
昨年以降、Apache Iceberg はデータインフラ界で最も注目されているトピックのひとつとなっています。
Databricks は最近、サーバーレス Postgres を構築しているスタートアップ Neon を 10億ドル で買収しました。Snowflake もまた、エンタープライズ向けの老舗 Postgres プロバイダーである Crunchy Data を約 2億5,000万ドル で買収しました。
これらは無作為な買収ではありません。2つの大手データベースベンダーが同じストーリーに賭けていることを示しています。すなわち — Postgres + Apache Iceberg:Postgres はトランザクション処理や小規模なクエリを、Iceberg は大規模分析を担い、両者が同じベンダーのエコシステム内で結び付けられるという構図です。
Postgres と Apache Iceberg はどちらも成熟したシステムですが、多くの人が十分に考えていない疑問があります。それは — Postgres から Apache Iceberg へリアルタイムにデータをストリーミングするにはどうすればいいのか?
一見簡単そうに聞こえます。既存の CDC(Change Data Capture)システム、たとえば Debezium を使って変更イベントを Iceberg に直接書き込めばいい、と。しかし現実はそう単純ではありません。
驚くべき事実はこうです。Snowflake、Databricks、Redshift といった主流システムは、Iceberg への「プレーンな CDC 書き込み」をネイティブにサポートしていない のです。
この記事では、多くの人が語らない部分を明らかにし、RisingWave がどのようにして一連のエンジニアリング技術によって Iceberg への真のストリーミング CDC インジェスト を可能にしているのかを説明します。
CDC と Iceberg における2種類の削除方式
Postgres のような OLTP データベースでは、変更や削除は常に発生しています。実際、UPDATE は内部的には DELETE + INSERT として実装されます。データベース内部では透過的ですが、CDC を通じて変更をキャプチャすると、この詳細が極めて重要になります。
CDC イベントには通常、テーブル名、プライマリキー、古い値/新しい値が含まれますが — 下流システムにおける行の物理的な位置(たとえば Iceberg 内のファイルや行番号)は 含まれません。つまり、ライターは削除対象行の正確な物理位置を直接特定する手段を持たないのです。
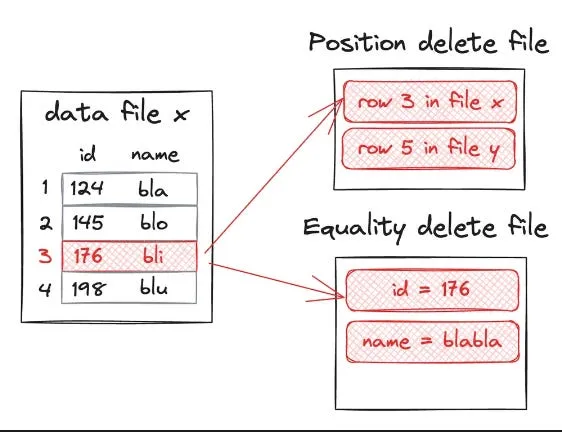
この問題に対処するため、Iceberg は行レベル削除のために2つの全く異なるメカニズムを定義しています。
Position delete
- 正確なファイルパス + 行番号で削除を行います。最大の利点はクエリ性能が高いことです。クエリエンジンは値の照合を行うことなく、指定された行を単純にスキップできます。
- ただし、これにはライターが事前に物理的な位置を知っている必要があります。バッチ処理のシナリオでは、削除前にテーブルをスキャンしてこの位置を特定することができます。しかしストリーミング CDC シナリオでは、削除ごとに Iceberg に対して位置を問い合わせる必要があり、ランダムリードやレイテンシーが発生し、高い同時実行性のもとではスループットが劇的に低下します。大規模テーブルでは、リアルタイム性能は事実上不可能になります。
Equality delete
- 列値の一致によって削除を行い、通常はプライマリキーを使用します。ライターは CDC イベントからプライマリキー値をイコーリティ削除ファイルに書き込むだけでよく、物理的位置は必要ありません。
- これはストリーミング CDC に自然に適合します。Debezium、Kafka Connect、Flink CDC、RisingWave のようなツールはこれらのファイルを直接生成できます。
- 欠点はクエリ時に merge-on-read が必要になることです。すなわちデータファイルと削除ファイルの両方をスキャンし、一致する行を除外しなければなりません。削除ファイルが蓄積すると(高頻度の CDC シナリオでは非常によくあること)、読み取り増幅が深刻になり、クエリレイテンシーとコストが上昇します。この問題を抑えるためには定期的な コンパクション が必要です。
Equality Delete vs. Position Delete: どちらを選ぶべきか?
