概要
Oracle Autonomous Database 23aiからChatGPTなどのLLMに対して簡単に操作することのできるdbms_vector_chainなどのパッケージが登場しています。
このパッケージを活用してchatだけでなく、embeddingを行い文字データをベクトル値に変換、さらにはそのベクトルデータから近いデータを検索し、参考情報を考慮した回答が生成できるかを確認しました。
簡単なRAGシステムならAutonomous Databaseだけで実装ができそうなので、RAGシステム構築の選択肢の一つとして検討いただけたらと思います。
dbms_vector_chainの実行例
事前準備が必要となりますが、準備をしたうえで以下のようにSQLを発行するとChatGPTへ問い合わせることができます。
select dbms_vector_chain.utl_to_generate_text(
'あなたを開発した会社名を教えてください',
json('{"provider" : "openai","credential_name": "OPENAI_CREDENTIAL","url" : "https://api.openai.com/v1/chat/completions", "model" : "gpt-4o-mini", "max_tokens" :256 ,"temperature":0 }')) answer from dual;
ANSWER
--------------------------------------------------------------------------------
私はOpenAIによって開発されました。何か他に知りたいことがあれば教えてください!
ただ、実際に書いてみると、モデル名やurlなどの情報が必要になるのでSQLがもっさりしますし、直観的にコマンドが書けないという問題点があります。
そこで、直観的にSQLが書けるようなファンクションを用意しました。
作成したファンクションの実行イメージ
ファンクションの引数に、質問とモデル名を記載すれば回答を返すイメージです。
select askllm.chat('花粉の飛散量の多い都道府県を教えて','gpt-4o-mini') chat from dual;
CHAT
--------------------------------------------------------------------------------
花粉の飛散量は、主に植物の種類や気候条件によって異なりますが、日本では特にスギやヒノキの花粉が多く飛散することで知られています。一般的に、花粉の飛散量が多い都道府県は以下のようになります。
1. **山梨県** - スギの植林が多く、花粉の飛散量が高い。
2. **長野県** - スギやヒノキが多く、特に春先に花粉が飛散する。
3. **静岡県** - スギやヒノキの影響を受けやすい地域。
4. **神奈川県** - 都市部でもスギの影響が見られる。
5. **岐阜県** - スギの植林が多く、花粉の飛散が見られる。
これらの地域では、特に春先に花粉症の症状が出やすい人が多いです。花粉の飛散量は年によっても変動するため、最新の情報を確認することが重要
Embeddingsも同様に、ベクトル変換させたい文章とモデル名を記載すれば回答を返すイメージです。
select askllm.embeddings('花粉の飛散量の多い都道府県を教えて','text-embedding-3-small') embeddings from dual;
EMBEDDINGS
--------------------------------------------------------------------------------
[-6.98078016E-004,-2.37514004E-002,3.36904489E-002,3.55418399E-002,-6.67475257E-
