現代のデジタルプロダクトは、ユーザー行動シグナルによって成否が決まります。すべてのページビュー、クリック、カート追加、購入には即時のビジネス価値がありますが、それは「意味のあるタイミング」で処理されてこそ価値を発揮します。
近年、多くのチームが以下を必要としています。
- リアルタイムのトラフィック可視化(今、ユーザーが何をしているかを把握)
- 継続的に更新されるコンバージョンファネル
- バッチ遅延のないセッション単位の KPI
- BI、実験、AI 向けのオープンな分析ストレージ
- Kafka に依存しない、低運用コストなパイプライン
従来のバッチ ETL は数分から数時間の遅延を引き起こし、Kafka ベースのストリーミングスタックは、多くのチームにとって不要なインフラ複雑性を追加します。こうした課題に対して、RisingWave Events API はよりシンプルな代替手段を提供します。
HTTP 経由でイベントを直接取り込み、Postgres ライクな マテリアライズドビューを使ってリアルタイム処理を行い、結果を Apache Iceberg に永続化することで、Kafka を一切使わない完全なリアルタイム・クリックストリームパイプラインを構築できます。
Kafka が適切な選択となる場合(そして RisingWave との関係)
Kafka は、RisingWave のような単一の宛先へのバッファではなく、組織全体で共有されるイベント基盤が必要な場合に、今なお明確な強みを持っています。
第一に、Kafka のエコシステムは非常に巨大です。Kafka Connect は、ソースおよびシンクのための標準フレームワークと、実証済みの運用パターンを提供しており、コミュニティやベンダーによって維持されている豊富なコネクタと統合が存在します。
これは、Kafka が RisingWave のような単一のデータベースではなく、複数のシステムの中間に位置する必要がある場合に特に有効です。
第二に、Kafka は 長期保持・準永続ストレージ・リプレイを設計上の前提とするユースケースで強みを発揮します。階層型ストレージ(Tiered Storage)を利用することで、Kafka は計算とストレージを分離し、古いログセグメントをリモートストレージやオブジェクトストレージへオフロードできます。
これにより、Kafka の消費モデルを維持したまま、コスト効率よく大量の履歴データを保持でき、履歴リプレイ、バックフィル、監査、災害復旧、新規コンシューマのオンボーディングに最適です。
第三に、Kafka は多数のプロデューサーとコンシューマー間での厳格なデータ契約とスキーマ進化が必要な場合に自然な選択となります。
Schema Registry により、チームは(Avro、Protobuf、JSON Schema などの)スキーマを一元管理・検証し、互換性ルールを強制し、クライアントは実行時に ID を用いてスキーマを解決できます。
これは、フォーマットが時間とともに進化する大規模分散組織において特に価値があります。
これらの Kafka ネイティブな利点が必要な場合、「両者のいいとこ取り」として、Kafka をイベント基盤として維持しつつ、Kafka コネクタ を通じて RisingWave に取り込む方法があります。
RisingWave は Kafka バックエンドのソースおよびテーブル作成をサポートし、Avro などのフォーマット用に Schema Registry とも統合可能です。これにより、Kafka への投資を維持しながら、下流で RisingWave のストリーミング SQL とマテリアライズドビューを活用できます。
ユースケースとアーキテクチャ概要:Iceberg へのリアルタイム・クリックストリーム分析
本ブログでは、以下を実現する完全なリアルタイム・クリックストリーム分析パイプラインとアーキテクチャを構築します。
- RisingWave の Events API を使用し、オンラインプラットフォームから HTTP 経由でクリックストリームイベントを取り込み(JSON および高スループットな NDJSON バッチをサポート)
- RisingWave テーブルを用いて、ユーザー、セッション、デバイス、キャンペーン、ページなどの主要エンティティをモデリング
- RisingWave マテリアライズドビューによる継続的な JOIN を通じて、イベントをリアルタイムでエンリッチ
- エンゲージメント、滞在時間、収益、ファネル進行状況を含むセッション単位の KPI およびファネルをリアルタイムで計算
