NeuralNetworkConsoleのセットアップをしてみたので、入門ということでKaggleのTitanicを試してみる。
自分で作ったコードで試してみたときのはこっち
Titanicを試してみる
ネットワークモデル
- 2値分類なので、01_logistic_regressionを流用してみる
DataSet
- DLしていたTrain/TESTデータをDataSetのTraining/Validationにそれぞれ指定。
INPUT
- sizeをTrainの項目数分に設定
実行してみる
- あまり深く考えずにとりあえず実行
エラー1
Variable “x” is not found in dataset.
- DetaSetにラベルが付いていないとだめらしい。
- 特徴量の対象とする項目を[x__0:項目名]みたいな感じに変更、目的変数の項目を[y__0:項目名]みたいな感じに変更。
- 今回だとこんな感じにしてみた
PassengerId,y:Survived,x__0:Pclass,Name,x__1:Sex,x__2:Age,x__3:SibSp,x__4:Parch,x__5:Ticket,x__6:Fare,x__7:Cabin,x__8:Embarked
エラー2
豪快にTraceback出力
何かがFileNotFoundErrorになっているらしい。
Traceback (most recent call last):
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\cli\cli.py", line 125, in cli_main
return_value = args.func(args)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\cli\train.py", line 440, in train_command
info = load.load([args.config], prepare_data_iterator=None, exclude_parameter=True)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\load.py", line 856, in load
info.datasets = _datasets(proto, prepare_data_iterator if prepare_data_iterator is not None else info.training_config.max_epoch > 0)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\load.py", line 632, in _datasets
d.uri, d.batch_size, d.shuffle, d.no_image_normalization, d.cache_dir, d.overwrite_cache, d.create_cache_explicitly, prepare_data_iterator, i)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\load.py", line 600, in _create_dataset
with data_iterator_csv_dataset(uri, batch_size, shuffle, rng=rng, normalize=False, cache_dir=cache_dir, with_memory_cache=False) as di:
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_iterator.py", line 587, in data_iterator_csv_dataset
epoch_end_callbacks=epoch_end_callbacks)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_iterator.py", line 409, in data_iterator
rng=rng)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_source.py", line 431, in __init__
self._create_cache()
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_source.py", line 324, in _create_cache
self._store_data_to_cache_buffer(self._position)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_source.py", line 274, in _store_data_to_cache_buffer
self._save_cache_to_file()
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_source.py", line 208, in _save_cache_to_file
pool.map(get_data, [(pos, q) for pos in self._cache_positions])
File "C:\PJ\20190313\neural_network_console_140\libs\Miniconda3\lib\multiprocessing\pool.py", line 266, in map
return self._map_async(func, iterable, mapstar, chunksize).get()
File "C:\PJ\20190313\neural_network_console_140\libs\Miniconda3\lib\multiprocessing\pool.py", line 644, in get
raise self._value
File "C:\PJ\20190313\neural_network_console_140\libs\Miniconda3\lib\multiprocessing\pool.py", line 119, in worker
result = (True, func(*args, **kwds))
File "C:\PJ\20190313\neural_network_console_140\libs\Miniconda3\lib\multiprocessing\pool.py", line 44, in mapstar
return list(map(*args))
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_source.py", line 197, in get_data
d = self._data_source._get_data(pos)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_source_implements.py", line 416, in _get_data
return tuple(self._process_row(self._rows[self._order[position]]))
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_source_implements.py", line 398, in _process_row
values[variable].append(self._get_value(column_value))
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_source_implements.py", line 411, in _get_value
with self._filereader.open(value) as f:
File "C:\PJ\20190313\neural_network_console_140\libs\Miniconda3\lib\contextlib.py", line 81, in __enter__
return next(self.gen)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\data_source_loader.py", line 139, in open
f = open(filename, 'rb')
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\work\\DL_FILES\\kaggle_ti
最初はファイルがUTF8じゃないとNGになるのかと思ったが、どうやらそういうわけでもなさそう。
とはいえ、何を読みこもうとしてFileNotFoundErrorになっているのかわからないので、ログを埋め込んでファイル名を出してみたりしたところ、
雰囲気的にはデータからキャッシュを作ってそれを読みこもうとしているときに対象データ(ファイル)が存在しないからエラーになっているような感じっぽい。
前処理していないデータをそのまま食わせているので、その辺が原因なのかなと思ったが確証がない。
マニュアルに書いていなかったのでフォーラムに質問を投げて、
前に作った処理を流用して前処理実施済みのCSVファイルを作ってみた。
結果
欠損値無し(+ちょい前処理)の状態のCSVであれば、ここのエラーは出なくなった。
エラー3
Traceback (most recent call last):
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\cli\cli.py", line 125, in cli_main
return_value = args.fun
c(args)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\cli\train.py", line 535, in train_command
result = _train(args, config)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\cli\train.py", line 412, in _train
args, config, monitoring_report, best_error, epoch)
File "C:\PJ\20190313\neural_network_console_140\libs\nnabla\python\src\nnabla\utils\cli\train.py", line 259, in _evaluate
d], ctx=dest_context,
KeyError: 'y'
(null)
TESTデータにもY列が必要?
