💡はじめに
所属してるサッカーチームで公式試合のスケジュールがあるサイトで更新されるのですが、最新のスケジュールを把握するため毎日サイトを見に行く必要があり、めんどくさいなあと思ってました。
ちょうどPythonを勉強していたこともあって、「これスクレイピングで解決できるやん?」ということでそのプログラムを勉強がてら作ってみました。
📄書いてること
ブログやお知らせ一覧などの定期的に更新されるページから、更新されたらSlackで更新内容を通知するプログラム
詳しいスクレイピングやcronのついては記載していないので参考記事を見ていただければと思います。
大まかな流れ
- 対象サイトをスクレイピングして必要情報取得
- 更新がないかをチェック
- 更新があれば内容をSlackで通知
この処理をcronで定期実行することでわざわざそのサイトを見に行かなくても更新があったと気づくことができます。
ただmac上で実行しているのでmac起動しているときしか動きません。
⚙️環境
macOS : Big Sur
conda version : 4.9.2
Python : 3.8.5
💻スクレイピング
- ライブラリインポート
import csv
import os
import sys
import requests
import slackweb
import pandas as pd
from bs4 import BeautifulSoup
- 対象サイトのほしい情報ををスクレイピングで取得
def scraping():
url = '対象ページURL'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
result = []
for top_news in soup.find_all(class_='取得したい箇所のクラス名'):
result.append([
top_news.text,
top_news.get('href')
])
return result
soup.find_all(class_='取得したい箇所のクラス名')の中身はyahooニュースでやるとこんな感じでリストに入って取得できます

今回だと、これでタイトルとリンクを取得しリストに格納
result.append([
top_news.text, #タイトル
top_news.get('href') #リンク
])
- 取得した情報をcsvに吐き出す
リストに格納されたタイトルとリンクを一行ずつ取り出してcsvに保存
def output_csv(result):
with open('last_log.csv', 'w', newline='',encoding='utf_8') as file:
headers = ['Title', 'URL']
writer = csv.writer(file)
writer.writerow(headers)
for row in result:
writer.writerow(row)
こんな感じ
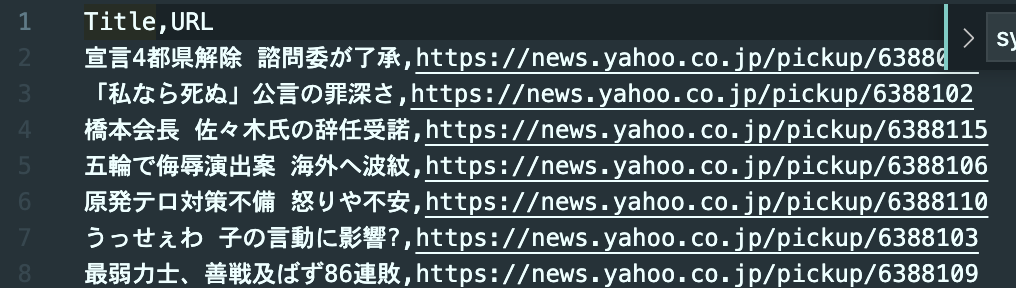
- csvを読み込む
ファイルの存在確認と中身の確認を行う
def read_csv():
if not os.path.exists('last_log.csv'):
raise Exception('ファイルがありません。')
if os.path.getsize('last_log.csv') == 0:
raise Exception('ファイルの中身が空です。')
csv_list = pd.read_csv('last_log.csv', header=None).values.tolist()
return csv_list
tolist()とすることでDataFrame型のものをリストにして返します
これが、
こう!

- 1つ前に保存したcsvと中身を比較して中身が変わったものだけ取り出す
直近で取得したリストをforで回し、その中で前回取得したリストの中に含まれていないものを新しいリストに入れます
def list_diff(result, last_result):
return_list = []
for tmp in result:
if tmp not in last_result:
return_list.append(tmp)
return return_list
ここまでで更新された内容が取得できました🙌
🔔Slackに通知(Incoming WebHooks)
Webhook URLについてはこの記事が参考になりました
-
チャンネル選択
通知を送るチャンネルを設定します
Add Incoming Webhooksintegrationをクリック -
Webhook URLをコピー
-
コピーしたWebhook URLを設定
import slackweb
slack = slackweb.Slack(url='コピーしたWebhook URL')
slack.notify(text='こんにちは、世界')
こんな感じ

- 更新されたものだけ通知
list_diff関数で取り出した更新されたものをSlackで通知する
def send_to_slack(diff_list):
text = '<!channel>\n' #@channelメンション
for tmp in diff_list:
text += tmp[0] + '\n' + tmp[1] + '\n'
slack = slackweb.Slack(url='コピーしたWebhook URL')
slack.notify(text=text)
こんな感じ

🔄cronで定期実行
cronの使い方についてはこの記事を参考にしました
- cronにファイルのアクセス権限を与える
cronからPCにあるファイルのアクセス権を設定します
これを設定しないとcronが言うことを聞いてくれません
この記事が参考になりました
- PATHを通す
今回実行した環境がanacondaなのでecho $PATHとターミナルに打つことによってPythonのPATHがわかります
そのPATHをcrontabを開いてPATHに代入します
こんな感じ(人によって変わると思います)
PATH=/Users/username/anaconda3/bin:~
- ログを吐かせる
* */1 * * * python /Users/hogehoge/main.py >> /Users/hogehoge/cron.log 2>&1
>>を指定することでpyファイルの出力結果(print関数で表示させてもの)を特定のログファイルに追記をすることができます
2>&1を指定することでpyファイルの出力結果に加えて、コマンドの実行時に起こったエラーもcron.logというファイルに記録されます
エラーの場合はこんな感じ
Traceback (most recent call last):
File "/Users/hogehoge/main.py", line 78, in <module>
main()
File "/Users/hogehoge/main.py", line 66, in main
last_result = read_csv()
File "/Users/hogehoge/main.py", line 41, in read_csv
raise Exception('ファイルがありません。')
Exception: ファイルがありません。
時間なども一緒に出力させるとよりいいですね
標準出力など詳しくはこの記事が参考になるかと思います
🤦♂️つまづきポイント
・csvファイルの比較ができない
read_csv関数で読み込んだcsvをDataFrame型で返していたたため、最新情報を取り込んだリストと比較ができていなかった
→pandasで読み込んだcsvはリストに型変換してから比較を行うことで解決🙆♂️
・cronうまく動かない
cronのファイルアクセス権がなかった
→システム環境設定からアクセス権付与で解決🙆♂️
mac標準のPythonを指定していた
→anacondaインストールしたときに追加されたPATHを指定することで解決🙆♂️
📦まとめ
いちいちサイトを見に行く手間が省けました🙌