最近 Sakana AI が出した Sakana Fugu を調べていたんですが、これが発想として結構おもしろかったので共有します。
ひとことで言うと、「複数のLLMを裏で協調させる “マルチエージェント” を、たった1つのモデルAPIとして提供する」 サービスです。
使う側からは普通のモデルを1つ叩いているだけに見えるのに、その裏では複数のモデルがチームを組んでタスクを解いている――という代物です。
この記事でわかること
- Sakana Fugu が何で、なぜ新しいのか
- 仕組み(ICLR 2026 の論文2本:TRINITY と Conductor)のざっくり解説
- ベンチマークでの立ち位置(Opus 4.8 / Gemini 3.1 Pro と比較)
- 実際の使い方イメージ(OpenAI互換)
そもそも Sakana Fugu とは
Sakana AI("sakana" は魚、"fugu" はフグ。魚モチーフで統一されてます)が公開した、マルチエージェントを1つのモデルAPIとして提供するサービスです。
ざっくり言うと「いろんなLLMをタスクごとに動的に組み合わせ、チームとして協調させることで性能を底上げする」もの。キモは、その組み合わせ方や役割分担を人間が手で設計するのではなく、システム側が学習しているところです。
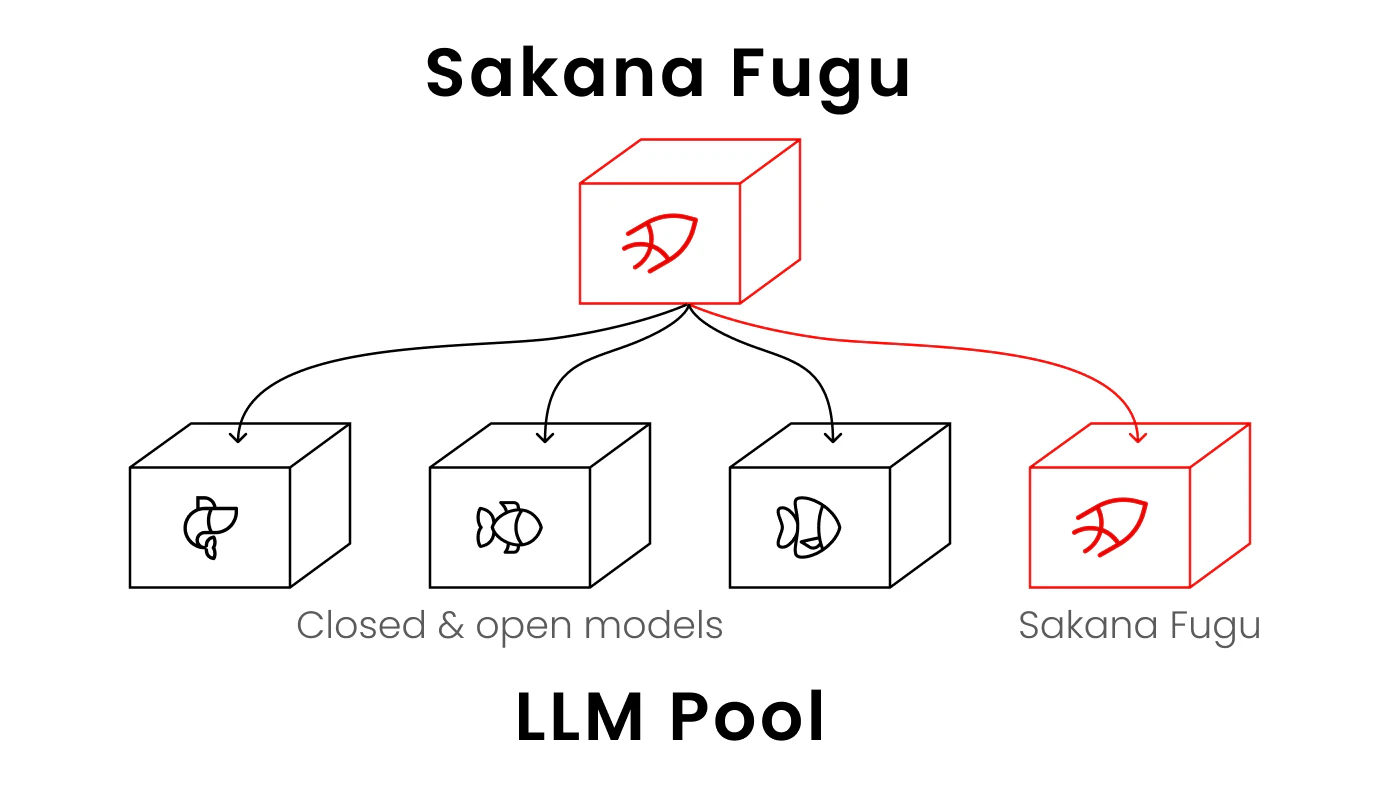
イメージはこんな感じ:
- 「LLM Pool」にクローズド/オープン問わず色々なモデルが入っている
- Fugu はタスクごとに最適なモデルを選び、役割を割り当てて連携させる
- 利用者は OpenAI互換のAPIを1本叩くだけ
何がそんなに新しいのか
「複数のモデルを使うサービス」と聞いて、どんなものを思い浮かべるでしょうか。
ここ数年、僕らがLLMにやってきたことは大きく2つでした。
- 1つの強いモデルにお願いする
- タスクに応じて「どのモデルを使うか」を選ぶ(=ルーティング)
Fugu がやっているのはそのどちらでもなく、1つのタスクに対して複数のモデルを同時に走らせ、役割分担して “合議” させる(=オーケストレーション)。しかもその段取りを学習で獲得している。ここが新しいポイントです。
仕組み:TRINITY と Conductor
Fugu は ICLR 2026 の論文2本がベースになっています。
- TRINITY:軽量な “コーディネーター” が複数のLLMをまとめ、それぞれに Thinker / Worker / Verifier(考える係 / 作る係 / 確認する係)のような役割を与えてタスクを振り分ける。
- Conductor:強化学習で、自然言語ベースの協調戦略そのものを学習させる。
要は、人間が書いた固定のワークフローに頼らず、「タスクごとに誰をどう動かすか」をシステム自身が決めている、というイメージです。
ベンチマーク:数字で殴ってくる
公開モデルとの比較(Sakana AI の発表より)。太字は、この4モデル中の最高スコアです。
| ベンチマーク | Fugu | Fugu Ultra | Opus 4.8 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE Bench Pro | 59.0 | 73.7 | 69.2 | 54.2 |
| TerminalBench 2.1 | 80.2 | 82.1 | 74.6 | 70.3 |
| LiveCodeBench | 92.9 | 93.2 | 87.8 | 88.5 |
