Apache Iceberg スタックの構築は、通常かなり複雑です。データを書き込むためのクエリエンジン、メタデータを管理するためのカタログ(Nessie や JDBC サービスなど)、そしてテーブルファイルを保存するオブジェクトストアが必要になります。これらを個別に管理するには、膨大なセットアップとメンテナンス作業が発生します。
RisingWave はこの一連のプロセスを大幅に簡素化します。RisingWave にはホスト型カタログ機能が組み込まれており、外部のカタログサービスを使わずに、オープンかつ高性能なストリーミングレイクハウスを簡単に構築できます。
このガイドでは、RisingWave を使って JDBC ベースの Iceberg カタログをたった1つのコマンドで作成する方法を紹介します。ネイティブ Iceberg テーブルを作成し、そこにデータをストリームし、RisingWave と Apache Spark の両方からクエリを実行して、相互運用性とオープン性を実証します。
概要・前提条件・クイックスタート
このデモでは、RisingWave の Awesome Stream Processing リポジトリにある Iceberg セットアップを利用します。
アーキテクチャ
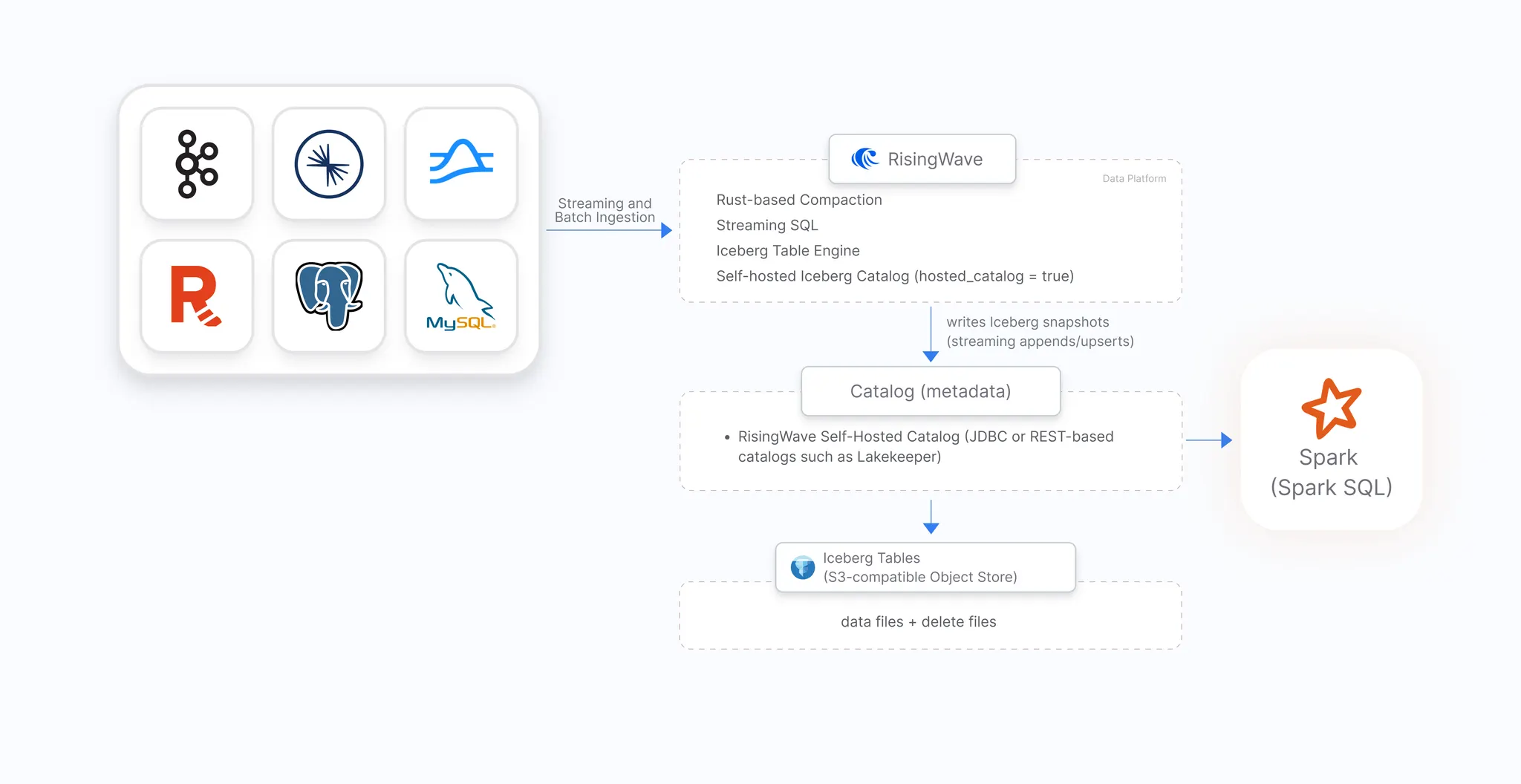
前提条件
次のツールをあらかじめインストールしておきましょう:
クイックスタート
まず、リポジトリをクローンし、デモスタックを起動します。
# リポジトリをクローン
git clone <https://github.com/risingwavelabs/awesome-stream-processing.git>
# Iceberg クイックスタートデモのディレクトリに移動
cd awesome-stream-processing/07-iceberg-demos/streaming_iceberg_quickstart
# デモスタックを起動
docker compose up -d
このコマンドで以下のコンポーネントが起動します:
- スタンドアロン RisingWave インスタンス(localhost:4566)
- PostgreSQL(localhost:5432)
- MinIO オブジェクトストア(localhost:9000)
Step 1: ホスト型カタログ接続を作成する
まず、psql を使用して RisingWave インスタンスに接続します。
psql -h localhost -p 4566 -d dev -U root
次に接続を作成します。
ここで hosted_catalog = 'true' を指定することで、RisingWave が Iceberg のメタデータを内部的に管理し、完全準拠の Iceberg カタログとして動作します。Glue や Nessie、外部 PostgreSQL は不要です。
CREATE CONNECTION my_iceberg_connection
WITH (
type = 'iceberg',
warehouse.path = 's3://icebergdata/demo',
s3.access.key = 'hummockadmin',
s3.secret.key = 'hummockadmin',
s3.region = 'us-east-1',
s3.endpoint = '<http://minio-0:9301>',
s3.path.style.access = 'true',
hosted_catalog = 'true' -- 👈 たった1つのフラグで外部サービス不要!
);
了解しました。では後半(Step 2 ~ 結論まで)を翻訳します。