機能的には、どちらの削除方式も絶対的に優れているわけではなく、それぞれ異なる目的に適しています。
バッチインジェスト(例:毎日のフルリフレッシュ):
まずデータファイルをスキャンして削除対象の行を特定し、その後ポジション削除を使用します。これにより最良のクエリ性能が得られます。削除ファイルには「パス + 行番号」しか格納されないため、クエリエンジンは値比較をせずに行をスキップできます。
ストリーミング CDC インジェスト(Postgres/MySQL などからの継続的な変更フィード):
ライターは物理的位置にアクセスできないため、イコーリティ削除のみが選択肢となります。これにより書き込みコストを低く抑え、レイテンシーも制御可能ですが、クエリ性能は定期的にイコーリティ削除をデータファイルにマージ(あるいはポジション削除に変換)しない限り低下します。
言い換えると、ストリーミング CDC シナリオにおいては、イコーリティ削除がほぼ唯一の実用的な選択肢 です。これにより書き込みは軽量かつ低レイテンシーになりますが、読み取り側では merge-on-read のコストを負担することになります。そして致命的なのは、下流のエンジンがイコーリティ削除をサポートしていなければ、CDC インジェストが単純に破綻してしまう という点です。
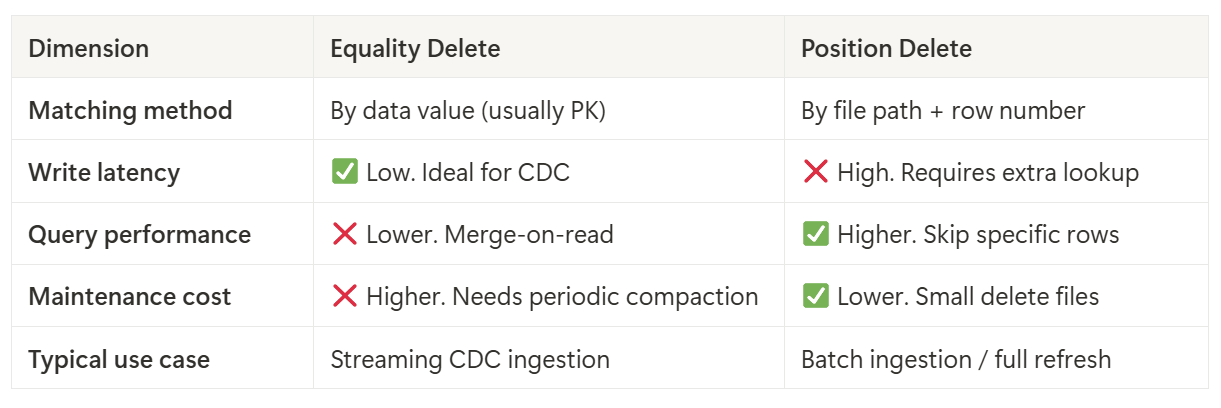
クエリエンジンにおける Equality Delete サポートの現状
Iceberg へのストリーミング CDC インジェストでは、イコーリティ削除が実質的に唯一の現実的な行レベル削除です。しかし Iceberg の仕様とクエリエンジンの実際のサポートは別物であり、現実は仕様ほど都合よくはいきません。
Snowflake
Snowflake には 2 種類の Iceberg モード があります:
- Snowflake 管理 Iceberg: Snowflake インフラを通じて Iceberg テーブルを完全にサポートし、読み取りと書き込みの両方を提供します。
- 外部管理 Iceberg: Iceberg テーブルが外部カタログ(例:AWS Glue)を使用する場合、Snowflake の機能は限定的です。特に、ポジション削除のみがサポートされ、削除ファイルの処理は不完全または信頼性が低い場合があります。
Databricks
Databricks も Iceberg テーブルをサポートしています、しかし:
- Databricks 管理 Iceberg: 行レベル削除は一切サポートされていません(イコーリティ削除もポジション削除も不可)。
- 外部管理 Iceberg: こちらも 行レベル削除はサポートされていません。
要するに Databricks では、削除の種類に関わらず一切クエリできません。
Amazon Redshift
Redshift は外部管理 Iceberg テーブルのみをサポートしています(Glue カタログ経由)。Redshift Spectrum や Serverless を通じてクエリされます。公式には Iceberg v2 の削除ファイルがサポートされており、イコーリティ削除も含まれます。
Equality Delete に関するコミュニティでの議論
