| シリーズトップページ |
|---|
| https://qiita.com/robozushi10/items/2c8b6951ee342b013974 |
概要
Ruby の Elasticsearch Client を使って Elasticsearch 7.14 で REST API の操作する.
また、比較のために、Kibana DevTool でのクエリも合せて記しておく.
今回はインデックス「shakespeare」から「全件(11万件超)」を取得する.
検証環境
下記の要領で検証用データ「Shakespeare」が登録された
・Elasticsearch + Kibana (7.14)
を使用した
[00] Ruby の elasticsearch client パッケージを使って Elasticsearch 7.14 を操作してみる ... 検証環境構築編
参考にした情報
実践
Kibana DevTool の場合
コード
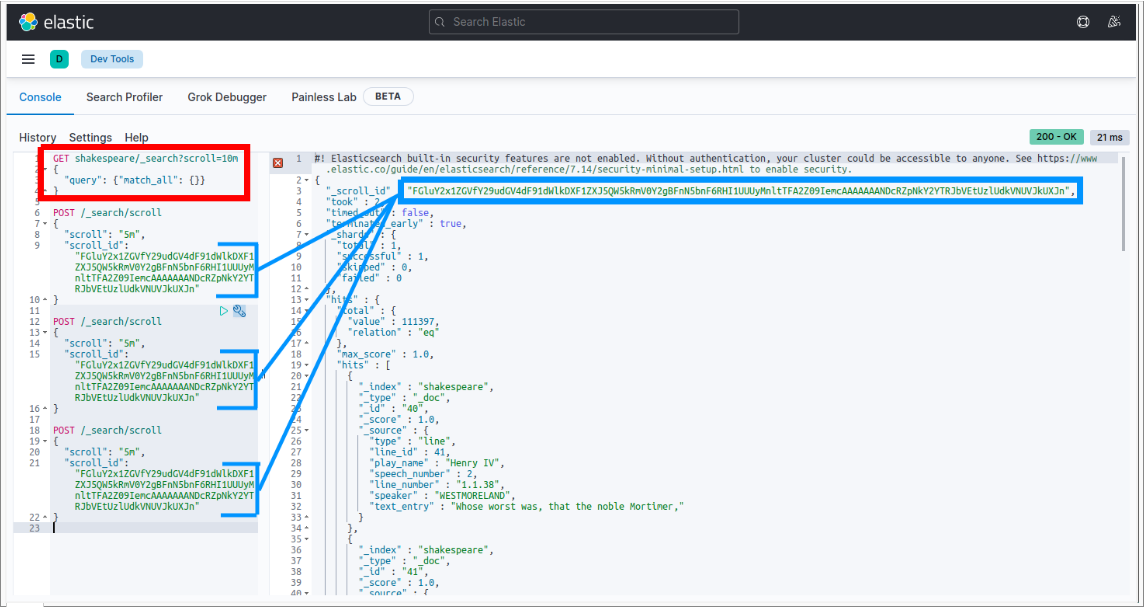
次の(1)〜(4)を実行すること.
(1) scroll_id を取得する.
GET shakespeare/_search?scroll=2m
{
"query": {"match_all": {}}
}
(2) 上記 (1) で得た scroll_id の値を使って /_search/scroll に対して ( GET では無くて) POST を実行する.
なおエンドポイントは「shakespeare」を含めずに、「/_search/scroll」とする こと.
POST /_search/scroll
{
"scroll": "5m",
"scroll_id": "上記(1) で得た scroll_id の値"
}
(3) 上記 (2)を 1回発行するごとに 10件ずつドキュメントを取り出せる
ただし、11万件超を取り出すには 10分以内に上記 (2) のコマンドを 1.1万回以上を実施しないといけない.
(4) スナップショットを消す
10分経過すると自動的に消えるが、明示的に消す場合は次のようにする.
なおエンドポイントは「shakespeare」を含めずに、「/_search/scroll」とする こと.
