はじめに
今回 Neural Network Console Challenge(以下、NNC Challenge)というコンテストに参加しました。
コンテスト概要
NNC ChallengeはSonyが提供している Neural Network Console(以下、NNC)を用いて[PIXTA]の写真素材を画像分類するというものです。
※学習用データ提供:[PIXTA]
コンテストに応募すると写真素材1万枚がダウンロードできます。その中から好きな枚数を使用して学習を行います。
[PIXTA]:https://pixta.jp/
テーマは次の4テーマ
1.『人物画像をNNCで学習させ新しいオノマトペ(擬音語/擬声語/擬態語)の画像カテゴリ分類を作り出す』
2.『画像内人物をNNCで学習させ画角/焦点距離による画像分類を作り出す』
3.『NNCで画像を学習し人の感情によって分類』
4.『上記以外のチャレンジテーマを自由に設定しての応募』
テーマ選択
今回チャレンジしたのは人数による画像分類です。4テーマのうち4番目です。
アノテーション(ラベル付け)
画像に対してテーマに沿ったラベル付けを行います。
今回は1人なら0、2人なら1としていき、6人以上を5にすることにしました。
流れとしてはこんな感じです。
1.まずは画像を全体的に確認して、どの様な画像があるのか確認
2.画像のサイズが640×426のファイルを抽出(サイズが数パターンあったため)
3.顔がわかる、人のシルエットがわかる、などの人が判別できる画像を抽出
4.人数毎に該当するラベルのディレクトリにドラッグ&ドロップ
画像のサンプルと各ラベルの枚数
| label | 枚数 | ||||
|---|---|---|---|---|---|
| 0 |  |
 |
 |
 |
2,675 |
| 1 |  |
 |
 |
 |
1,229 |
| 2 |  |
 |
 |
 |
553 |
| 3 |  |
 |
 |
 |
247 |
| 4 |  |
 |
 |
 |
93 |
| 5 |  |
 |
 |
 |
266 |
| ※学習用データ提供:[PIXTA] |
DataSet
アノテーションで分類した画像を元にNNCを使用してDataSetの作成を行います。
