はじめに
前回作成した記事の続きです。
最後にちらっと触れたのですが
confidenceと照合することで発音評価の機能に近いものが実現できそう
これをちょっと作ってみようかなと思います。
SpeakToTextは沢山ありますけど、発音の良し悪しを判定してくれるものと言えば結構高級な某英会話学習アプリか、無料だけどもう一声…みたいなものしか無かったので、自分で使う用に自分で作ってみます。
おさらい
AmiVoice APIのレスポンスは以下のような感じです。
{
written: I,
confidence: 0.93,
starttime: 750,
endtime: 1370,
spoken: I
},
{
written: would,
confidence: 0.99,
starttime: 1410,
endtime: 1670,
spoken: would
},
{
written: like,
confidence: 0.78,
starttime: 1670,
endtime: 2070,
spoken: like
},
{
written: to,
confidence: 0.98,
starttime: 2070,
endtime: 2410,
spoken: to
},
{
written: leave,
confidence: 0.53,
starttime: 2450,
endtime: 2690,
spoken: leave
},
{
written: my,
confidence: 0.99,
starttime: 2690,
endtime: 2930,
spoken: my
},
{
written: luggage,
confidence: 1.0,
starttime: 2930,
endtime: 3970,
spoken: luggage
},
このconfidenceの値が肝で、簡単に言えば1に近いほど自信アリ、0に近いほど
Amiちゃん「多分こう言ってるけど自信ないよぉ…´•̥ ω •̥`」
って感じです。先の例でいくと僕のlikeとleaveの発音が怪しいことがわかりますね。
そういえば日本語エンジンで英語喋ったらどうなるんだ?
ちょっと気になったので試してみます。これで「アイウッドライクトゥーリーブマイラゲッジ」とかカタカナで返ってきたらなんか使い道ありそうな気もします。検証開始
エンジンを汎用-英語の「-a-general-en」で適当な英語を話しかけてみます。結果は以下の通り

良いですね。
では同じ文章を日本語-音声入力汎用「-a-general-input」に投げてみましょう。


そりゃ日本語で入れろって言ってんのに英語で話しかけているこっちが悪いですね。すいません。
でも日本語エンジンだからといって英語が解釈できないというのも不便だなぁ…
と、ここで先日アドバンスト・メディアの方から「文脈に応じた文章を返すので、文章が短いより長い方が精度が高くなる」とお話をお伺いしたので、無理やり日本語の中に英語を入れてみます。

ワーオ!ちゃんと英語の部分は英語で解釈されてますね!
という訳で日本語エンジンに対して「急に英語で話しかけると今井プロが出てくる」けど、「日本語文脈の中に英語が登場したら正しく判別される」ことがわかりました。スッキリ。
今回作るやつ
閑話休題
とりあえず英文を読み上げて、どの単語の発音が良い、微妙、ダメって教えてくれるやつが欲しいので考えていきます。
構成
Amiちゃんに認識させた文章そのものに対して発音評価できればいいんですが、
正しく認識されなかった場合、何が正なのか判別がつかないと思うので、
1.発音する文章を用意する
こちらから例文を提供するのでもユーザーが直接入力するのでもなんでも良いです。
いちいち例文考えて作成して入力してやっと読む…というのも大変そうなので今回は例文を用意します。
2.音声を入力する
前述の用意した文章を音読します。Ttsとか使ってお手本も再生したいですね。
3.認識された文章と読み上げた文章を照合する
なんとなくのイメージですが、こんな感じで表示されたらわかりやすいかなと考えています。
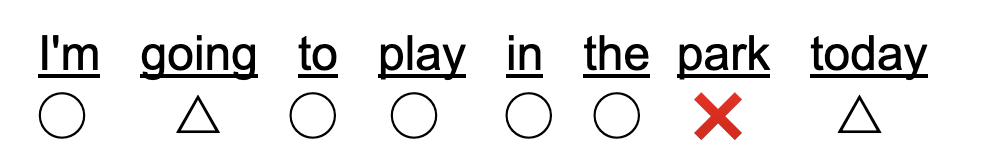
confidenceの値が低かったら△とか、そもそも違う単語が出てきていたら×とか、単語単位で発音の評価をしてみたいですね。
記号を表示しなくてもテキストの色を変えるとかそんな感じにしてみましょう。
実装
まずは前回作成したコードを基に、表示を変更してみましょう。
認識された文章と、各単語の真下にconfidenceの値を表示してみます。
var uri = Uri.parse('https://acp-api.amivoice.com/v1/recognize');
var request = http.MultipartRequest('POST', uri)
..fields['u'] = 'APIキー'
..fields['d'] = 'grammarFileNames=-a-general-en'
..files.add(await http.MultipartFile.fromPath('a', filePath, filename: 'output.wav'));
var response = await request.send();
if (response.statusCode == 200) {
var responseData = await http.Response.fromStream(response);
var data = jsonDecode(responseData.body);
print('Response text from AmiVoice API: ${data}');
setState(() {
responseText = data['text'];
wordConfidences = data['results'][0]['tokens'].map<Map<String, dynamic>>((token) {
return {'word': token['written'], 'confidence': token['confidence'] ?? 0.0};
}).toList();
});
} else {
print('Failed to send audio data. Status code: ${response.statusCode}');
}
ScaffoldのContainerも変更します。少数第2位まで表示しましょう。
Container(
child: Text("入力結果", style: TextStyle(fontSize: 16, color: Colors.blue)),
margin: EdgeInsets.only(top: 100),
),
Container(
margin: EdgeInsets.only(top: 5),
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Wrap(
alignment: WrapAlignment.center,
spacing: 10.0,
runSpacing: 10.0,
children: wordConfidences.map((wordData) {
return Column(
children: [
Text(
wordData['word'],
style: TextStyle(fontSize: 16, color: Colors.blue),
),
Text(
"(${wordData['confidence'].toStringAsFixed(2)})",
style: TextStyle(fontSize: 12, color: Colors.red),
),
],
);
}).toList(),
),
],
),
),
結果はこんな感じ

