埋め込み空間完全に理解した。

そうですよここですけども。
とはいえ今までよりは本当に理解した感触があるので、手元に転がっていた感情表現のデータセット使って単語と感情のベクトルデータベース(データ入り)作ってみましたよね。
ただデータ量が多いと学習の待ち時間が長くて記事を書く前に飽きてしまいますので、データ量少なめで済む仕様にしましたところ「この程度のデータを有名どころのベクトルデータベースに入れて使うというのは完全にオーバーキルなので…」と賢いAI氏にしつこく止められてしまいました。そのため「いわゆるベクトルデータベース」のプロダクトは使いませんでしたが、「いわゆるベクトルデータベースでベクトルデータの運用」をしたいならあとはいわゆるベクトルデータベースのサーバを立ててデータを入れるだけです実に簡単ですというところまではやりました。そう軽さはいつだって正義。まさよしじゃないよせいぎだよ。
使用したデータセットについて
年末にデータの整理をしていたら見つけました。
タイムスタンプなどを見る限り2020年の1月ごろに拾ったもののようで、出自を探した結果、おそらくこのページの SNOW D18 日本語感情表現辞書 のリンク先にあったものではないかと思うのですが、現在はページが開けなくなっています。
最低でも「商用でなければ使用フリー」のものしか手元には保存していなかったはずなのですが、ページがないので再配布規定等が確認不能な状態です。そのため今回は「こんな感じのフォーマットを使わせてもらいました」ということと動かしたソースコード、および結果がどうなったか、ということだけ公開させていただくことにしました。
こんなデータセットです
感情分類のフォーマット
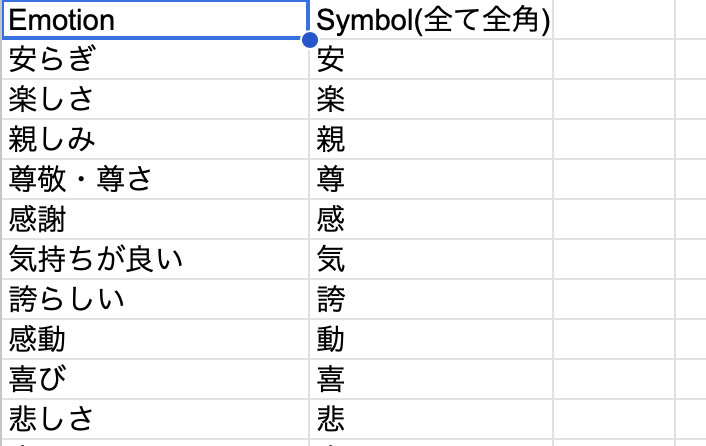
作業者ごとのラベリング結果のフォーマット

感情分類(ラベル)は全部で49あり、ラベリング対象の単語は1977。
Excel形式で、ラベル定義が1シート、さらに1977単語それぞれに対し3人の作業者が独自の印象でラベル付与した内容が作業者ごとに1シートでまとめられていて、全部で4シート、という構成です。
