はじめに
RTL設計ではデータフロー方式(data flow method, DF)と呼ばれるものが一般的です。
しかし、データフロー方式の記述は既存のコードを読もうとすると大変です。(後述)
データフロー方式の問題点を克服するために、VHDLでは2プロセス方式(two-process method, TP)と呼ばれる記述方法が提唱されています。
[PDF] 5 A structured VHDL design method
2プロセス方式の基本となる部分をSystemVerilogで書くとどうなるかをまとめました。
より詳しくは参考資料をご覧ください。
データフロー方式 (data flow method, DF)
データフロー方式は合成可能なHDLのコーディングスタイルでおそらく最も一般的なものです。
データフロー方式の記述を理解するためには、次の2つのステップが必要となります。
- コードから回路構成を理解する。
- 回路構成から機能を理解する。
しかし、これらは簡単ではありません。
なぜなら、データフロー方式には次のような特徴があるからです。
- 単純なprocessやstatementが無数に点在し、記述された順序で実行されず、特定の入力信号が変化すると特定の文が実行される
- 処理の流れを追うのが困難
- 解読指針は信号の識別子のみ
- 回路図なら書かれている信号線のつながりが見えない
- 結局、回路図のような接続図を作って依存関係を探ることも珍しくない
- 実装の抽象度が低い
- 何を意図して記述した文なのか把握しにくい
- アルゴリズム全体を把握してデバッグすることが困難
2プロセス方式 (two-process method, TP)
データフロー方式の問題点を克服するために2プロセス方式のコーディングスタイルが提案されており、次のような利点があります。
(シミュレーション上の利点もありますが、ここでは触れません。)
- 一様なアルゴリズム記述
- 抽象化レベルの向上
- 可読性の向上
- シーケンシャルロジックの明確化
- デバッグの簡易化
上記を実現するために、
2プロセス方式のコーディングスタイルでは、次の方法をとります。
- モジュール毎に2つのプロセスのみを使用する
- 関数化可能な逐次実行でアルゴリズムを記述する
- 構造体およびインターフェースを積極的に使用する
SystemVerilogを2プロセス方式で書く
モジュール毎に2つのプロセスのみを使用する
HDLとCなどの一般的なプログラミング言語の最大の違いは、プログラムが記述された順序で実行されないことです。HDLでは複数のプロセスおよびステートメントが同時に実行されます。これは実物のハードウェアのデータフローの動作を表しています。しかし、同時に実行される処理が一定数を超えると、理解および分析が難しくなります。
一方でプログラムが上から順に逐次実行されるプログラミング言語では、ある程度の規模のプログラムであってもアルゴリズムを理解、分析することができます。
HDLにおいて、読みやすさを向上させ一様なアルゴリズム記述を行うために2プロセス方式ではモジュール毎に次の2つのプロセスのみを使用します。
- combinational process
- 非同期式組み合わせ回路
- アルゴリズムのみを逐次実行で記述する
- sequential process
- 同期式順序回路
- 状態保存のみ行う
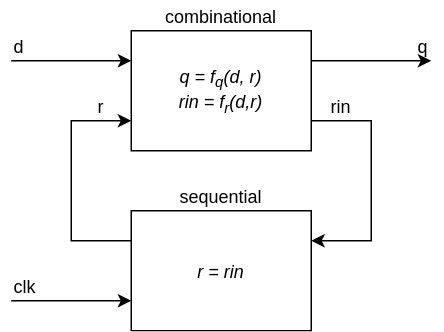
上の図が2プロセス方式の一般化したブロック図です。
モジュールの入力dおよび出力qはcombinational processに接続されます。
sequential processへの入力rinはcombinational processによってドライブされます。
sequential processではクロックclkのエッジでrがrinに更新されます。
combinational processの機能は次の2式で表すことができます。
\begin{eqnarray*}
q = f_q(d, r)\\
rin = f_r(d, r)
\end{eqnarray*}
SystemVerilogで2プロセス方式に対応した8ビットカウンタを書くと次のようになります。
module counter8 (
input logic clk,
input logic load,
input logic count,
input logic unsigned[7:0] d,
output logic unsigned[7:0] q
);
logic unsigned[7:0] r, rin;
// combinational process
always_comb begin
if (load) begin
rin = d;
end else if (count) begin
rin = rin + 1;
end else begin
rin = r
end
q = r;
end
// sequential process
always_ff @(posedge clk) begin
r <= rin;
end
endmodule
SystemVerilogでは順序回路、組み合わせ回路をそれぞれalways_ff, always_combで明確に区別できるので利用するとよいです。
特にalways_combはセンシティビティリストを記述する必要がなくなるため、記述ミスの削減につながります。
また、VHDLではprocess内で順次処理を行うためには中間変数をvariableで宣言する必要がありますが、
SystemVerilogではブロッキング代入を使用すれば必要ありません。
構造体およびインターフェースを積極的に使用する
上記の8ビットカウンタは単純で、ポートと信号数が限られているため非常に読みやすいです。
ただし、複雑なIPブロックではインターフェースリストが多数の信号で構成されます。
信号の構成が複雑になってくると次の問題が発生します
- 信号と機能の依存関係の理解が難しくなる
- 信号の追加、削除が難しい(想定外の機能に影響がでる, etc...)
