どうも ryo_grid です。
今回は自作RDBMS SamehadaDB の開発の中で、インデックスとして用いるためのコンテナとして、オンディスク並行Skip Listなるものを作ってみたので、それについて書きたいと思います。
(以降、文体が変わりますが気にしないで下さい)
はじめに
- 本文書は筆者がオンディスク並行Skip Listを設計・実装してみた中で得た、知識や知見の共有を目的とするものである
- 英文のものも含め、Skip Listに関して、本文書で共有する種の情報がまとまった形で提供されているWebページ(等)は、筆者が探した範囲で見当たらなかったので、その点で、価値のある知識・知見として、多くの人の役に立てば幸いである
Skip Listについて
Skip Listとは
- いわゆる Key-Value ストアを実現する確率的なデータ構造
- 他の同様の機能性を提供するデータ構造に対し、”確率的”というところが特徴的
- O (log N) でデータの探索(取得)、挿入、削除が可能
- ※logの底は設計により変化させられるが、多くは2か4。筆者は2となるよう設計
-
B+ tree などと同様、ストアされているデータを、Keyとして用いているデータの大小(の定義)に基づきソートされた順序で効率的に取り出せる
- ex) A < B なKey-AおよびBがあった時に、 A <= x <= B を満たすxをKeyとして格納されているValueをKeyの昇順で取り出す、といったことが可能
- データ構造の概要
- 基本的には単なる連結リストであり、線形探索で所望のエントリを保持しているノードに辿りつける
- ただし、Skipと名に冠しているように、ノードを作成する際、一定の確率で、いくらかのノードをスキップしていけるパスを作る
- 結果的に、電車で始発駅から特急、急行、普通、各停と順に乗り継ぎながら目的地に移動するようなイメージになる
- 上記の例えに合わせると、パスを作るというのは各々の異なる運行の電車に停車駅と認識させるイメージになる(各停から特急と運行があるうち、どこまでに停車駅と認識させるかが確率的に決定されることになる)
- 各運行はレベルという値で区別され、(確率的に)停車駅の数はレベルの高いものの方が少なくなる。各駅停車となるレベルは本文書ではレベル1とする
- 詳細はWikipediaの スキップリスト のページ等を参照されたい
- 下の画像は上記Wkipediaのページより
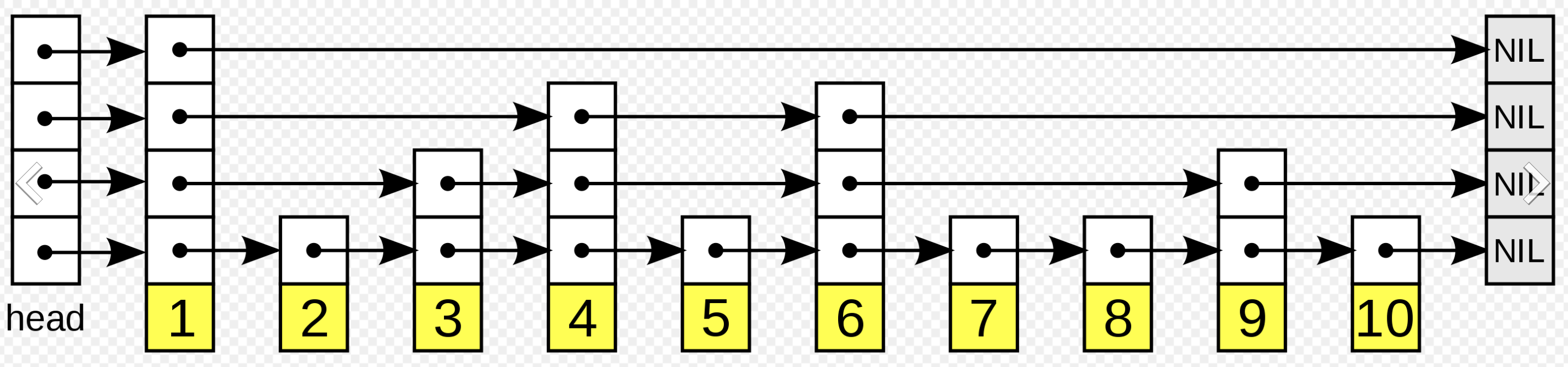
- 下の画像は上記Wkipediaのページより
Skip Listの良いところ
- B+ tree などとおおむね同等の機能性・アクセス時性能を提供可能でありながら、比較的実装がシンプルで済む
- B-tree系
- B-tree系のデータ構造は、Balanced treeなので、木構造の中でのデータの分布に偏りが生じた場合、リバランスと呼ばれる処理が行われる
- ノードのsplitとmerge と呼ばれる内部処理(もしくはそれと同様の目的が達成できる別種の処理)が、必要に応じて行われる
- 基本的には更新操作であるデータの挿入と削除の際にリバランスが発生するが、削除の際のmerge処理の実装は特に複雑になりがち
- 特別な設計をとっていない限り、リバランスの処理が木における局所的な更新でなく、広範囲に渡る更新となる場合を考慮した実装が必要
- Skip List
- Skip Listのベースは単なる連結リストであり、リバランスも行わないため実装は比較的シンプル
- ノードのsplitと削除は必要だが、mergeは無くても問題ない
- Skip Listのベースは単なる連結リストであり、リバランスも行わないため実装は比較的シンプル
(本文書における)オンディスク 並行Skip Listとは
- オンディスクで
- 基本的にメモリ上にデータが存在したまま操作され続けるものをオンメモリな〇〇と呼ぶとする
- オンメモリな〇〇に対し、オンディスクな〇〇は、格納データを扱う部分要素(B-tree系やSkip Listではノード)がSSDやHDD等の不揮発なストレージに書き出されたり、逆にメモリ上にロードされるなど居場所を変える
- メモリ上にキャッシュ領域を設けるなどして、全体がメモリ容量に収まらないサイズのデータ群を効率よくあつかえるよう設計されたもの、と言ってもよいかもしれない
-
並行(≒並列)アクセス可能な
- データ構造内部で部分的なロックをとらせる設計により、データの整合性を保ちながら複数のスレッドが(可能な限り)同時にデータ構造にアクセスできるようになっている
- <=> データ構造全体を単一のロックで制御すると、1スレッドしか同時にはアクセスできない
- Skip List
Skip Listの良いところ(並行アクセス対応観点)
- 並行アクセスへの対応も比較的シンプルで済む
- 本文書では排他制御のためのロックはノード単位で行うものとする
- (B-tree系ではツリーロックを用いる場面もあるかもしれないが基本は同様)
- B-tree系
- リバランスを適切に排他制御しながら行うコードは複雑(難解)なものとなる
- リバランスのための更新範囲が広範囲にわたる場合へ対応が必要
- デッドロックが起こらないように注意しながらロック獲得する必要があるが、その順序自体が難解になりがち
- Skip List
- 難所の複雑度がB-tree系より低い
- 両者とも更新操作の多くは、排他制御を行いながら、データの挿入・削除処理を行うノードを探索し、発見したノードの内容を適宜更新し処理を終える
- 実装が大変なのは、あるノードを更新しようとすると他のノードの更新も行わなければならなくなるケースだが...
- B-tree系ではリバランスの必要性からもノードのsplitとmergeが発生する
- Skip Listではエントリを保持させようとするノードの空き領域が無かった場合にsplit、ノード内のエントリが0個となった場合にノード削除が発生するが、リバランスを行わないため、行われる処理は比較的シンプル
- 必要となる処理にはノード間の接続情報の更新と保持するエントリのノード間での移動があり、Skip Listでもsplitでエントリの移動が発生するが、移動先は新規ノード(隣接ノードとなる)に限定され局所的な範囲に留まる
- Skip Listのベースはあくまで1本のノードの連結リストであり、追加・削除はあっても位置が入れ替わることはないため、排他制御を行う際のロック獲得の順序は上述のリストにおける並び順に照らして考えればよくシンプル
- 難所の複雑度がB-tree系より低い
(単純な)Skip Listの良くないところ
- 確率的なデータ構造であり、かつリバランスを行わないため、log N ステップでアクセスできないことはB-tree系と比べれば多いと思われる
- 並行アクセス時のパフォーマンスがB-tree系と比べて出しにくい(はず)
- (並行アクセス対応のセクションを読んでから戻ってきた方がよいかもしれない)
- どちらも同一の始点から全スレッドが探索をスタートする点は同じであり、同じルートを通るスレッドのうちの1つが先んじてそのルート上のノード(木構造の場合は節?)のWロックをとってしまうと、ロック競合で並列アクセス時のスループットが落ちる点も同じ
- しかし、Skip ListはあるスレッドがあるノードのWロックをとると、そのノードのレベル(高さ)までのレベル全てにおいて、当該ノードを通過したい他のスレッドがロック獲得待ちでブロックしてしまう
- 木構造の場合のように節とリーフのロックが分離されていないことが根本的な違い?
