はじめに
(1)データ取得編からの続きです。
前回は、Power BI から Twitter API に接続して、ツイートデータを取得するところまでを解説しました。
前回までの手順で、特定のキーワードで検索したツイートデータを Power BI へ持ってくることができたので、ここからは、Power BI の機能を使って、データ整形 → 可視化を行っていきます。
前回取得したデータ
Power Query エディタで、「data」「inclueds」「meta」の3つのデータを取得するところまでやりました。
ツイートの内容は「data」「inclues」に分かれて入ってくるので、それぞれを整形していきます。

大まかな手順
- 取得したデータを「data」(ツイート内容) と「include」(それ以外の情報) に分ける
- 「data」(ツイート内容) を整形
- 「include」(それ以外の情報:今回はユーザー情報のみ)を整形
- ツイートテキストを Text Analytics でキーフレーズ抽出 (※要 Premium ライセンス)
1. 取得したデータを「data」(ツイート内容) と「include」(それ以外の情報) に分ける
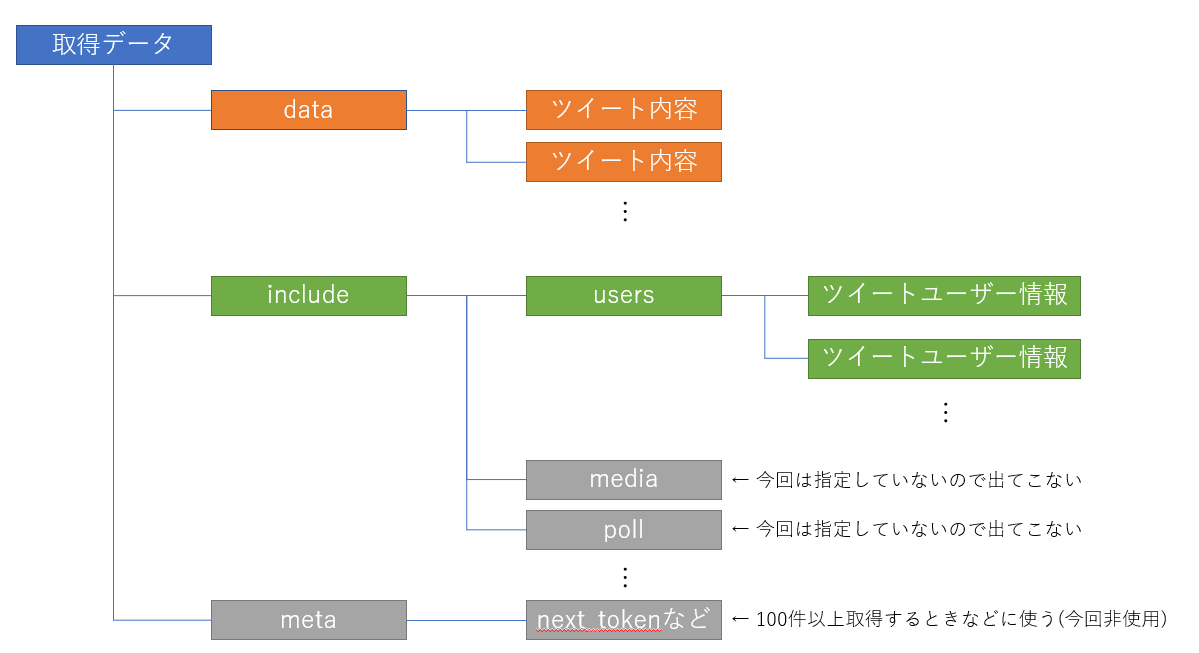
「data」にはツイートに関する情報、「include」には今回はユーザーに関する情報が入っているため、別々のテーブルに分けてから整形をしていきます。
構造の概要としては以下の通りです。
-
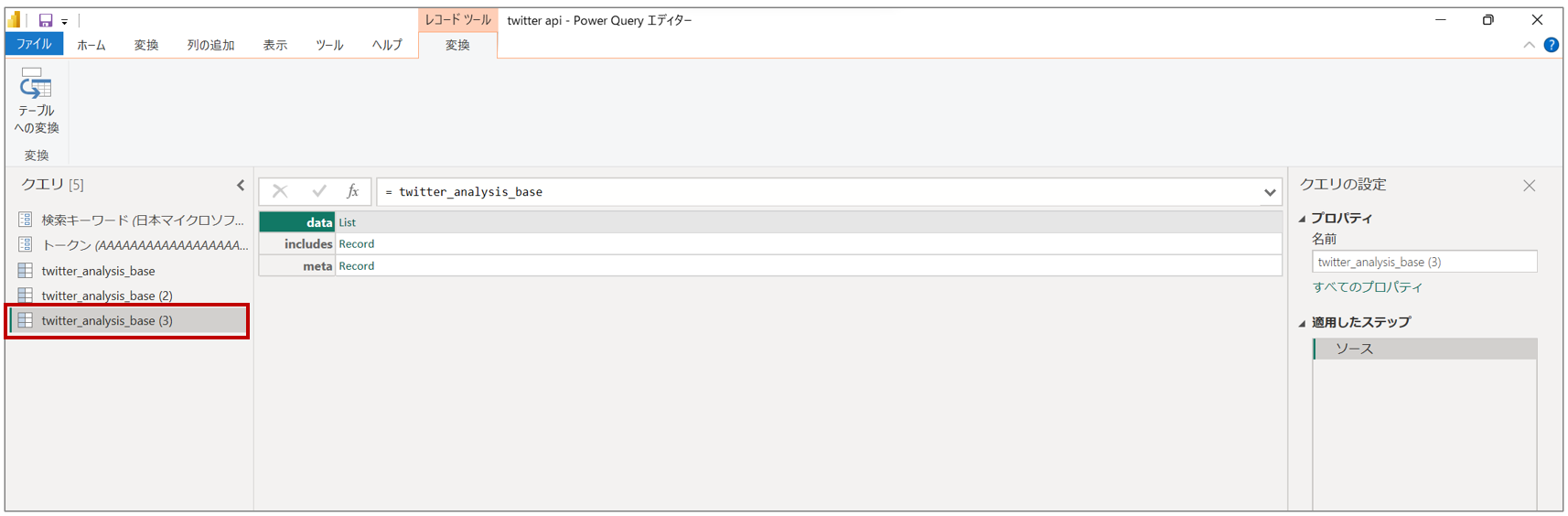
取得したデータ(下図例では twitter_analysis_base)を「参照」して、新しいクエリ(下図例では twitter_analysis_base (2))を生成する