Iceberg コミュニティでは、イコーリティ削除の長期的な役割について継続的な議論が行われています。メーリングリストには Equality Deletes を廃止する提案 などがあり、クエリ性能への悪影響や実装の複雑さを理由に存続に疑問を呈する声もあります。これに対し、別の返信 ではエンジニアが妥協策を共有していました:
- 低レイテンシーかつ高スループットなインジェストのためにまずイコーリティ削除を書き込む。
- 定期的にポジション削除へ変換したり、データファイルにマージしてクエリ性能とクロスエンジン互換性を回復する。
- インデックスや Bloom フィルターを用いてクエリ時の merge-on-read コストを削減する。
イコーリティ削除を放棄するのではなく、その性能コストを認識し、リアルタイム書き込みから非同期メンテナンスジョブへと負担を移すという考え方です。
複数の Iceberg PMC メンバーとの私的な会話からも明らかなように、大手クエリエンジンにおける完全なイコーリティ削除サポートは時間がかかります。意思がないわけではなく、複雑だからです。効率的なイコーリティ削除の読み取りには、複数のファイルメタデータを同時に処理し、ファイル横断的に値を照合し、それを分散実行計画にプッシュダウンする必要があります。これはストレージ、実行、ファイルフォーマットデコード層すべてに複雑さを追加します。Snowflake、Databricks、Redshift のようにクエリ性能を重視するシステムでは、I/O や CPU コストを大幅に増加させる機能は非常に慎重にしか採用されません。
RisingWave の解決策
RisingWave は現在、Apache Iceberg へのストリーミング CDC をエンドツーエンドでサポートする唯一のシステム であり、この分野の最先端ソリューションです。
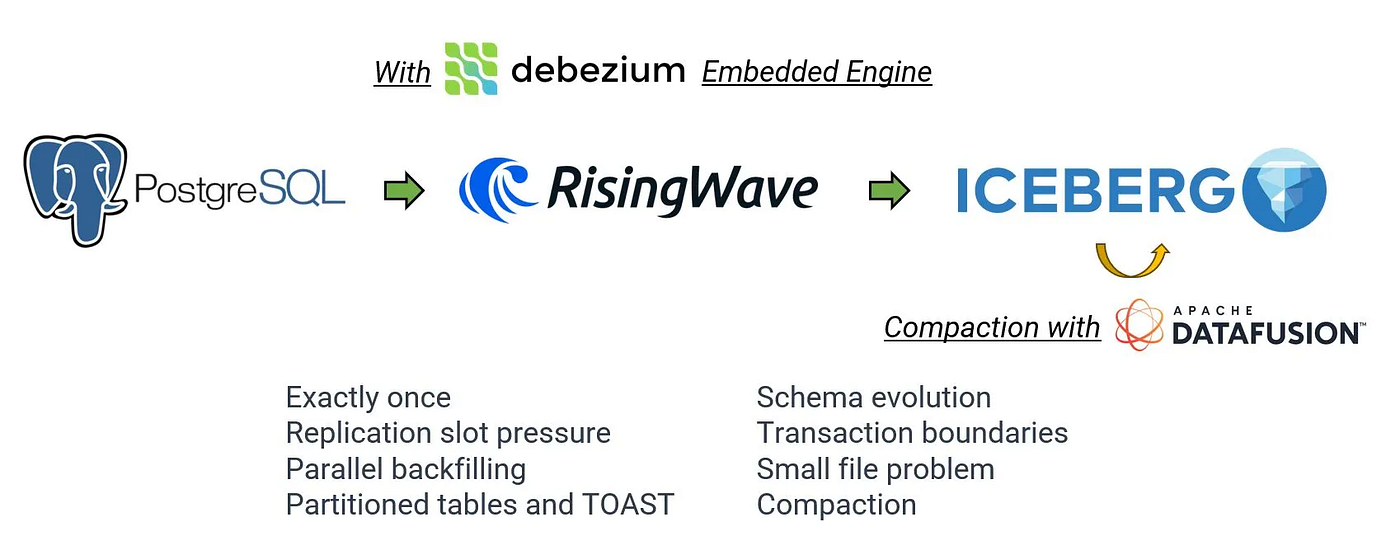
もしあなたが Postgres/MySQL → Apache Iceberg ストリーミング CDC を行う場合、特に高頻度の更新や削除があると、既存のソリューションは 削除処理 でつまずくことになります。問題はデータの書き込みではなく、イコーリティ削除かポジション削除かという選択にあります。
前述の通り、CDC シナリオでは イコーリティ削除が唯一現実的な選択肢 です。これにより書き込みは軽量で低レイテンシーになりますが、クエリエンジンは merge-on-read のコストを支払わなければなりません。さらに悪いことに、多くの主流エンジン(Snowflake、Databricks、Redshift)はイコーリティ削除を全くサポートしていないため、削除が反映されません。
RisingWave はこれを解決するため、CDC から Iceberg へのパイプラインをエンドツーエンドで構築し、以下のフェーズを備えています。
書き込みフェーズ: 高頻度の更新・削除に最適化
CDC シナリオでは、高頻度の更新や削除によって大量の Delete ファイルが生成されます。RisingWave は異なる削除戦略を組み合わせることで書き込み効率を最大化します:
- 同一バッチ内で複数回更新されたプライマリキー: 物理的位置がすでにバッチ内で判明しているため、より効率的な ポジション削除 を使用して対象行を削除し、余分な照合を回避。