という訳で、各単語に対してConfidenceの値を紐づけることに成功しました。最後のピリオドとかハテナは除外したいですね。いつか。
では後は提示された英文と、読み上げて認識された英文の一致判定をする必要があるんですが、、、
う〜〜〜〜ん、どうしましょ?大小文字スペース無視で文字列の完全一致で判定したら、全文一致か否かにしかならないし、各単語配列で比較するにしてもなんか個数がズレるとややこしそうだなぁ、、、
うーん🤔

先生!お願いします!
「間違っていたら、間違っている単語の部分(=認識されなかった、つまり発音が良くなかった)
を赤字にする」という処理を追加したいと思います。
コードを作成する前に、あなたの考えを教えてください。
どのようなロジックで「間違っている単語」を抽出しますか?
考え方としては、以下のステップで間違っている単語を抽出することができます:
・単語ごとに分割
例文(targetSentence)と音声認識の結果(responseText)を単語ごとに分割します。
・一致チェック
各単語を順に比較して、一致するかどうかをチェックします。
音声認識の結果が例文より短い場合、または単語が一致しない場合は、その単語を間違っていると判断します。
・例外処理
例文が「She sells seashells by the seashore.」で、
認識結果が「She shared shells by the seashore.」のような場合、
認識された単語の数が多いか少ない場合に対応します。
・具体的なアルゴリズムは以下のようになります
targetSentenceとresponseTextを空白文字で分割し、それぞれの単語リストを作成します。
2つの単語リストを順に比較し、一致しない単語を抽出します。
responseTextの単語リストがtargetSentenceの単語リストより短い場合、
targetSentenceに含まれるがresponseTextには含まれない単語を間違いと判断します。
・具体的なロジックの例は以下の通りです
例文の単語リスト: ["She", "sells", "seashells", "by", "the", "seashore."]
認識結果の単語リスト: ["She", "shared", "shells", "by", "the", "seashore."]
各単語を順に比較して、sharedやshellsが一致しないため、間違っていると判断します。
これを踏まえて、次にコードを書いていきます。
大凡の考え方は良さそうなので、何度か要望のすり合わせもしてコードの生成をして貰いました。
Container(
margin: EdgeInsets.only(top: 5),
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Wrap(
alignment: WrapAlignment.center,
spacing: 10.0,
runSpacing: 10.0,
children: targetSentence.split(' ').map((word) {
bool isCorrect = false;
bool isLowConfidence = false;
List<String> responseWords = responseText.split(' ');
// 対象の単語と比較して一致するかどうか確認
for (int i = 0; i < responseWords.length; i++) {
if (word.toLowerCase() == responseWords[i].toLowerCase()) {
isCorrect = true;
// confidence値をチェック
if (i < wordConfidences.length && wordConfidences[i]['confidence'] < 0.9) {
isLowConfidence = true;
}
break;
}
}
return Text(
word,
style: TextStyle(
fontSize: 20,
color: isCorrect
? (isLowConfidence ? Colors.yellow : Colors.green)
: Colors.red, // 一致する場合は緑、一致するがconfidenceが低い場合は黄色、一致しない場合は赤
),
);
}).toList(),
),
],
),
),
// 以下略
お〜こう書かれてみるとmapで各単語に対して判定色付きの単語を返してる、割とシンプルな処理になっていますね。color部分の三項演算子とか凄いGPTさんのコードみを感じます。
という訳で表示を確認。音声認識で判定された文章も確認したいので、さっき作ったやつと並べて配置してみます。

間違った単語で認識されたら赤字、confidenceが低い単語は黄色、0.9以上は緑、という表示にちゃんとなっていますね。イイネ!
もちろんテストの為にあえて下手な発音をしましたよ。もちろん。
実行における料金
何度か試してみて、1リクエストあたりの時間をカウントしてみます。時間だけ抜き出して
[
{ "starttime": 860, "endtime": 1100 },
{ "starttime": 1100, "endtime": 1340 },
{ "starttime": 1340, "endtime": 1940 },
{ "starttime": 1940, "endtime": 2200 },
{ "starttime": 2200, "endtime": 2440 },
{ "starttime": 2440, "endtime": 3000 },
{ "starttime": 3000, "endtime": 3660 },
{ "starttime": 3660, "endtime": 3780 },
{ "starttime": 3780, "endtime": 4680 }
]
endtime - starttime の合算を計算してみると、3820ms でした。
1回の入力上限は5000msで良さそうですね。なので60分(3600000ms)を越える720回までは無料ってことですか。
絶対使い切れないんで個人利用の範疇とはいえタダ使いがちょっと申し訳ないくらいですね。youtubeでアドバンスト・メディア Channelとかあったらスパチャしておきます。
まとめ
たぶんAmiVoice正規の使い方じゃないような気がしますが、御誂え向きとばかりに認識精度の値が見つかったので試しに作ってみました。
結果として僕は某超高級英会話学習AIサポートアプリの課金で破産する未来を回避し、激安APIのAmiVoiceを使ってバイリンガルになることができました。eatenの発音が一回も0.9を越えてくれません。
最後までお読みいただきありがとうございました。