引き続きフォーマット・コードブロック・語彙の自然さを完全に維持した日本語訳です。
Step 2: ネイティブ Iceberg テーブルを作成する
現在のセッションでこの接続を有効化します。これ以降の Iceberg 関連操作は、すべてこの設定を使用します。
SET iceberg_engine_connection = 'public.my_iceberg_connection';
次に、ENGINE = iceberg を指定してネイティブ Iceberg テーブルを作成します。
RisingWave はテーブルの構造とデータを管理し、接続設定で指定した MinIO のパスにファイルを保存します。
CREATE TABLE crypto_trades (
trade_id BIGINT PRIMARY KEY,
symbol VARCHAR,
price DOUBLE,
quantity DOUBLE,
side VARCHAR, -- 例: 'BUY' または 'SELL'
exchange VARCHAR, -- 例: 'binance', 'coinbase'
trade_ts TIMESTAMP
)
WITH (commit_checkpoint_interval = 1) -- 低レイテンシーなコミット設定
ENGINE = iceberg;
これでテーブルが作成され、ストリーミング挿入を受け付ける準備が整いました。
Step 3: データをストリームし RisingWave でクエリを実行する
いくつかのレコードをテーブルに挿入してみましょう。
INSERT INTO crypto_trades
VALUES
(1000001, 'BTCUSDT', 57321.25, 0.005, 'BUY', 'binance', NOW()),
(1000002, 'ETHUSDT', 2578.10, 0.250, 'SELL', 'coinbase', NOW());
次に、コミットを確認するためにテーブルをクエリします。
SELECT * FROM crypto_trades;
出力例は以下のようになります:
trade_id | symbol | price | quantity | side | exchange | trade_ts
----------+---------+----------+----------+------+----------+----------------------------
1000001 | BTCUSDT | 57321.25 | 0.005 | BUY | binance | 2025-07-17 15:04:56.123
1000002 | ETHUSDT | 2578.10 | 0.250 | SELL | coinbase | 2025-07-17 15:04:56.456
このテーブルは オープンな Iceberg 形式 で保存されているため、外部エンジンからもすぐにクエリできます。
Step 4: Apache Spark からテーブルをクエリする
相互運用性を確認するため、外部エンジンである Apache Spark から同じテーブルをクエリしてみましょう。
まず、Apache Spark がインストールされていることを確認してください。
まだの場合は、公式 Spark サイト からダウンロードし、インストールガイドに従ってセットアップします。
Spark が環境で利用可能になったら、RisingWave のホスト型カタログに接続するための設定とパッケージを指定して Spark SQL シェルを起動します。
spark-sql \\