- Apache Iceberg にエンリッチ済みデータをストリーミング保存(Lakekeeper REST カタログ + MinIO を使用)
- データは Apache Iceberg 形式で保存されるため、RisingWave、Spark、Trino、BI ツール、その他の Iceberg 互換クエリエンジンから直接クエリ可能
これらすべてを、Postgres ライクな SQL、最小限のサービス構成、そして Kafka なしで実現します。
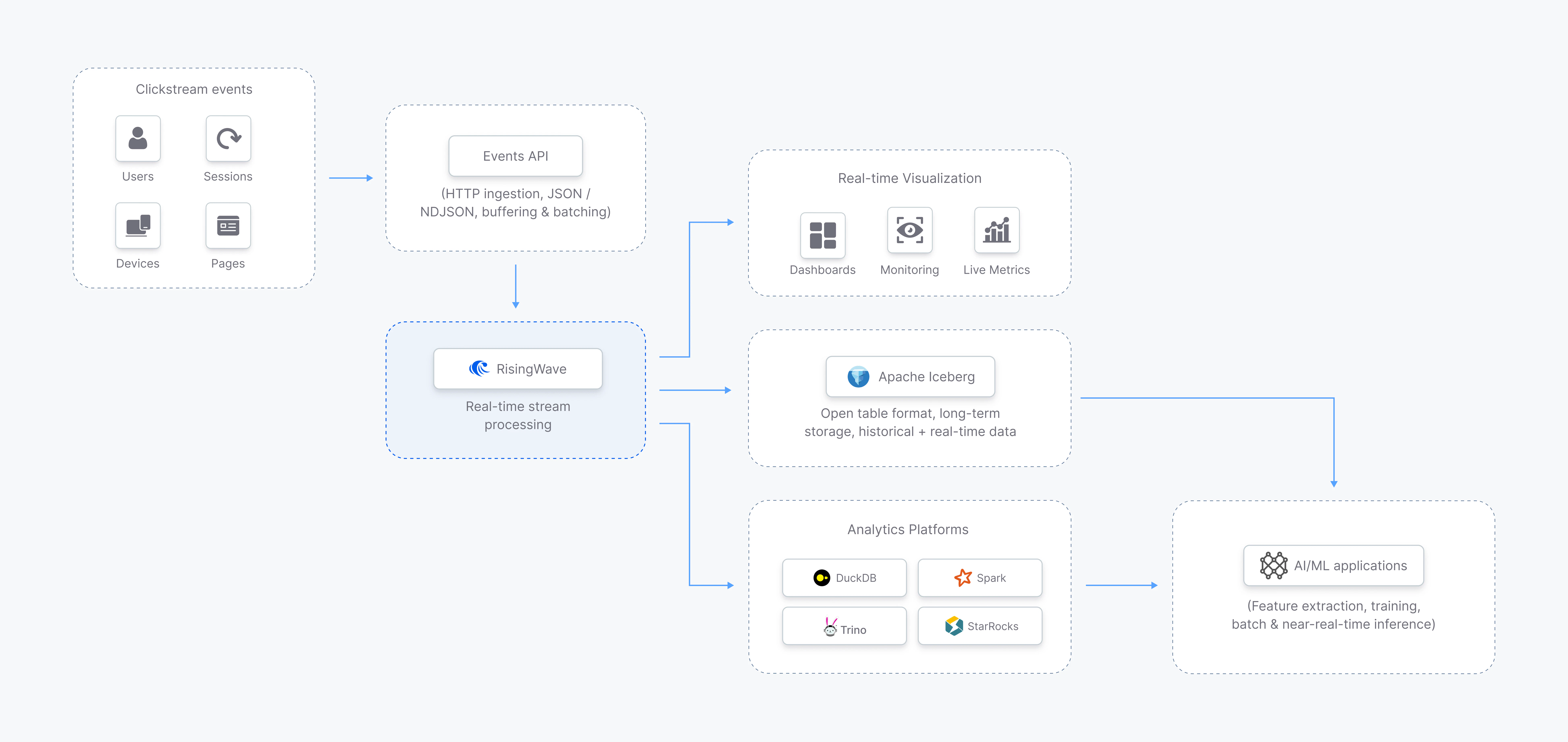
RisingWave Events API を用いたクリックストリームデータの取り込み
RisingWave Events API をどのように利用し、アーキテクチャへ統合するかを示すために、本ブログでは RisingWave の awesome-stream-processing リポジトリに含まれる、エンドツーエンドで実行可能な デモ を使用します。
リポジトリをクローンし、スタックを起動
まず、RisingWave の awesome-stream-processing リポジトリをクローンし、デモディレクトリへ移動して各サービスを起動します。
起動されるサービスは以下の通りです。
-
RisingWave(
localhost:4566) -
Events API(
localhost:8000) - Lakekeeper(Iceberg REST カタログ)
- MinIO(S3 互換オブジェクトストレージ)
- クリックストリーム HTTP プロデューサー(NDJSON バッチ送信)
git clone https://github.com/risingwavelabs/awesome-stream-processing.git
cd awesome-stream-processing/07-iceberg-demos/clickstream_events_api_to_iceberg
docker compose up -d
RisingWave への接続
Docker Compose により RisingWave は localhost:4566 で起動されます。以下のように psql を使用して接続します。
psql -h localhost -p 4566 -d dev -U root
クリックストリームテーブルのモデリング(Events API 取り込み)
Kafka トピックの代わりに、イベントは HTTP 経由で直接送信されます。
POST /v1/events?name=<table>- JSON および NDJSON をサポート
- 高スループットのための Append-only テーブル
コアテーブル
パフォーマンス最適化のため、以下の Append-only テーブルを作成します。
usersdevicessessionscampaignspage_catalogclickstream_events
これらのテーブルは、HTTP プロデューサーによって継続的にデータが書き込まれます。
-- Users
CREATE TABLE users (
user_id BIGINT,
full_name VARCHAR,
email VARCHAR,
country VARCHAR,
signup_time TIMESTAMPTZ,
marketing_opt_in BOOLEAN,
ingested_at TIMESTAMPTZ
) WITH (appendonly = 'true');
-- Devices
CREATE TABLE devices (
device_id VARCHAR,
device_type VARCHAR,
os VARCHAR,
browser VARCHAR,
user_agent VARCHAR,
ingested_at TIMESTAMPTZ
) WITH (appendonly = 'true');
-- Sessions
CREATE TABLE sessions (
session_id VARCHAR,
user_id BIGINT,
device_id VARCHAR,
session_start TIMESTAMPTZ,
ip_address VARCHAR,
geo_city VARCHAR,
geo_region VARCHAR,
ingested_at TIMESTAMPTZ
) WITH (appendonly = 'true');
-- Campaigns