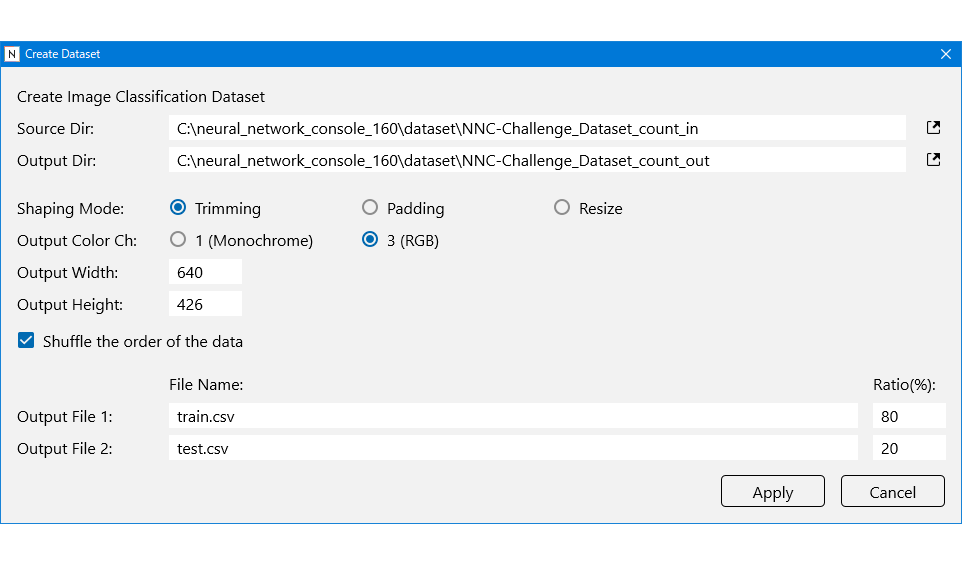
画像サイズは今回640×426の画像を使用しているので、640×426を指定します。
train:testを8:2で作成しました。
trainが約4,000枚、testが約1,000枚になりました。
モデル作成
以前作成したCNNのモデルを流用したものを使用しました。
人物を検出するようにアノテーションした方がいいと思ったのですが、アノテーションから含めての作業は初めてだったので、とりあえずCNNで行うことにしました。
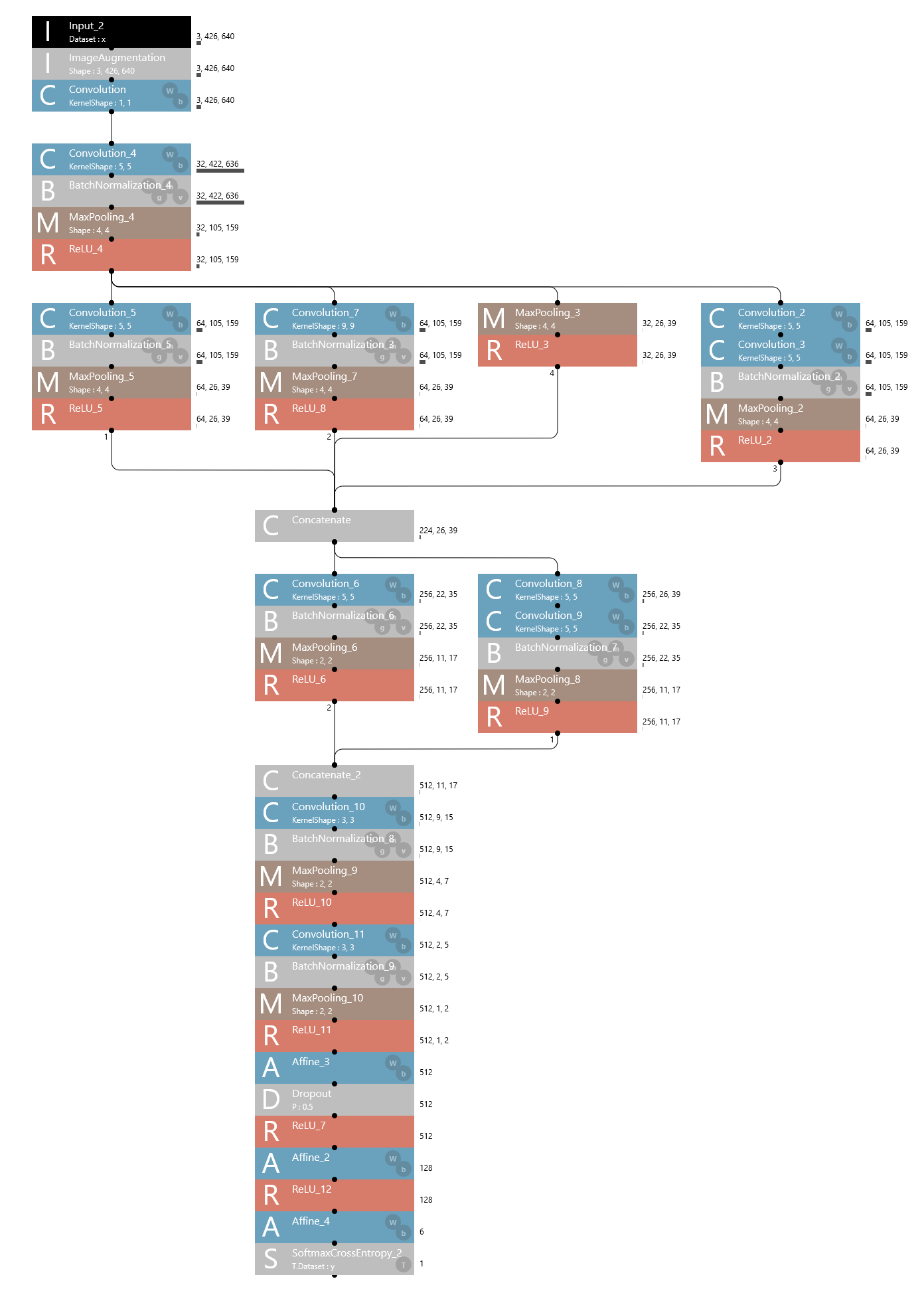
複数条件のCNNをConcatenateで結合して次の層に渡すというイメージです。
また、入力データの水増しのためにInput後にImageAugmentationを使用しています。
学習
学習は主にローカルPCを使用しました。
GPUはGeForce GTX1070
NNC Challengeではクラウド環境のGPU利用枠10,000円分が使用できるということで、クラウド環境も利用しました。
※クラウドのGPUはTesla V100x4を使用
300epochの学習時間比較
| ローカルPC GeForce GTX1070 |
クラウド Tesla V100x4 |
|
|---|---|---|
| CPU | - | メモリ不足で動かず |
| GPU | 06:10:08 | 00:48:45 |
Tesla V100x4だと1/7以下の学習時間になりました。
学習結果
トレーニング結果

training error(赤の実線)は下がっていますが、validation error(赤の破線)が0.6付近で停滞しています。
さらにvalidation errorが250epoch辺りから若干上がり気味なので、過学習とも考えられます。
評価結果
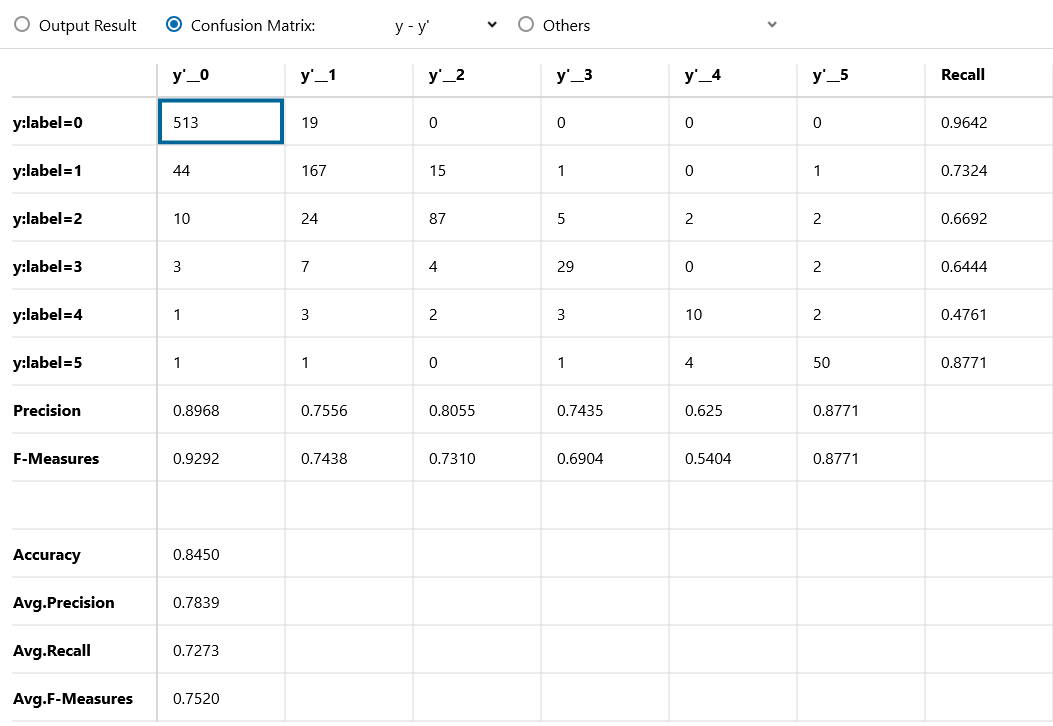
Accuracy(正確度)が0.845、まずまずの結果というところでしょうか。
実用レベルではなさそうです。
各ラベル別に見ると、ラベル4(5人)の精度が他のラベルと比べて低い結果となりました。