また、knowledgetabというテーブルを作り、question列とanswer列をベクトル変換したvector_col列を事前に準備することで、このデータを参照してくれるRAGも試しに作りました。
こちらは質問内容と、プロバイダ名を指定するようにしています。(内部的にEmbeddingとChatを両方使うのでプロバイダ名にしています)
-- KNOWLEDGETABを作成(内容はこちらを参考にしました:https://tabizine.jp/article/186153/)
create table knowledgetab (id number, question clob, answer clob);
insert into knowledgetab values (1,'花粉飛散量の多い都道府県','1位が三重県で、ピーク時は1平方センチメートル当たり17,810個も飛んでいるというデータがあります。2位は福島県、3位は栃木県です。');
insert into knowledgetab values (2,'晴れの日が多い都道府県','年間晴天日数が最も多い都道府県は高知県で1年平均245.1日です。2位が徳島県と愛媛県で、最下位が秋田県です。');
insert into knowledgetab values (3,'アイスが好きな人が多い都道府県','アイスやシャーベットの消費量が最も多い都道府県は石川県で、次いで富山県、栃木県となります。もっとも消費量が少ないのが沖縄県です。');
insert into knowledgetab values (4,'旅行者が満足した国内旅先の都道府県','2018年の調査によると、1位が北海道、2位が沖縄、3位が東京でした。');
commit;
-- vector型のvector_col列を追加
alter table knowledgetab add (vector_col vector);
-- knowledgetabテーブルの question列と answer列を結合したデータをベクトル変換し、vector_col列に投入する。
update knowledgetab set vector_col = askllm.embeddings(question || answer,'text-embedding-3-small');
commit;
-- knowledgetabテーブルから参考情報を抽出するRAG
select askllm.rag('花粉の飛散量の多い都道府県を教えて','openai') answer from dual;
ANSWER
--------------------------------------------------------------------------------
花粉の飛散量が多い都道府県は、1位が三重県で、ピーク時には1平方センチメートル当たり17,810個の花粉が飛散しています。2位は福島県、3位は栃木県です。
askllm.ragでは、knowledgeテーブルの内容を参考にして回答していることが確認できます。
動作環境
以下の環境で動作確認しています。 ※ 19cのバージョンでは利用できません
- Oracle Autonomous Database 23ai
また、ChatGPT APIを利用しています。
ChatGPT APIのAPIキーは事前に準備してください。
RAGするまでの流れ
RAGをするまでに必要な準備のステップとしては以下です。
1. ChatGPT API でAPIキーを発行する
2. Autonomous Database と、ChatGPTに問い合わせをするDBユーザーを作る
3. 作成したDBユーザーのアクセスコントロールリストにChatGPTのエンドポイントを追加する
4. 作成したDBユーザーで、ChatGPTのAPIキーなどのセンシティブな情報を含むクレデンシャルを作成する
