はじめに
AIエージェントを作るときに、AIエージェントに様々なtoolを持たせることがあります。リモートまたはローカルMCPサーバーを使うこともあれば、自作したtoolを使うこともあると思います。
Strands AgentsではCommunity Built Toolsとして、いくつかのtoolがpip installするだけで簡単に使えます。今回はそのtool一覧を使いながらまとめてみます(数が多いので一部だけ)。
パッケージインストール
基本的には下記でインストール可能ですが、一部ツールは追加のインストールが必要になります。
pip install strands-agents-tools
例:mem0 toolの場合
pip install 'strands-agents-tools[mem0_memory]'
RAG & Memory
retrieve
環境変数であらかじめ作成したナレッジベースのIDを環境変数KNOWLEDGE_BASE_IDで設定するだけで参照してくれそうです。お手軽!
import os
from strands import Agent
from strands_tools import retrieve
os.environ["KNOWLEDGE_BASE_ID"] = "XXXXXXXXXX"
os.environ["AWS_REGION"] = "ap-northeast-1"
agent = Agent(tools=[retrieve])
agent("田中さんって誰?")
% python3 retrieve.py
田中さんについて調べてみますね。
Tool #1: retrieve
知識ベースによると、田中さんはIT会社の社長とのことです。
ただし、この情報は限定的ですので、もし特定の田中さんについてより詳しい情報が必要でしたら、より具体的な質問をしていただければと思います。例えば、どのような文脈で田中さんについて知りたいのか、会社名や他の詳細があれば教えてください。
memory
memoryツールでは以下の5つができるようです。
store:ナレッジベースに新たなドキュメントを保存
delete:ナレッジベースに保存されたドキュメントを削除
list:ナレッジベースに保存されているドキュメント一覧を取得
get:ナレッジベースに保存されているドキュメントの内容取得
retrieve:先ほどのretrieveツールと同様、セマンティック検索を行う
memoryツールはデータソースをカスタムデータソースにする必要があります。retrieveツールのようにS3をデータソースとする場合はエラーとなります。
storeとdeleteの処理については処理前にユーザーへの確認が発生します。もしAIエージェントに組み込み、自動で処理をさせたい時は環境変数BYPASS_TOOL_CONSENTをfalseにすることで確認無しの処理ができますが、意図しないデータ追加・削除が発生する可能性もあるので利用には注意してください。
agent_core_memory
こちらはAgentCore Memoryに対してRECORD、RETRIEVE、LIST、GET、DELETEの操作ができます。memoryツールのAgentCore Memory版ですね。AgentCore Memoryのパラメータであるmemory_id、actor_id、session_id、namespaceはツールの初期化時に必要となります。
# Initialize with required parameters
provider = AgentCoreMemoryToolProvider(
