioTest extends StatefulWidget {
@override
AudioTestState createState() => new AudioTestState();
}
class AudioTestState extends State<AudioTest> {
FlutterSoundRecorder? _recorder;
bool _isRecorderInitialized = false;
bool isRecording = false;
@override
void initState() {
super.initState();
_initializeRecorder();
}
Future<void> _initializeRecorder() async {
_recorder = FlutterSoundRecorder();
await _recorder!.openRecorder();
_isRecorderInitialized = true;
}
void start() async {
print('start');
Directory tempDir = await getTemporaryDirectory();
String path = '${tempDir.path}/output.wav';
await _recorder!.startRecorder(
toFile: path,
codec: Codec.pcm16WAV,
numChannels: 1,
sampleRate: 16000,
);
setState(() {
isRecording = true;
});
}
void stop() async {
print('stop');
if (_recorder != null && _recorder!.isRecording) {
await _recorder!.stopRecorder();
}
setState(() {
isRecording = false;
});
}
@override
Widget build(BuildContext context) => MaterialApp(
home: Scaffold(
body: Center(
child: Column(mainAxisAlignment: MainAxisAlignment.center, children: <Widget>[
Container(
margin: EdgeInsets.all(25),
child: Column(children: [
Container(
child:
Text(isRecording ? "Mic: ON" : "Mic: OFF", style: TextStyle(fontSize: 25, color: Colors.blue)),
margin: EdgeInsets.only(top: 20),
),
])),
])),
floatingActionButton: FloatingActionButton(
backgroundColor: isRecording ? Colors.red : Colors.green,
child: isRecording ? Icon(Icons.stop) : Icon(Icons.mic),
onPressed: isRecording ? stop : start,
),
),
);
}
ここでMissingPluginException (MissingPluginException...みたいなエラーが出たんですけど、iOSシミュレータ再起動したらなおりました。ホットリロードじゃだめでしたね。
あと音声入力許可のために色々やる必要があるかもしれませんが、自分は既にあるチャットアプリ内に追加しているのでそこは省かせていただきます。
無事起動できたらこんな感じ

まあ、めちゃくちゃシンプルですが一旦これでいいでしょう。
右下のマイクアイコンを押下して何か喋ってみて、コンソールに表示されたパスから音声ファイルを見つけてきます。

発見。再生してみると先ほど喋った自分の美声が再生されます。
自分の声って録音して聞いてみると本当に気持ち悪いですよね。オエ
3.AmiVoice APIを使って音声データを送信する
AmiVoice APIでは音声認識エンジンが色々あります。
以下がエンジンのリストです。

このあと英語も検証するけど、とりあえず最初のチュートリアルでも使った会話汎用の「-a-general」で試してみます。
では先ほど出力された音声ファイルをAmiVoiceに送ってみましょう。ワクワク!
APIレスポンスはこんな感じになるらしいです。