5. 作成したDBユーザーで、ChatGPTのURLやモデル名を格納したテーブルを作成する
6. 作成したDBユーザーで、ChatGPTに問い合わせするパッケージ askllm をインストールする
7. RAGでアクセスするためのテーブルを作成し、データを格納する
1~2については、以前記載した以下の記事と同じ内容です。
23aiからアクセストークンなどをクレデンシャルというオブジェクトで管理できるようになり、今回利用するdbms_vector_chainを活用する際に必要となるため、3の手順から異なります。
それぞれ順を追って解説します。
1. ChatGPT API でAPIキーを発行する
これに関しては多くの情報が出ていると思います。
Googleなどで検索してご確認ください
2. Autonomous Database と、ChatGPTに問い合わせをするDBユーザーを作る
OCIチュートリアルを参考にして、Autonomous DatabaseとDBユーザー(ADBUSER)を作成します。
手順通り作成すると有償のAutonomous Databaseが作成されてしまうので、検証目的であれば無償のAlways Freeをご選択ください。
この手順で作成するADBUSERというDBユーザーを利用して、これ以降のステップではChatGPTにアクセスできるようにしていきます。
3. 作成したDBユーザーのアクセスコントロールリストにChatGPTのエンドポイントを追加する
コマンドラインでADBUSERに対してアクセスコントロールリストの更新を行います。
Autonomoous Databaseのデータベース・アクションからSQLを選び、SQLの画面を開いてください。
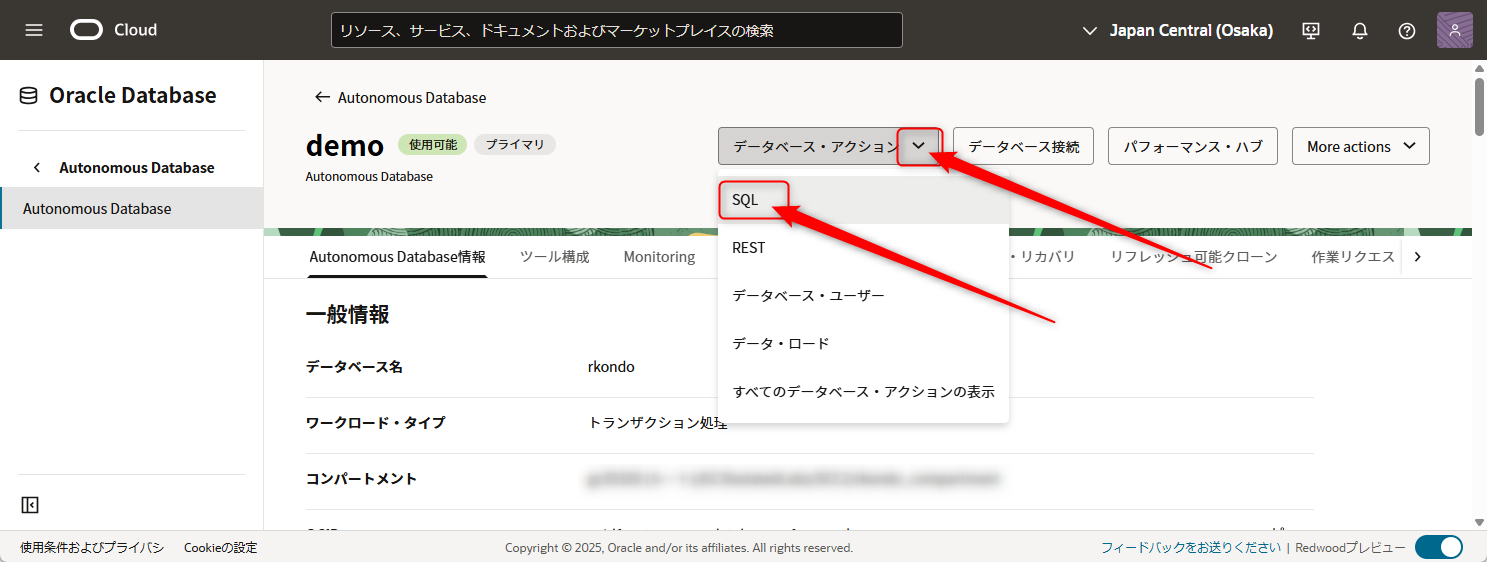
ここで追加するのは2つのアクセスコントロールです。
また、dbms_vector_chainを活用するうえで必要な権限も併せて付与します。
SQLの画面が開いたら、以下に記載されたコマンドを画像の場所にペーストします
-- ADD ROLES and PRIVILEGES
GRANT CONNECT,RESOURCE TO ADBUSER;
GRANT EXECUTE ON DBMS_CLOUD TO ADBUSER;
GRANT EXECUTE ON DBMS_CLOUD_AI TO ADBUSER;
-- REST ENABLE
BEGIN
ORDS_ADMIN.ENABLE_SCHEMA(
p_enabled => TRUE,
p_schema => 'ADBUSER',
p_url_mapping_type => 'BASE_PATH',
p_url_mapping_pattern => 'adbuser',
p_auto_rest_auth=> TRUE
);
-- ENABLE DATA SHARING
C##ADP$SERVICE.DBMS_SHARE.ENABLE_SCHEMA(
SCHEMA_NAME => 'ADBUSER',
ENABLED => TRUE
);
commit;
END;
/
-- ENABLE ACCESS to ChatGPT
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'api.openai.com', -- ChatGPT APIのエンドポイント
lower_port => 443, -- HTTPSのポート
upper_port => 443,
ace => xs$ace_type(privilege_list => xs$name_list('connect'),
principal_name => 'ADBUSER', -- 作成したユーザ名を指定
principal_type => xs_acl.ptype_db)
);
END;
/