- B-tree系についてはリバランスを行う際にアクセス不可になる領域が生じることも勘案しないといけない気もするが
- ページキャッシュとの相性がB+treeなどと比べると悪い
- エントリのレンジスキャン(範囲指定してのイテレート)が設計時に決めた方向でしか行えない
- 両方向で可能ともできないことはないだろうが、あまり処理効率を低下させずに実現しようと思うと、ロジックの複雑度が(並行アクセスに対応したものでは特に)大きく増すのではないかと思われる
筆者の作成したオンディスク並行Skip Listの仕様・設計等についての解説
開発の背景
- RDBの自作を行う中で、メジャーなRDBで広く利用されているB-tree系インデックスを実装しようと考えたが、ここまでに説明したようにB-tree系のインデックスを並行アクセスも可能なところまで作り込もうとすると非常に難易度が高いことを知り、その代替とできるSkip Listなインデックスを実装すべく、同インデックス内部で用いるコンテナを作成した
- このため、実装は筆者がメイン開発者である SamehadaDB のコードベース内に存在
- 【参考】Google Chrome等でも利用されているLevel DB(オンディスクKVS)は(ディスク上でなく)メモリ上のエントリデータへのアクセス効率化のためのインデックス(オンメモリ)においてSkip Listを採用していたりする
- 従って、解説するものは、RDBのインデックスとして用いる目的で仕様決定・設計されているため、その目的に引っ張られているところもあると思われる
- とはいえ、おおむね汎用的な設計とはなっており、また多くの部分は閲覧者が変更や拡張することも難しくないはず
外部仕様
- 注意点
- 意図的なものではなく、単に詳細設計が終わっていないために仕様となっているものもある
- 筆者の実装において記述の通りとなっていないところもある
- 本文書は構成法に関する知識・知見の共有を目的としており、それらは筆者の実装と必ずしも一致している必要がないため
- 本文書で疑似コードの形で説明を行う場合はGo言語ライクのシンタックスを用いる
- 前提
- データは Key:数値・文字列等 -> Value:数値・文字列等 のマッピングで扱い、このペアをエントリと呼ぶ
- (説明の都合から)複数のデータ形式を表現でき、各々について比較関数(任意)、byte列との{デ,””}シリアライズ、を提供する型(本文書では以降KV型と呼ぶ)が存在することを前提とし、KeyおよびValueはKV型で統一的に扱う
- KV型において表現可能となっていれば任意のデータ形式に対応可能だが、Keyとして用いるデータ形式については大小比較が実装されている必要あり
- Keyのデータ形式はSkip Listのインスタンス作成時に指定した一種に固定される
- KeyはUniqueなものとして処理される。比較関数で同値と判定されるKeyを持つ複数のエントリは共存できない。例えば、同一キーのエントリをInsertした場合はValueの上書きが行われる(Insert = UPSERT)
- 余談: RDBのインデックスで用いるコンテナとしては、Key-> Value ではなく、Key -> [Value] の形で利用可能でないと使い勝手が悪いため、近いうちに拡張の予定
- 元々のKeyとValueをCompareable Formatと呼ばれる形式で結合(下では++と表記)したものをKey'とした上で、Key' -> Value とすることで、Key -> [Value] と拡張させられる
- 元々のKeyに対応するValue群を取りだす場合はKey ++ Valueの値域の下限 から Key ++ Valueの値域の上限をKeyとして指定してIteratorを生成すれば良い
- 特定のKey-Valueの組み合わせを削除する際は、Key'でRemoveを行えば良い
- 特定のKeyのエントリを全て削除したい場合は、上述の方法で全て取り出してから一つづつ削除
- ただし、後述だがIterator関数が他の操作に対してアトミックではなく、また、そのため、Iteratorで得た値を使って何等かの操作をするケース(上述の特定のKeyのエントリ全削除のケースなど)についても本文書に記述の内容だけではアトミックにならないので注意が必要である
- 余談: RDBのインデックスで用いるコンテナとしては、Key-> Value ではなく、Key -> [Value] の形で利用可能でないと使い勝手が悪いため、近いうちに拡張の予定
- データは Key:数値・文字列等 -> Value:数値・文字列等 のマッピングで扱い、このペアをエントリと呼ぶ
- 提供する操作
- エントリの取得
- SkipList::Get(key *KV) *KV
- 取得に成功した場合は返り値がValueの内容となり、失敗した場合はnullが返る
- SkipList::Get(key *KV) *KV
- エントリの挿入(更新)
- SkipList::Insert(key *KV, val *KV) bool
- 返り値は操作の成功・失敗の真理値
- SkipList::Insert(key *KV, val *KV) bool
- エントリの削除
- SkipList::Remove(key *KV) bool
- 返り値は操作の成功・失敗の真理値
- SkipList::Remove(key *KV) bool
- イテレータの取得と、取得したイテレータを用いたレンジスキャン
- SkipLisr::Iterator(start *KV, end *KV) *SLItr
- startにはスキャン範囲の下限、endには上限を渡す。start、endのいずれもnullを渡すと、そちら側は無指定と解釈される
- SLItr型は昇順にソートされたValueを1つづつ返すイテレータ。返す内容はIterator関数の呼び出し時にSkip Listを指定されたレンジでスキャンして得られたValue群
- ただし、スキャンは他の操作に対しアトミックに行われないため、Iterator関数を呼び出した瞬間のスナップショットとなることは保証されない
- SkipLisr::Iterator(start *KV, end *KV) *SLItr
- エントリの取得
内部設計
- オンディスク対応
- ノードはページと呼ぶディスク上の永続化用ファイル内のブロック(固定長)と対応づけて扱う
- 例えば、排他制御のためにノードのロック獲得・解放を行うが、それはページに対するそれを行うことと基本的にはイコールである
- ページは各々がユニークなページIDを持つ
- ページのデータはページマネージャと呼ぶコンポーネントを介して取得し、アクセスを終えたら同マネージャに対して使用を終えた旨を通知する
- ページマネージャは内部にメモリ上のバッファ(ページのキャッシュ領域)を持っており、個々のページは必要に応じて当該バッファ上にロードされるが、他のページを利用するために領域確保の必要があればディスクに書き出される、という遷移を繰り返す
- ページ(注: OSのメモリ管理機構におけるページとは別物)
- Page型
- 対応するページのページIDをメンバ変数に保持
- あるページA(ページID=>A)に対応するインスタンスがメモリ上に存在する場合、ページAに対応するインスタンスは1つのみ存在するよう制御し、プログラム中でページAを操作する場合、同一のインスタンスへの参照を共有した形でアクセスする
- Read-Writeロックが可能(メンバとして対応するMutexを持つ)
- ピンカウントと呼ぶカウンタをメンバに持ち、それが0の場合、利用しているスレッドが存在しないことを意味し、ページマネージャはディスクへキャッシュアウトしてよいページと認識する
- メモリ上にロードされているページデータの領域への参照を持つ
- 対応するページのページIDをメンバ変数に保持
- Page型
- ノードはページと呼ぶディスク上の永続化用ファイル内のブロック(固定長)と対応づけて扱う
- ページマネージャ(以降PMと呼称)
- PMは以下のI/Fを提供するものとする(※挙動は以下に記述のところだけ規定)
- PageManager::NewPage(newPage *Page) int32
- 新たなページを生成し、割り振られたページIDとPage型の実体への参照を返す
- ページのピンカウントは1となっているものとする
- PageManager::DeallocatePage(pageId int32)
- 指定されたIDに対応するページをNewPageで返すことのできる空きページのリストに加える
- 永続化用ファイルの対応する領域も再利用可能とする
- 一度DeallocatePageに渡されたページIDは再利用されない
- Deallocate済みのページIDでFetchPageしてもnullが返る
- 指定されたIDに対応するページをNewPageで返すことのできる空きページのリストに加える
- PageManager::FetchPage(int32 pageId) *Page
- ページのIDを渡すと、メモリ上にキャッシュされていればその領域、されてなければバッファ内にディスクからデータを読み込んだ上でのその領域、へのデータを紐づけたPage型オブジェクトを返す
- メモリ上にもディスク上にも存在しないページIDを渡された場合はnullを返す
- ページはピンカウントを+1した上で返す
- PageManager::UnpinPage(pageId int32, isDirty bool)
- 渡したページIDに対応するページへのアクセスの完了をPMに通知する
- isDirtyフラグはページの内容を書き換えていた場合にtrueとする
- キャッシュ処理の効率化のためのヒント情報
- 対応するページのピンカウントを-1する。ピンカウントが0となったページはキャッシュアウト可なページとPMは認識する
- 複数スレッドがページにアクセスしている場合、あるスレッドがUnpinPageしたからといってピンカウントが0になるとは限らない
- PageManager::NewPage(newPage *Page) int32
- 参考
- PageManagerの内部設計が気になる方は下のCMUのオープンコースウェアな講義のスライドなど参照されたし
- 注:この講義では Buffer Pool と呼んでいる
- 講義の詳細はリポジトリのトップを参照のこと
- 03-storage1.pdf
- 04-storage2.pdf
- 05-bufferpool.pdf
- PageManagerの内部設計が気になる方は下のCMUのオープンコースウェアな講義のスライドなど参照されたし
- PMは以下のI/Fを提供するものとする(※挙動は以下に記述のところだけ規定)
- ノード
- Node型
- Page型の実体への参照を持ち、それを介す形でRead-Writeロックが可能
- 同様にページデータ領域へのアクセスが可能であり、ページに格納されている・されるメタデータやエントリデータに関するgetter/setter相当のI/F群を提供する
- メンバは上述の1つだけであり、その他のデータはページデータ領域に存在するため、それらへは上述のI/F群が行う{デ,””}シリアライズを介してアクセスする
- ほとんどの場合、複数のエントリを格納している
- Node型
その他の重要なところ
- 制約
- 1エントリのサイズ上限はページサイズからページのヘッダ領域および、KV型をシリアライズした際に必要となるメタデータ領域のサイズを減じたものとなる
- 上記を踏まえて、仕様としてのサイズ上限を考える場合、1ノード全てを占めるエントリを許すことも可能であろうが、後述するsplit時に新規ノードを2つ作らないと収まらないケースなどの考慮が必要となり、処理が複雑化するはずで、現実的にはページサイズの半分弱程度を最大サイズとするのが無難かと思われる
- 1エントリのサイズ上限はページサイズからページのヘッダ領域および、KV型をシリアライズした際に必要となるメタデータ領域のサイズを減じたものとなる
- データストアとして補足しておくべき点
- トランザクションはサポートするか?