DELETE /_search/scroll
{
"scroll_id" : "上記(1) で得た scroll_id の値"
}
結果
Ruby の場合
コード
重要な部分は「if __FILE__ == $0 以降」である.
class MySimpleClient は丸々コピーで良い. (が、192.168.10.115 のみ、適宜読み替えること)
# !/usr/bin/env ruby
# -*- encoding: utf-8 -*-
require 'multi_json'
require 'faraday'
require 'elasticsearch/api'
require 'active_support/core_ext' #! note_0004
require 'active_support' #! note_0005
class MySimpleClient
# note_0001
include Elasticsearch::API
CONNECTION = ::Faraday::Connection.new url: 'http://192.168.10.115:29200'
def perform_request(method, path, params, body, headers = nil)
#! note_0003
CONNECTION.run_request \
method.downcase.to_sym,
path_with_params(path, params),
(body ? MultiJson.dump(body): nil),
{'Content-Type' => 'application/json'}
end
private
def path_with_params(path, params)
return path if params.blank?
case params
when String
"#{path}?#{params}"
when Hash
"#{path}?#{params.to_query}"
else
raise ArgumentError, "Cannot parse params: '#{params}'"
end
end
end
if __FILE__ == $0
client = MySimpleClient.new
q = {
"query": {
"match_all": {
}
}
}
res = client.search index: 'shakespeare', scroll: '10m', body: q
h = JSON.parse(res)
pp h
while h['hits']['hits'].size.positive?
q = {
"scroll_id": h['_scroll_id']
}
res = client.scroll scroll: '5m', body: q
h = JSON.parse(res)
pp h
end
# elasticsearch 上のスナップショットを消す
res = client.clear_scroll scroll: '5m', body: q
end
# note_0001: https://rubydoc.info/gems/elasticsearch-api
# note_0002: https://www.elastic.co/guide/en/elasticsearch/reference/7.14/scroll-api.html
# https://www.elastic.co/guide/en/elasticsearch/reference/7.14/clear-scroll-api.html#clear-scroll-api-scroll-id-param
# note_0003: MySimpleClient.new のインスタンスである client から呼び出されるので実装が必要である
# note_0004: 'active_support' を 'active_support/core_ext' に変更する.
# APIドキュメントにある 'active_support' 指定だと次のエラーが発生してしまうためである.
# tutorial.rb:26:in `path_with_params': undefined method `blank?' for {}:Hash (NoMethodError)
# note_0005: require 'active_support' が存在しないと次のエラーが発生してしまう.
# /usr/local/bundle/gems/activesupport-6.0.4/lib/active_support/core_ext/object/json.rb:42:
# in `to_json': uninitialized constant ActiveSupport::JSON (NameError)
結果
10件ずつのペースで合計 111397件 🛑 のドキュメントを GET できた.
なお、当方の環境では 111397件の取得に 1分42秒を費した.
{"_scroll_id"=>
"FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFnN5bnF6RHI1UUUyMnltTFA2Z09IemcAAAAAAAJEsBZpNkY2YTRJbVEtUzlUdkVNUVJkUXJn",
"took"=>0,
"timed_out"=>false,
"_shards"=>{"total"=>1, "successful"=>1, "skipped"=>0, "failed"=>0},
"hits"=>
{"total"=>{"value"=>111397, "relation"=>"eq"},
"max_score"=>1.0,
"hits"=>
[{"_index"=>"shakespeare",
"_type"=>"_doc",
"_id"=>"0",
略
{"_scroll_id"=>
"FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFnN5bnF6RHI1UUUyMnltTFA2Z09IemcAAAAAAAJEsBZpNkY2YTRJbVEtUzlUdkVNUVJkUXJn",
"took"=>1,
"timed_out"=>false,
"terminated_early"=>true,
"_shards"=>{"total"=>1, "successful"=>1, "skipped"=>0, "failed"=>0},
"hits"=>
{"total"=>{"value"=>111397 🛑} , "relation"=>"eq"},
"max_score"=>1.0,
略