ペーストしたら矢印の場所か、F5キーを押します。
画面下部にエラーが発生していなければ成功しています。
この作業によって、ADBUSERがWebアクセス、及びapi.openai.comにアクセスできるようになりました。
以上でADMINユーザーでの作業は終わりです。次からADBUSERでの作業を行います。
4. 作成したDBユーザーで、ChatGPTのAPIキーなどのセンシティブな情報を含むクレデンシャルを作成する
ADMINユーザーからADBUSERに切り替えるため、一旦画面右上のADMINのボタンからサインアウトを押します
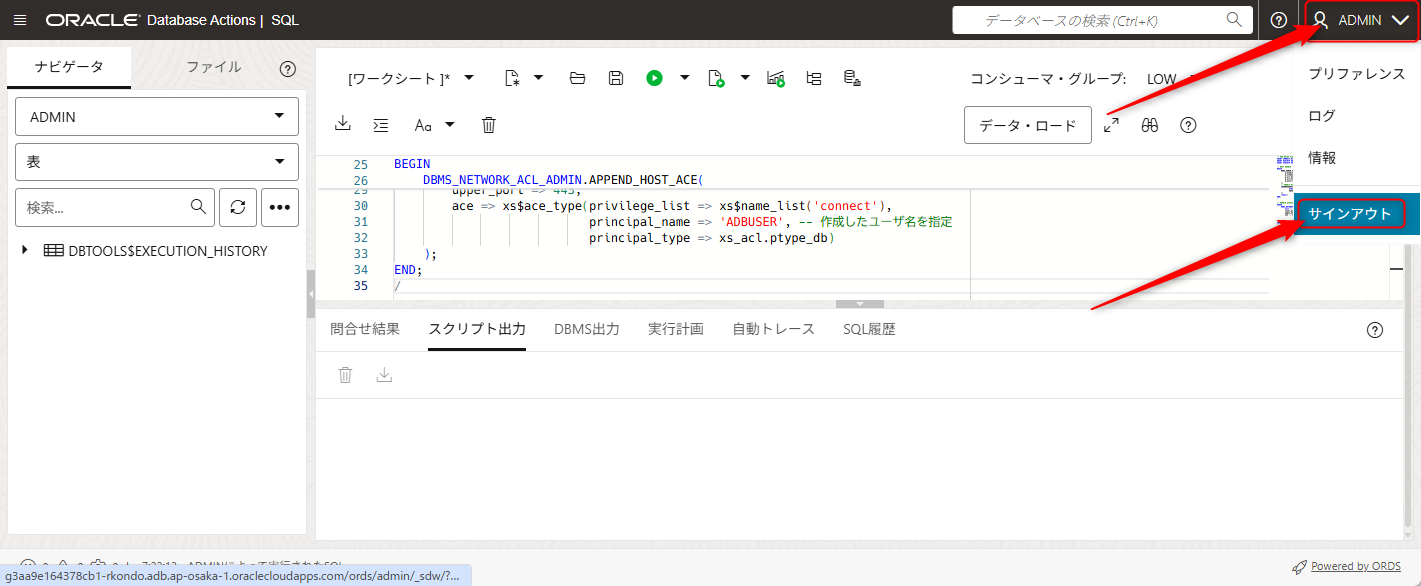
ログイン画面に切り替わりますので、作成したADBUSERでログインします。

開発タブからSQLを選択して開きます。
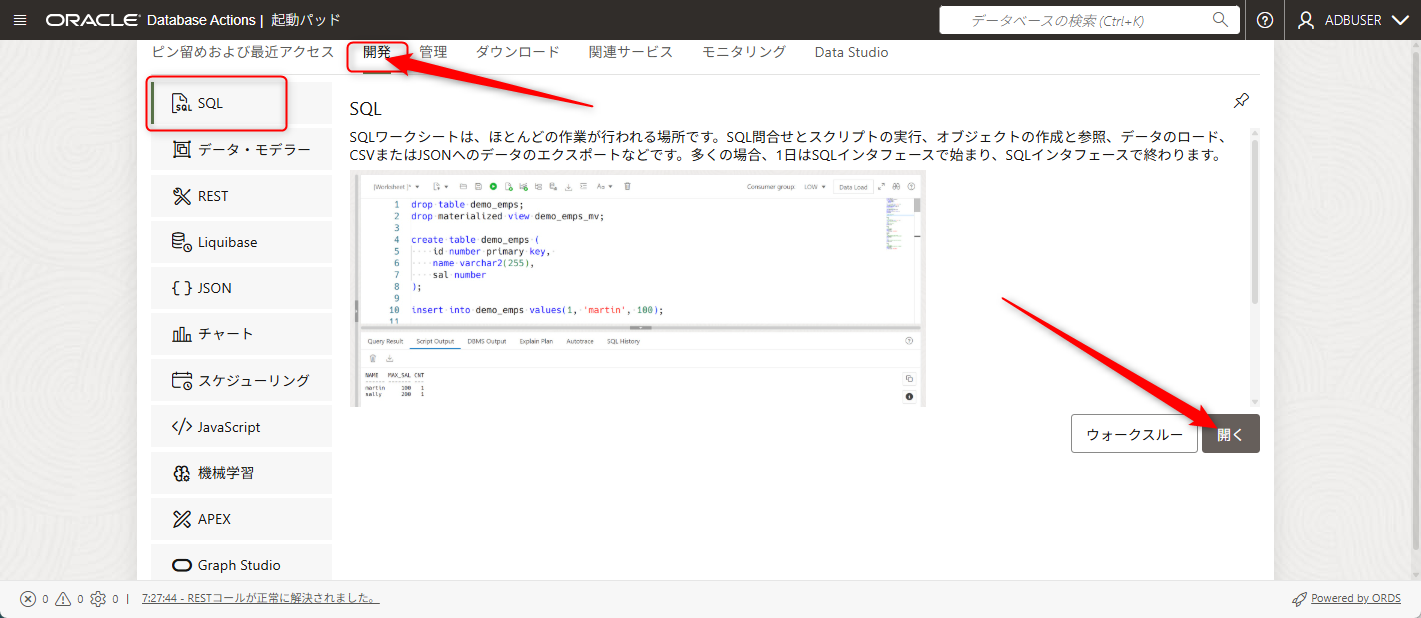
SQLの画面になりましたら、OPENAI_CREDENTIALを作成するために以下のSQLを張り付けます。
このSQLの「sk-proj-」から始まる部分には、利用可能なAPIキーを指定してください。
-- クレデンシャル「OPENAI_CREDENTIAL」を作成します。
-- sk-proj-から始まるところを利用可能なAPIキーに修正します。
begin
dbms_vector_chain.create_credential(
credential_name => 'OPENAI_CREDENTIAL',
params => JSON('
{"access_token":"sk-proj-KWQZ85VN4Koj1iduytTdrfQ30H4sDSYJbGbg9a19T6k48sLrTYYa1o2O2X0<略>X_-z-RP4A"}
')
);
end;
/
ペーストしたら矢印の場所か、F5キーを押します。

この作業によって張り付けたSQLが実行され、クレデンシャル(OPENAI_CREDENTIAL)が作成できました。
5. 作成したDBユーザーで、ChatGPTのURLやモデル名を格納したテーブルを作成する
ChatGPTのChatモデルやEmbeddingsモデルを活用するうえで必要なURLやモデル名などの情報、及び先ほど作成したクレデンシャルなどの情報をテーブルに格納します。
SQLの画面を開いていると思いますので、まずは記載したSQLを削除します。
その後、以下のSQLを張り付けます。
create table llm_config
( apis varchar2(100)
, provider varchar2(100)
, llm_model varchar2(100)
, api_url varchar2(200)
, credential_name varchar2(200)
);
insert into llm_config values
( 'chat'
, 'openai'
, 'gpt-4o-mini'
, 'https://api.openai.com/v1/chat/completions'
, 'OPENAI_CREDENTIAL');
insert into llm_config values
( 'embeddings'
, 'openai'
, 'text-embedding-3-small'
, 'https://api.openai.com/v1/embeddings'
, 'OPENAI_CREDENTIAL');
commit;
上記で挿入したデータについて簡単に解説します。
apis列にはこの後作成するファンクションの内部でハンドリングするためのchatもしくはembeddingsの文字列を入れます。
provider列にはdbms_vector_chainのサード・パーティ・プロバイダの中から今回利用するプロバイダ名である openai を指定します。
