S3のJSONを気軽にAthenaで集計したいと思い、安く済ます方法を調べた。
事前の印象では結構なお値段かかってしまうものだと思っていたが、小さいデータを最低コストで集計する分にはかなり安く済みそうだった。
ということで、ここでやりたいのは、
- S3の小さいデータを
- 気軽に
- 安く
- SQLで集計する
ということで、RDSなど立てるのはもってのほかである。
前提知識
パーティション
データをパーティション分割することで、各クエリでスキャンするデータの量を制限し、パフォーマンスの向上とコストの削減を達成できます。Athena では、データのパーティション分割に Hive を使用します。すべてのキーでデータをパーティション化できます。一般的な方法では、時間に基づいてデータをパーティション分割します。これにより、通常、複数レベルのパーティション構成となります。たとえば、1 時間ごとに配信されるデータを年、月、日、時間でパーティション分割できます。別の例として、さまざまなソースから配信されるデータを 1 日 1 回ロードする場合、データソースと日付でパーティション分割できます。
データのパーティション分割 | Amazon Athena
このようにS3のパスを年月日などで区切ると、それをパーティションとしてデータ分割することができる。
パーティションを分けることでクエリーの条件として利用できるようになり、条件を絞ることでスキャンするデータ量を削減できる。
具体例はこんな感じ。どれも年月日でパーティションを分けている。
s3://datasource/year=2020/month=01/day=01/...
s3://datasource/dt=2020-01-01/...
s3://datasource/2020/01/01/...
上2つの変な形式のことをHive形式と言うらしい。
Athenaはこの形式を認識して自動でパーティションを追加してくれる。
一番下の例はHive形式ではないので手動でパーティションを追加する必要がある。
パーティションプロジェクション
Athena でパーティション射影を使用すると、高度にパーティション化されたテーブルのクエリ処理を高速化し、パーティション管理を自動化できます。
Amazon Athena を使用したパーティション射影 | Amazon Athena
前述のパーティションデータはGlueデータカタログに保存されるデータだが、Athenaのパーティションプロジェクションを使うとテーブル設定から計算してパーティションを認識するようになる。
実際のパーティションデータを保持するわけではないので検索対象に存在しないパーティションがあり虫食い状態だと、クエリーに時間がかかってしまう場合がある。パーティションプロジェクションの制限事項/考慮事項は 公式ドキュメント を参照。
今回はパーティションのデータ追加処理が不要になることで、Glueクローラーなどの処理コストが無料になるため利用している。
パーティションの追加/更新方法
パーティションはデータの追加に従って更新していかなければならない。
年月日でパーティションを切っている場合、翌月のデータが追加されたらパーティションも増えるから。
いくつか方法は考えられる。
-
手動でADD PARTITION/MSCK REPAIR TABLE
手動でDDLクエリーを実行する。
データが増えないのであれば、テーブル作成後に「パーティションのロード」を選択すれば同じ処理をしてくれるのでそれでいいと思う。 -
LambdaでADD PARTITION/MSCK REPAIR TABLE
EventBridge+Lambdaで定期的に実行する。
でも無駄な管理リソースが1つ増えるので、こういうコードを書きたくない。 -
Glueジョブのついでに
試してないがこちらの記事が参考になった。
Glueジョブを使っているならこの方法がよさそう。
[アップデート]AWS Glueがジョブ実行後のパーティション更新に対応しました! | Developers.IO -
Glueクローラー
パーティションの更新だけでなく、テーブル定義もデータを元に自動更新してくれたりする。有能だけど高い。 -
Athenaパーティションプロジェクション
今回使った方法。
考慮事項と制約事項 | Amazon Athena
最終的な構成
とにかくAWS Glueにコストがかかる。Athenaの料金体系の幅とはマッチしていない感じだった。
なのでGlueの利用は最低限にして、制限やバグを回避しつつAthena+S3で集計できるようにした。
S3 Selectも少し調べたが制限が多く、特殊な使い方しか出来なさそうだったので早々に諦めた。
-
S3
S3にNDJSON形式のファイルを置いてある前提(別のファイル形式でも問題ない)。
集計対象のパスが意味を持っているのでパスの設計に気をつけないといけなかった。 -
