目次
1. 導入
-
はじめに
Kenと申します。都内で勤務しておりますが、(エンジニアではないものの)仕事上Pythonで作成されたツールに触れる機会が多くなり、全く何も知らないのはまずいと思い、Aidemyの「データ分析講座」を受講しております。本ブログ記事は、その最終成果物としてのアウトプットとなります。 -
本記事の概要
本記事は、Python学習を始めたばかりの超初心者向けです。Aidemyの講座では、最終課題以外にも10数個の添削課題があったものの、純粋に一からコードを自力で書き上げていく機会はありませんでした。その為、今回の課題に対し、Python初心者の自分がどのように向き合ってきたのかを記述します。
2. 分析過程
最終課題の内容:
Aidemyでは、以下のように最終課題が設定されています。
”受講生のみなさまには、最後の締め括りとしてオリジナルテーマのブログを作成していただいています。ご自身でテーマを設定した後、
どんな成果物を作成し
どんな問題を解決したのか
どの程度問題を解決したのか
など作成したオリジナルな成果物についてまとめてください。”
問題の定義:
今回データ分析によって成し遂げたいことは、「ファストフードの画像情報から、それがどの食べ物であるかを当てる」です(10の食べ物は、Baked Potato、Burger、Crispy Chicken、Donut、Fries、Hot Dog、Pizza、Sandwitch、Taco、Taquito)。詳細はこちらをご参照ください。
実行環境・データの出典:
使用PCはmacで、kaggle notebookを使用しました。また、データは上記リンクのKaggleの「Fast Food Classification Dataset - V2 | 20k Images」というコンペのものを使用しております。
実際の写真:
今回の画像データは、例えば以下の様なものとなります。

訓練および検証データの取得:
まずはKaggleから、以下コードにてデータを取得しました。こちらは初期設定でKaggleのNotebookにデフォルトで入っているコードです。
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here is several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
次に、必要なライブラリを読み込みます。実際は、必要になる度に該当のライブラリを足していくという方法を取りました。
# 共通
import os
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
# データの読み込み
from keras.preprocessing.image import ImageDataGenerator as IDG
# モデル化
from keras import optimizers
from tensorflow.keras.models import Model, Sequential
from tensorflow_hub import KerasLayer as KL
from keras.layers import Dense, Input, InputLayer, Dropout, Flatten
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras import layers
from tensorflow.keras.applications.vgg16 import VGG16
# 視覚化
import matplotlib.pyplot as plt
import plotly.express as px
次に、検証データを取り込みます。
train_dir ="/kaggle/input/fast-food-classification-dataset/Fast Food Classification V2/Train"
valid_dir = "/kaggle/input/fast-food-classification-dataset/Fast Food Classification V2/Valid"