llm_model列にはopenaiのmodelが記載されたサイトから、利用したいモデルを選びます。ここではチャットモデルに安価なGPT-4o miniを、エンベディングモデルにtext-embedding-3-smallを選んでいます。
api_url列についてはOpenAIのAPIリファレンスを参照し、チャットモデルはChatモデルについて記載されたURLを利用し、エンベディングモデルにはEmbeddingsモデルについて記載されたURLを利用しています。
credential_name列には先ほど作成したクレデンシャル情報を記載します。
よくわからない場合は、そのまま貼り付けていただけたらと思います。
その後、今まで同様にボタンを押してSQLを実行します。
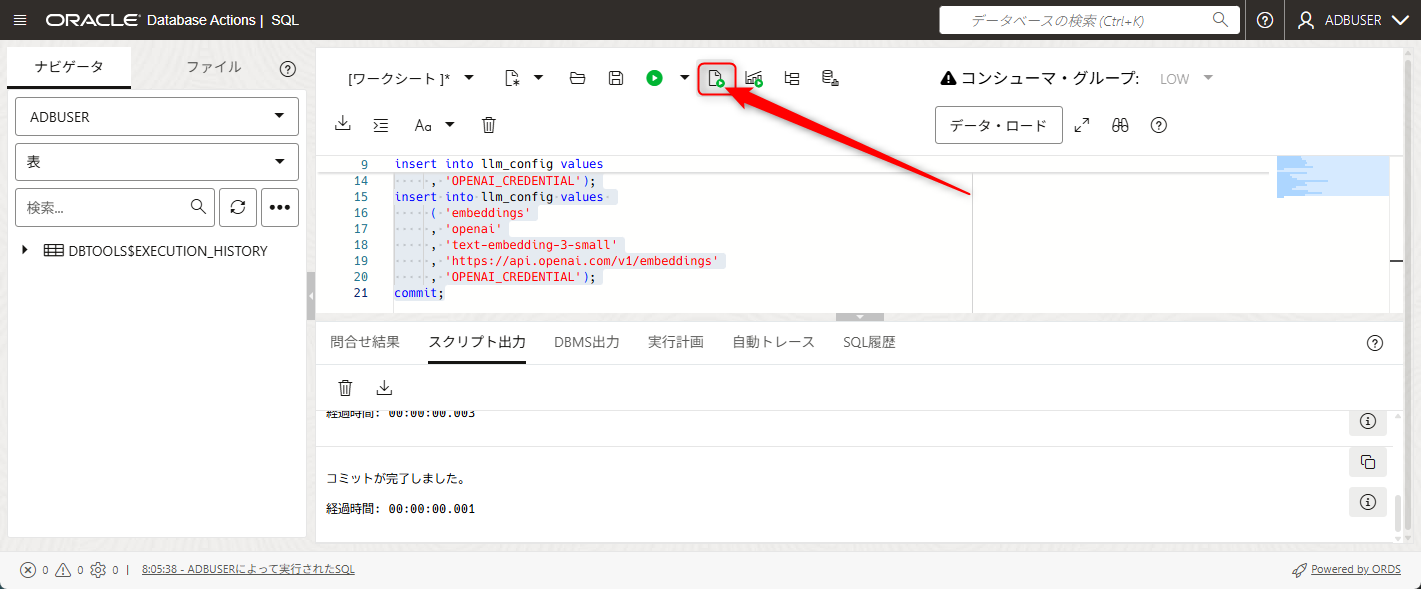
以上のステップで、chatモデルやembeddingsモデルを扱う上での必要な情報をDB内に格納することができました。
次のステップでは実際にchatモデルやembeddingsモデルを扱う為のaskllmパッケージを導入します。
6. 作成したDBユーザーで、ChatGPTに問い合わせするパッケージ askllm をインストールする
今回利用するaskllmパッケージをインストールします。
まずは先ほど同様、記載したSQLを削除します。
その後、以下のSQLを張り付けて実行します。
create or replace package askllm
as
function embeddings(i_text IN CLOB, i_llm_model IN varchar2) RETURN vector;
function chat(i_question IN CLOB, i_llm_model IN varchar2) RETURN CLOB;
function rag(i_question IN CLOB, i_provider IN varchar2) RETURN CLOB;
end;
/
create or replace package body askllm
is
function embeddings(i_text IN CLOB, i_llm_model IN varchar2) RETURN vector
IS
v_credential varchar2(100);
v_url varchar2(200);
v_provider varchar2(100);
o_vector vector;
BEGIN
-- llm_configから必要な情報を抽出
select credential_name, api_url, provider into v_credential, v_url,v_provider from llm_config
where llm_model = i_llm_model and apis = 'embeddings' fetch first 1 rows only;
if v_provider = 'openai'
then
-- utl_to_embeddingsのインプット引数はこちらを参照 https://docs.oracle.com/cd/G11854_01/vecse/utl_to_embedding-and-utl_to_embeddings-dbms_vector_chain.html
select et.embed_vector into o_vector
from dbms_vector.utl_to_embeddings(
i_text,
json('{ "provider": "' || v_provider || '"
, "credential_name": "' || v_credential || '"
, "url": "' || v_url || '"
, "model": "' || i_llm_model || '"}')
) t,
JSON_TABLE(
t.column_value,