-
再度取得したデータ(下図例では twitter_analysis_base)を「参照」して、新しいクエリ(下図例では twitter_analysis_base (3))を生成する

-
新しく生成したクエリのそれぞれの名前を変更する。1つは「data」用、もう1つは「include」の中の「users」用 (下図例では、それぞれ twitter_analysis_data、twitter_analysis_users に変更)
- twitter_analysis_base (2) → twitter_analysis_data へ変更

- twitter_analysis_base (3) → twitter_analysis_users へ変更

2. 「data」(ツイート内容) を整形
data 部分には、1 レコードずつツイート内容が格納されているので整形していきます。
-
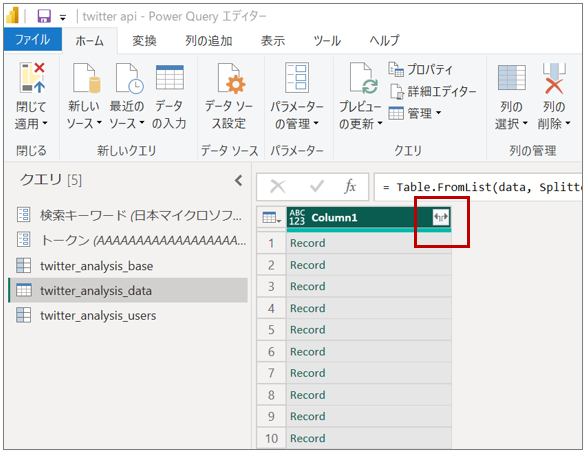
「twitter_analysis_data」 の 「data」 の 「List」をクリックする

-
展開されたリストをテーブルに変換する

- 表示されたテーブルへの変換ダイアログはそのまま OK を押す

- 表示されたテーブルへの変換ダイアログはそのまま OK を押す
-
Column1 の横の展開ボタンを押してレコードの中身を展開する
- 展開時は、「元の列名をプレフィックスとして使用します」のチェックボックスを外す

