はじめに
MDN Web Docs の HTML: コンテンツの作成 のページを読みます。
読み進め方や、なぜ今あらためて MDN Web Docs を読んでいるのかについては、前回の記事に書きました。
今回はこのページを読みながら、HTML の基本的な要素の考え方や、<head> 要素に入る情報、文字コード、viewport、アクセシビリティについて確認したことをまとめます。
読みながら確認したこと
ページを読み進めながら、気になったことや理解を整理したことを書いていきます。
HTML とは(再確認)
まず、HTML とは何かをあらためて確認しました。
HTML は、コンテンツの構造や意味を定義するマークアップ言語 です。
タグでコンテンツを囲んで要素を表現し、それらの要素を組み合わせて HTML 文書全体を作ります。
なぜ構造や意味を定義する必要があるのかというと、HTML は単に見た目を作るためのものではないからです。見た目を整えるのは主に CSS の役割で、HTML は「それが何であるか」を表します。
人間がコードを読むときにも構造が分かりやすくなるだけでなく、見出し、段落、リンクといった役割を要素で明示することで、ブラウザや検索エンジンが文書を理解しやすくなります。
そうした意味で、適切な HTML を書くことは SEO の土台にもなるのだなと理解しました。
HTML 要素はどのようにできているか
要素は、たとえば次のように 開始タグ・内容・終了タグ で構成されています。
<p id="msg">HTML は、コンテンツの構造や意味を定義するマークアップ言語です。</p>
この例では、<p> が開始タグ、HTML は、コンテンツの構造や意味を定義するマークアップ言語です。 が内容、</p> が終了タグです。
また、開始タグの中にある id="msg" は 属性 です。
属性は、その要素についての追加情報を表します。
要素が「タグで囲まれた内容」であり、さらに属性で情報を追加できる、というのは基本として押さえておこうと思いました。
id 属性と JavaScript の関係
本文では「要素 (element)」という言葉が使われていて、ここで JavaScript で動きをつける際に DOM 操作をするときの getElementById の Element のことだと理解が繋がりました。
const el = document.getElementById("msg");
このように書くと、id="msg" を持つ HTML 要素を取得できます。
私は React を使ったフロントエンド開発しか経験がなく、DOM を直接操作する機会が実務ではありませんでした。