| LiveCodeBench Pro | 87.8 | 90.8 | 84.8 | 82.9 |
| GPQA-D | 95.5 | 95.5 | 92.0 | 94.3 |
| MRCRv2 | 86.6 | 93.6 | 87.9 | 84.9 |
特にコード系(SWE Bench Pro / TerminalBench / LiveCodeBench)で Ultra が頭ひとつ抜けているのが印象的。公開されている frontier モデルを上回るスコアを、単一の巨大モデルではなく 複数モデルの協調 で出してきている、という主張です。
スコアはあくまで提供元(Sakana AI)公開の数値です。自分のユースケースで効くかどうかは別途検証推奨。
使い方のイメージ
「OpenAI互換だから移行が楽」が売りなので、コードはたぶんこんな雰囲気になります。
from openai import OpenAI
# OpenAI互換なので、base_url と model を差し替えるだけ
client = OpenAI(
base_url="<Fugu のエンドポイント>", # ※正式なURLは公式ドキュメント参照
api_key="<YOUR_API_KEY>",
)
resp = client.chat.completions.create(
model="fugu", # or "fugu-ultra"(※正式なモデル名は要確認)
messages=[{"role": "user", "content": "二分探索を書いて"}],
)
print(resp.choices[0].message.content)
既存の OpenAI クライアントのまま、base_url と model を差し替えるだけ――というのが狙いです。
エンジニア視点で何が嬉しいのか
- API は1本だけ:OpenAI互換なので、既存コードからの移行コストがほぼゼロ(SDK 入れ替え不要)。
- 料金が積み上がらない:裏で複数モデルが動いても、課金は “最上位モデル1つ分” のレートが基準。「マルチエージェント=高額」の常識を崩しにきている。
- モデルのオプトアウトができる:コンプラ/データ要件に合わせて、特定のプロバイダやモデルをプールから外せる。
- 輸出規制リスクなしで frontier 級:ここは国産ならではの売り文句。
ラインナップは2つ。
- Fugu:パフォーマンスとレイテンシのバランス型(日常使い)
- Fugu Ultra:難しいタスク向けに、より多くのモデルを束ねて品質最優先
まとめ
- Sakana Fugu = 世界中のトップモデルを裏でオーケストレーションして、1つのAPIで使えるようにした サービス
- 「モデルを選ぶ」から「モデルたちに分担させる」への発想転換がおもしろい
- コード系ベンチで公開モデルを上回るスコア、しかも料金は積み上がらない設計
- 単体のツールというより、既存の開発フローに “中身(モデル)” として挿し込めるタイプ
個人的に一番しびれたのは、「マルチエージェントを単一APIに抽象化した」うまさ です。エージェント開発の複雑さを、利用者からきれいに隠している。今後この「オーケストレーションそのものを売る」流れが増えるのか、要注目です。
参考
- Sakana Fugu 公式ページ(
https://sakana.ai/fugu/) - ICLR 2026:TRINITY / Conductor(公式の technical report 参照)