memory_id="memory-123abc", # Required
actor_id="user-456", # Required
session_id="session-789", # Required
namespace="default", # Required
)
mem0_memory
Mem0という記憶管理ソフトウェアにstore/delete/list/get/retrieveの処理ができます。ナレッジベースやAgentCore Memory以外にもメモリ保存するツールがあるんですね。
File Operations
editor
リッチテキスト表示にも対応した、ファイル編集ツールです。以下のように、様々な処理ができます。
view:ファイルの読み取り、ディレクトリ構造の表示
create:新規ファイルの作成、親ディレクトリの作成
str_replace:文字列置換
pattern_replace:正規表現を用いた文字列置換
insert:特定行へのテキスト挿入
find_line:特定のテキストが書かれた行数の検出
undo_edit:編集内容のundo
file_read
このツールはファイルの読み取りができるツールですが、2つのファイルのdiffを取得する機能もあります。
file_write
こちらはファイル書き込みツールです。editorツール同様、テキストだけではなくPythonプログラムなどの書き込みもできます。
Shell & System
environment
環境変数の管理をするツールです。環境変数の表示、作成、削除等の操作が可能です。
shell
任意のコマンドを実行するツールです。並列実行も可能なオプションが有りました。
cron
crontabを使ったジョブの定期実行を設定できます。処理の内容として、以下5つがあります。rawは特殊な処理な気がします。crontabに対して無知なので、いまいち使い所がわかっていません。(crontabで複雑な設定をするときにrawが使われるようです)
list:設定されているcronジョブの一覧。crontab -lと同義。
add:cronジョブの新規追加
remove:設定されているcronジョブの削除
edit:設定されているcronジョブの編集
raw:crontab行をそのまま追加
addはrawにはない以下のようなコードがあります。このフォーマット処理の有無がaddとrawの違いです。
# Format the cron job
description_text = f"# {_sanitize_description(description)}" if description else ""
cron_line = f"{schedule} {command} {description_text}".strip()
use_computer
一言で言えば、LLMがPCを操作するツールです。このツールは別途use_computerパッケージをインストールする必要があります。
pip install 'strands-agents-tools[use_computer]'
VSCodeでコードを書いて試してみましたが、画面の読み取りがうまくいかず、期待していた動作をしませんでした。後日またトライしてみようと思います。
Code Interpretation
python_repl
REPL(Read-Eval-Print Loop)環境を提供し、Pythonコードを実行することができるツールです。Windowsは対応していないようです。