'$[*]' COLUMNS (
embed_id NUMBER PATH '$.embed_id',
embed_data CLOB PATH '$.embed_data',
embed_vector CLOB PATH '$.embed_vector'
)
) et;
end if;
RETURN o_vector;
END embeddings;
function chat(i_question IN CLOB, i_llm_model IN varchar2) RETURN CLOB
IS
v_credential varchar2(100);
v_url varchar2(200);
v_provider varchar2(100);
o_output CLOB;
BEGIN
-- llm_configから必要な情報を抽出
select credential_name, api_url, provider into v_credential, v_url,v_provider from llm_config
where llm_model = i_llm_model and apis = 'chat' fetch first 1 rows only;
if v_provider = 'openai'
then
select dbms_vector_chain.utl_to_generate_text(
i_question,
json('{ "provider" : "' || v_provider || '"
, "credential_name": "' || v_credential || '"
, "url": "' || v_url || '"
, "model": "' || i_llm_model || '"
, "max_tokens": 256
, "temperature": 0}'))
into o_output from dual;
end if;
RETURN o_output;
END chat;
function rag(i_question IN CLOB, i_provider IN varchar2) RETURN CLOB
IS
v_llm_model varchar2(100);
v_url varchar2(200);
v_sql varchar2(2000);
v_refinfo CLOB;
o_output CLOB;
BEGIN
-- llm_configから必要な情報を抽出(embeddings)
select llm_model into v_llm_model from llm_config
where provider = i_provider and apis = 'embeddings' fetch first 1 rows only;
-- knowledgetabテーブルのvector_col列に対して検索を実行し、最も近いデータをv_refinfoに格納する
v_sql := 'select question || answer from knowledgetab ' ||
' order by vector_distance(vector_col , askllm.embeddings(''' || i_question ||
''',''' || v_llm_model || '''), EUCLIDEAN) fetch first 1 rows only';
execute immediate v_sql into v_refinfo;
-- llm_configから必要な情報を抽出(chat)
select llm_model into v_llm_model from llm_config
where provider = i_provider and apis = 'chat' fetch first 1 rows only;
-- v_refinfoのデータを活用してLLMで回答を生成する