全文欲しいのでresultのtextをログ出力してみましょう。
stop関数を以下のように修正していざ実行!
// 追加
import 'package:http/http.dart' as http;
import 'dart:convert';
// 略
void stop() async {
print('stop');
String? filePath;
if (_recorder != null && _recorder!.isRecording) {
filePath = await _recorder!.stopRecorder();
}
setState(() {
isRecording = false;
});
if (filePath == null) return;
var uri = Uri.parse('https://acp-api.amivoice.com/v1/recognize');
var request = http.MultipartRequest('POST', uri)
..fields['u'] = 'APIトークン'
..fields['d'] = 'grammarFileNames=-a-general'
..files.add(await http.MultipartFile.fromPath('a', filePath, filename: 'output.wav'));
try {
var response = await request.send();
if (response.statusCode == 200) {
print('Audio data sent successfully.');
// Handle response.
var responseData = await http.Response.fromStream(response);
var data = jsonDecode(responseData.body);
print('Response text from AmiVoice API: ${data['text']}');
} else {
print('Failed to send audio data. Status code: ${response.statusCode}');
}
} catch (e) {
print('Error sending audio data: $e');
}
}
マイクONにして話してOFFにしたら結果が出るはず、果たして…
flutter: Audio data sent successfully.
flutter: Response text from AmiVoice API: エリンギの花言葉は、宇宙です。
おお、すごい!
結構「んぁ〜〜エリンギノォハナッッ言葉は、えーーーーーっと宇宙でス」みたいに惑わせてみようと頑張ったのですが、見事に聞き取られてしまいました(?)
特筆すべきはフィラーの排除ですね。先述の通り今回このAmiVoiceで気になっていたところでもあって感動しています。
開発中のアプリでは音声入力にflutter_tts(TextToSpeach)を使っています。
母国語ならそこまで不便ではないかもしれませんが、コンセプトが外国語学習なので、スラスラ話すのは難しい人が多い(と思う)のです。
そういう意味ではこの補完はめちゃくちゃUX向上に繋がりそうですね。あとは英語で使ってどうなるかですが、最後に検証します。期待。
4.応答を表示する
まあこれはなんでもいいので、適当に画面表示できるようコードをいじります。
void stop() async {
print('stop');
String? filePath;
if (_recorder != null && _recorder!.isRecording) {
filePath = await _recorder!.stopRecorder();
}
setState(() {
isRecording = false; // 追加
});
// 略
try {
var response = await request.send();
if (response.statusCode == 200) {
print('Audio data sent successfully.');
// Handle response.
var responseData = await http.Response.fromStream(response);
var data = jsonDecode(responseData.body);
print('Response text from AmiVoice API: ${data['text']}');
setState(() {
responseText = data['text']; // 追加
});
} else {
print('Failed to send audio data. Status code: ${response.statusCode}');
}
} catch (e) {
print('Error sending audio data: $e');
}
}
@override
Widget build(BuildContext context) => MaterialApp(
home: Scaffold(
body: Center(
child: Column(mainAxisAlignment: MainAxisAlignment.center, children: <Widget>[
Container(
margin: EdgeInsets.all(25),
child: Column(children: [
Container(
child:
Text(isRecording ? "Mic: ON" : "Mic: OFF", style: TextStyle(fontSize: 25, color: Colors.blue)),
margin: EdgeInsets.only(top: 20),
),
// 追加
Container(
child: Text(responseText, style: TextStyle(fontSize: 20, color: Colors.grey)),
margin: EdgeInsets.only(top: 20),
),
])),
])),
floatingActionButton: FloatingActionButton(
backgroundColor: isRecording ? Colors.red : Colors.green,
child: isRecording ? Icon(Icons.stop) : Icon(Icons.mic),
onPressed: isRecording ? stop : start,
),
),
);

とりあえず形になったのでコードはOKですね。
ガバガバ発音英語を聞き取れるのか?
さあ本題はここです。いや本当に全然ダメなんですよ。flutter_ttsじゃなくて僕の発音が。
試しに
I would like to leave my luggage.
という例文で音声入力してみますね。
ぼく「アイゥドゥラィトゥリブマイラゲジ」
お、いい感じじゃないか?
.
.
.
.
えっ
.
.
.
.

この際問題があるのは十中八九僕の発音だと思うんですが、英会話学習しようと思って頑張って喋ったのにアプリからこんな仕打ち受けてモチベーションが保てますか?
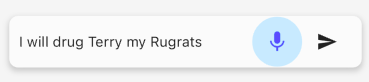
という訳で先ほどのI will drug Terry my Rugratsを録音しておいたので、それをAmiVoiceAPIさんに送ってみましょう。エンジンは英語汎用の「-a-general-en」です。
これでまだ私がドラ◯グ予備軍だったらもう諦めます。
果たして結果は…
.
.
.
.

いやだめなんかーーーい!!!
とツッコミたくなるところですが、先ほどと違って大体あってます!
ここまでくると致命的に僕が「líːv」の発音がダメってことがわかり、wouldもluggageもまあ聞こえなくはないよって事ですよね。
カモンジピえもん!