とりあえず0で補ってみる。
df_test["y__0:Survived"] = 0
出力できた!
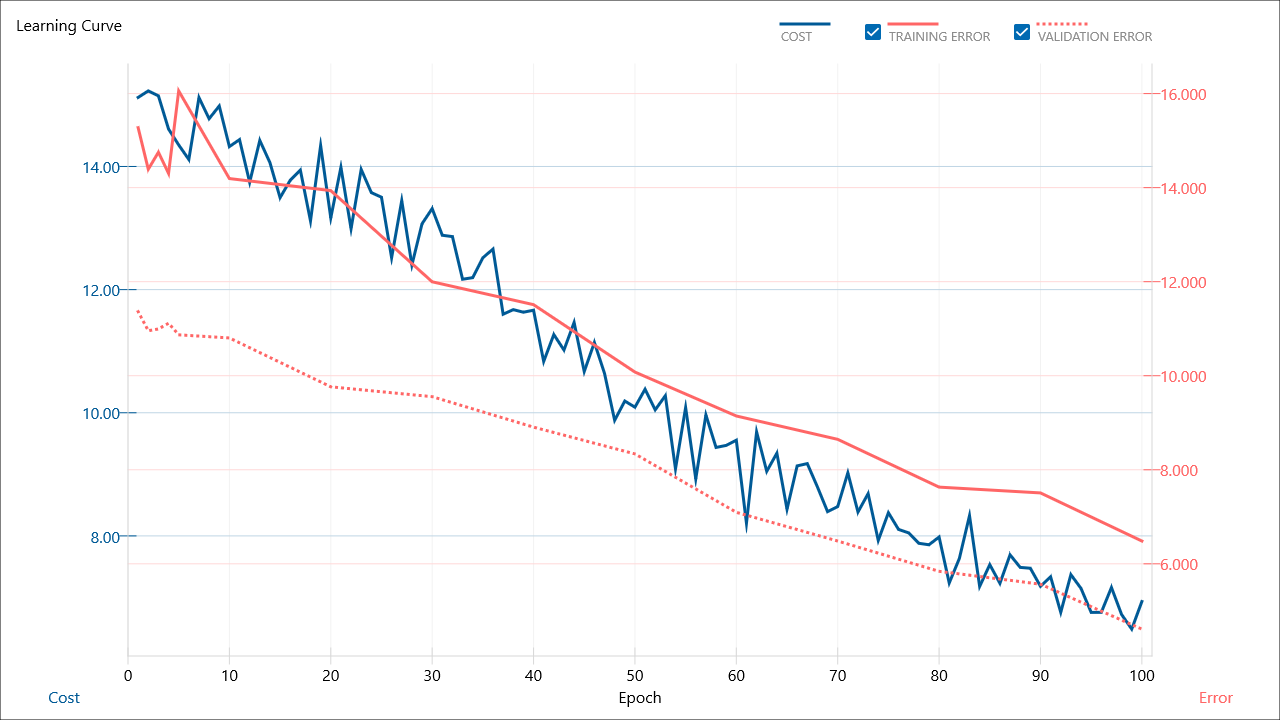
で、これでどうすればいいんだ?