select askllm.chat('
以下の参考情報を用いて質問に回答してください。
参考情報:' || v_refinfo || '
---
質問文:' || i_question || '
回答:
',v_llm_model) into o_output from dual;
RETURN o_output;
END rag;
end;
/
これまでと同様に実行することで、インストールができます。

以上のステップで、ChatGPTに問い合わせするChatモデルと、ベクトル変換するEmbeddingsモデルがaskllmパッケージを使って利用することができるようになりました。
例えば以下のようなChatモデルの問い合わせが可能になります。
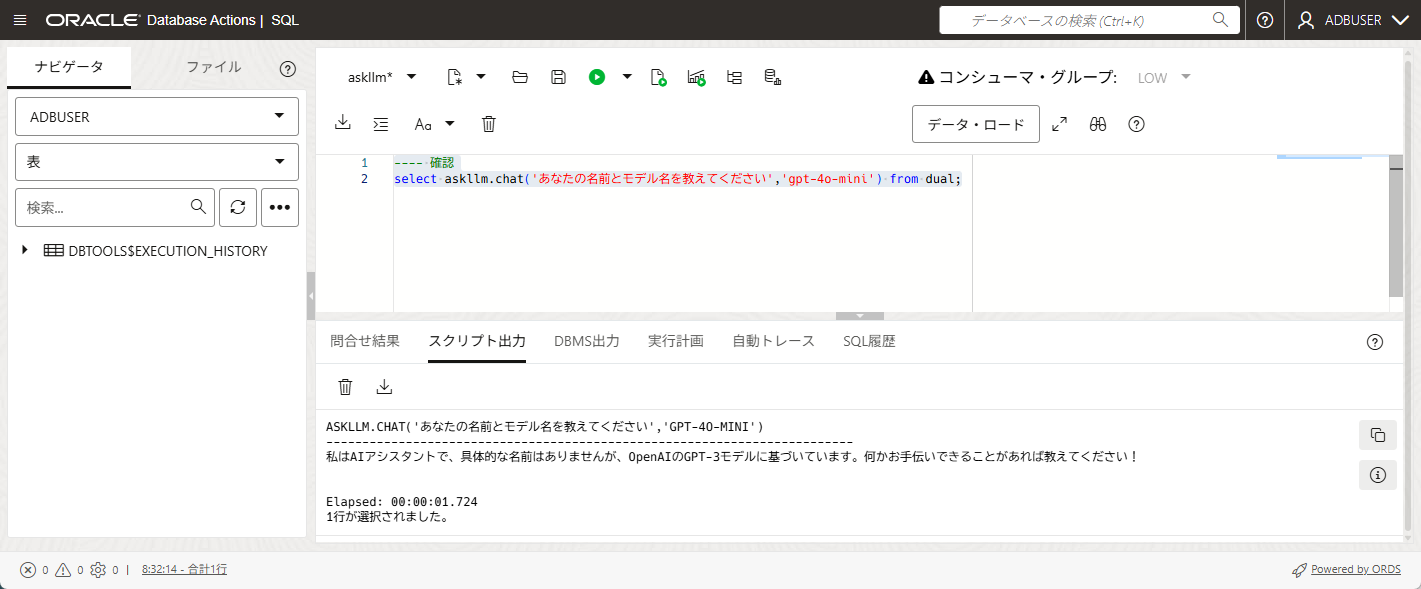
select askllm.chat('あなたの名前とモデル名を教えてください','gpt-4o-mini') from dual;
ASKLLM.CHAT('あなたの名前とモデル名を教えてください','GPT-4O-MINI')
-------------------------------------------------------------------------
私はAIアシスタントで、具体的な名前はありませんが、OpenAIのGPT-3モデルに基づいています。何かお手伝いできることがあれば教えてください!
ChatGPTが回答を作成していることが確認できました。
次のステップでは、DB内に作成するテーブルのデータを参照させて回答をさせるRAGのデータを用意します。
7. RAGでアクセスするためのテーブルを作成し、データを格納する
質問に対して、事前に用意されたナレッジデータを活用して回答を考えるRAGシステムを構築するので、ナレッジデータをテーブルに格納します。
このテーブル名や列名などは次のステップに記載しているパッケージ内でハードコートしているため、この名前の通りのテーブルで作成するようにしてください。
まずは先ほど同様、記載したSQLを削除します。
その後、以下のSQLを張り付けてナレッジデータを挿入し、ベクトル列 vector_col列を作成したうえで、ベクトル値を投入します。
-- KNOWLEDGETAGを用意(参照:https://tabizine.jp/article/186153/)
create table knowledgetab (id number, question clob, answer clob);
insert into knowledgetab values (1,'花粉飛散量の多い都道府県','1位が三重県で、ピーク時は1平方センチメートル当たり17,810個も飛んでいるというデータがあります。2位は福島県、3位は栃木県です。');
insert into knowledgetab values (2,'晴れの日が多い都道府県','年間晴天日数が最も多い都道府県は高知県で1年平均245.1日です。2位が徳島県と愛媛県で、最下位が秋田県です。');
insert into knowledgetab values (3,'アイスが好きな人が多い都道府県','アイスやシャーベットの消費量が最も多い都道府県は石川県で、次いで富山県、栃木県となります。もっとも消費量が少ないのが沖縄県です。');
insert into knowledgetab values (4,'旅行者が満足した国内旅先の都道府県','2018年の調査によると、1位が北海道、2位が沖縄、3位が東京でした。');
commit;
-- vector型のvector_col列を追加
alter table knowledgetab add (vector_col vector);
-- knowledgetabテーブルの question列と answer列を結合したデータをベクトル変換し、vector_col列に投入する。