- 信号の追加、削除時の編集が面倒になる
- 信号宣言、接続ポートの追加、削除を手動で行う必要がある。
SystemVerilogではinterfaceを使うことでインターフェースの多数の信号を機能ごとにまとめることができます。
これには次のメリットがあります。
-
interfaceで信号を機能ごとにまとめる- 信号と機能の依存関係が明確になる
- 信号の追加、削除は
interface上のみで行う-
interfaceの変更は全てのモジュールに自動的に反映される - 時間がかかりエラーが発生しやすい手動編集を行う必要がなくなる
-
インターフェースについてはデータフロー方式でも広く利用されています。
また、レジスタの追加、削除についても同様に次の問題が発生します。
- レジスタの追加と削除の編集が面倒になる
- レジスタの入力と出力、両方の宣言を手動で編集する必要がある。
SystemVerilogではstructを使うことでレジスタの入出力rおよびrinを構造体にすることができます。
これには次のメリットがあります。
-
structの変更が全てのレジスタに反映される- 時間がかかりエラーが発生しやすい手動編集を行う必要がなくなる
interface counter8_interface;
logic load;
logic count;
logic unsigned[7:0] din;
logic unsigned[7:0] dout;
logic zero;
modport counter_in(
input load, count, din,
);
modport counter_out(
output dout, zero
);
endinterface
module counter8 (
input logic clk,
counter8_interface.counter_in d,
counter8_interface.counter_out q
);
typedef struct packed{
logic load;
logic count;
logic zero;
logic unsigned[7:0] cval;
} reg_type;
reg_type r, rin;
// combinational process
always_comb begin
// default assignment
rin = r;
// overriding assignment
rin.load = d.load;
rin.count = d.count;
rin.zero = 1'b0;
// module algorithm
if (r.count) rin.cval = r.cval + 1;
if (r.load) rin.cval = d.data;
if (rin.cval == 0) rin.zero = 1'b1;
// drive module output
q.dout = r.cval;
q.zero = r.zero;
end
// sequential process
always_ff @(posedge clk) begin
r <= rin;
end
endmodule
combinational processの先頭にあるrin = rによって、processの開始時に現在のレジスタ値rがレジスタ入力rinに割り当てられます。
これによって、プロセス中で更新されないrinの要素は現在のレジスタ値が維持されます。つまり、レジスタ値は変更されません。
レジスタ信号rおよびrinを構造体にすることで、レジスタの要素を変更してもsequential processのr <= rinを変更する必要はありません。
多くのレジスタを持つ大きなモジュールでは、関連するレジスタを個別の構造体で定義することで、読みやすさが向上します。これは同じタイプの複数のレジスタを使用する場合に特に役立ちます。
typedef struct packed{
logic par;
logic frame;
logic ready;
logic [7:0] data;
} uart_rx_reg_type;
typedef struct packed{
logic par;
logic ena;
logic empty;
logic [7:0] baud;
} uart_tx_reg_type;
typedef struct packed{
uart_rx_reg_type [3:0] rxregs;
uart_tx_reg_type [3:0] txregs;
} reg_type;
reg_type r, rin;
クロックとリセット
上記の例では、クロック信号はinterfaceに含まれていません。
これには次の2つの理由があります。
- クロックをグローバルバッファ等で低スキューで分配するため
- 多くの場合、ベンダーツールで構造体中のクロックのタイミングを解析できないため
また、クロックと同じ理由でリセットもinterfaceに含まれていません。
ただし、同期リセットの場合はクロック同期で動作するためinterfaceに追加しても問題ありません。
2プロセス方式では、同期リセットと非同期リセットの両方を使えますが、書き方が異なります。
同期リセット
同期リセットは他の入力信号と同様にcombination process内で使用されます。
リセット処理をプロセスの最後に配置することで、他の処理より前に優先順位がつけられます。
module counter8 (
input logic clk,
input logic rst,
counter8_interface.counter_in d,
counter8_interface.counter_out q
);
// ...
// combinational process
always_comb begin
// default assignment
rin = r;
// overriding assignment
rin.load = d.load;
rin.count = d.count;
rin.zero = 1'b0;
// module algorithm
if (r.count) rin.cval = r.cval + 1;
if (r.load) rin.cval = d.data;
if (rin.cval == 0) rin.zero = 1'b1;
// reset condition
if (rst) begin
rin.cval = '0;
rin.zero = 1'b0;
end
// drive module output
q.dout = r.cval;
q.zero = r.zero;
end
非同期リセット
非同期リセットは、クロックに関係なく状態(レジスタ)に影響するため、sequential processに接続する必要があります。
クロックに関係なくリセットが発生するため、リセット信号はsequential processのセンシティビティリストに追加する必要があります。
// sequential process
always_ff @(posedge clk, posedge rst) begin
if (rst) begin
r.cval <= '0;
r.zero <= 1'b0;
end else begin
r <= rin;
end
end
まとめ
2プロセス方式はVHDLで提案された手法ですが、基本的な考え方は言語に依存しません。
しかし、Verilog-HDLでは構造体やインターフェースがないため、
2プロセス方式で書くメリットはほぼありませんでした。
SystemVerilogでは、多数の機能が拡張されたため、
2プロセス方式の恩恵を十分に受けることができるようになっています。
参考
- two-process method
- SystemVerilog
更新
- 2020/2/28
- counterのinterfaceを統合