import pandas as pd
import numpy as np
df = pd.DataFrame({
"category1" : ["A","A","A","B","B","B"],
"column1" : np.array([5,4,6,9,11,13])
})

統計量
df.describe()
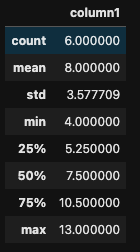
column1はcategoryでAとBに別れているが区別なく統計量が出るのは不便。
groupby関数
category A,B で区別して統計量を得る。
# category1でgroupを作る
group = df.groupby("category1")
# groupごとに関数処理する
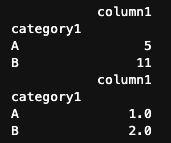
print(group.mean()) # 平均
print(group.std(ddof = 1)) # 標準偏差
group.describe() # groupごとに統計量の一括表示

地道に取り出す
# Aを取り出す
df_A = df[df["category1"] == "A"]
# mean関数に通す
df_A["column1"].mean()
groupby便利。