TESTのYに対して確率?を出しているのがこの状態。
本当であればTESTを使って推論を実施して出来上がりというのがあるべき姿なきがする。
BinaryCrossEntropy をSquaredError にしてみる
全然収束していない気がする。
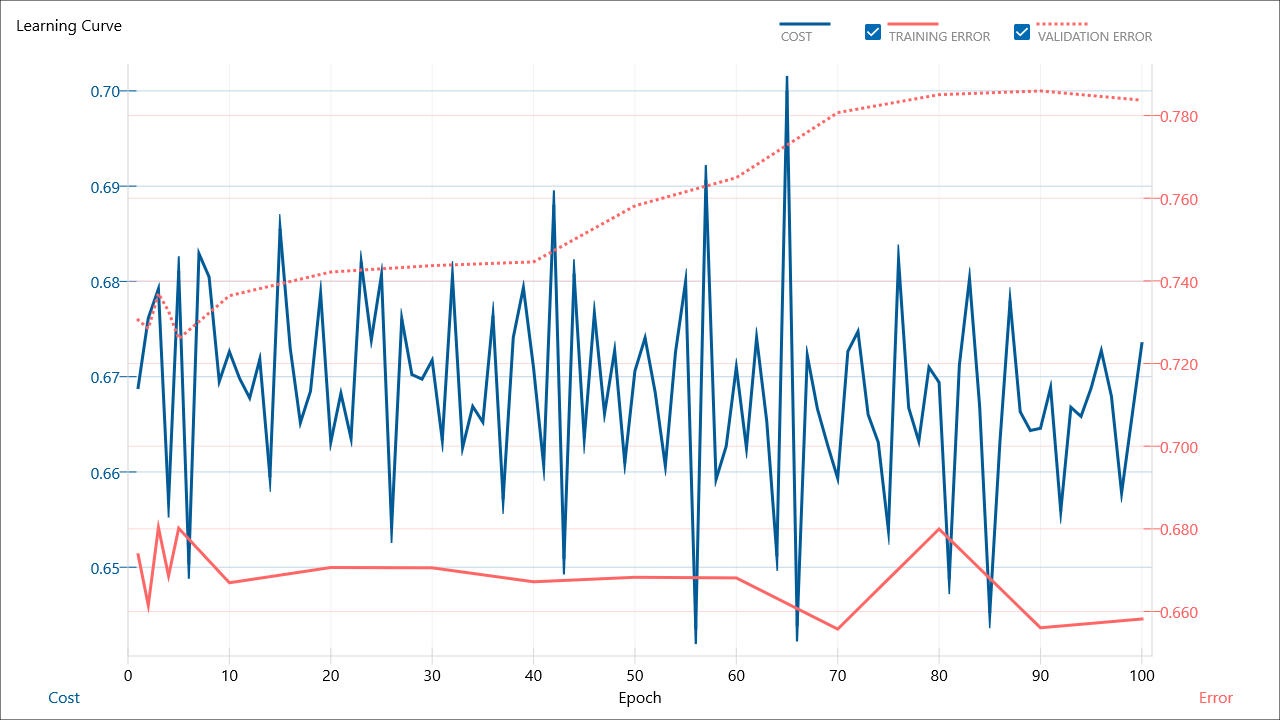
でも表にしてみるとこんな感じ。それっぽい推定にはなっているような気もする。

MAX EPOCHを1000にしてみた。
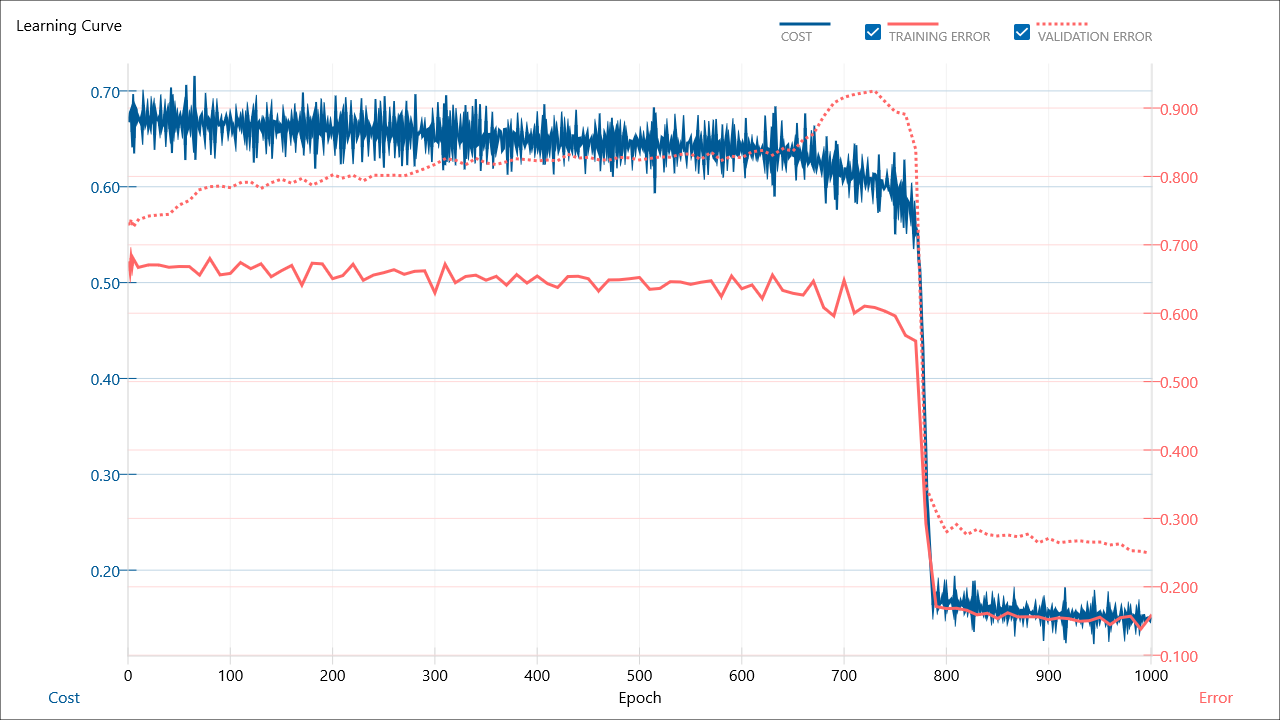
あまりみたことないような絵に。
y'で出てきちゃっているのが推論結果な気がするので、この値をSurvivedとしてコンペに出せればいいような気がする。