そのため getElementById についても理解していなかったのですが、これは id 属性を手がかりに HTML 要素を取得するためのメソッドなのだと確認できました。
今回のページでは、このほかにも属性、要素の入れ子、空要素について説明がありましたが、そのあたりは理解が難しい点はなかったです。
HTML 文書全体はどう構成されるのか
続いて、初めての HTML 文書の作成 の説明を読みながら、個々の要素を組み合わせて HTML 文書全体を作る流れを確認しました。
ここであらためて意識したのが、HTML は単にタグを並べるだけではなく、文書全体に役割分担があるということです。
特に気になったのが、<head> 要素です。
<head> 要素には何が書かれているのか
MDN では、<head> 要素について次のように説明されています。
ページの閲覧者に向けて表示するためのコンテンツではない、 HTML ページに含めたいものをすべて収めるための入れ物です。検索エンジン向けのキーワードやページのディスクリプション(説明書き)、ページの見た目を変更するための CSS、文字コードの宣言などを含みます。
この説明を読んで、実際に Yahoo! の検索ページを検証ツールで確認してみました。
すると、たとえば次のような meta 要素が含まれていました。
<meta name="description" content="Yahoo!検索による「スマレジ」のウェブ検索結果です。">
<meta name="keywords" content="スマレジ">
<head> にはページ本文として表示される内容ではなく、文書の設定や補助情報 が入っているのだとわかります。
普段ブラウザでページを見るときには意識しませんが、文書の裏側では、検索エンジン向けの情報や文字コード、CSS などがここにまとめられています。
HTML 文書は、画面に見えている部分だけでできているわけではないのだと実感しました。
文字コードとは何か
<head> 要素の中には、次のような記述もあります。
<meta charset="utf-8">
これは、この文書が UTF-8 という文字コードで書かれていることを示しています。
ここで、文字コードとは何かも整理しました。
コンピューターの中では、文字はそのまま保存されるわけではなく、バイト列として保存されます。
そのため、「どの文字をどのバイト列で表すか」という対応のルールが必要になります。このルールが文字コードです。
参考にしたページはこちらです。
普段は utf-8 を何となく書いていましたが、「なぜ必要なのか」をあらためて考えると、文字を正しく表示するための前提そのものだと分かります。
