ChatGPTの「記憶喪失」にサヨナラ。Django×Railwayで実装する「超・長期記憶」(Memory as a Service) API
はじめに:AIに「愛着」がわかない最大の理由
「昨日の晩ごはん、何食べたか覚えてる?」
友人にこう聞かれて「すみません、私は大規模言語モデルなので以前の会話内容は保持していません」と返されたら、その友人との仲はそこまでです。
現在のAIチャットボットの最大の課題、それは**「記憶喪失」**です。
どんなに賢いモデルでも、ブラウザをリロードすれば全てを忘れます。これでは、真のパートナー(AI Agent)は作れません。
「でも、Gemini 1.5 ProとかGPT-4oなら、100万トークン入るから全部プロンプトに入れればよくない?」
そう思ったあなた。半分正解で、半分間違いです。
この記事では、DjangoとRailwayという最強にコスパの良いスタックを使って、**「半年前に話したこと」でも一瞬で思い出す「超・長期記憶(Memory as a Service)」**の実装方法を解説します。
Pineconeなどの高価なVector DBは不要です。PostgreSQL一つあれば、AIに「魂」を実装できます。
1. なぜ今、あえて「RAG」なのか?(2025-2026年視点)
実装に入る前に、多くのエンジニアが抱く**「全部コンテキストに入れればいいじゃん問題」**を論破しておきます。これが、今回RAG(検索拡張生成)を採用する技術的根拠です。
理由①:お財布が死ぬ(コスト1250倍の差)
会話履歴が積み重なって「10万トークン」になったとします。
毎回これをAPIに投げると、1往復のコストはどうなるでしょうか?
| 手法 | 処理内容 | 推定コスト(1回あたり) |
|---|---|---|
| Full Context | 全過去ログを毎回送信 | 約 $0.10 (約15円) |
| RAG | 必要なログのみ検索して送信 | 約 $0.00008 (約0.01円) |
その差、実に1250倍。
ユーザーが100人、1日10回会話したら、Full Contextでは破産します。RAGは経済的合理性の塊です。
理由②:"Lost in the Middle" 現象
最新の研究(Liu et al., 2024)によると、LLMは**「文章の最初と最後は覚えているが、真ん中に埋もれた情報は忘れやすい」という特性があります。
長大なログを全部読ませるより、「検索(Retrieval)によって、必要な情報だけをピンポイントで抽出」**して渡した方が、AIの回答精度は高くなるのです。
2. アーキテクチャ構成
「お財布に優しく、かつ最強の構成」を目指します。
- Backend: Python (Django)
- Infrastructure: Railway
-
Database: PostgreSQL (with
pgvector) - AI: OpenAI API (Embedding & Chat)
なぜ Railway × pgvector なのか?
ここが本記事のキモです。
通常、ベクトル検索には Pinecone や Weaviate などの専用DBを使うことが多いですが、これらは月額数千円〜と高価になりがちです。
RailwayのPostgreSQLプラグインは、追加料金なしで pgvector(ベクトル演算拡張機能)が使えます。
つまり、普段のDjango用DBの中に「記憶」も一緒に保存できるため、管理コストも金銭的コストも最小限で済みます。
3. 実装:Djangoで「脳」を作る
では、手を動かしていきましょう。
今回は langchain-postgres などのラッパーは使いません。DjangoのORMとガッツリ統合して細かく制御するため、django-pgvector を採用します。
Step 1: 準備
Railway上でPostgreSQLを立ち上げたら、以下のライブラリをインストールします。
pip install django-pgvector openai
Step 2: Models.py (記憶の保管庫)
ここが重要です。単に embedding を保存するだけでなく、HNSWインデックスを定義して検索速度を爆速にします。
from django.db import models
from django.contrib.auth.models import User
from pgvector.django import VectorField, HnswIndex
class Memory(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE, related_name='memories')
# 記憶の内容(例:「ユーザーは親子丼が好き」)
content = models.TextField()
# メタデータ(いつ、どんな文脈で、重要度は?)
# 例: {"type": "conversation", "importance": 5}
metadata = models.JSONField(default=dict, blank=True)
# ベクトルデータ (OpenAI text-embedding-3-small なら 1536次元)
embedding = VectorField(dimensions=1536)
created_at = models.DateTimeField(auto_now_add=True)
class Meta:
# HNSWインデックスを作成(これがないとデータ量が増えた時に死にます)
indexes = [
HnswIndex(
name='memory_embedding_idx',
fields=['embedding'],
m=16,
ef_construction=64,
opclasses=['vector_cosine_ops']
)
]
def __str__(self):
return f"{self.user.username}: {self.content[:20]}..."