Athena
S3というかGlueのデータカタログにSQLを投げられる便利なサービス。
パーティションプロジェクションの登場でお手軽に安く使えるようになった気がする。 -
Glue
データに関する色々なことができるサービス。そのほとんどが今回不要。
ちゃんと使うとS3のデータレイクからGlueを介してAWSの豊富なデータベースサービスと連携できそう。
ただ今回は不要。もっと小物から大物まで利用できる柔軟な料金体系にして欲しい。
AWS Glue との統合 | Amazon Athena
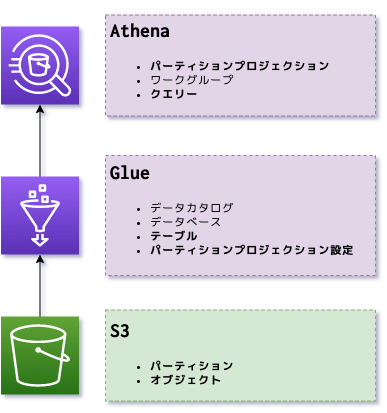
図にするほどでもないがこのような構成になった。
色々な用語がでてくるが、自動で設定される部分も多いので太字の部分だけ考えればいい感じ。
コスト
東京リージョンの場合。
ごらんの通りGlueクローラーが高いので、クローラーを使ったパーティションの自動更新をやめて、Athenaのパーティションプロジェクションを使うことでGlue分は無料になった。
これ以外にも通信量などもかかるが、今回の件に限った話ではないので割愛。
S3
安い。
Athena
料金 | Amazon Athena
スキャンされたデータ1TB あたり 5ドル。
結果セットの大きさでなく、集計対象のデータの大きさに課金される。
気になる最低料金は10MB(0.000001TB)分の金額になる。
0.000001TB * 5ドル = 0.000005ドル/クエリー
日次で1クエリー実行すると毎月0.0015ドル。ほんとか?
Glue
-
ストレージとリクエスト
ストレージは100万オブジェクトまで無料。
リクエストは毎月100万回まで無料。 -
クローラー
高い。パーティションの自動更新などに利用するとびっくりする。
1DPUあたり0.44ドル/時かかる。DPUはData Processing Unitの略で、4vCPU/16GBメモリの計算リソース。
最低利用時間は10分だが、DPUは2つ利用されるという噂を見かけたので2DPUで計算しておく。
0.44ドル * 1/6時間 * 2DPU = 約0.146ドル
こちらも日次で実行すると毎月4.38ドル。高い。
構築
データソースの用意
集計対象のファイルが置いてあるバケットを用意する。
元から /YYYY/MM/DD/ 形式で保存されているなら、その形式にするしかないと思う。もしくはGlueジョブなどで加工するか。これからパスを決められるならHive形式にするのが良さそう。
今回は /datehour=YYYY-MM-DD-HH/ にした。パーティションプロジェクションの date 型、Firehose、Lambdaのタイムゾーン、などに合わせてUTCにしたかったのと、日本時間で集計するため−9時間できるように時間(HH)まで含めた。
問題のあるHive形式のパス
当初 /year=2020/month=01/day=01/hour=00/ にしたところ、パーティションプロジェクションでエラーになり認識できなかった。これはyear を date 型として認識させようとした場合 yyyy ではダメで java.time.Year 型が動作しないようだった。不具合と思われるのでAWSサポート経由でフィードバックした。
date 型でなく integer 型で認識させた場合は問題なく動作するが、その場合 NOW-3YEARS や NOW+1MONTHなどの相対日付文字列が使えなくなる。ここらへんのパーティションプロジェクションの設定については後述。
Athenaのクエリー結果出力先
ワークグループ設定やクエリー実行時に出力先のS3バケットを指定する。
クエリーの実行結果だけでなく、クエリーを保存した場合もここに保存される。
なんなら保存してないクエリーもここに保存される(?)。
APIでも結果を取得できるので、直接ここを見ることは少ないかもしれない。
データソースの追加
ドキュメント を参考にAthenaのデータソースを追加する。
データソースを追加することでデータベースとテーブルが登録され、Athenaで検索できるようになる。
以下、ドキュメントにある手動追加手順の補足。
-
8.テーブル名の入力
ここが一番の難関。データベース名やテーブル名に入力できる記号は_だけ。
-を入力してもここではエラーなど出ない。クエリー実行時になって意味不明なエラーがでるだけ。
本当に意味不明なので解決はできない。
テーブル、データベース、および列の名前 | Amazon Athena
予約キーワード | Amazon Athena -
11.データ形式
JSONを選択する。
JSON形式を選択すればNDJSONやJSON Linesのような改行区切りのJSONも認識する。 -
14.パーティションの追加