文字化けはどういうときに起きるのか
文字コードを確認した流れで、文字化けがどういうときに起きるのかを試してみます。
文字化けは、ファイルを保存したときの文字コードと、ブラウザが読み込むときの文字コードが一致しないとき に発生します。
今回、デモ用の HTML ファイルを用意して確認しました。
UTF-8 で保存されたファイルを UTF-8 として読み込む場合
UTF-8 のバイト列で保存したファイルを、ブラウザが <meta charset="utf-8"> を見て UTF-8 として読み込むと、正しく表示されます。
<meta charset="utf-8">

UTF-8 で保存されたファイルを Shift_JIS として読み込む場合
一方で、ファイル自体は UTF-8 で保存されているのに、<meta charset="shift_jis"> と書いて Shift_JIS として読ませると、既視感のある文字化けが起きました。
<meta charset="shift_jis">

実際に試してみると、文字コードの宣言は、ブラウザが文書をどう解釈するかを決める重要な情報 なのだとよく分かりました。
viewport を設定しないとどうなるのか
<head> の中に入る情報として、もうひとつ気になったのが viewport の設定です。
MDN では、viewport について次のように説明されています。
このビューポート属性は、このページがある幅のビューポートで描画されることを保証し、モバイルブラウザーがビューポートより広い幅でページを描画した上で縮小して表示するのを防止します。
この説明を読んで、「では設定しないとどうなるのか」が気になったので、こちらも試してみました。
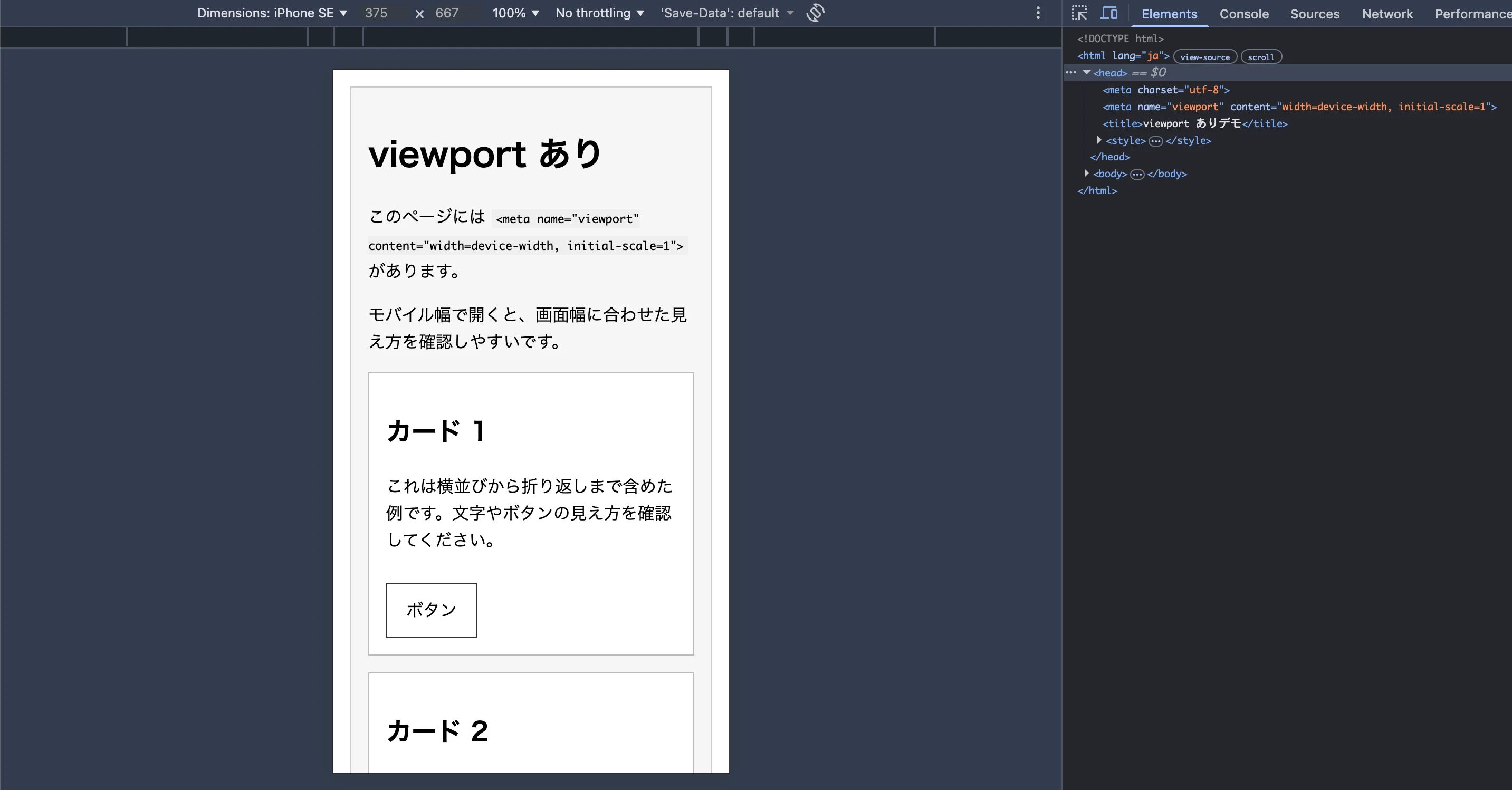
上記は viewport を設定しているページをスマートフォン幅で表示している様子です。
viewport を設定していないページをスマートフォン幅で表示すると、下記のように PC 向けの広いページをそのまま縮小したような見え方 になります。
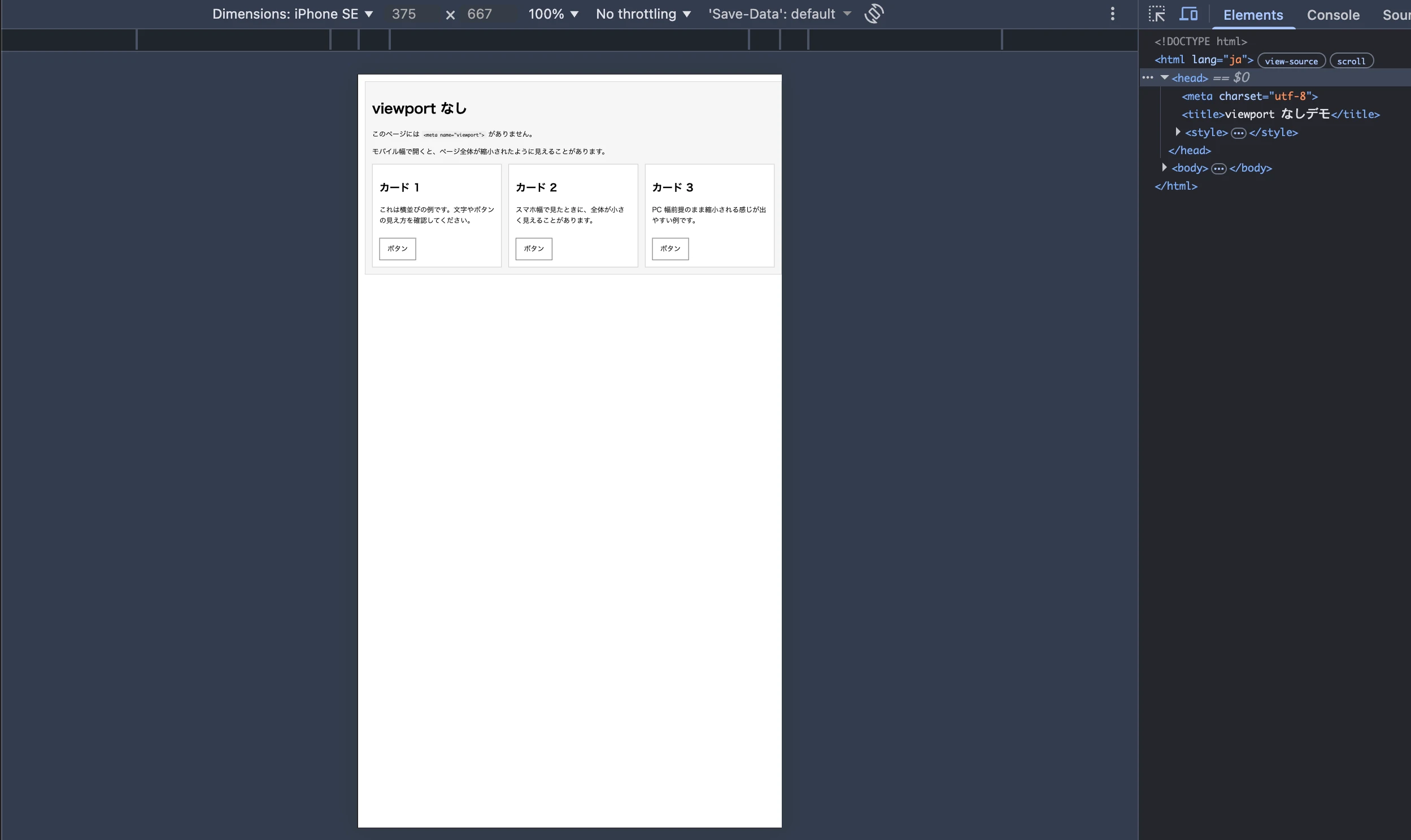
その結果、文字やレイアウトが小さく表示されて、見づらくなります。
普段はテンプレートの中に最初から書かれているので深く考えていませんでしたが、viewport の指定はモバイルでの表示を自然にするために重要なのだと確認できました。
アクセシビリティとは何か
本文の中では、アクセシビリティにも触れられていました。
アクセシビリティとは、ハンディキャップのある人を含め、できるだけ多くの人が Web サイトやアプリを使えるようにする考え方 です。