- 展開時は、「元の列名をプレフィックスとして使用します」のチェックボックスを外す
-
3で展開された項目のうち、「public_metrics」 の横の展開ボタンを押してレコードの中身を展開する

- 展開時は、「元の列名をプレフィックスとして使用します」のチェックボックスを外す

- 展開時は、「元の列名をプレフィックスとして使用します」のチェックボックスを外す
-
3で展開された項目のうち、「edit_history_tweet_ids」は今回使用しないので、削除する

-
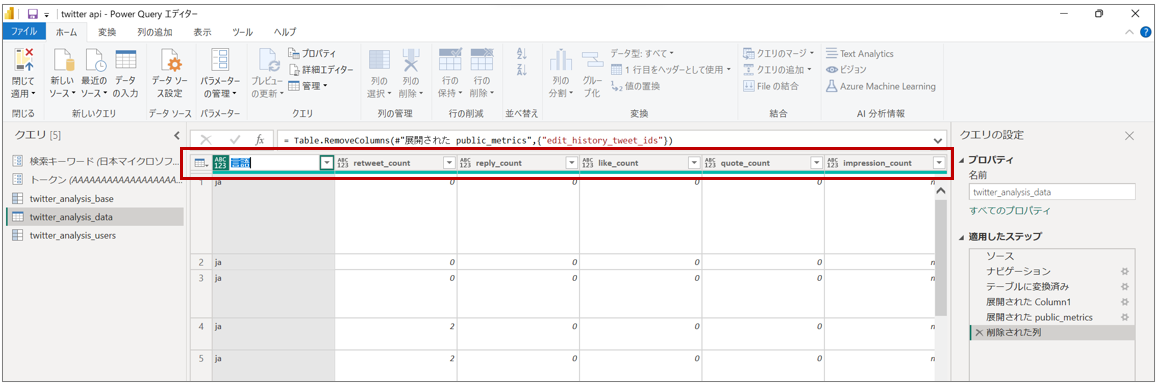
項目の名前をわかりやすくするため一つずつ変更し、また、各項目の型を変更する
| 項目名(変更前) | 項目名(変更後) | 型 |
|---|---|---|
| lang | 言語 | テキスト |
| retweet_count | リツイート数 | 整数 |
| reply_count | リプライ数 | 整数 |
| like_count | いいね数 | 整数 |
| quote_count | 引用数 | 整数 |
| impression_count | 表示数 | 整数 |
| text | ツイートテキスト | テキスト |
| created_at | ツイート日時 | 日付/時刻/タイムゾーン |
| id | ツイートID | テキスト |
| author_id | ユーザーID | テキスト |
※2023年1月17日現在、Twitter API が 項目「source」 を返さなくなっているため、こちらの一覧からは除外しています。
-
項目名の変更(各項目をダブルクリックして変更)
-
型の変更(各項目の左のアイコンを変更)

3. 「include」(それ以外の情報:今回はユーザー情報のみ)を整形
include 部分には、ツイート内容以外の情報が格納されており、今回はユーザー情報のみ取得するよう指定しています。user の中に1 レコードずつツイートしたユーザーの情報が格納されているので整形していきます。
-
「twitter_analysis_users」 の 「includes」 の 「Record」をクリックする

-
「users」の 「List」をクリックする
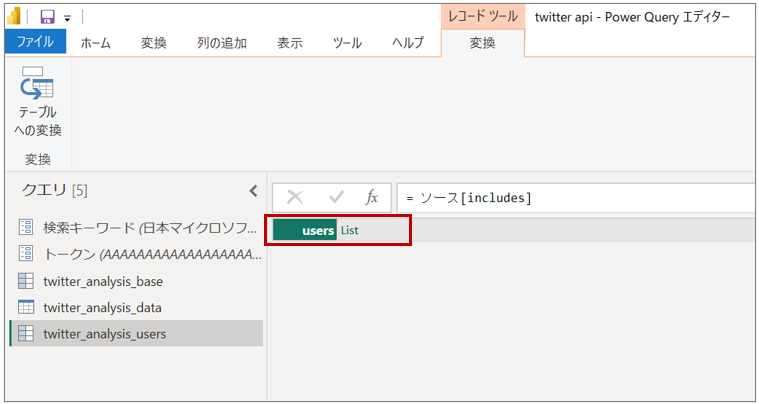
-
展開されたリストをテーブルに変換する