最終的にタイタニックコンペは「PassengerId,Survived」という形式にすればいいので、y'のデータを0か1に分類して必要なデータだけ結合してあげればいいのかな。
分類ぐらいまではNNCの中でできそうな気もするけど、最後にとりあえず手動でやってみることにして先へ進む
2値分類なのにSquaredErrorにしたのがダメな気がするので、BinaryCrossEntropyに戻す。
で、MAX EPOCH:1000
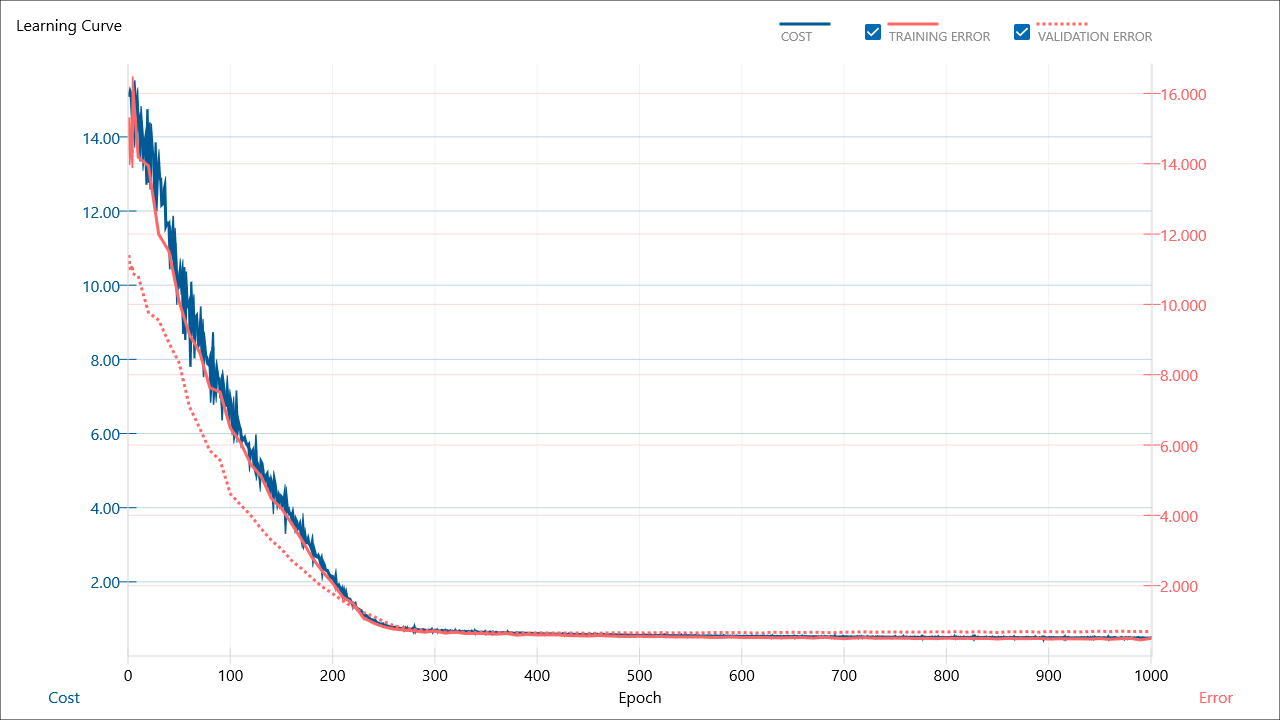
1000もいらないのかな。
でも、2値分類なのに、0/1にならないのはなぜだ?