- => サポートしない
- (元々RDBのインデックスに用いるコンテナとして開発したものであるため。RDB本体に組み込んだ場合はそちらのトランザクションの仕組みにより実現はできている)
- Logging/Recoveryはサポートするか?
- => サポートしない
- 従って、プログラムの終了が正常終了ではなく、クラッシュなどでPM内のdirtyなページをディスクに全て書き出すことができずに終了してしまった場合、永続化されていないエントリが発生し得る
- (RDBに組み込んだ際でも未対応だが、こちらについてはRDB本体の仕組みと連携しつつ実装の予定。現時点ではreboot時に再構築するようになっている)
- トランザクションはサポートするか?
オンディスクなものだと何故大変か(になったか)
続く説明に先立ってまとめておく
- 1ノードが複数エントリを含む構造であるため
- オンメモリ実装では通常、1ノードを1エントリに対応させる形で実装する(後述)
- 対して、解説するものは1ノードに複数エントリを含む構造とする必要がある
- OSのページサイズを考慮した(ランダムアクセスより効率的な)シーケンシャルなディスクI/O、主記憶と比べて低速なディスクI/Oを可能な限り隠蔽するためのデータキャッシュを行うために、ページ単位でデータを扱う必要がある
- ページのサイズは近年のOSのデフォルト設定を踏まえると4KBよりは大きくする必要があり、結果として、ページ内に複数エントリを格納する形の設計が合理的となる
- しかし、複数エントリを含む構造となると、単純にロジックの拡張が必要となることもあるが、1対1対応であればシンプルに済む処理がそうでなくなってしまうケースがしばしばあった
- オンメモリのSkip Listを並行アクセス可能とする手法については情報があった(後述)が、上述の通り、データ構造が異なるため、適用にあたって追加の考慮が必要となった
ロジック周りの設計他
ベースとした Skip List のアルゴリズム(=オンメモリ実装)
- ACM ICPC Maraton Prague 2015 の入賞チームのスライドで解説されているロジックを下敷きとさせてもらった
- https://cw.fel.cvut.cz/old/_media/courses/a4b36acm/maraton2015skiplist.pdf
- ただし、このスライドで解説されているものはオンメモリでの実装であり、各ノードは1エントリと対応づいたものとなっている
- 並行・並列アクセス可能なものでもない
- 以降では"ACM ICPC Maraton Prague 2015 の入賞チームのスライド" で紹介されている実装についての理解を前提とする
- 以降での内容の理解のために特に重要な点
- どのようなコードで先頭ノードからノードを辿り探索対象のノードに辿りつくか
- ノードを辿っていく過程でどのような情報を記憶しているか
- => 乗り換えたノードへの参照のリスト
- ノードの追加や削除で何が必要となるか
- => 辿っていく過程で乗り換えたノードと、レベル1での直前のノードが各レベルで接続している次ノード(=forwardメンバ)の情報の更新
- 以降での内容の理解のために特に重要な点
1ノードが複数エントリを保持する形への拡張(対オンメモリ実装、データ構造について)
- 本文書でいうところのオンディスク版にしようと思うと、1ノードを1ページに対応づける形になるため、自然と複数エントリを保持する設計となる
- 各ノード(Node型)は以下を提供すれば良い(1対1対応でも必要であったもの含)
- (ノード内でもエントリがKeyでソートされた状態となっている、を維持する前提で)
- Key(及び必要な操作であればValue)を指定してのエントリの取得・削除・追加
- エントリがKeyでソートされていることで二分探索が可能となり、ノードの探索以降の処理まで含めても、全体の処理時間は O (log N) とできる
- 取得処理では、存在しなかった場合でも指定したKeyより小さなKeyを持つエントリのうち最も近い値を持つエントリを返す
- Iteratorの実現のために必要
- ノード内で最小のKeyを持つエントリの取得
- なお、エントリを返しても、利用されるのはKeyのみではある
- ノードのレベル取得
- 作成された際に設定された値
- 指定したレベルにおいて、次ノードとして接続している(する)ノードのページIDの取得・設定
- 取得・設定が可能である必要があるのは、レベル1からノードのレベル、まで
【参考】SamehadaDB内に存在する実装におけるノードのデータレイアウト
※用途の都合からValueは4バイトの固定長になっている. LSNは現状、後述の更新カウンタとしてだけ利用している

1ノードが複数エントリを保持する形への拡張(対オンメモリ実装、ロジックについて)
- ここではGo言語によるコード例も適宜用いて解説する
- ここで解説するものは並行(並列)アクセスは考慮していない段階のものである
- 拡張方法が自明なところについては説明を省略する
- ノードの探索処理
- コード中に [番号] というコメントを入れてあるので、その各々について解説する
- FindNodeの呼び出し終了時に、返り値foundNodeのピンカウントは+1された状態となっている
findnode_serial.go
// Page型のポインタをNode型のポインタにキャストするユーティリティ関数
func FetchAndCastToNode(pm *PageManager, pageId int32) *Node {
fetchedPage := pm.FetchPage(pageId)
return (*Node)(unsafe.Pointer(fetchedPage))
}
// 引数
// key: 探索対象のエントリのKey
// opType: FindNode関数を何の目的で呼び出したかを示す定数. GET, INSERT, REMOVEのいずれかに対応する定数を渡す
// 返り値
// isSuccess: 探索が成功したか(このコード例ではtrueしか返らない)
// foundNode: 探索の結果発見したノードへのポインタ. foundNodeノードに対応するエントリが存在する可能性があるというだけで、存在は保証しない
// predOfCorners_: 各レベルで"乗り換え"を行ったノードに至った際に、そのノードに接続している1つ前のノードのページID. インデックスは(レベル - 1)となっている
// corners_: 各レベルで"乗り換え"を行ったノードのページID. レベル1の値はfoundNodeと対応する. インデックスは(レベル - 1)となっている
func (sl *SkipList) FindNode(key *KV, opType SkipListOpType) (isSuccess bool, foundNode *Node, predOfCorners_ []int32, corners_ []int32) {
pred := FetchAndCastToNode(sl.pm, sl.HeadNodeID)
predOfPredId := int32(-1)
predOfCorners := make([]int32, MAX_FOWARD_LIST_LEN)
// entry of corners is corner node or target node
corners := make([]SkipListCornerInfo, MAX_FOWARD_LIST_LEN)
var curr *Node = nil
for ii := (MAX_FOWARD_LIST_LEN - 1); ii >= 0; ii-- { //[1]
for { //[2]
curr = FetchAndCastToNode(sl.pm, pred.GetForwardEntry(int(ii)))
if !curr.GetSmallestKey(key.ValueType()).CompareLessThanOrEqual(*key) { // !(key >= curr.GetSmallestKey())
// (ii + 1) level's corner node or target node has been identified (= pred)
break
} else {
// keep moving foward
predOfPredId = pred.GetPageId()
sl.pm.UnpinPage(pred.GetPageId(), false)
pred = curr
}
}
if opType == SKIP_LIST_OP_REMOVE && ii != 0 && pred.GetEntryCnt() == 1 && key.CompareEquals(pred.GetSmallestKey(key.ValueType())) {
// [3]
// pred is already reached goal, so change pred to appropriate node
predOfCorners[ii] = int32(-1)
corners[ii] = predOfPredId
sl.pm.UnpinPage(curr.GetPageId(), false)
sl.pm.UnpinPage(pred.GetPageId(), false)
// go backward for gathering appropriate corner nodes info