Step 3: マイグレーションの注意点(Railway特有)
RailwayのPostgresで pgvector を有効化するには、マイグレーションファイルで明示的にExtensionを作成する必要があります。
python manage.py makemigrations した後、生成されたファイルを開いて以下のように編集してください。
from django.db import migrations
from pgvector.django import VectorExtension # これをインポート
class Migration(migrations.Migration):
dependencies = [
# ...
]
operations = [
VectorExtension(), # 最初にこれを実行して拡張機能を有効化!
migrations.CreateModel(
# ... Memoryモデルの作成 ...
),
]
4. アルゴリズム:ただの検索じゃ「人間」になれない
ここからが**「QiitaでLGTMをもらうための差別化ポイント」**です。
単純に Cosine Similarity で検索するだけでは、「半年前の『おはよう』」と「今の『おはよう』」が競合してしまいます。
人間のような「自然な想起」を実現するために、以下の2つのアルゴリズムを組み合わせます。
- 時間減衰 (Time Decay): 昔のことは少しずつ忘れる(直近の文脈重視)
- ハイブリッド検索 (RRF): 「意味」と「単語」の両方で探す(専門用語対応)
① 時間減衰(Time Decay)の実装
人間のように**「最近のことはよく覚えていて、昔のことは重要なことだけ覚えている」**仕組みを作るために、以下の数式を導入します。
$$Score = Similarity \times e^{-\lambda \times Time}$$
これをDjango ORMで書くとこうなります。データベース側で計算させるため、Pythonの処理速度を落としません。
from django.db.models import F, ExpressionWrapper, FloatField
from django.db.models.functions import Now, Exp
from pgvector.django import CosineDistance
def search_memories(user_id, query_vector, limit=5):
"""
時間減衰を考慮した「人間らしい」記憶検索
"""
# 1. 時間経過(時間単位)を計算
age_in_hours = ExpressionWrapper(
(Now() - F('created_at')),
output_field=FloatField()
) / 3600000000.0
# 2. 減衰係数(値が大きいほど、昔のことはすぐ忘れる)
decay_rate = 0.005
decay_factor = Exp(-decay_rate * age_in_hours)
# 3. 検索実行
# 類似度(1 - 距離) に 時間減衰(decay_factor) を掛ける
memories = Memory.objects.filter(user_id=user_id)\
.annotate(
distance=CosineDistance('embedding', query_vector),
similarity=1 - F('distance'),
final_score=F('similarity') * decay_factor
)\
.order_by('-final_score')[:limit]
return memories
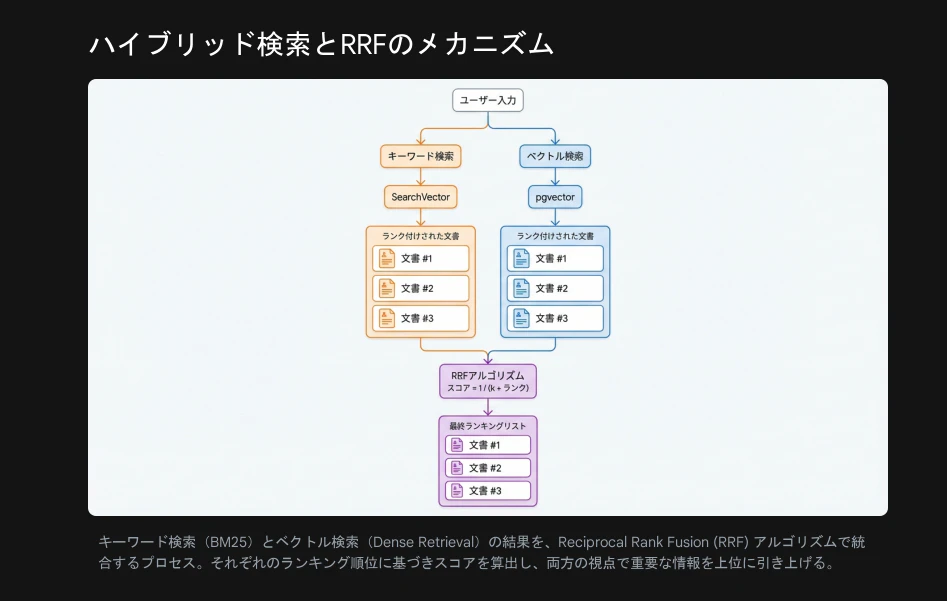
② ハイブリッド検索とRRF(精度向上の鍵)
ベクトル検索(意味の検索)は優秀ですが、「固有名詞」や「完全一致させたい専門用語」には弱い弱点があります。