あらためてググる
https://newtechnologylifestyle.net/sonny_nnc_irisdata_junnbi/
evaluationに指定すべきなのは?
よくよく考えるとevaluationのデータにTESTのデータを使っているのが間違っているような気がする。
そうするとTrainを二つにわけてTrainingとValidationに設定したうえで、推論時にTESTをつかうことになるのか?
フォーラムより
https://groups.google.com/forum/#!topic/neural_network_console_users_jp/t5LF6bn9230
Trainをわけるのもめんどくさかったので、どっちも同じものを使用。
Tarin時にはシャッフルしてるし、いいでしょ。。
で、推論させてみるためにTESTを差し替えて実施。
Y'が確率?で出力されるので、それを表ソフトで四捨五入。
※ここも含めてNNC上でできるとはおもうのだが、めんどくさかったので妥協。
「PassengerId,Survived」のみを残してKaggleにアップロード

PublicScoreは0.75119
前にいくつか処理を書いたときのMAXが0.77990なので、そこまでよくはない感じ。
でも、最初にアップロードしたときよりは良い。
これはどう評価したらいいもんなんだろうか。
自動最適化してくれるらしいので、それを使うと8割の壁を越えてくれたりするのだろうか?
それとも前処理がさらに必要なのだろうか?
自動最適化させてみる
設定そのものは簡単。ConfigのStructure SearchをONにすればいいだけ。
これでTrainingを実行すると最初に自分がEDITしたやつが実行され、それ以降いろいろとネットワークを組み替えて動く
・・・これいつ終わるんだ?
※自分で適当なところで止めないと終了しないっぽい。
二時間ぐらいずっと動かしてたら、ゴミみたいなネットワークも大量に。
この中から有用なものを探すというのがちょいめんどう。
Imconpleteのものを削除する機能があるので、収束していないものを削除できる機能もしくは複数選択してまとめて削除できる機能が欲しい。
というか、出来上がったものをみると自分で作った最初のやつ以外F値がくそ低くて使い物にならない。
データの問題なのか、ネットワーク的に最初の方がいいだけなのか。これぐらいシンプルなものだとこんなものなのか。
この辺の切り分けがよくわからない。
前にやった「いくつかの手法を順番に流してみてスコアのいい奴を残すやり方」を簡単にできるようにしているような感じに見えるな。
でも、アンサンブルみたいなものはどうやったらいいんだろう?
アンサンブルはNNC上で実施するのではなく、いくつかのネットワークをこれで作って、それをスクリプトでアンサンブル化するのがちょうどいい使い方なんだろうか?
