はじめに
LLMにドキュメントを解析させるには、ドキュメントをテキストに変換する必要があります。
(最近では、APIに直接画像を設定して解析させる、VLMなどの手法が使えることもありますが、RAGなどでベクトル検索やキーワード検索を実装する際には依然としてドキュメントをテキストに変換する必要があります。)
本記事では、PDFを操作するライブラリであるPyMuPDFとVLMによる画像読み取りのマークダウン化を試した結果を記載します。
PyMuPDFとは
ドキュメントのデータ抽出、分析、変換、操作のための高性能な Python ライブラリです。
Artifex Softwareという企業により開発されている様です。
VLMとは
VLM(Vision-Language Model、視覚言語モデル)とは、画像や動画といった視覚情報とテキスト(言語情報)を同時に理解・処理できるAIモデルのことで、「画像の内容を説明する文章を生成する(画像キャプション生成)」、「画像について質問に答える(視覚質問応答)」、「テキストで指示して画像を生成する」など、視覚とテキストをまたいだ複雑なタスクが可能になっています。
本記事の検証ではGemini 1.5 Flashを利用しています。
検証内容
マークダウンファイル作成手順
- PyMuPDFによる文字起こし・表抽出結果の取得
- VLMによるPDFの画像抽出とマークダウン化の取得
※ PyMuPDFによる画像認識は別途Tesseract-OCRの有効化が必要であった為、今回PyMuPDFからはテキストと表の抽出のみ実施した。
検証環境
- 検証対象のPDF:環境省が公開している、「令和7年版 環境・循環型社会・生物多様性白書」および「こども環境白書(2019年版)」を利用しました。(参考資料ご参照ください)
- 利用API:Gemini 1.5 Flash
検証結果
もとのPDF


| もとのPDF | PyMuPDF | VLM |
|---|---|---|
 |
```
テキスト内容: 6 7 今、日本で何が起こっている のか 世界では、環 かん 境 (以下略) ``` |
```
# 今、日本で何が起こっているのか 世界では、環境・経済・社会のからみ合った問題の解決に向けて様々な動きが始まりました。日本も世界の一員として取組を進めていますが、その前に、日本ではどのような問題が起こっているか考えてみましょう。 ``` |
 |
```
日本では、経 けい 験 けん したことのない「人口減 (以下略) ``` |
```
## 人口減少・少子高齢化 日本では、経験したことのない「人口減少」、子どもに比べて高齢者の割合が増えていく「少子高齢化」が進んでいます。2060年には人口は約9,000万人に、また約5人に2人が65歳以上になると推計されています。人口減少と少子高齢化がともに進むと、働き盛りの人の数が少なくなり、経済へ影響が生じると考えられています。 ``` |
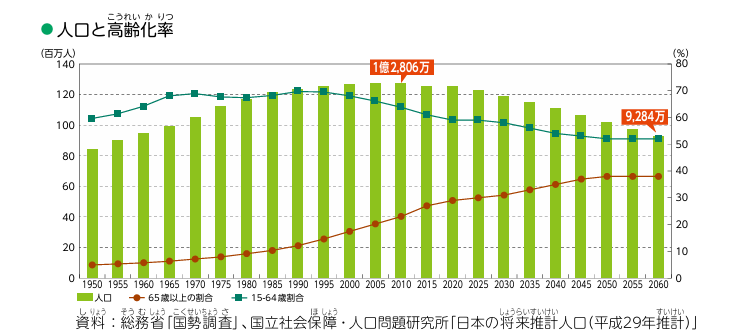 |
(なし) |
```
* 人口と高齢化率 *  資料:総務省「国勢調査」、国立社会保障・人口問題研究所「日本の将来推計人口(平成29年推計)」 ``` |

|
(なし) |
```
**図2-2-1 地域連携保全活動支援センターの役割** 土地所有者、地域連携保全活動支援センター、NPO等、企業等の連携図。 - 土地所有者等は、情報提供や相談を通じて支援センターと連携。 - 企業等は、情報提供や相談を通じて支援センターと連携。 - NPO等は、相談や連携を通じて支援センターと土地所有者や企業等と連携。 資料: 環境省 ``` |

|
```
|地方公共団体名|地域連携保全活動支援センターの名称|
|---|---| |北海道|北海道生物多様性保全活動連携支援センター(HoBiCC) |青森県|青森県 環境エネルギー部 自然保護課| |茨城県|茨城県生物多様性センター ※| |栃木県|栃木県 環境森林部 自然環境課 ※| (以下略) ``` |
```
### 表2-2-1 地域連携保全活動支援センター設置状況【2025年3月時点】 | 地方公共団体名 | 地域連携保全活動支援センターの名称 | |:---|:---| | 北海道 | 北海道生物多様性保全活動連携支援センター (HoBiCC) * | | 青森県 | 青森県 環境エネルギー部 自然保護課 | | 茨城県 | 茨城県生物多様性センター※ | | 栃木県 | 栃木県 環境森林部 自然環境課※ | (以下略) ``` |
結果まとめ
記載されている文字やを抜き出すだけであれば、PyMuPDFだけでも十分に出せて居ました。
しかし、マークダウン化して構造情報も保持したり、画像の内容を解説するとなると不十分で、VLMなどを活用した方が良い結果が見込めます。
参考資料
付録
- VLMによるマークダウン化のプロンプト
details
このPDFページの画像を見て、内容を適切なマークダウン形式に変換してください。
## 指示
- 画像に表示されているすべてのテキストを読み取ってください
- 視覚的なレイアウト(フォントサイズ、太字、配置など)から文書構造を判断してください
- 適切な見出し階層(#, ##, ###など)をつけてください
- 段落、リスト、引用などを適切にフォーマットしてください
- 表がある場合は、マークダウンの表形式で出力してください
- 図表や画像がある場合は、その内容を説明してください
- 数式や専門用語も正確に記述してください
## 出力形式
- マークダウン形式で出力してください
- コードブロック記号(```markdown など)は出力しないでください
- 余計な説明は不要です
上記の指示に従って、このページをマークダウン形式で出力してください。