そこで、Django標準の全文検索(SearchVector)を組み合わせ、RRF (Reciprocal Rank Fusion) というアルゴリズムで結果を統合します。
これにより、「文脈は合っているが単語が違う」検索漏れを防ぎ、最強の検索精度を実現します。全体のメカニズムは以下の通りです。
5. いざ、API化(Views.py)
最後に、これをAPIとして叩けるようにします。
from rest_framework.views import APIView
from rest_framework.response import Response
from django.conf import settings
import openai
class ChatAPI(APIView):
def post(self, request):
user_input = request.data.get('message')
user = request.user # 認証済みユーザー
# 1. ユーザーの入力をベクトル化
client = openai.OpenAI(api_key=settings.OPENAI_API_KEY)
resp = client.embeddings.create(
input=user_input,
model="text-embedding-3-small"
)
query_vec = resp.data[0].embedding
# 2. 過去の記憶を検索 (Time Decayあり)
past_memories = search_memories(user.id, query_vec)
# 3. コンテキストを構築
context_text = "\n".join([f"- {m.content}" for m in past_memories])
# 4. LLMにプロンプトとして渡す
system_prompt = f"""
あなたはユーザーの親しい友人です。以下の「過去の記憶」を参考に会話してください。
【ユーザーに関する記憶】
{context_text}
"""
# ... ここで chat.completions.create を呼ぶ ...
# 5. 会話が終わったら、今回の会話も Memory に保存する (非同期推奨)
# Memory.objects.create(...)
return Response({"reply": "AIからの返信..."})
6. ハマりどころとPro Tips
実運用で泣かないための、現場の知見を共有します。
① インデックス作成時のメモリ不足
RailwayのHobbyプラン(512MB RAM)などで、数十万件のデータに対して HnswIndex を作ろうとすると、OOM(メモリ不足)で落ちることがあります。
- 対策: データを入れる前にインデックスを作るのではなく、ある程度データが溜まってからバッチ処理でインデックスを作るか、一時的にプランを上げてインデックス作成時のみメモリを確保しましょう。
② 次元数の変更は「死」を意味する
text-embedding-3-small (1536次元) から large (3072次元) に変えたくなった時、pgvector のカラムは型定義で次元数が固定されているため、単純な ALTER TABLE ができません。
-
対策: 新しいカラム
embedding_v2を作ってデータを移行し、コードを切り替えてから古いカラムを消す「ダブルライト戦略」が必要です。
おわりに:記憶は「機能」ではなく「体験」だ
今回実装したAPIを使えば、あなたのアプリのAIはこう変わります。
- Before: 「はじめまして(5回目)」
- After: 「あ、Koさん!先週言ってたPythonのバグ、直りました?」
「自分のことを覚えていてくれる」。
たったこれだけで、ユーザーはAIに対して「ツール」以上の感情、すなわち愛着を抱くようになります。
DjangoとRailwayなら、この「Memory as a Service」を今すぐ、低コストでデプロイできます。
ぜひ、あなたのプロダクトに「魂」を吹き込んでみてください。
参考リンク