code_interpreter
AgentCoreのビルトインツールである、Code Interpreterを使えます。
Strands Agentsを使わずにCode Interpreterを利用する方法もありますが、セッション管理が不要(裏側でやってくれる)であったり、よりシンプルにコードを書けます。
Strands Agentsを使ったやり方
Bedrock AgentCore SDKを使ったやり方
Web & Network
http_request
このツールは任意のURLに対してHTTPリクエストができるツールです。GITHUB_TOKENやSLACK_BOT_TOKENなどのトークンを環境変数で認証情報を渡すと認証が必要なURLに対してもAPIリクエストができるようになります。単にWebページの検索をするときはTavilyに分がありますが、http_requestツールではPOST/PUT/DELETEの操作もできる点で大きくできることが異なります。
slack
名前の通り、slackに関する操作が可能です。
メッセージの送信はもちろん、チャンネルに投稿されたメッセージの履歴取得やリアクションをすることもできるようです。簡単にSlack上で動作するAIエージェントも作れそうです。
browser
browserツールはAgentCore Browserを利用してブラウザ操作ができるツールです。ちなみに、Strands Agents以外にもブラウザ操作が可能なフレームワークとしてNova ActとPlaywrightが紹介されています。
rss
RSSフィードを確認できるツールです。現在のRSSエントリの確認はもちろん、subscribeをした上で更新部分を抽出することもできそうです(要保存先ストレージ)。
Multi-modal
generate_image_stability
Stability Platform APIを使い、画像生成をするツールです。利用するためにはStabilityのAPIキーを発行し、環境変数(STABILITY_API_KEY)で設定する必要があります。
image_reader
画像(PNG, JPEG/JPG, GIF, WebP)を読み取り、どんな画像であるかを分析できるツールです。
generate_image
generate_image_stabilityと似ていますが、こちらはBedrockのStability AIのモデルを使って画像を生成できます。環境変数(STABILITY_API_KEY)がなくても利用できるのが特徴ですね(利用可能リージョンはus-west-2のみ)。
nova_reels
text-to-video(T2V)とimage-to-video(I2V)による動画生成ができるツールです。画像生成ツールと異なる点として、作成された動画はS3に保存されるため、ツール利用時に保存先のS3バケット名を教える必要があります。
speak
text-to-speachで音声を生成するツールです。Mac標準のsayコマンドを使って音声を読み上げるモードとAmazon Pollyを使って音声を作成をするモードの2種類あります。どちらも簡単に作成可能です。
余談ですが、Amazon Polly初心者なので、最初日本語を片言で喋る音声ファイルを作ってしまいました。voice_idを指定して自然な日本語で喋る音声を生成できるので言語に合わせて作成しましょう。
diagram
クラウドのアーキテクチャ図やUML図を作成してくれるツールです。試しにサーバーレス構成の図を作成させてみました。