そもそも使い続けていいのかという問題もあるのですが、昔拾ったはいいけど持ち腐れていたデータの使い方をついに身につけたという自分の成長が嬉しかったのでどうしてもね……そこはね……。
なお現在は「感情分析」のデータセットとして wrime というものが有名なようですので、同じようなことをやってみたい場合はそちらを使用してみると良いかもしれません。
作ったもの
学習結果のデータはコミットしていません。
また作った結果のデータを分析するUIも一緒に用意してあります。Dockerで動かせます。こんな感じ。
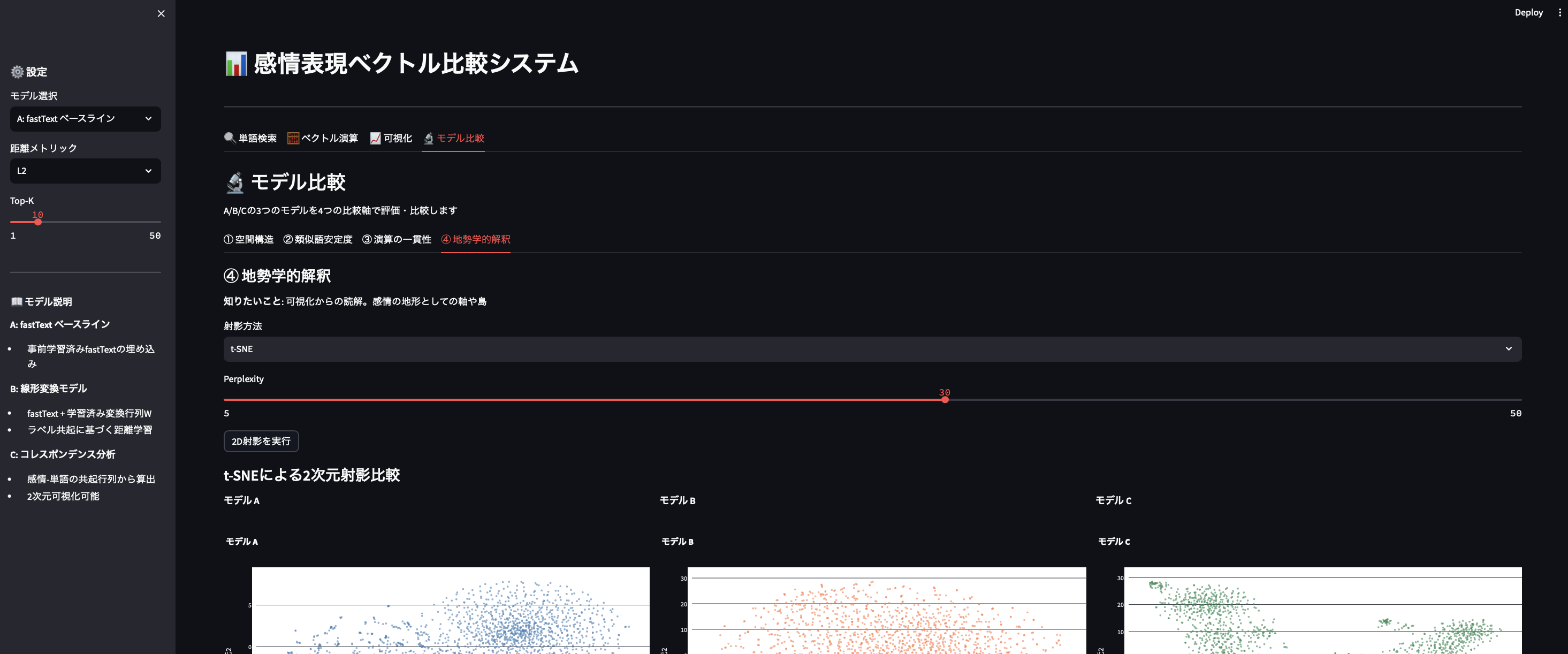
内容解説
以下のような3種のモデルを作成して、それぞれどれだけ有用か、というより、どういう違いが現れたか、というのを見て、また数値化して確認する、という感じの方針でやりました。
- モデルA: データセットに存在している単語のみをfastTextから持ってきて埋め込んだだけのモデル
- モデルB: モデルAに対し、データセットのラベリングによる「単語に含まれる感情」で再学習したモデル
- モデルC: モデルAともBとも関係なく、データセットをコレスポンデンス分析を用いて二次元座標に配置したモデル
実現コスト(実装の手間・モデルが完成するまでの計算コスト)としては、完全にモデルC > モデルA > モデルB です。今回は「感情分析」というのをフックにしていますが、内容は違えどデータ構成は似たようなデータセットがあったとして、そのデータセットをモデル化する際に、モデルの実現コストをかける意義が実際あるのかを体感したいなと考えたわけです。
なお単語が内包している感情なんて今どきデータベース化しなくてもChatGPTに聞けばいいじゃんと思われるとは思いますが、個人的には、手元で動かせるくらい小さな機械学習モデルのニーズってなんだかんだ今後も決してなくならない、むしろ「手軽に作りたい」ニーズは増すのではと考えております。
そんなわけでつまりは勉強目的でやりました。内容がゆるくても多めにみてください
結果について