pred = FetchAndCastToNode(sl.pm, predOfPredId)
} else { //[4]
sl.pm.UnpinPage(curr.GetPageId(), false)
predOfCorners[ii] = predOfPredId,
corners[ii] = pred.GetPageId()
}
}
return true, pred, predOfCorners, corners
}
-
[1] Skip List全体のレベルにおける上限値(MAX_FOWARD_LIST_LEN)のレベルからレベル1に向かって辿っていくためのループ
- 筆者の実装では上限値は20とした
- ノードのレベルを決定する関数でのprobablility P は 0.5 としたが、その前提で 2^20 程度のノードまで問題なく動作するよう設定
- オンメモリ実装ではSkip List全体での"最も高いレベル"を保持・更新しておき、そのレベルから探索を開始していたが、並行アクセス対応まで行う際、"最も高いレベル"を常に適切に更新し参照可能とすることは困難となるため、逐次実行では無駄な処理が発生することになるが上限レベルから探索を開始するようになっている
- 筆者の実装では上限値は20とした
-
[2] レベルii で乗り換えするノードを線形探索していくループ
- 探索対象のキーと各ノードの最小Keyを比較していく。エントリは昇順に保持されるよう設計されているため、探索対象のKeyより最小Keyが大きいノードにぶつかった時点で、そのノードの一つ前のノードを乗り換えするノードとし、ループが終了する
- 上述のぶつかったノードまで進むと行き過ぎになるので、1つ前のノードで下のレベルに乗り換える、ということ
- 探索対象のキーと各ノードの最小Keyを比較していく。エントリは昇順に保持されるよう設計されているため、探索対象のKeyより最小Keyが大きいノードにぶつかった時点で、そのノードの一つ前のノードを乗り換えするノードとし、ループが終了する
-
[3] ノード削除が発生することが判明した際の考慮
- 乗り換えノードを発見したあとに行われる処理
- 行おうとする操作がremoveであり、かつ辿ったレベルが1より大きく、かつ発見した乗り換えするノードの保持するエントリ数が1で、かつそのエントリの値が探索対象のキーと一致した場合に通るルート
- このルートは結果的にノード削除を行うことになるケースで、かつ、探索対象のノードにレベル1より上でたどり着いてしまったケースの考慮
- ノード削除を行う際はノード間の接続関係の更新が発生するが、このケースで考慮なく処理を継続すると、削除を行うノードでレベル1まで乗り換えを行ってしまうために、predOfCornesリストに格納されない、削除対象のノードに接続しているノードが出てきてしまい都合が悪い
- そこで、[3]のルートでは、今いるレベルでの乗り換えするノードを1つ前のノードに変え、上記の問題が発生しないようにする
-
[4] 通常の場合のループの1周を終える際の処理([3]でも同様のことは行っている)
- 行き過ぎであったノードであるcurrはもうアクセスしないので、UnpinPageしておく
- 乗り換えノードのページIDをcorners、乗り換えノードの一つ前にいたノードのページIDをpredOfCornersに格納
-
ノードを見つけて以降の処理について
- Get
- 基本的には、返り値foundNodeが示すノードが提供するエントリ取得のI/Fを呼び出してその結果を返り値とするだけ
- 二分探索によりノード内の探索を行う(他の操作でも同様)
- 存在しない場合もある
- 最後に、アクセスを終えたfoundNodeが示すノードを引数にPageManager::UnpinPageを呼び出す(dirtyフラグ=false)
- 基本的には、返り値foundNodeが示すノードが提供するエントリ取得のI/Fを呼び出してその結果を返り値とするだけ
- Insert
- 基本的には、返り値foundNodeが示すノードが提供するエントリ追加のI/Fを呼び出してその結果を返り値とするだけ
- 大半の場合はエントリがノード内の適切な位置に挿入されて処理を終えるが、ノード内に十分な空き領域が無かった場合はsplitが行われる
- split
- PageaManager::NewPageで新規ノード(ページ)を作成
- 新規ノードのレベルはNewPageの呼び出し後に、レベルを決定する関数(オンメモリ版のコード例参照)を用いて得た値とする
- 新規ノードは元々追加しようとしていたノード(ここでは以降親ノード)の(レベル1における)次のノード(隣接ノード)とする
- ノードの接続関係の更新
- 新規ノードのレベルの高さまで接続関係を更新する
- レベル1においては、親ノードの接続先を新規ノードとし、新規ノードの接続先を親ノードが接続先としていたノードとする
- 他のレベルにおいてはFindNodeの返り値corners_内に保持されている探索過程で通ってきた乗り換えノードを参照し同様にすればよい
- 格納されているのはページIDであるためPageManager::FetchPageでノードを取得し、接続先の更新も含めたアクセスを完了したらPageManager::UnpinPageを呼び出す(dirtyフラグ=true)
- エントリの移動
- 基本的には、新規ノードに親ノード内に存在するエントリの後ろ半分を移動する
- データ領域のサイズで見た時の半分になるべく近くなるよう移動するエントリを決定する
- 半分移動させるのでは追加しようとするエントリが収まらない場合は適宜計算して移動する
- 基本的には、新規ノードに親ノード内に存在するエントリの後ろ半分を移動する
- エントリの追加
- 親ノード、新規ノードの適切な方のノードにエントリを追加する
- 新規ノードを引数にPageManager::UnpinPageを呼び出す(dirtyフラグ=true)
- PageaManager::NewPageで新規ノード(ページ)を作成
- 最後に、アクセスを終えた親ノードを引数にPageManager::UnpinPageを呼び出す(dirtyフラグ=true)
- Remove
- 基本的には、返り値foundNodeが示すノードが提供するエントリ削除のI/Fを呼び出してその結果を返り値とするだけ
- Keyで指定したエントリが存在しない場合もある
- 大半の場合は指定したKeyに対応するエントリが削除されて処理を終えるが、削除した結果、ノード内のエントリ数が0となった場合はノード削除を行う
- ノード削除
- ノードの接続関係の更新
- 削除対象ノードのレベルの高さまで、削除対象に接続していたノードの接続先を、削除対象が次ノードとしていたノードとする処理を行う
- 行うことはInsertでsplitが発生した際とおおむね同様であるが、splitの場合、親ノードに相当するノードがFindNodeの返り値predOfCorners_のインデックス0にページIDが格納されているノードとなる点だけが異なる
- 削除対象ノードを引数にPageManager::UnpinPageを呼び出す(dirtyフラグ=true)
- ノードが用いていたページの削除
- PageManager::DeallocatePageを呼び出す
- ノードの接続関係の更新
- ノード削除が発生しなかった場合は、アクセスを終えたfoundNodeが示すノードを引数にPageManager::UnpinPageを呼び出す(dirtyフラグ=true)
- 基本的には、返り値foundNodeが示すノードが提供するエントリ削除のI/Fを呼び出してその結果を返り値とするだけ
- Iterator
- FindNodeを呼び出しているケースは少なくとも範囲指定において始点が指定されているケース
- 得られたエントリを用いてSLItr型を生成する
- イテレーションはレベル1で次ノードを辿っていくことで行える
- これを踏まえて、SLItr型はよしなに設計すればよい
- ただし、逐次でもイテレータ生成後、イテレータが指定された範囲のエントリ全てを返すまでの間に、Skip Listを更新するような操作を行った場合に、仕様通り動作するかは考えなければならない
- 注意点
- SLItr型の実装において、範囲指定の始点として指定したKeyと一致するエントリが存在しなかった場合に、仮の始点としたエントリを返さないようにする考慮が必要になるはず
- Get
Skip Listを並行・並列アクセス可能とする手法
- Maurice Herlihy, Nir Shavit, Victor Luchangco, Michael Spear 著『THE ART of MULTIPROCESSOR PROGRAMMING - SECOND EDITION』
- 通称TAoMP本。並列プログラミングのバイブル的書籍の1つ(邦訳版は無い)

- この書籍の chapter14 section3 "A lock-based concurrent skiplist" で並行Skip Listの構成法の例示がある
- なお、この手法は元々、下の論文で提案されたもののようである
- M. Herlihy, Y. Lev, V. Luchangco, N. Shavit, A provably correct scalable skiplist (brief announcement), Proc. of the 10th International Conference on Principles of Distributed Systems. OPODIS 2006. 2006.