表示されたテーブルへの変換ダイアログはそのまま OK を押す

-
Column1 の横の展開ボタンを押してレコードの中身を展開する

- 展開時は、「元の列名をプレフィックスとして使用します」のチェックボックスを外す

- 展開時は、「元の列名をプレフィックスとして使用します」のチェックボックスを外す
-
4で展開された項目のうち、「public_metrics」 の横の展開ボタンを押してレコードの中身を展開する

- 展開時は、「元の列名をプレフィックスとして使用します」のチェックボックスを外す

-
項目の名前をわかりやすくするため一つずつ変更し、また、各項目の型を変更する
| 項目名(変更前) | 項目名(変更後) | 型 |
|---|---|---|
| id | ユーザーID | テキスト |
| description | ユーザー説明 | テキスト |
| username | ユーザーハンドルネーム | テキスト |
| profile_image_url | ユーザープロフィール画像URL | テキスト |
| url | ユーザープロフィールURL | テキスト |
| followers_count | フォロワー数 | 整数 |
| following_count | フォロー数 | 整数 |
| tweet_count | ツイート数 | 整数 |
| listed_count | リスト数 | 整数 |
| name | ユーザープロフィール名 | テキスト |
| created_at | ユーザー作成日時 | 日付/時刻/タイムゾーン |
| location | 場所 | テキスト |
4. ツイートテキストを Text Analytics でキーフレーズ抽出 (※要 Premium ライセンス)
Power BI の Premium 機能である Text Analytics のキーフレーズ抽出機能を使って、ツイート内容から主要なキーフレーズをマイニングします。
実装には、Premium ライセンス(Power BI Premium Per User もしくは Power BI Premium Per Capacity)が必要です。(試用版でも可)
ワードクラウドを作成しない場合はこのステップは飛ばすことも可能です。
-
twitter_analysis_dataを「参照」して、新しいクエリ(下図例では twitter_analysis_data (2))を生成する

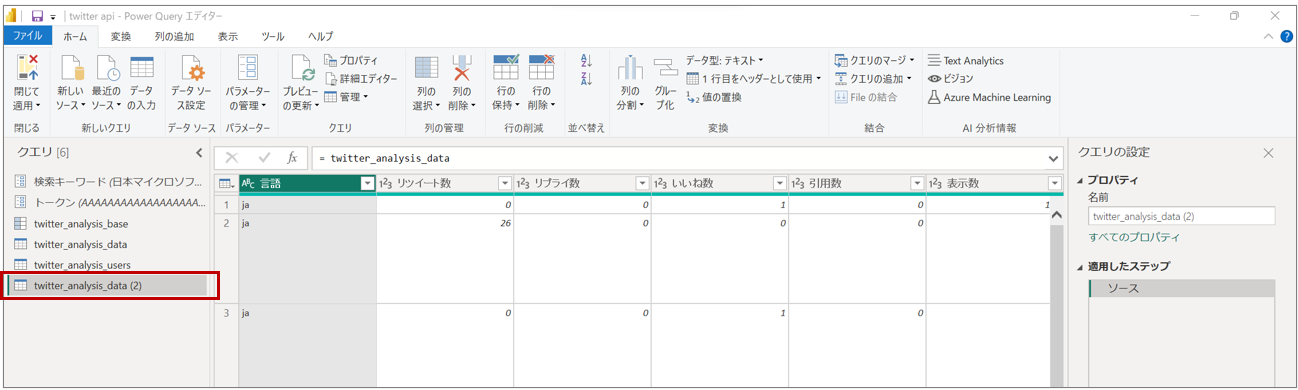
-
新しく生成したクエリの名前を変更する。 (下図例では、twitter_analysis_keyphrase に変更)
- twitter_analysis_data (2) → twitter_analysis_keyphrase へ変更

- twitter_analysis_data (2) → twitter_analysis_keyphrase へ変更
-
ツイートID、ツイートテキスト 以外の項目を削除する
- ツイートID と ツイートテキスト 列を Ctrl キーを押しながら選択し、右クリックメニューで「他の列の削除」をクリック

- ツイートID と ツイートテキスト 列を Ctrl キーを押しながら選択し、右クリックメニューで「他の列の削除」をクリック
-
ツイートテキストを選択して、AI 分析情報の「Text Analytics」を選択