CREATE TABLE campaigns (
campaign_id VARCHAR,
source VARCHAR,
medium VARCHAR,
campaign VARCHAR,
content VARCHAR,
term VARCHAR,
ingested_at TIMESTAMPTZ
) WITH (appendonly = 'true');
-- Page catalog
CREATE TABLE page_catalog (
page_url VARCHAR,
page_category VARCHAR,
product_id VARCHAR,
product_category VARCHAR,
ingested_at TIMESTAMPTZ
) WITH (appendonly = 'true');
-- Clickstream events
CREATE TABLE clickstream_events (
event_id VARCHAR,
user_id BIGINT,
session_id VARCHAR,
event_type VARCHAR, -- page_view/click/add_to_cart/checkout_start/purchase
page_url VARCHAR,
element_id VARCHAR,
event_time TIMESTAMPTZ, -- client event time
referrer VARCHAR,
campaign_id VARCHAR,
revenue_usd DOUBLE PRECISION,
ingested_at TIMESTAMPTZ -- ingest time
)WITH (appendonly = 'true');
マテリアライズドビュー:リアルタイムエンリッチメント(中核ロジック)
MV 1 — 完全にエンリッチされたクリックストリーム
このマテリアライズドビューは、イベント → ユーザー → セッション → デバイス → ページ → キャンペーンを JOIN し、テーブルに新しいイベントが到着するたびに継続的に更新されます。
CREATE MATERIALIZED VIEW clickstream_joined_mv AS
SELECT
e.event_id,
e.event_time,
e.ingested_at,
e.event_type,
e.user_id,
u.full_name,
u.country,
u.marketing_opt_in,
s.session_id,
s.session_start,
s.geo_city,
s.geo_region,
d.device_type,
d.os,
d.browser,
e.page_url,
p.page_category,
p.product_id,
p.product_category,
e.element_id,
e.referrer,
c.source AS campaign_source,
c.medium AS campaign_medium,
c.campaign AS campaign_name,
e.revenue_usd
FROM clickstream_events e
LEFT JOIN users u ON e.user_id = u.user_id
LEFT JOIN sessions s ON e.session_id = s.session_id
LEFT JOIN devices d ON s.device_id = d.device_id
LEFT JOIN page_catalog p ON e.page_url = p.page_url
LEFT JOIN campaigns c ON e.campaign_id = c.campaign_id;
MV 2 — リアルタイム・セッション KPI とファネル
このマテリアライズドビューは、セッション単位の指標をリアルタイムで計算します。
含まれる指標は以下の通りです。
- 最初/最後のイベント時刻
- セッション継続時間
- イベントタイプ別カウント
(ページビュー、クリック、カート追加、チェックアウト開始、購入) - 総収益
- 購入有無フラグ
CREATE MATERIALIZED VIEW session_kpi_mv AS
SELECT
s.session_id,
s.user_id,
u.country,
d.device_type,
MIN(e.event_time) AS first_event_time,