- なお、この手法は元々、下の論文で提案されたもののようである
- 以下に同書籍内で示されている実装例(Java)のコードを引用する
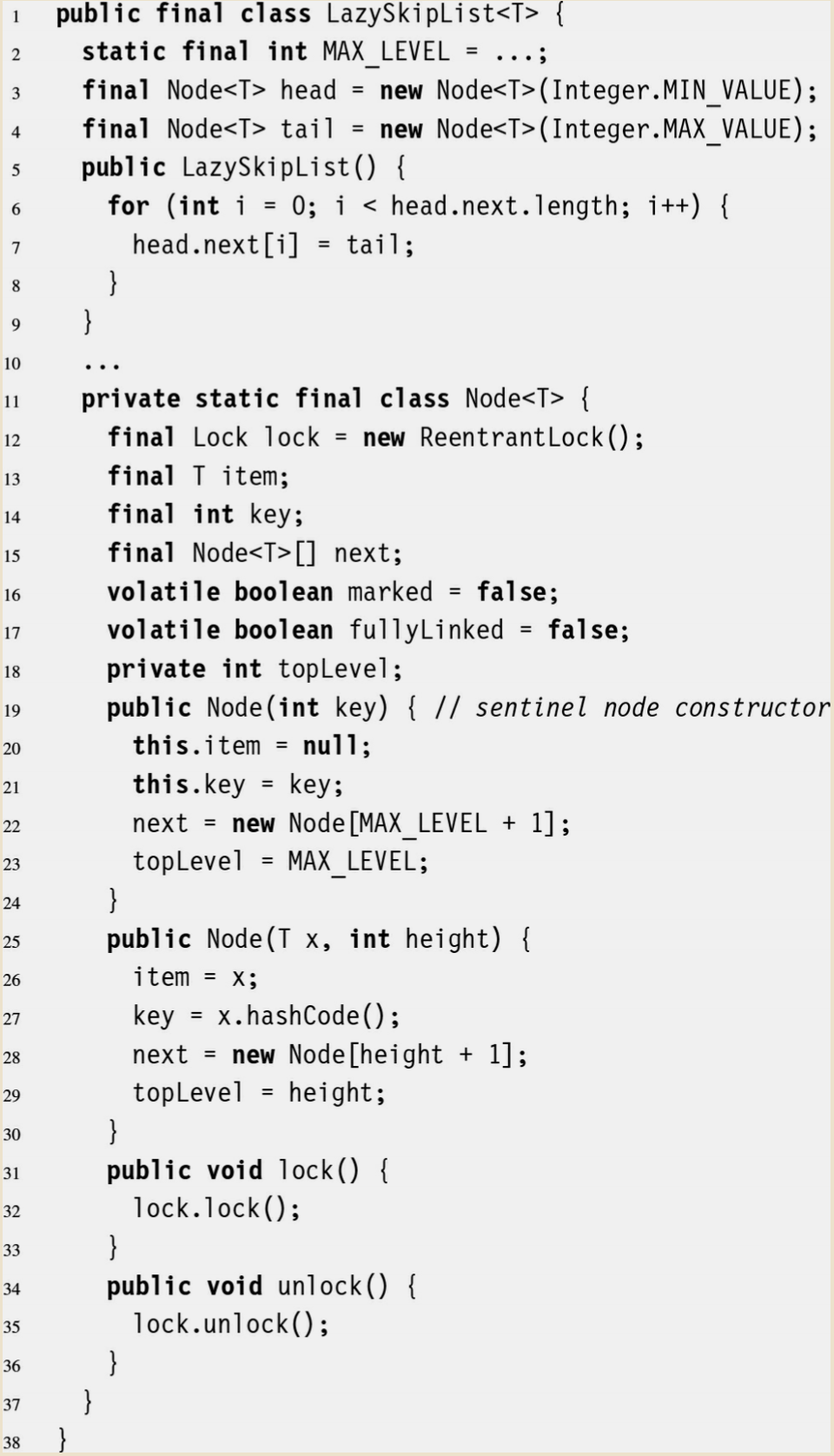
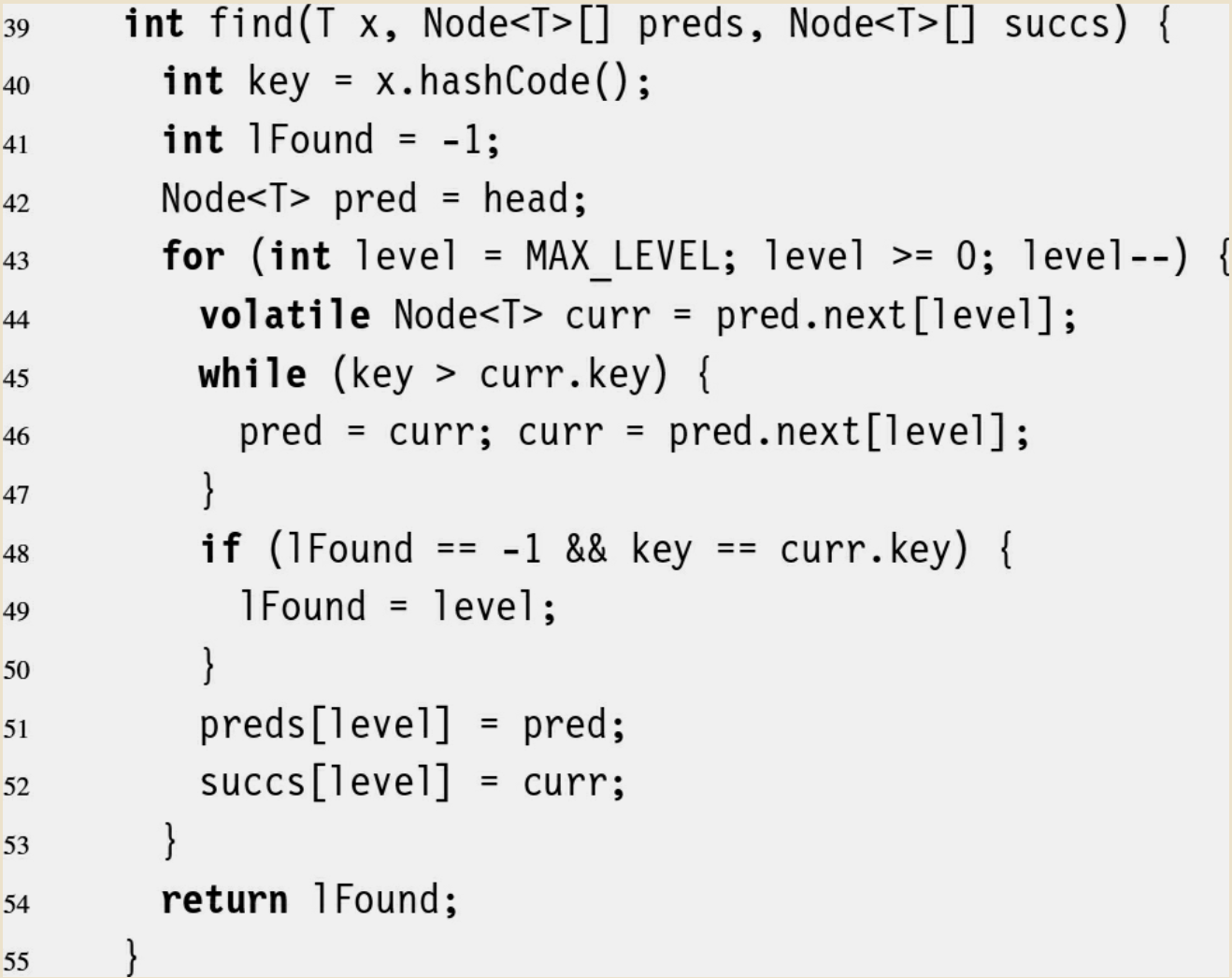
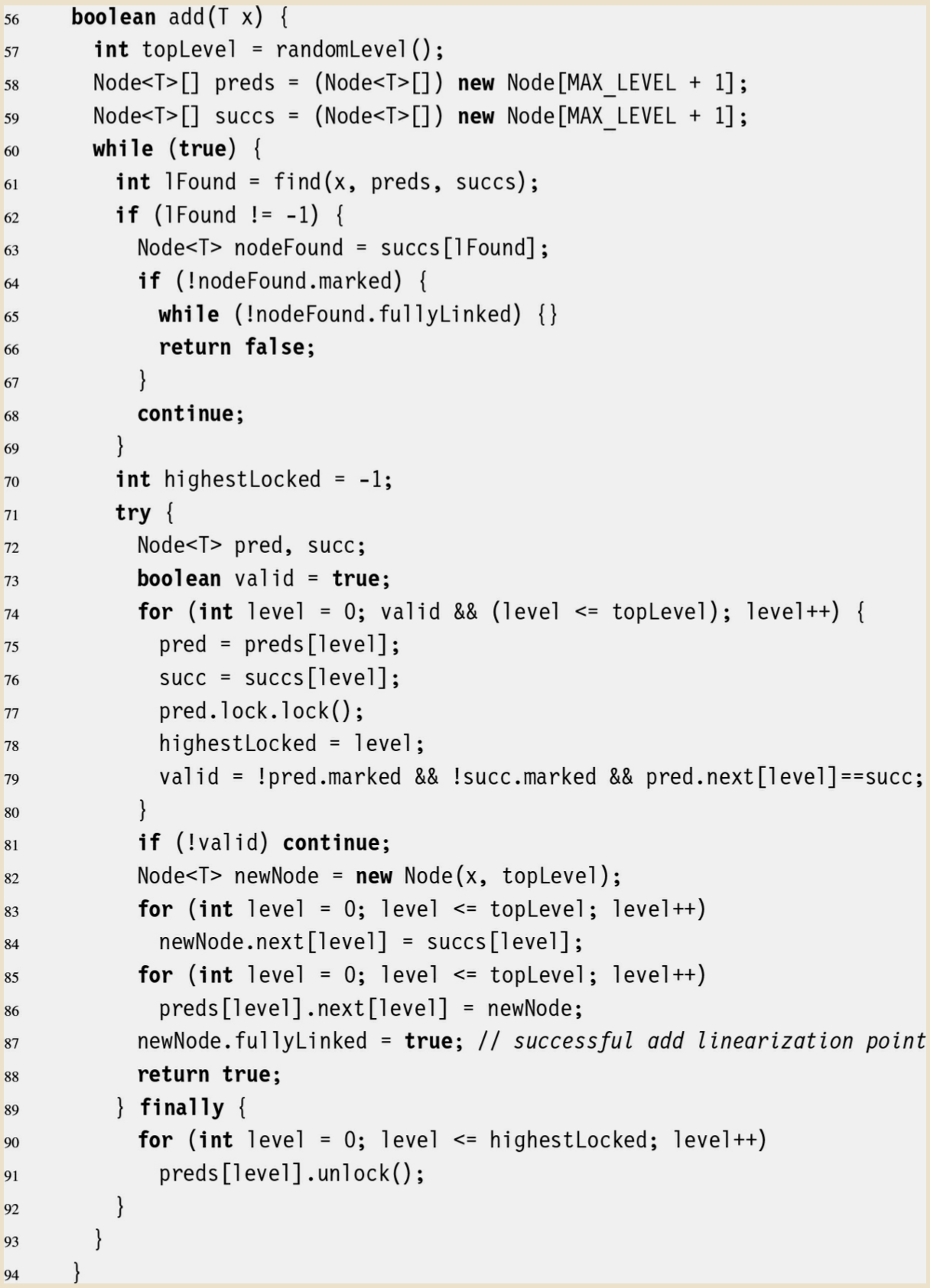


- Lazyという接頭語がついているが、これはSkip Listに限らず、この実装例のタイプのような排他制御の手法を呼ぶ際に用いられるもののようで、"遅延させた" というような意味にとるのがよいと思われる
- 書籍のなかでは Optimistic (楽観的な) というキーワードも出てきているが、こちらのほうが排他制御の手法の文脈では適当なように思われる
- 実装例の詳細な解説は割愛するが、押さえておくべき点は排他制御の方法であり、以下のような手法で実現している
- 更新対象のノード群のロックを事前にとっておくことをせず、Skip Listを先頭から辿っていき、ノードの追加・削除が必要になったタイミングで初めて取る
- ここで対象となるノードはリストを辿ってく途中に(先の例えで言えば)乗り換えを行った駅に対応するノード全てである
- 更新対象のノード群について、一つずつ順にロックをとり、他のスレッドに更新されていないかチェックを行う
- 途中で更新されてしまっていたノードが見つかった場合は獲得したロックを全て解放して、スキップリストを辿る処理からリトライする
- 更新されてしまったノードが一つもなかった場合は獲得したロックを全て保持したまま、所望の更新処理(ノード追加・削除)を行う
- 更新対象のノード群のロックを事前にとっておくことをせず、Skip Listを先頭から辿っていき、ノードの追加・削除が必要になったタイミングで初めて取る
- 単純に考えると、この手法を1ノードが複数エントリを保持する形に拡張したSkip List(並行アクセス未対応=逐次版)に適用すれば並行アクセス対応できることになる
- なお、上に引用した実装例では1ノードが1エントリしか保持していない
1ノード複数エントリ版にTAoMP本で紹介されている並行アクセス対応の手法を適用する
- 逐次版を並行アクセスへ対応させる上で必要となった処理や、対応させる上で注意すべき点に絞って解説する
- 排他制御の設計における基本的なところ
- 排他制御の方法
- Read-Writeロック(が可能なMutex)を用いて行う
- リエントラント(同一スレッドが同一のロックを解放を挟まずに複数回獲得してもブロックしない)なMutexは原理上パフォーマンスが落ちるため利用しない
- Read-Writeロック(が可能なMutex)を用いて行う
- ロックを獲得する順序
- デッドロックが起きないようにするため、ロック獲得の順序がスレッド間で同様になるようにする
- 例えば、MutexがA、B、Cとあり並んでいる順に獲得する規約とした場合、A->B->C、A->C はOKだが、B->A、C->B はNG
- Skip Listでは先頭ノードから終端ノードに向かってノードが連結しているので、その順序に逆らわらないようにすれば良い
- デッドロックが起きないようにするため、ロック獲得の順序がスレッド間で同様になるようにする
- ロックの保持
- Skip Listへのアクセスを開始した後は、splitおよびノード削除時の一部の処理を行っている際を除き、常に少なくとも1つのノードのロックを保持し、アクセス終了後はロックを解放する。リトライを行う際(後述)も同様にロックは全て解放する
- 排他制御の方法
- ノードの探索処理
- コード中に [番号] というコメントを入れてあるので、その各々について解説する
- FindNode終了時、返り値isSuccessがtrueであれば、スレッドは返り値foundNodeのRロックもしくはWロックを獲得した状態となっている。また、同ノードのピンカウントは+1された状態となっている
- 更新系操作であればWロック、参照系操作であればRロック
- コード中では、データベースシステムの世界のお作法に従いロックではなくLatch(ラッチ)という記述になっている
findnode_parallel.go
type SkipListCornerInfo struct { // [1]
PageId int32
UpdateCounter int32
}
// Page型のポインタをNode型のポインタにキャストするユーティリティ関数
func FetchAndCastToNode(pm *PageManager, pageId int32) *Node {
fetchedPage := pm.FetchPage(pageId)
return (*Node)(unsafe.Pointer(fetchedPage))
}
// ノードのラッチ(≒ロック)の獲得および解放を引数に応じて行うユーティリティ関数
func latchOpWithOpType(node *Node, getOrUnlatch LatchOpCase, opType SkipListOpType) {
switch opType {
case SKIP_LIST_OP_GET:
if getOrUnlatch == SKIP_LIST_UTIL_GET_LATCH {
node.RLatch()
} else if getOrUnlatch == SKIP_LIST_UTIL_UNLATCH {
node.RUnlatch()
}
default: // SKIP_LIST_OP_INSERT or SKIP_LIST_OP_REMOVE
if getOrUnlatch == SKIP_LIST_UTIL_GET_LATCH {
node.WLatch()
} else if getOrUnlatch == SKIP_LIST_UTIL_UNLATCH {
node.WUnlatch()
}
}
}
// 引数
// key: 探索対象のエントリのKey
// opType: FindNodeメソッドを何の目的で呼び出したかを示す定数. GET, INSERT, REMOVEのいずれかに対応する定数を渡す
// 返り値
// isSuccess: 探索が成功したか(falseの場合はリトライが必要であることを示す)
// foundNode: 探索の結果発見したノードへのポインタ. foundNodeノードに対応するエントリが存在する可能性があるというだけで、存在は保証しない