-
Text Analytics ダイアログで、「Extract key phrases」を選択し、「Text」 で 「ツイートテキスト」 が選択されていることを確認し、OK ボタンを押す

-
キーフレーズ抽出された結果が、「Extract key phrases」列と「Extract key phrases.KeyPhrase」列に抽出される。
- 「Extract key phrases」列 → キーフレーズ抽出された結果をカンマ区切りですべて格納
- 「Extract key phrases.KeyPhrase」列 → キーフレーズ抽出された結果を1語1レコードで格納
→ 今回は 「ツイートID」と「Extract key phrases.KeyPhrase」を使用するので、その他の列を削除する

-
「Extract key phrases.KeyPhrase」列の名前を 「キーフレーズ」に変更する

-
キーフレーズ列の値の前後に空白が入っているため、トリミングする
- 「キーフレーズ」列を右クリックして、「変換」→「トリミング」を選択
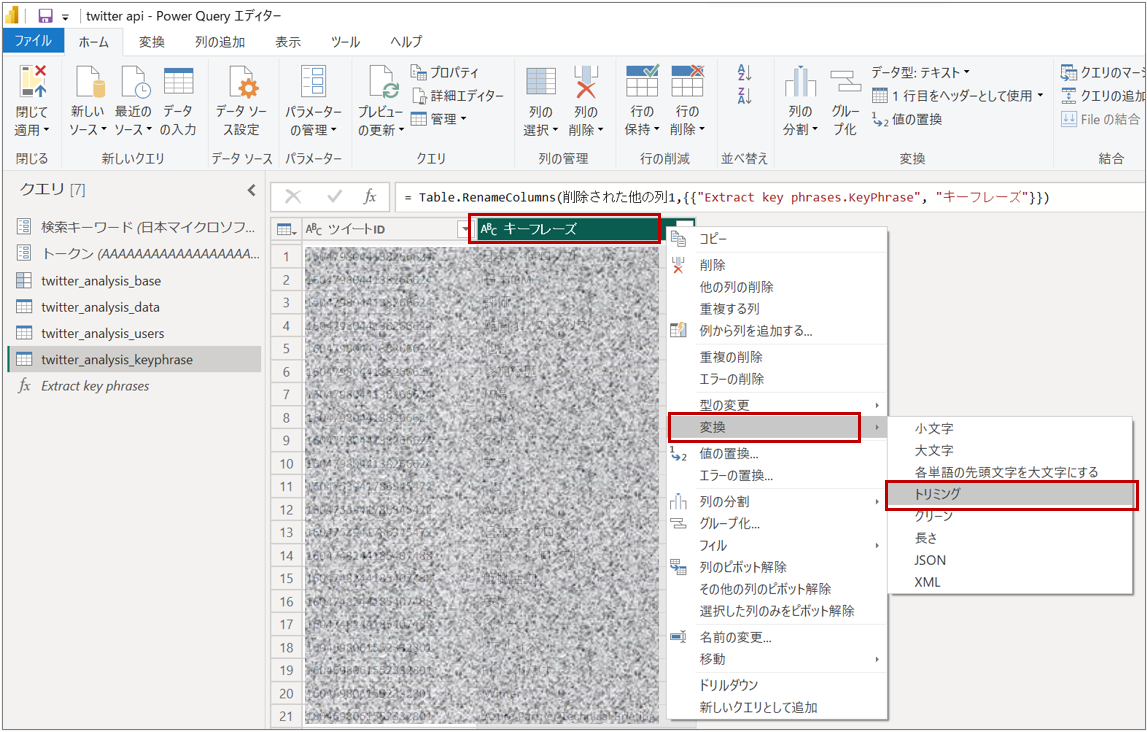
- 「キーフレーズ」列を右クリックして、「変換」→「トリミング」を選択
データ整形の最後に
twitter_analysis_base から、3種類のデータ(ツイート内容、ユーザー情報、キーフレーズ)を作成しましたが、この本体は可視化には使用しないので、読み込みをOFFにします。(読み込みをOFFにしても、レポートの更新をONにしておけば、このデータを基にしている3つのデータはしっかりと更新されます)

ここまででデータ整形が完了しました。
今回はここまでとし、次回はいよいよデータを取り込み、ビジュアル作成・可視化していきます。