MAX(e.event_time) AS last_event_time,
EXTRACT(EPOCH FROM (MAX(e.event_time) - MIN(e.event_time)))::BIGINT AS session_duration_seconds,
SUM(CASE WHEN e.event_type = 'page_view' THEN 1 ELSE 0 END) AS page_views,
SUM(CASE WHEN e.event_type = 'click' THEN 1 ELSE 0 END) AS clicks,
SUM(CASE WHEN e.event_type = 'add_to_cart' THEN 1 ELSE 0 END) AS add_to_cart,
SUM(CASE WHEN e.event_type = 'checkout_start' THEN 1 ELSE 0 END) AS checkout_start,
SUM(CASE WHEN e.event_type = 'purchase' THEN 1 ELSE 0 END) AS purchases,
COALESCE(SUM(e.revenue_usd), 0) AS revenue_usd,
CASE WHEN SUM(CASE WHEN e.event_type='purchase' THEN 1 ELSE 0 END) > 0 THEN TRUE ELSE FALSE END AS did_purchase
FROM sessions s
LEFT JOIN clickstream_events e ON e.session_id = s.session_id
LEFT JOIN users u ON s.user_id = u.user_id
LEFT JOIN devices d ON s.device_id = d.device_id
GROUP BY s.session_id, s.user_id, u.country, d.device_type;
作成したテーブルおよびマテリアライズドビューに対して、リアルタイム分析クエリを実行してみましょう。
ライブトラフィック(直近 5 分間)
以下のクエリは、直近 5 分間における1 分単位のイベント数と収益を表示します。
SELECT
date_trunc('minute', event_time) AS minute,
COUNT(*) AS events,
SUM(revenue_usd) AS revenue
FROM clickstream_events
WHERE event_time > now() - interval '5 minutes'
GROUP BY 1;
デバイス別コンバージョン率
このクエリは、購入完了を基準として、デバイスタイプ別のセッション単位コンバージョン率を算出します。
SELECT
device_type,
COUNT(*) FILTER (WHERE did_purchase) AS converted,
COUNT(*) AS sessions,
ROUND(100.0 * COUNT(*) FILTER (WHERE did_purchase) / COUNT(*), 2) AS conversion_pct
FROM session_kpi_mv
GROUP BY device_type;
リアルタイム分析結果を Apache Iceberg に永続化
処理・分析済みデータは、Lakekeeper を用いたセルフホスト型 Iceberg カタログ を利用し、RisingWave ネイティブ Iceberg テーブル に保存します。
Iceberg 接続の作成(Lakekeeper + MinIO)
以下の設定により、MinIO(S3 互換ストレージ)をバックエンドとするIceberg REST カタログ(Lakekeeper)接続を作成します。これにより、RisingWave は指定された warehouse 内の Iceberg テーブルを読み書きできるようになります。
CREATE CONNECTION lakekeeper_catalog_conn
WITH (
type = 'iceberg',
catalog.type = 'rest',
catalog.uri = 'http://lakekeeper:8181/catalog/',
warehouse.path = 'risingwave-warehouse',
s3.access.key = 'hummockadmin',