test_dir= "/kaggle/input/fast-food-classification-dataset/Fast Food Classification V2/Test"
データの整形、作成、クレンジング
今回使用するデータは、Kaggleで事前に準備されている画像データですが、特段のクレンジングや整形処理は取っておりません。ただ、どの様なデータを取り扱っているか把握するため、クラスの数や種類を以下コードにて確認します。
# クラスネームの収集
class_names = sorted(os.listdir(train_dir))
n_classes = len(class_names)
# 出力
print("No. Classes : {}".format(n_classes))
print("Classes : {}".format(class_names))
結果、以下の様なメッセージが出力されました。
No. Classes : 10
Classes : ['Baked Potato', 'Burger', 'Crispy Chicken', 'Donut', 'Fries', 'Hot Dog', 'Pizza', 'Sandwich', 'Taco', 'Taquito']
更に、各クラスのデータ数の割合を確認する為、情報を視覚化します。
# クラスの割合を表示
class_dis = [len(os.listdir(train_dir)) for name in class_names]
# 視覚化(Train)
fig = px.pie(names=class_names, values=class_dis)
fig.update_layout({"title":{'text':"Training Class Distribution"}})
fig.show()
fig = px.bar(x=class_names, y=class_dis, color=class_names)
fig.show()
出力結果は以下の通りです。
これにより、全てのクラスのデータが均等に存在することが確認できました。
また、データの読み込みの為、以下の通りイメージデータジェネレーターを使用しますが、その前段階でハイパーパラメーターを設定します(ハイパーパラメーターは、最初に仮の数字を置き、何度かモデルを回してみた上で結果が比較的によかった数字をおいています)。
# ハイパーパラメーター
image_resize = 256
num_classes = 10
batch_size = 32
epochs = 10
# イメージデータジェネレーターの初期化
train_gen = IDG(rescale=1./255, rotation_range=10, horizontal_flip=True, vertical_flip=False)
valid_gen = IDG(rescale=1./255)
test_gen = IDG(rescale=1./255)
# データの読み込み
train_ds = train_gen.flow_from_directory(train_dir, shuffle=True, batch_size=batch_size, target_size=(image_resize,image_resize), class_mode='categorical')
valid_ds = valid_gen.flow_from_directory(valid_dir, shuffle=True, batch_size=batch_size, target_size=(image_resize,image_resize), class_mode='categorical')
test_ds = test_gen.flow_from_directory(test_dir, shuffle=True, batch_size=batch_size, target_size=(image_resize,image_resize), class_mode='categorical')