自分の勉強用なので、第三者的な内容の良し悪しはコードの方を見ていただければと思いますが、個人的に結果の中で面白かった内容をいくつか
単語分布の違い
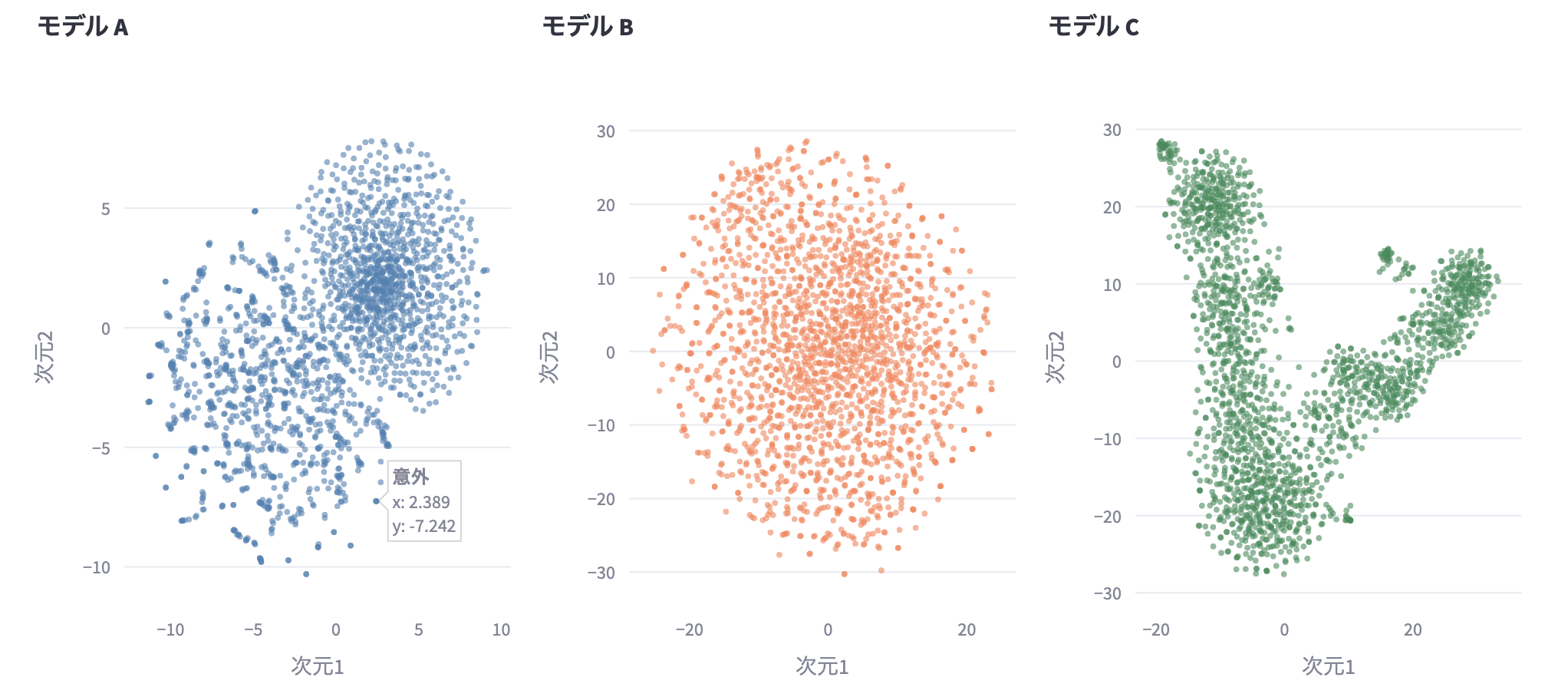
- fastTextの埋め込み状態モデルAに対し、学習済みのモデルBは分布が均等になっています
- 対象のデータセットに対する最適化だけに特化した分布に変化しているものと読み取れます
- 目視でアドホックにサンプリングした限りの印象では、モデルAよりもモデルBの方が、近接している単語に感情的な関連を感じるものが増えていました。この印象通りの結果が全体に及んでいるのであれば、求めた効果が得られていると言えます
- なおモデルAの単語分布の偏りは、感情の内容ではなく語彙としての使用頻度に依存している印象でした
- 右上の丸い塊には「よく使う」印象の単語が多買ったです
- 一方で左のばらつきのうち、特に外縁部については「普段聴いたことのない」単語が多かったです
- なおモデルAの単語分布の偏りは、感情の内容ではなく語彙としての使用頻度に依存している印象でした
- モデルA(ベースライン。文脈由来分布?)は「意外」「存外」「案外」がほぼ同じところに配置されていましたが、モデルB(感情重視分布)ではそうではなかったです。近接単語を検索して確認した結果、モデルAでは「存外」に近い単語はユークリッド距離基準・コサイン類似度基準で共に「意外」でしたが、モデルBではユークリッド距離基準で「ナンセンス」、またコサイン類似度基準では「慕情」でした
- モデルCで前項と同じく「存外」の近傍単語を検索すると「悚然(しょうぜん)」という単語が引っかかります。元データからするとラベルが違いすぎるのでバグである可能性もありますが、比較的納得がいく単語も多いので、とりあえずそのままにしました。モデルBとCを比較すると、モデルCは感情的には類似性を感じるものの文脈的には代替不能な単語が多くひっかかるなという印象でした
※モデルAとモデルBは表示の便宜上1024次元を2次元に射影しているため、図で目にみえる分布と実際の距離は多少異なります
類似単語の凝集度