という訳で無事勝利しました。

いや結局発音を直すことになったじゃん、って話なんですけど、
最初のあの文ではどこをどう直せばいいかわからないですし、アプリの使い勝手としてはかなり段違いになると思います。フィラーの件もあるのでなおさら!
という訳で結論ですが 「ガバガバ発音の英語も最先端AIの気遣いによってかなり認識してくれた」 でした。えっこんな内容の記事で怒られませんか?
気になる料金
色々遊んで検証した後ですが、どれくらいの料金がかかるのか概算出してみようと思います。
例えば先ほどの文章ですが、各ワードに対しての時間が以下の通りです。
{
written: I,
confidence: 0.93,
starttime: 750,
endtime: 1370,
spoken: I
},
{
written: would,
confidence: 0.99,
starttime: 1410,
endtime: 1670,
spoken: would
},
{
written: like,
confidence: 0.78,
starttime: 1670,
endtime: 2070,
spoken: like
},
{
written: to,
confidence: 0.98,
starttime: 2070,
endtime: 2410,
spoken: to
},
{
written: leave,
confidence: 0.53,
starttime: 2450,
endtime: 2690,
spoken: leave
},
{
written: my,
confidence: 0.99,
starttime: 2690,
endtime: 2930,
spoken: my
},
{
written: luggage,
confidence: 1.0,
starttime: 2930,
endtime: 3970,
spoken: luggage
},
leaveのconfidenceだけ低いのめちゃくちゃ面白いですね、まだ下手みたいですヴが。
リファレンスには次のように書いてあります。
音声認識 API の請求は、results[].starttimeとresults[].endtimeに基づいています。
starttime: 750で endtime: 3970なので3970-750=3220ミリ秒でしょうか?
いや、results[].starttimeとresults[].endtimeに基づいてるってことは、単語と単語の間の時間は換算されていないってことですね。
例えばIのendtimeは1370でwouldのstarttimeは1410なので、
この間の40ミリ秒は料金に勘定されていないってことだ…なのでそれぞれの発話時間で数え直すと3140ミリ秒ですね。
今回使った英語汎用は0.025円/1000msなので、この1回の入力は0.0785円でしょうか。安い!
ん・・・?

60分まで無料…?
60分って3,600,000msだよな…
超長く見積もって一回の入力を10,000msとしても360入力までタダ…ってコト!?
この辺りの情報間違っていたらすみません。安すぎてあんまり自信ないです。
あとがき
今回音声認識AIを触ったのは初めてだったのですが、コスパの良さ(安さもだけどパフォーマンスの高さ)にとっても驚きました。背景音入れたりしてもみたのですが、検証した限りでは何も拾われなかったです。
別に記事投稿キャンペーンだから媚びてるとかではないです。ぜひ使ってみていただきたい。
記事書いてて思ったのですが、さっき
leaveのconfidenceだけ低いのめちゃくちゃ面白いですね、まだ下手みたいですヴが。
と言いました。この箇所ですね。
{
written: leave,
confidence: 0.53,
starttime: 2450,
endtime: 2690,
spoken: leave
}
某英会話アプリとかで発音の良し悪し評価機能とかすごいな〜って思っていたのですが
例えば発音強化コーナーみたいなものを作って例文を用意してユーザーに読んでもらって、このconfidenceと照合することで
発音評価の機能に近いものが実現できそうですね。というか十分すぎるのでは…?
音声データを扱うのもあんまり経験がなかったので、色々勉強になったのと純粋に楽しかったです。
最後までお読みいただきありがとうございました。
追記
なんと当記事をキャンペーン「音声認識APIを使ってみよう!」のAmiVoice最優秀賞として選出していただきました。身に余る光栄で御座います。。
上で触れた発音評価機能についての実装編も作成したので、良かったらご一読ください。