上記の結果、train_dsには15,000、valid_dsには3,500、test_dsには1,500の画像データが格納されていることが確認できました。
問題のモデル化、予測、解決
これから、モデル化の作業を行います。今回は、Aidemyの「CNNを用いた画像認識」講座で使用されていた、学習済みモデルであるVGG16を使用してモデル化を行います。
# VGG16のモデルと重みをインポート
input_tensor = Input(shape=(image_resize, image_resize, 3))
vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=input_tensor)
# モデル化
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(1024, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(10, activation='softmax'))
# vgg16とtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
model.summary()
# 重みを固定
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
こちらのモデル化では、2行目のFlattenを含めていなかった為、エラーが出続けたという失敗談もありますが、他の方のコードも参照しながら、なんとか回せるモデルを作成することができました。SGDの数字等を変更することで、更にAccuracyを改善できる可能性もありましたが、先ずはモデルを作り切ることを優先しました。
最後に、モデルを利用してValidation dataでAccuracyを算出します。
fit_history = model.fit(
train_ds,
steps_per_epoch=len(train_ds)//batch_size,
validation_steps=len(valid_ds)//batch_size,
epochs=epochs,
validation_data=valid_ds,
verbose=1,
)
試行結果は以下の通りとなります。最終的なVal_Accuracyは0.3438と大いに改善の余地がある結果となりました。
Epoch 1/10
14/14 [==============================] - 10s 645ms/step - loss: 2.6588 - accuracy: 0.1138 - val_loss: 2.3868 - val_accuracy: 0.0729
Epoch 2/10
14/14 [==============================] - 9s 670ms/step - loss: 2.5383 - accuracy: 0.0864 - val_loss: 2.2672 - val_accuracy: 0.1250
Epoch 3/10
14/14 [==============================] - 9s 649ms/step - loss: 2.4701 - accuracy: 0.1339 - val_loss: 2.2237 - val_accuracy: 0.2396
Epoch 4/10
14/14 [==============================] - 9s 652ms/step - loss: 2.3407 - accuracy: 0.1272 - val_loss: 2.1649 - val_accuracy: 0.2500
Epoch 5/10
14/14 [==============================] - 8s 592ms/step - loss: 2.2335 - accuracy: 0.2098 - val_loss: 2.0564 - val_accuracy: 0.3229
Epoch 6/10