- バッチ外のプライマリキーに対する更新や削除: 高価な物理位置ルックアップをスキップし、プライマリキーに基づいて イコーリティ削除 ファイルを直接生成(Postgres、MySQL、MongoDB、SQL Server などのソース対応)。
このハイブリッド手法により、バッチ内更新にはポジション削除の高性能を活用し、バッチ外変更にはイコーリティ削除の柔軟性を利用します。これにより高い同時実行性のもとでも低レイテンシーと高スループットを維持し、リアルタイム位置ルックアップによるランダム I/O やレイテンシーコストを回避します。
コンパクションフェーズ: スケジューラブルなコンパクション(データマージ)
大量の Equality Delete ファイルは深刻な 読み取り増幅 を引き起こします。クエリエンジンはデータファイルと削除ファイルの両方をスキャンし、値照合を行わなければならないからです。RisingWave は内部的にスケジューラブルなコンパクションサービスを実装しており(https://github.com/nimtable/iceberg-compaction、DataFusion プロジェクトベースのエンジン)、定期的にイコーリティ削除ファイルを除去し、小さいファイルを統合 します。これにより読み取り増幅やストレージ断片化を軽減しつつ、データの新鮮さを保持します:
-
低レイテンシーモード: コンパクション間隔を短縮(
Commit Checkpoint Interval、デフォルト 1 分)してデータをほぼリアルタイムで可視化。削除ファイルが一時的に増加しても鮮度を維持。 - オフライン分析モード: コンパクション間隔を延長し、ファイル生成頻度、S3 API コスト、小ファイル数を削減。
将来の最適化計画には以下が含まれます:
- 部分コンパクション: キーレンジに基づいてマージ範囲を制限し、不要なデータスキャンを削減。
- 超大規模テーブルコンパクションの最適化: タスク分割とマルチノード並列処理を強化し、TB/PB 級テーブルのコンパクションを高速化。
エクスポートフェーズ: クロスエンジン互換性の処理
Snowflake、Databricks、Redshift の外部テーブルモードでは、Equality Delete ファイルをサポートしないか、正しく解釈できません。この互換性ギャップを解消するため、RisingWave はエクスポート前に ターゲットコンパクション を実行し、削除ファイルのない「クリーン」バージョンを生成します:
- 内部のリアルタイムクエリは equality delete バージョンを利用し、低レイテンシーを維持。
- クロスプラットフォーム分析はクリーンバージョンを参照し、イコーリティ削除非対応エンジンとの互換性を確保。
Exactly-Once と冪等性保証
Flink CDC の OSS Iceberg コネクタや Kafka Connect の二相コミット(複雑かつ高負荷)とは異なり、RisingWave のカスタムログストアは 冪等コミット を提供します:
- すべてのコミットはリプレイ可能かつ検証可能で、重複書き込みやデータ損失を防止。
- パフォーマンスオーバーヘッドは最小限であり、高頻度更新・削除があるリアルタイムインジェストパイプラインに最適。
成功事例