from strands import Agent
from strands_tools import diagram
agent = Agent(tools=[diagram])
agent("API Gateway、Lambda、DynamoDBを使用して、ユーザー情報を管理するシステムのアーキテクチャ図をdiagram_typeをcloudとして、ツールを活用して作成してください。")
agentへの指示文にdiagram_typeをcloudとして、と書いていますが、これを書かないと(私の環境では)シーケンス図やクラス図が出てきました。色んな図を作成できる反面、明確に指示が必要になります。
構成図を作成時、下記エラーが発生したためgraphvizをインストールしてエラーを解消しました。
ERROR:root:Failed to create cloud diagram: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATH
brew install graphviz
下記のような図が出来上がりました。
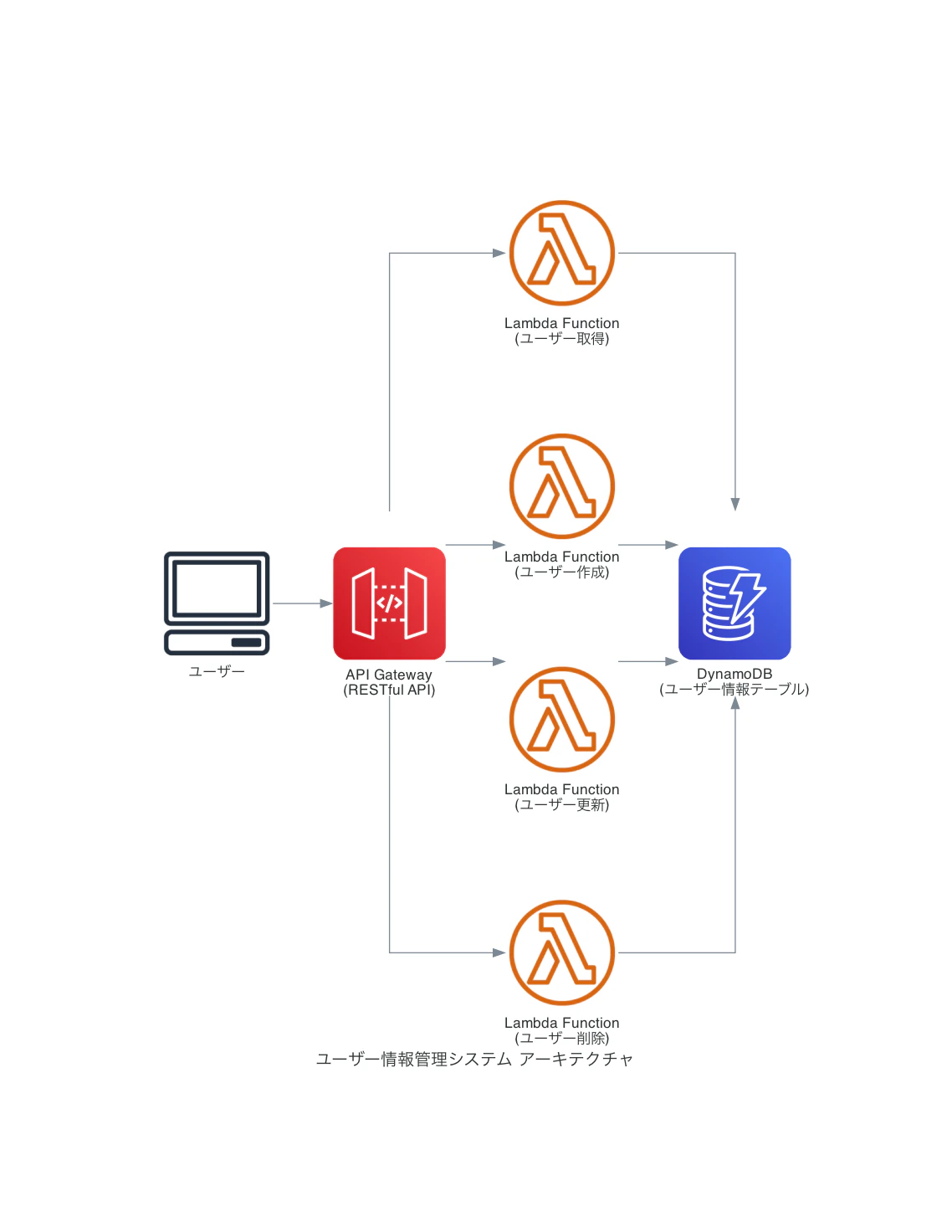
diagramsというPythonライブラリを経由して様々なAWSアイコンを使った構成図が作成できるようです。
上記の構成図にBedrockを加えるように指示しました。どうしてこうなった。
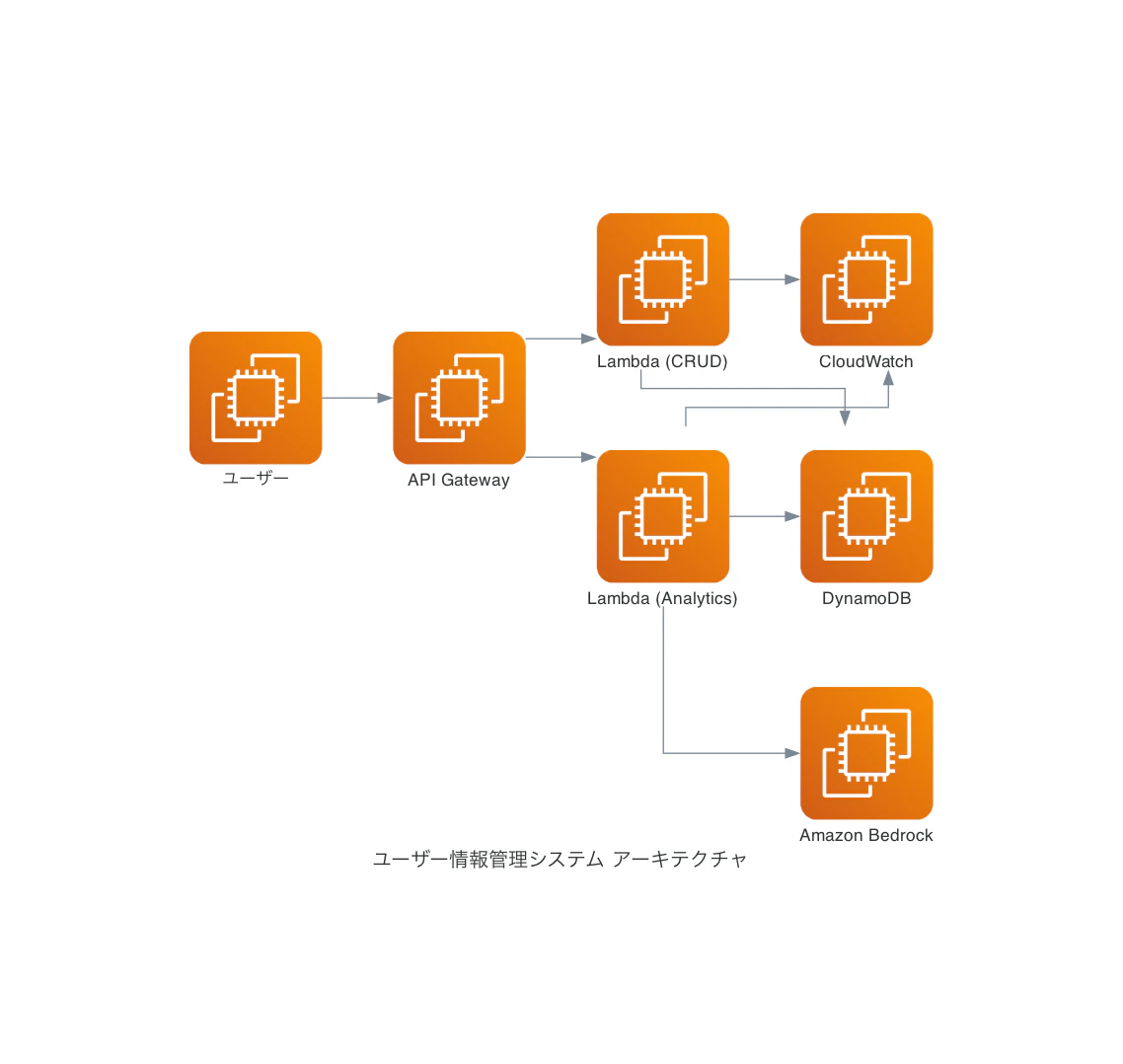
AWS Services
use_aws
このツールはboto3を使ってAWSリソースを操作できるツールです。できることはAWS API MCPサーバーと同じなので、単にAWSリソースを操作するだけであれば差はよくわかりませんでした。
Utilities
calculator
計算ツールです。よくサンプルコードとかでも出てきますが、四則演算以外にも三角関数の取り扱いや微積分もできるようなので、思ってる以上に高度な計算ができそうです。
current_time
ISO 8601形式 (2023-04-15T14:32:16.123456+00:00)で現在時刻を取得できるツールです。
ただし、このツールがISO 8601形式で取得されるというだけで、実際にAIエージェント応答でどのようにレスポンスするかはLLMやシステムプロンプト次第です。
デフォルトではUTCで時刻が返されますが、私の環境で日本語で時刻を聞いたところ、JSTの時刻も教えてくれました。
load_tool
通常、ツールは事前にエージェントに持たせることで動作しますが、このツールは動的にPythonファイルを読み込み、そのファイルの中に@toolデコレータがあれば、そのツールを参照して使えるようにします。ツールだけ別ファイルで実装して、後から読み込ませたい時に使えそうです。
sleep
このツールはシンプルで、指定された秒数待機(sleep)させることができるツールです。環境変数MAX_SLEEP_SECONDSで設定可能な最大時間を指定でき、デフォルトでは300秒(5分)です。
Agents & Workflows
このカテゴリのツールは私の知識不足もあって完全に理解できていないです。
graph
Strands SDK Graphを使って、有向非巡回グラフ(DAG)の作成や実行ができるツールです。決まったワークフローに沿ってエージェントを動かすケースでは使えそうです。
agent_graph
このツールもグラフを作って実行できるという点は同じですが、star/mesh/hierarchicalといったトポロジーでグラフを作成できます。