MDN Web Docs のアクセシビリティに関するページでは、次のように説明されています。
かつては我々はアクセシビリティのことをハンディキャップを持つ人々のためのものだと考えていましたが、現在はモバイル端末や遅いネットワークを利用している人々のためのものでもあると考えられています。
これを読んで、アクセシビリティは単に身体的なハンディキャップへの配慮だけではなく、利用環境の違いも含めて、より多くの人が使えるようにすること なのだと理解しました。
HTML の文脈で考えると、適切な要素を使って文書をマークアップすることが、アクセシビリティの土台にもつながっているのだと理解しました。
補足: <a> タグと React の SPA について
今回の MDN のページを読んでいて、リンクを表す HTML 要素としての <a> タグについても、あらためて考えるきっかけになりました。
<a> タグは本来、別のページや別の場所へのリンクを表す HTML 要素です。
一方で、SPA(Single Page Application)では、アプリ内の画面遷移を <a> タグでそのまま行うと、HTML 文書全体の再読み込みが発生することがあります。
そのため、React の SPA では React Router などを使って、再読み込みを避けながら必要な画面だけを切り替える形で遷移するのだと認識できました。
これは今回の MDN ページの中心テーマではありませんが、HTML の要素の意味を理解し直すことで、普段 React で何気なく使っている仕組みも整理しやすくなると感じました。
おわりに
MDN Web Docs の HTML: コンテンツの作成 のページを読み進めて、HTML の基本をあらためて整理できました。
普段から HTML のコードには触れているので、分かったつもりになっていた部分も多かったのですが、読み直してみると、<head> に入る情報の意味や、文字コード、viewport の役割など、曖昧だったところをきちんと確認できたのがよかったです。
特に今回は、
- HTML は、要素を組み合わせて文書全体を作ること
-
<head>には、表示されないが重要な情報が入ること - 文字コードの指定が、文字化けに直結すること
- viewport の設定が、モバイル表示に重要なこと
このあたりを、自分の中で整理できました。
引き続き MDN を読みながら、基礎の理解を少しずつ固めていきたいと思います。
ありがとうございました。
Web 開発の会社に入社してすでに 4 年経過した私が基礎勉強している様子を見て焦らず進んでほしい、という形での応援で、イベント参加、タグづけしています ![]()