// predOfCorners_: 各レベルで"乗り換え"を行ったノードに至った際に、そのノードに接続している1つ前のノードのページID. インデックスは(レベル - 1)となっている
// corners_: 各レベルで"乗り換え"を行ったノードのページID. レベル1の値はfoundNodeと対応する. インデックスは(レベル - 1)となっている
func (sl *SkipList) FindNode(key *KV, opType SkipListOpType) (isSuccess bool, foundNode *Node, predOfCorners_ []SkipListCornerInfo, corners_ []SkipListCornerInfo) {
pred := FetchAndCastToNode(sl.pm, sl.HeadNodeID)
latchOpWithOpType(pred, SKIP_LIST_UTIL_GET_LATCH, opType)
predOfPredId := int32(-1)
predOfPredCounter := int32(-1)
predOfCorners := make([]SkipListCornerInfo, MAX_FOWARD_LIST_LEN)
// entry of corners is corner node or target node
corners := make([]SkipListCornerInfo, MAX_FOWARD_LIST_LEN)
var curr *Node = nil
for ii := (MAX_FOWARD_LIST_LEN - 1); ii >= 0; ii-- {
for { // [2]
curr = FetchAndCastToNode(sl.pm, pred.GetForwardEntry(int(ii)))
latchOpWithOpType(curr, SKIP_LIST_UTIL_GET_LATCH, opType)
if !curr.GetSmallestKey(key.ValueType()).CompareLessThanOrEqual(*key) {
// (ii + 1) level's corner node or target node has been identified (= pred)
break
} else {
// keep moving foward
predOfPredId = pred.GetPageId()
predOfPredCounter = pred.GetUpdateCounter()
sl.pm.UnpinPage(pred.GetPageId(), false)
latchOpWithOpType(pred, SKIP_LIST_UTIL_UNLATCH, opType)
pred = curr
}
}
if opType == SKIP_LIST_OP_REMOVE && ii != 0 && pred.GetEntryCnt() == 1 && key.CompareEquals(pred.GetSmallestKey(key.ValueType())) {
// [3]
// pred is already reached goal, so change pred to appropriate node
predOfCorners[ii] = SkipListCornerInfo{types.InvalidPageID, -1}
corners[ii] = SkipListCornerInfo{predOfPredId, predOfPredLSN}
sl.pm.UnpinPage(curr.GetPageId(), false)
latchOpWithOpType(curr, SKIP_LIST_UTIL_UNLATCH, opType)
sl.pm.UnpinPage(pred.GetPageId(), false)
latchOpWithOpType(pred, SKIP_LIST_UTIL_UNLATCH, opType)
// go backward for gathering appropriate corner nodes info
pred = FetchAndCastToNode(sl.pm, predOfPredId)
latchOpWithOpType(pred, SKIP_LIST_UTIL_GET_LATCH, opType)
// check updating occurred or not
afterCounter := pred.GetUpdateCounter()
// check update state of beforePred (pred which was pred before sliding)
if predOfPredCounter != afterCounter {
// updating exists
sl.pm.UnpinPage(pred.GetPageId(), false)
latchOpWithOpType(pred, SKIP_LIST_UTIL_UNLATCH, opType)
return false, nil, nil, nil
}
} else { // [4]
sl.pm.UnpinPage(curr.GetPageId(), false)
latchOpWithOpType(curr, SKIP_LIST_UTIL_UNLATCH, opType)
predOfCorners[ii] = SkipListCornerInfo{predOfPredId, predOfPredCounter}
corners[ii] = SkipListCornerInfo{pred.GetPageId(), pred.GetUpdateCounter()}
}
}
return true, pred, predOfCorners, corners
}
-
[1] 探索の過程で通過した乗り換えノード情報記憶用の構造体
- 逐次版ではint32でページIDだけを記憶していたが、並行アクセス対応版では更新カウンタも記憶しておく必要がある
-
[2] レベルii で乗り換えするノードを線形探索していくループ
- やっていることは逐次版と基本的に同じ
- ただし、並行アクセス対応のためにロックを獲得・解放しながら進んでいく点が異なる