journal
日々の作業内容をジャーナル(日記)として作成してくれるツールです。ジャーナルと言いつつ、add_taskという機能もあり、TODOリストの管理ができます。日々の作業内容を記録するエージェントに使えそうですかね(要永続化)。
swarm
スウォームと聞くと、スクラム開発におけるスウォーミングのことを想像しますが、複数のエージェントが一つのタスクに注力するようなイメージです。GitHubのサンプルとして以下のようなコードがありました。
下記コードを実行すると、ツールが見つからない、と警告が出ます。各エージェントにツールを使わせたいときは親エージェントにツールを持たせる必要があります。
(イメージとしては、親エージェントが「これ使ってね」とツールを渡す感じでしょうか)
Agent 'market_researcher' missing tools: {'retrieve', 'calculator'}
Agent 'product_strategist' missing tools: {'calculator', 'file_write'}
Agent 'creative_director' missing tools: {'generate_image', 'file_write'}
from strands import Agent
from strands_tools import swarm
agent = Agent(tools=[swarm])
# Define custom agent team
result = agent.tool.swarm(
task="Develop a comprehensive product launch strategy",
agents=[
{
"name": "market_researcher",
"system_prompt": (
"You are a market research specialist. Focus on market analysis, "
"customer insights, and competitive landscape."
),
"tools": ["retrieve", "calculator"],
"model_provider": "bedrock",
"model_settings": {"model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0"}
},
{
"name": "product_strategist",
"system_prompt": (
"You are a product strategy specialist. Focus on positioning, "
"value propositions, and go-to-market planning."
),
"tools": ["file_write", "calculator"],
"model_provider": "anthropic",
"model_settings": {"model_id": "claude-sonnet-4-20250514"}
},
{
"name": "creative_director",
"system_prompt": (
"You are a creative marketing specialist. Focus on campaigns, "
"branding, messaging, and creative concepts."