Siemens はエンタープライズ向け Snowflake 顧客であり、大量の高並列業務データを Apache Iceberg にストリーミングし、Snowflake 上で分析する必要がありました。
RisingWave 導入前のプロセスは以下の通りです:
- リアルタイム CDC データは直接 Iceberg に書き込まれ、すべての削除は Equality Delete ファイルとしてマテリアライズされていました。
- しかし Snowflake 外部テーブルはイコーリティ削除を読み取れないため、Siemens は定期的に Spark ジョブを実行して削除ファイルをすべて除去(実質的にはフルコンパクション)する必要がありました。
- 削除ファイルがクリアされて初めて Snowflake がデータを正しく読み取れる状態でした。
この手法は Spark ジョブの実行によるレイテンシーと計算コストを追加し、リアルタイム可視性を低下させ、アーキテクチャの複雑さを増大させていました。
RisingWave 導入後、Siemens はハイブリッド削除戦略へ移行しました。すなわち、同一バッチ内で複数回更新されたプライマリキーにはポジション削除、バッチ外の更新・削除にはイコーリティ削除 を使用。
RisingWave の組み込みスケジューラブルコンパクションが適切なタイミングでイコーリティ削除ファイルを除去し、小ファイルを統合:
-
内部リアルタイムクエリ(リスク制御やモニタリングシステムなど)は、イコーリティ削除とポジション削除の両方を含む Iceberg テーブルを秒単位の鮮度で参照可能。
-
Snowflake 外部テーブル は RisingWave がエクスポートする「クリーン」バージョンを読み込み、Spark クリーンアップジョブを不要にし、イコーリティ削除互換性の問題を完全に回避。
この変革によりデータ可用性のレイテンシーはバッチレベルからリアルタイムへと短縮され、アーキテクチャは単純化し、運用負荷は軽減され、既存の BI ツールとの完全な互換性も維持されました。
結論
近年、Postgres + Apache Iceberg は技術的な話題から、Databricks、Snowflake、Redshift のような企業が戦略的に賭ける対象へと進化しました。しかし CDC インジェストを実際に実装すると、特に変更・削除処理の面で現実の厳しさに直面します。
主流エンジンはイコーリティ削除のサポートが一貫しておらず、クロスプラットフォーム互換性の乏しさが「Postgres から Iceberg へのストリーミング」を地雷原に変えています。
RisingWave のアプローチは実用的です。書き込み経路で不要な複雑さを避け、イコーリティ削除を効率的な CDC 選択肢として受け入れ、その後、制御可能なコンパクションとエクスポート前最適化でクエリ性能と互換性の問題を解決します。これにより書き込み側は軽量かつ高速に保たれ、読み取り側は必要に応じて削除ファイルのないクリーンバージョンを得ることができます。
これはエンジニアリング上のトレードオフです。理論的な完璧さを追うのではなく、予測可能なレイテンシーと透明なコストで本番稼働に耐える CDC→Iceberg システムを構築することに重点を置いています。言い換えると、私たちが構築しているのは単なる「高速な CDC ツール」ではなく、実際のワークロードにおいて長期的に稼働できる CDC インジェストシステム なのです。