- ロックを持っているノードが1つも無い状態になると、他のスレッドにより位置しているノードが更新されるといったことが起こった場合に進めている探索処理が正しく行われない可能性が出てくるため、常に1つのノードはロックを持った状態で進む
- しかし、保持しているロックを解放せずに新たに獲得しながら探索を進めてしまうと、ロックを保持しているノードへの他のスレッドのアクセスの阻害(≒ロック競合)が発生し、並行アクセス時の複数スレッド全体で見た時のスループットが低下するため、必要最低限のロックのみ保持して進む
- 必要最低限とするため、大枠としては、元々持っているロックは保持した状態で新たなノードのロックを獲得し、元々持っていたロックは解放するという流れで進む
- 例外は、新たにロックを獲得したノードが探索処理を継続する上で不要と分かった場合(逐次版の解説で"行き過ぎ"と言っているケース)で、新たに獲得したロックを解放して、探索処理を継続する
- 更新系の操作の場合はWロックを獲得しながら進み、参照系の操作の場合はRロックを獲得しながら進む
- RロックをWロックに持ち替えるということは基本的にはできないので、最終的に更新対象のWロックが必要な更新系の操作は排他ロックであるWロックを取りながら進むことになる
- (工夫をすれば、少なくともレベル1まではRロックで進むという方法もあるが、ロックの持ち替えに失敗した場合に探索処理を最初からリトライすることになるなど煩雑なので、今回解説しているものでは採用していない)
- [3] および [4] のところで必要となるため、前進する際はpredOfpredIdにpredのページID、predOfpredCounterにpredの更新カウンタの値を記憶しておく
- 更新カウンタとはノードが更新されたか否かを判定するために、ページで管理するカウンタ
- 更新系の操作がノードに対して何等かの更新を行った際は更新カウンタがインクリメントされる(ように実装しなければならない規約を設ける)
-
[3] ノード削除が発生することが判明した際の考慮
- これも逐次版と基本的にやっていることは同じ
- ただし、現在地を後方に戻すということは、単純に行うとロックの獲得順序に違反してしまうため、それを避けるための考慮が追加で必要となる
- まず、保持しているロックを全て解放し、その後でリスト上で後方(先頭ノード寄り)にある新たにロックが必要なノードのロックを獲得する
- 新たにとは言っても、過去に一度ロックの獲得は行ったが解放してしまったノードである
- 続いて、後ろに現在地をずらしたが、そのノードが更新されていた場合、探索を継続しても正しく行われない可能性が出てくるため、最後に通過した際に記憶しておいた更新カウンタと、再度のロック獲得後の更新カウンタが一致するかチェックする
- もし、2つの更新カウンタの値が一致しなかった場合は更新が行われたことを意味するため、探索処理の続行をあきらめ、全ての保持しているロックを解放して探索処理を最初からリトライする
- リトライはFindNodeの呼び出し元が行うように設計する。返り値isSuccessがfalseの場合はリトライの必要性があることを示す
- もし一致した場合は、そのまま探索処理を継続する
- まず、保持しているロックを全て解放し、その後でリスト上で後方(先頭ノード寄り)にある新たにロックが必要なノードのロックを獲得する
-
[4] 通常の場合のループの1周を終える際の処理([3]でも同様のことは行っている)
- やっていることは逐次版と基本的に同じ
- 乗り換えノードのページIDをcorners、乗り換えノードの一つ前にいたノードのページIDをpredOfCornersに格納しているのは逐次版と同様だが、splitとノード削除の際に必要となるため、SkipListCornerInfo型を用いて、更新カウンタの値も格納しておく
-
ノードを見つけて以降の処理について
- Get
- 基本的には、返り値foundNodeが示すノードが提供するエントリ取得のI/Fを呼び出してその結果を返り値とするだけ
- 二分探索によりノード内の探索を行う(他の操作でも同様)
- 存在しない場合もある
- 最後にアクセスを終えたfoundNodeが示すノードを引数にPageManager::UnpinPageを呼び出し、加えてRロックを解放する
- 基本的には、返り値foundNodeが示すノードが提供するエントリ取得のI/Fを呼び出してその結果を返り値とするだけ
- Insert
- 基本的には、返り値foundNodeが示すノードが提供するエントリ追加のI/Fを呼び出してその結果を返り値とするだけ
- ただし、逐次版と異なり操作に失敗するケースが出てくるためリトライが必要な旨を呼び出し元に伝える返り値が追加で必要となる
- split
- 基本的にやることは逐次版の時と同じ
- ただし、接続関係の更新の際は、ロック獲得順序の規約に違反することになるため、ノード探索の[3]のケースと同様に、保持しているロックを全て解放した後で、各ノードのロックを一つづつ獲得し、更新が無いかチェックを行い、もし更新があればノード探索からリトライし、なければ全てのロックを保持したまま各ノードとの接続の繋ぎ変えを行い、その後で全てのロックを解放する
- ただし、チェック結果がOKの場合、親ノードのロックはInsertの処理が終了するまで解放してはいけない
- 同様にUnpinPageの呼び出しもNG。なお、Insertの処理の終了時にはピンカウントがトータルで+2されているので、2回呼びだす必要がある
- 注意点
- 親ノードについても更新チェックしなければいけないことを忘れない
- 新規ノードは作成直後にロックをとっておき、Insertの処理が終了するまで解放してはいけない。ロックを解放する際はUnpinPageも忘れずに
- 保持しているロックは一度全てを解放する必要があるが、親ノードのピンは立てたままにしておかないと、キャッシュアウト&インが発生して、Fetchして得た参照のアドレスが変化してしまうなどして面倒なことになる
- そして、立てておいたままにしたピンをUnpinPageで落とすことを忘れても面倒なことになる
- 繋ぎ変えを行ったノードについては更新カウンタをインクリメントすることと、UnpinPage(dirtyフラグ=true)しておくことを忘れない
- 親ノードと新規ノードも忘れずに
- corners_ には異なるレベルで同一のノードが設定されている場合がある
- 基本的には、返り値foundNodeが示すノードが提供するエントリ追加のI/Fを呼び出してその結果を返り値とするだけ
- Remove
- 基本的にやることは逐次版の時と同じ