14/14 [==============================] - 9s 648ms/step - loss: 2.1652 - accuracy: 0.1987 - val_loss: 2.0748 - val_accuracy: 0.3333
Epoch 7/10
14/14 [==============================] - 9s 650ms/step - loss: 2.1796 - accuracy: 0.2098 - val_loss: 2.0079 - val_accuracy: 0.3125
Epoch 8/10
14/14 [==============================] - 9s 641ms/step - loss: 2.1247 - accuracy: 0.2344 - val_loss: 2.0558 - val_accuracy: 0.3021
Epoch 9/10
14/14 [==============================] - 9s 649ms/step - loss: 2.1178 - accuracy: 0.2679 - val_loss: 2.0183 - val_accuracy: 0.3333
Epoch 10/10
14/14 [==============================] - 9s 635ms/step - loss: 2.1197 - accuracy: 0.2746 - val_loss: 2.0052 - val_accuracy: 0.3438
問題解決のステップと最終的な解決方法を視覚化、報告
上記結果を視覚化します。
# 評価
accuracy = fit_history.history['accuracy']
val_accuracy = fit_history.history['val_accuracy']
loss = fit_history.history['loss']
val_loss = fit_history.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'r', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'r', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
上記の出力結果は以下の通りとなります。
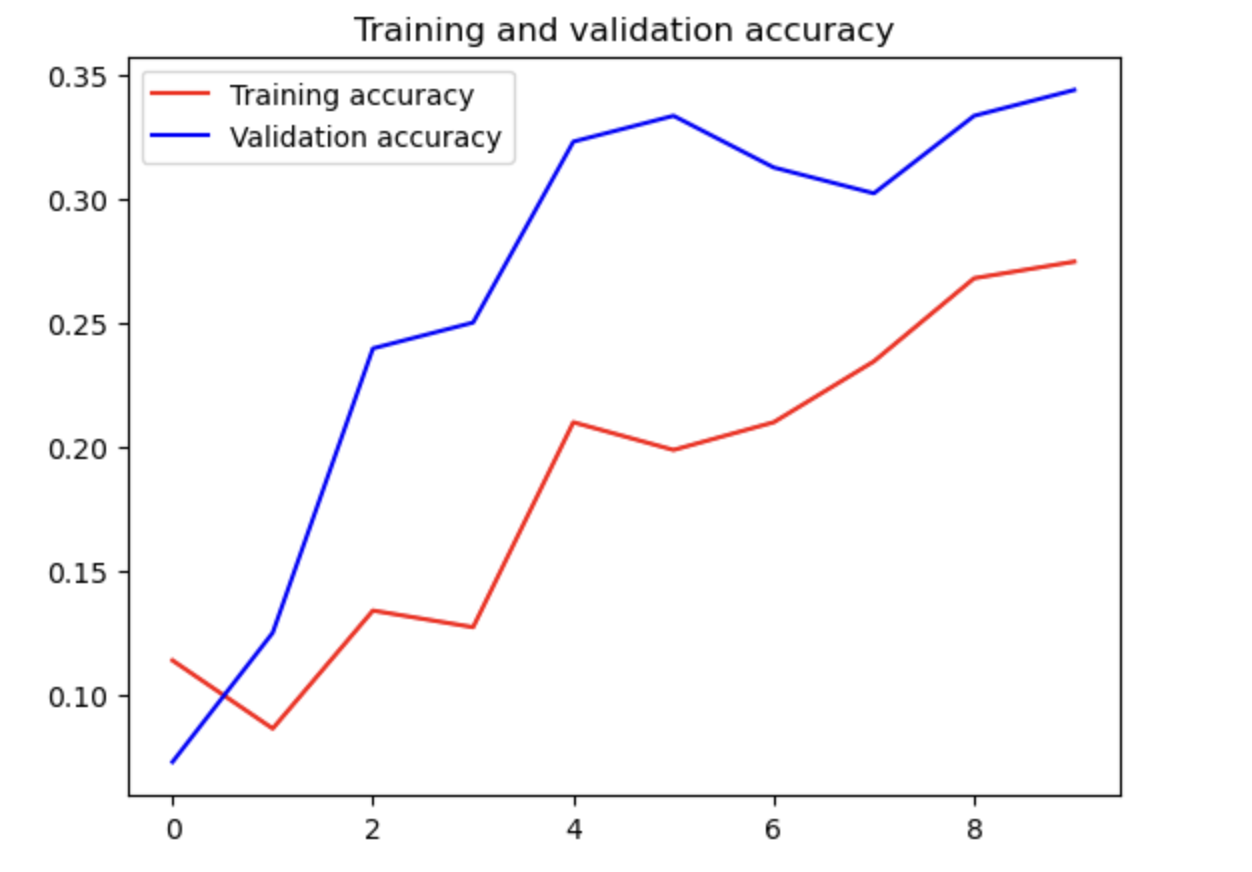
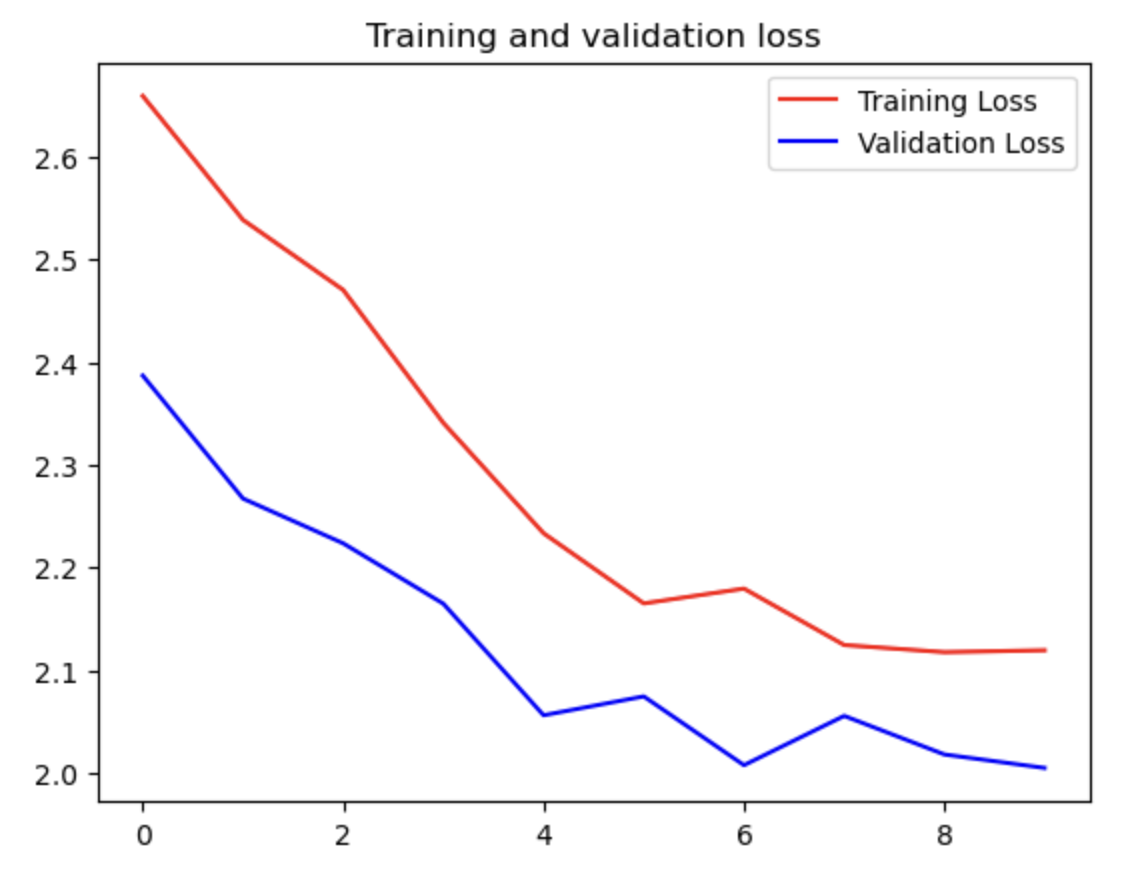
上記を踏まえた説明・考察です。
うまく行った点:まず何よりも、コードをオリジナルの構成で書き切れたことです。もちろん、他の方々のノートブックや、Aidemyのカウンセラーの方々のサポートなしには書き切れませんでした、それでも構成等を自ら主導して一つのモデルを組めたことは自信になりました。更に、ハイパーパラメーターを調整することで、改善の余地があることが自ら発見できたこともうまく行った点でした。同じモデルでも、例えばEpochを10から30に変更することで、Validation accuracyを50%近くまで改善することができましたが、それ以上はEpochを50にしてもなかなか改善が見られず、過学習の影響を肌で感じることができました。
改善点:もう少しVGG16以外の学習済みモデル以外の特徴を勉強すべきでした。今回は、Aidemyの教材で取り扱われていたのがVGG16であった為に、VGG16を使用しましたが、他の方々が使用していたResNet50等の特徴や、今回の題材におけるモデルの親和性等をもう少し学習することで、学習済みモデル選定をもう少し論理的に行うことができたかと思います。
3. 今後の活用・終わりに
本講座や最終成果物への取り組みを通じ、普段の実務で触れている機械学習においてPythonがどのように用いられていることが理解できました。それと同時に、Pythonの世界の奥深さの一端を垣間見ることができました。今後は、本課題に関しては、別のVGG16以外の事前学習モデルの使用も検討すると共に、実務では実際のコードをみながら、積極的に業務改善案を提案してゆきたいと考えております。