Precision(精度):0.625
Recall(再現率):0.4761
NNCで分類した画像の一例
|label|||||
|:-:|:-:|:-:|:-:|:-:|:-:|
|0| |
| |
| |
| |
|
|1| |
| |
| |
| |
|
|2| |
| |
| |
| |
|
|3| |
| |
| |
| |
|
|4| |
| |
| |
| |
|
|5| |
| |
| |
| |
|
※学習用データ提供:[PIXTA]
考察
モデルやパラメータを変更したり、NNCの構造自動探索機能を使用してみましたが、精度の向上がほとんど見られなかったことから、精度を向上させるためにはアノテーションのやり方やモデル全体の見直しが必要だと考えられます。
またラベル4の精度が低い原因として、ほかのラベルよりも画像枚数が少ないため(100枚以下)と考えられます。画像の枚数が多いラベル0やラベル1は他のラベルよりも正解率が高い傾向にあると言えます。
ラベル4(5人)の枚数が少ないのであれば6人以上ではなく、5人以上でまとめたDataSetだと違う結果になるかもしれません。
追記(2020/3/31)
5人以上でまとめたDataSetで試してみました。
https://qiita.com/ryo19841204/items/4e083c427eeb149bc86f
感想
今回、初めてアノテーションから作業しましたが、かなり大変でした。
元々は3の感情による分類を行うつもりだったのですが、アノテーションの段階でこの表情は何に分類しようか?複数人写っている写真の場合はどうするか?などなど作業が止まり中々進まず。。。
気を取り直して、取り合えず人数で分類できるようになれば1人の写真を抽出できるし、その後のアノテーションも楽になるはず。今後のことを考えると一石二鳥。という感じで人数での分類に変更しました。
NNCを使用した感想ですが、NNCはネットワークの設計がGUIで出来るのでプログラムより作業がかなり楽です。更にパラメータの調整もある程度自動でやってくれるため、試行錯誤もやり易いと思います。
また、評価結果の確認もやり易いです。
今後、さらに使いやすくなっていくのではないかと期待します。