- ノード削除が必要で、接続関係の更新を行う際は上のsplitのところで解説した内容と同様にして行えばよい
- 注意点
- 逐次版と同様にpredOfCorners_のインデックス0にレベル1での繋ぎ変えが必要なページIDが格納されているが、これについても更新チェックが必要なので忘れない
- 削除対象のノードもロックを手放すので更新チェックが必要
- corners_のインデックス0にノードIDが格納されているのでそれを使えば良い
- corners_ には異なるレベルで同一のノードが設定されている場合がある
- Iterator
- 基本的にやることは逐次版の時と同じ
- 得られたエントリを用いてSLItr型を生成する
- エントリを得る際に、そのエントリが格納されていたノードのRロックを解放してはいけない
- 解放してしまうと、他のスレッドがそのエントリをremoveしてしまったり、エントリの追加でsplitを発生させるなどして、エントリの居場所が変わってしまう可能性があるため
- 設計としては、悩ましいところであるが、SLItr型を生成する際にSkip List内のFindNodeで得たエントリから指定範囲に応じた個所までエントリを取得し、結果を保持しておくのが無難ではないかと考える
- この設計であれば、指定範囲内に存在するエントリだけが昇順で返ることは保証される
- ただし、前述の通りここでのエントリ群の取得は他の操作に対してアトミックではないため、SkipList::Iteratorが呼びだされた瞬間のスナップショットとはならない
- 処理としては、レベル1で連続するノードをRロックの獲得・解放を繰り返しながら辿っていくことになる
- 特に工夫をしなければ、メモリ上に集めたエントリを保持しておくことになり、許容できないメモリ消費となることも想定されるが、PMやぺージの仕組みを利用しても良いし、他の方法でも良いが、ディスクに書き出しておいて、後で読み出すといったことで、この懸念は回避できるであろうとは思われる
- この設計であれば、指定範囲内に存在するエントリだけが昇順で返ることは保証される
- エントリを得る際に、そのエントリが格納されていたノードのRロックを解放してはいけない
- 注意点
- 範囲の始点として指定されたKeyと一致するエントリが存在しなかった場合に、仮の始点としたエントリを返さないようにするといった考慮が必要になるはず
- Node型の実装にもよるが
- 範囲の始点として指定されたKeyと一致するエントリが存在しなかった場合に、仮の始点としたエントリを返さないようにするといった考慮が必要になるはず
- Get
【重要】補足
- 更新チェックの処理に一部考慮不足がある
- 実は、上のコード例や説明に従った実装だと、別のスレッドが脇でノード削除をして、それが運悪く、[3] や、splitおよびノード削除時の更新チェックの対象となるノードであった場合、FetchPageでnullが返る。また、そもそもロック獲得待ちのスレッドがいた場合、ノード削除完了後にロックを獲得したスレッドでの処理が不正なものとなる
- (筆者のSamehadaDB内の実装ではPageManager::DeallocatePageを呼び出していないため、ノードは論理的に削除されているが、利用していたページは再利用されない形になっており、FetchPageした際に元の内容のままのページが返ってきて動く・・・)
- 説明通りDeallocatePageの呼び出しを行う場合は、更新チェック時のFetchPageでnullが返ってきたらチェック結果をNGとするようにする、ノードに各種操作を行う際に削除済みのノードであるか(=ページデータの内容がアクセスしようとしたノードに対応するものであるか)チェックする、といった考慮を加える必要がある
- 実は、上のコード例や説明に従った実装だと、別のスレッドが脇でノード削除をして、それが運悪く、[3] や、splitおよびノード削除時の更新チェックの対象となるノードであった場合、FetchPageでnullが返る。また、そもそもロック獲得待ちのスレッドがいた場合、ノード削除完了後にロックを獲得したスレッドでの処理が不正なものとなる
- ページロック解放のタイミングの誤り
- 上記のコード例や説明、ではUnpinPageを呼び出した後にページのロック解放をしているが、本来、UnpinPageを呼び出した後は、ページへの参照が有効であることは保証されないため、ロック解放のためにページ(ノード)にアクセスすることはNGである
- 従って、ロック解放はUnpinPageの前に行う必要がある
- (SamehadaDBにある実装はNGなコードとなっている。しかし、PMの実装上、また、Go言語がGCあり言語であることから、Page型のインスタンスはページがキャッシュアウトされてもGCが走るまでメモリ上に存在し、かつ、参照はロック解放を行なう箇所に残っているためGCされない。従って、動作する・・・)
【参考】実装について
- 本文書で解説した設計と若干異なる点はあるものの、筆者が中心となって開発している RDB(SamehadaDB、Go言語製)に実装が存在する
- Skip Listの実装に対応するソースファイル及び主たる関連ソースファイル
- RDB全体のコードツリー
- Keyが重複しても動く版(Skip Listの薄いラッパーであり実質的にSkip List)
- RDB全体のコードツリー(Keyが重複しても動く版)
- 本文書の解説には不足もあったかもしれないが、その場合でも、本文書の内容を踏まえて上で挙げたソースコードを読めば、(開発言語問わず)なんとか同様のものが作成可能となることを期待する
最後に
- 設計にバグがあったり、コード例にバグがあるといったことがあればご指摘いただければ幸い
- 肝心なところが駆け足になった感が否めないので、良く分からない点があればコメント欄にて質問いただければ可能な範囲で対応します
- 自作RDB?とか思った方は下のページを一読することをおすすめします
Disclaimer
- 共有した設計等の内容に誤り(=考慮漏れ等)が無いことは保証しかねるため、あくまで参考として捉えて頂きたい
- 本文書に記述する設計に基づいた実装のテストは入念に行い、不具合なく動作したが、かといって設計に誤りがないことが保証されているわけではない
- 本文書は、その内容を参考としたり、利用して閲覧者が行った行動により閲覧者およびその他の第三者に損害が生じたとしても、筆者が責任を負わないことに閲覧者が同意していることを前提として提供される
enjoy!