),
"tools": ["generate_image", "file_write"],
"model_provider": "openai",
"model_settings": {"model_id": "o4-mini"}
}
]
)
マルチエージェントと何が違うのだろう、と思ったのでChatGPTに聞きながら整理していたのですが、マルチエージェントと明確に違うなと感じた点はどのエージェントにもTaskを共有している点かと思いました。それぞれのタスクがゴールを意識して回答や調査を行うと考えれば精度が上がったりするかもと思いました。
(有識者の方のコメントお待ちしております!)
stop
エージェントに対して、次の思考やツール使用を止める指示をして、次のイベントの発生を抑制します(結果、出力が止まる)。内部的にはstop_event_loopというフラグをTrueにしています。
handoff_to_user
判断を人間側に委ねることができるツールです。ツール側で重大な処理前にはyes/noを入力させる機能があるものもありますが、本ツールによりそのような機能を明示的につけることができます。内部的にはbreakout_of_loopというフラグがあり、一時中断してユーザーが承認/否認してからエージェントが処理を継続するものと、完全に停止し処理を止める2パターンがあります。
ドキュメント内にもこのツールを使ったHuman-in-the-Loopの記載があります。
use_agent
エージェントの中で、使い捨てのエージェントが作成されるツールです。エージェントが処理の中で、別エージェントに聞いた方が良いと判断した時に使うツールのようです。いまいちマルチエージェントで事前に定義しておくケースとの差別化点がわかっていないので、ユースケースが思いついていないです。
think
Inputに対して、指定された回数(cycle_count)分だけ新しいAgentを作成しながら思考を繰り返し、より深い回答を導き出すツールです。Claude Codeにおけるultrathinkのようなものかなと解釈しました。
use_llm(非推奨)
一時的なエージェントが作成されるツールですが、現時点で非推奨のAPIとなっており、use_agentを使うことが案内されています。
以下はコード上に記載されていた内容です。
logger.warning(
"DEPRECATION WARNING: use_llm will be removed in the next major release. "
"Migration path: replace use_llm calls with use_agent for equivalent functionality."
)
workflow
名前の通り、AIエージェントのワークフローを管理するツールです。graphツールと似たようなものですが、workflowツールでは、タスクごとにpriorityパラメータがあり、優先度に応じてどのタスクを優先して行うかをあらかじめ設定できます。
batch
このツールは複数のツールを並列で実行し、複数ツールの結果を統合して1つのResponseを返すものです。例えば、通常であれば、「ツールA利用→結果応答→ツールB利用→結果応答→最終結果」のように、逐次処理がされますが、batchツールでは「ツールA、ツールB利用→最終結果」といった形で単一の応答が返されるツールです。ツール間で応答結果を引き継ぐ必要がない処理では使えそうです。
a2a_client
AIエージェント同士がやり取りするためのプロトコルA2Aを扱うツールです。
以下ページのサンプルが一番わかりやすいと思いますが、既知のエージェントURLをA2AClientToolProviderとして設定することで、エージェントが他のエージェントと通信するための準備をします。
エージェントが必要に応じて外部のエージェントを検索、ツール取得を行い回答を生成します。
Tool Consent and Bypassing
ツールの紹介は以上ですが、これらのツールを扱う上で考慮すべき環境変数があります。書き込みや削除、作成などリソースに何らかの変化があるような操作は、デフォルトでユーザーに確認を行います。確認を求めない場合は環境変数BYPASS_TOOL_CONSENTをtrueにすることで、確認を省略できます。
Trueではなく、"true"で設定します。
os.environ["BYPASS_TOOL_CONSENT"] = "true"
想定される実行環境としては以下に記載がありました。
- ユーザーインタラクション(ユーザーによる応答)が不可能な自動化されたワークフロー
- 開発およびテスト環境
- CI/CDパイプライン
- 運用の安全性をすでに検証している状況
まとめ
Strands Agentsで提供されているツールを試しながら紹介しました。簡単に扱えるものから、少し複雑なものもあるので各ユースケースに応じて使いこなしたいですね!