--packages "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.2,org.apache.iceberg:iceberg-aws-bundle:1.9.2,org.postgresql:postgresql:42.7.4" \\
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \\
--conf spark.sql.defaultCatalog=dev \\
--conf spark.sql.catalog.dev=org.apache.iceberg.spark.SparkCatalog \\
--conf spark.sql.catalog.dev.catalog-impl=org.apache.iceberg.jdbc.JdbcCatalog \\
--conf spark.sql.catalog.dev.uri=jdbc:postgresql://127.0.0.1:4566/dev \\
--conf spark.sql.catalog.dev.jdbc.user=postgres \\
--conf spark.sql.catalog.dev.jdbc.password=123 \\
--conf spark.sql.catalog.dev.warehouse=s3://hummock001/my_iceberg_connection \\
--conf spark.sql.catalog.dev.io-impl=org.apache.iceberg.aws.s3.S3FileIO \\
--conf spark.sql.catalog.dev.s3.endpoint=http://127.0.0.1:9301 \\
--conf spark.sql.catalog.dev.s3.region=us-east-1 \\
--conf spark.sql.catalog.dev.s3.path-style-access=true \\
--conf spark.sql.catalog.dev.s3.access-key-id=hummockadmin \\
--conf spark.sql.catalog.dev.s3.secret-access-key=hummockadmin
続いて、RisingWave 上の Iceberg テーブルに挿入したデータを Spark 側からクエリします。
select * from dev.public.crypto_trades;
これで RisingWave によって管理されている Iceberg テーブルを、Spark からシームレスに読み取ることができます。
まとめ
このガイドでは、RisingWave がどのようにしてストリーミングレイクハウスの構築を簡略化するかを紹介しました。
hosted_catalog = true を設定するだけで、外部サービスをデプロイ・管理することなく、完全な Iceberg カタログを利用できます。
ネイティブ Iceberg テーブルを作成し、データをストリーム挿入し、RisingWave と Spark の両方からクエリを実行しました。
これにより、RisingWave がテーブル作成、データ取り込み、メタデータ管理を一貫して担いながら、データをオープンフォーマットのまま保持し、どのエンジンからでもアクセス可能であることが示されました。
RisingWave をはじめよう
-
今すぐ RisingWave を試す:
- RisingWave のオープンソース版をダウンロード して、自分のインフラ上でデプロイ。
- 完全マネージド体験を求めるなら RisingWave Cloud で簡単に始められます。