参考
http://cedro3.com/ai/rent-dl/
http://printf.hatenablog.com/entry/2017/09/24/184448
http://cedro3.com/ai/nikkei-stock-dl/
https://arakan-pgm-ai.hatenablog.com/entry/2018/04/11/080000
前処理として作ったコード
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# Python3
import pprint
import datetime
import pandas as pd
import numpy as np
import os
folder_path_data_set = <データセット用フォルダ>
csv_train = os.path.join(folder_path_data_set, r"kaggle_titanic\train.csv")
csv_test = os.path.join(folder_path_data_set, r"kaggle_titanic\test.csv")
csv_train_output = os.path.join(folder_path_data_set, r"kaggle_titanic\train_output.csv")
csv_test_output = os.path.join(folder_path_data_set, r"kaggle_titanic\test_output.csv")
csv_encoding='shift_jis'
print(csv_train)
print(csv_test)
print(csv_train_output)
print(csv_test_output)
def read_dataset(df):
# サイズ
print("= size =")
pprint.pprint(df.shape)
# 統計量
print("= describe =")
pprint.pprint(df.describe())
# 欠損データ
print("= 欠損データ =")
pprint.pprint(kesson_table(df))
# 先頭データ
print("= head =")
pprint.pprint(df.head(10))
def read_datasets(df_train, df_test):
print("---> train ---")
read_dataset(df_train)
print("---> test ---")
read_dataset(df_test)
print("------------------------")
def kesson_table(df):
null_val = df.isnull().sum()
percent = 100 * df.isnull().sum()/len(df)
kesson_table = pd.concat([null_val, percent], axis=1)
kesson_table_ren_columns = kesson_table.rename(
columns = {0 : '欠損数', 1 : '%'})
return kesson_table_ren_columns
def distribution(df, column_name):
#平均・標準偏差・null数を取得する
Age_average = df[column_name].mean() #平均値
Age_std = df[column_name].std() #標準偏差
Age_nullcount = df[column_name].isnull().sum() #null値の数=補完する数
# 正規分布に従うとし、標準偏差の範囲内でランダムに数字を作る
rand = np.random.randint(Age_average - Age_std, Age_average + Age_std , size = Age_nullcount)
#Ageの欠損値
df[column_name][np.isnan(df[column_name])] = rand
pass
def pre_processing(df):
# 欠損値の補完
## 中央値を設定:median()で中央値が取得できる
df["Age"] = df["Age"].fillna(df["Age"].median())
# distribution(df, "Age")
## 最頻値を設定:pandas.Seriesに対してmode()で最頻値のSeriesが取得できるのでそれの先頭を使用
df["Embarked"] = df["Embarked"].fillna(df["Embarked"].mode()[0])
# distribution(df, "Embarked")
## 最頻値を設定
df["Fare"] = df["Fare"].fillna(df["Fare"].mode()[0])
# distribution(df, "Fare")
# 文字列→数字化
df['Sex'] = df['Sex'].map({ 'male':0, 'female':1})
df['Embarked'] = df['Embarked'].map({ 'S':0, 'C':1, 'Q':1})
# df['Sex'] = df['Sex'].map({ 'male':1, 'female':0})
# df['Embarked'] = df['Embarked'].map({ 'S':1, 'C':2, 'Q':0})
def get_data():
# ファイル読み込み
df_train = pd.read_csv(csv_train, encoding=csv_encoding)
df_test = pd.read_csv(csv_test, encoding=csv_encoding)
return df_train, df_test
if __name__ == '__main__':
print("start")
# データ取得
df_train, df_test = get_data()
# 前処理:pre_processing
# pd.options.mode.chained_assignment = None
for df in [df_train, df_test]:
pre_processing(df)
# pd.options.mode.chained_assignment = 'warn'
# 変換後データの確認
read_datasets(df_train, df_test)
# 特徴量の対象とする項目と目的変数の項目を決定
lst_params = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
rename = {}
new_lst_params =[]
for index, name in enumerate(lst_params):
newname = "x__{}:{}".format(index, name)
rename[name] = newname
new_lst_params.append(newname)
# lst_params = ["Pclass", "Sex", "Age", "Fare"]
# 学習には使用しないけどのこしておきたい項目
new_lst_params.append("PassengerId")
# 目的変数以外は一緒なので先にTESTを出力
new_df_test = df_test.rename(columns=rename)
new_df_test["y__0:Survived"] = 0
# 目的変数の項目を設定
rename["Survived"] = "y__0:Survived"
new_lst_params.append("y__0:Survived")
# print(new_lst_params)
# 教師データを出力
new_df_train = df_train.rename(columns=rename)
new_df_train.to_csv(csv_train_output, columns=new_lst_params, index=False, encoding='utf-8')
new_df_test.to_csv(csv_test_output, columns=new_lst_params, index=False, encoding='utf-8')
print("end")