ここでdatehour列を追加する。
型はstringにする。dateやtimestampにするとエラーになる。
これはデータソースの追加時に設定したS3パス(/datehour=YYYY-MM-DD-HH/)のdatehour部分に合わせる。 -
16.テーブル作成クエリーの実行
生成されたクエリーに問題がなければ自動的に実行されたと思う。
問題があった場合エラーメッセージが表示される。されるが意味不明なので覚悟すること。
パーティションプロジェクションの設定
ここまででクエリー自体は実行できるようになっている。
まだパーティションの設定をしていないのでクエリー結果は0件になるはず。
続いてAthenaがパーティションを認識できるようパーティションプロジェクションの設定をする。
そのためにはGlueのテーブルにプロパティを追加する必要がある。
ドキュメントには integer 型の例しか載っていないので、ここでは date 型で設定してみる。
設定の流れはどちらも変わらないので、ドキュメントを参考のこと。
パーティション射影の設定 | Amazon Athena
date型のテーブルプロパティ
projection.enabled を true に設定するのは共通項目。
date 型の設定として下記の項目を追加する(列名は datehour の前提)。
日付型 | Amazon Athena
| プロパティ名 | 値 | 備考 |
|---|---|---|
| projection.enabled | true | 必須。固定値。 |
| projection.datehour.type | date | 必須。固定値。 |
| projection.datehour.range | NOW-3YEARS,NOW | 必須。カンマ区切りで下限,上限を指定する。 ここでは直近3年を指定している。 |
| projection.datehour.format | yyyy-MM-dd-HH | 必須。 |
| projection.datehour.interval | 1 | 単一日/単一月でなければ必須。 1時間単位を指定。 |
| projection.datehour.interval.unit | HOURS | 同上。1時間単位を指定。 |
パスがHive形式でない場合
データソースであるS3のパスが /datehour=YYYY-MM-DD-HH/ のようなHive形式でない場合、 storage.location.template テーブルプロパティを設定することでAthenaにパーティションとして自動認識させることができる。
例えば s3://bucket/prefix/yyyy/MM/dd/HH/... なら下記のように設定する。
| プロパティ名 | 値 |
|:--|:--|:--|
| projection.enabled | true |
| projection.datehour.type | date |
| projection.datehour.range | NOW-3YEARS,NOW |
| projection.datehour.format | yyyy/MM/dd/HH |
| projection.datehour.interval | 1 |
| projection.datehour.interval.unit | HOURS |
| storage.location.template | s3://bucket/prefix/${datehour} |
Amazon Kinesis Data Firehose 例 | Amazon Athena
余談だがFirehoseではHive形式も指定できるっぽい。
Amazon S3 オブジェクトのカスタムプレフィックス | Amazon Kinesis Data Firehose
Firehose でS3プリフィックスのカスタマイズが可能になりました | Developers.IO
クエリーを実行する
パーティションプロジェクションの設定まで終わったので、これで検索できるようになっているはず。
パーティション列を条件に入れて検索してみる。これは日本時間で7月分のデータを検索するクエリー。
SELECT *
FROM database_name.table_name
WHERE datehour >= '2020-06-30-15'
AND datehour < '2020-07-31-15'
パーティションを絞って検索しないと過去3年分の存在しないパーティションを検索しにいってしまいえらい処理時間がかかるので注意。
まとめ
- Athenaのパーティションプロジェクションありがとう
- Athena思ったより安い、というか料金体系に幅があってよい
- Glueデータカタログは無料枠が使える
- あまり気軽じゃないが1回やれば慣れる