s3.secret.key = 'hummockadmin',
s3.path.style.access = 'true',
s3.endpoint = 'http://minio-0:9301',
s3.region = 'us-east-1'
);
この構成により、Glue や Nessie、特定ベンダーへのロックインなしで、Iceberg 仕様に完全準拠した REST カタログを利用できます。
Iceberg エンジンの有効化
事前に定義した Lakekeeper カタログを、RisingWave の Iceberg エンジン接続として設定します。
SET iceberg_engine_connection = 'public.lakekeeper_catalog_conn';
ネイティブ Iceberg テーブルの作成
以下は、エンリッチ済みクリックストリームデータを保存するRisingWave 管理の Iceberg テーブルを作成します。
CREATE TABLE clickstream_joined_iceberg (
event_id VARCHAR,
event_time TIMESTAMPTZ,
event_type VARCHAR,
user_id BIGINT,
session_id VARCHAR,
device_type VARCHAR,
page_url VARCHAR,
campaign_source VARCHAR,
revenue_usd DOUBLE PRECISION
)
WITH (commit_checkpoint_interval = 1)
ENGINE = iceberg;
この Iceberg テーブルは、1 秒間隔でコミットされるため、常に最新の状態が保たれます.commit_checkpoint_interval は、RisingWave が Iceberg テーブルへデータをコミットする頻度を制御します。
Iceberg への継続的ストリーミング書き込み
以下のクエリにより、エンリッチ済みマテリアライズドビューから Iceberg テーブルへ継続的にデータを書き込みます。
INSERT INTO clickstream_joined_iceberg
SELECT * FROM clickstream_joined_mv;
結果確認として、ネイティブ Iceberg テーブルを直接クエリすることも可能です。
SELECT * FROM clickstream_joined_iceberg LIMIT 5;
Spark / Trino / DuckDB から同一データをクエリ
データは Apache Iceberg 形式で保存されているため、Lakekeeper REST カタログを使用して、
- Spark
- Trino
- DuckDB
- その他の Iceberg 対応クエリエンジン
から直接クエリできます。エクスポートやデータ複製は不要です。これにより、以下が可能になります。
- エンジン横断の分析とデータ共有
- 機械学習向け特徴量抽出
- 履歴データとリアルタイムデータの JOIN
- オープンフォーマットによる長期保存
戦略的メリット
このアーキテクチャは、以下の価値を提供します。
- 真のリアルタイム取り込み・分析・保存・低遅延配信
- Kafka 運用コストの完全排除
- Postgres ライクな SQL のみでのストリーム処理
- オープンな分析ストレージ(Iceberg)
- ClickHouse、StarRocks、BigQuery、Snowflake などへのストリーミング連携
- Superset、Grafana、Metabase などの BI ツールとのシームレスな統合
- AI / ML 向けの特徴量エンジニアリングおよび抽出
まとめ
本ブログでは、RisingWave + Events API を用いて、**HTTP(JSON / NDJSON)**経由でクリックストリームデータを取り込み、マテリアライズドビューによってリアルタイムにイベントをエンリッチし、セッション KPI とファネルを即時計算する完全なリアルタイム分析パイプラインを構築しました。
さらに、結果を Apache Iceberg に継続的に保存し、RisingWave、Spark、Trino から同一データを直接クエリできることを示しました。
このアプローチにより、RisingWave は低遅延・オープン・運用がシンプルな分析パイプラインを、Kafka なし、バッチ遅延なし、ロックインなしで実現できることを示しています。