凝集度から見るとモデルCが一番すごいように見えますが「凝集の基準」つまりは「単語の感情的類似の基準」を感情データセットのラベルで取っているので、データセットの情報を配置しただけのモデルCが最も優秀なのはただの当たり前です。騙されないようご注意ください。自分は騙されました
読み取る内容として正しいと言えるのは、モデルAが学習を経てモデルCの特性を獲得したことが数字でも読み取れる、というところかなと思います
感想
というわけで今回は「目的に即した小さいモデルの作成」の有用さ検討を目的としてこんなものを作ってみましたが、ベースモデルそのままを使用するよりも「目的に即した情報が得られる」期待の高いものができる、ということが体感できました
作り方としてモデルBはいわばモデルAとCの特徴の混合物な訳で、結果としてまさにその通りのものが出来上がりました
今年はこのあたりも駆使していろいろ遊んでいきたいです\(^o^)/
なおHTMLで動くUIも用意しました
上記のUIはdocker上のstreamlitで動かしていますが、類似(近傍)単語検索と単語のベクトル演算だけできる静的ページも用意してみました。

これの必要性を問われるとちょっと困るのですが、この程度のモデルサイズであればJavascriptでも動かせるんだなあと……面白かったので……前述の通りstreamlit用の学習結果モデルはコミットから除外しているのですが、こちらのHTML用のベクトルデータは公開するためにgithubリポジトリで一緒に公開していますので記事内容の信憑性が気になった方はそちらもぜひご参考までに。
ちなみにstreamlit用のベクトルデータ(Faiss向けフォーマット)は1モデルあたりせいぜい2MB強だったのですが、js用にテキスト化したものは1モデルあたり12MBほどあります。「静的ページでもできちゃった」という以上のメリットは特にないです。あるのはロマンだけ。
おまけ
学習を待っている間ヒマだったのでChatGPTに作ってもらっていたダニング・クルーガー曲線3兄弟

何も知らない人には一番左が一番頼りになる印象を与えてしまうという怖さ