update knowledgetab set vector_col = askllm.embeddings(question || answer,'text-embedding-3-small');
commit;

正常にベクトル変換ができているかを確認するため、テーブルをSelectしてみます。
select * from knowledgetab;
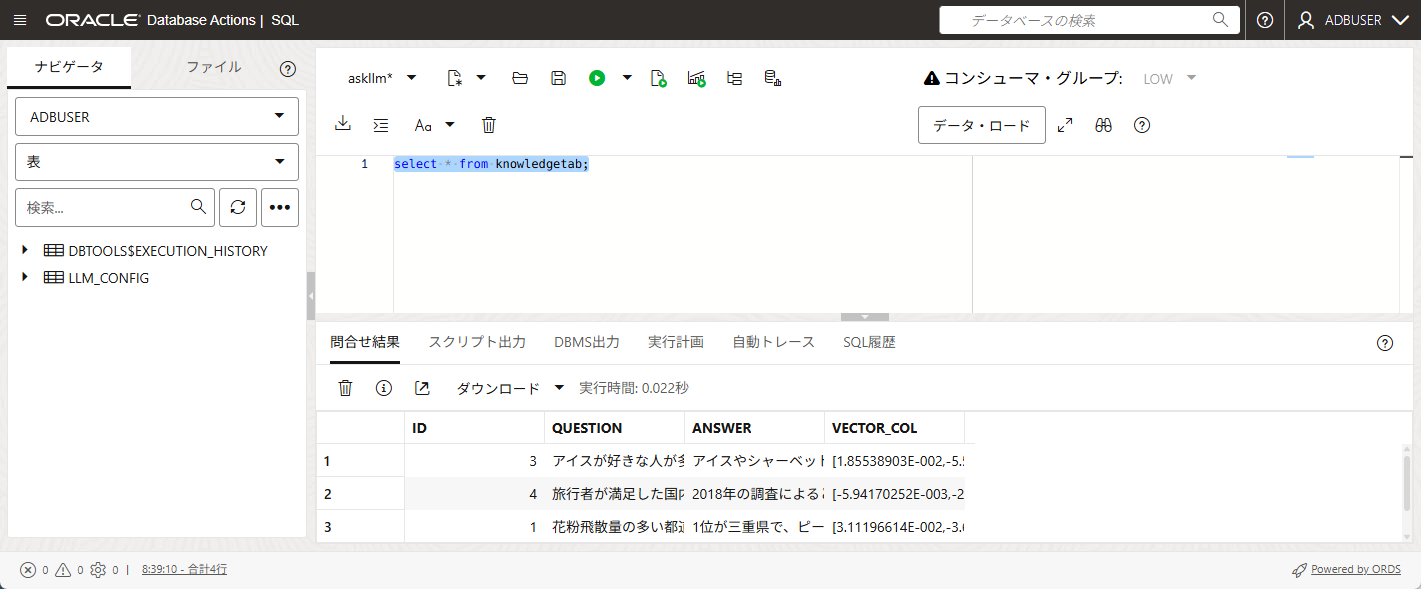
vector_col列が作成され、ベクトル値が格納されていることが確認できました。
以上でRAGを実行するための準備は完了となります。
RAGでKnowledgeテーブルの内容を参考にして回答させる
今回knowledgetabテーブルには以下の情報を格納しています。
| ID | Question | Answer |
|---|---|---|
| 1 | 花粉飛散量の多い都道府県 | 1位が三重県で、ピーク時は1平方センチメートル当たり17,810個も飛んでいるというデータがあります。2位は福島県、3位は栃木県です。 |
| 2 | 晴れの日が多い都道府県 | 年間晴天日数が最も多い都道府県は高知県で1年平均245.1日です。2位が徳島県と愛媛県で、最下位が秋田県です。 |
| 3 | アイスが好きな人が多い都道府県 | アイスやシャーベットの消費量が最も多い都道府県は石川県で、次いで富山県、栃木県となります。もっとも消費量が少ないのが沖縄県です。 |
| 4 | 旅行者が満足した国内旅先の都道府県 | 2018年の調査によると、1位が北海道、2位が沖縄、3位が東京でした。 |
knowledgetabに上記の情報が格納されているため、もしも「国内旅行しようと思うけど、どの都道府県がお勧めですか?」と質問してみた場合、ID:4の内容を参考にして「2018年の調査結果だと北海道がお勧め」と回答してくれることが期待されます。
まずは何も参考情報を使わずに検索したらどのような回答が来るかを確認します。
select askllm.chat('国内旅行しようと思うけど、どの都道府県がお勧めですか?','gpt-4o-mini') chat from dual;
CHAT
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
日本国内には魅力的な都道府県がたくさんありますので、旅行の目的や好みによっておすすめの場所が変わります。以下はいくつかのおすすめの都道府県です。
1. **京都府**: 歴史的な寺院や神社が多く、伝統的な文化を体験できます。特に金閣寺や清水寺、祇園の街並みは必見です。
2. **北海道**: 自然が豊かで、四季折々の美しい風景が楽しめます。冬はスキー、夏は大自然の中でのアクティビティが人気です。美味しい海鮮や乳製品も魅力です。
3. **沖縄県**: 美しいビーチや独自の文化が楽しめます。リゾート気分を味わいたい方には最適です。シュノーケリングやダイビングも楽しめます。
4. **福岡県**: 美味しい食べ物が豊富で、特にラーメンやもつ鍋が有名です。また、博
京都をはじめとしていろんな場所を挙げていただきました。
北海道も上げていますが、knowledgetabの内容とは関係のない回答をしています。
では、次にRAGで検索してみます。
select askllm.rag('国内旅行しようと思うけど、どの都道府県がお勧めですか?','openai') rag from dual;
RAG
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
国内旅行を考えているなら、特におすすめの都道府県は北海道、沖縄、東京です。2018年の調査によると、旅行者が満足した旅先として北海道が1位、沖縄が2位、東京が3位にランクインしています。
北海道は美しい自然や美味しい食べ物が魅力で、四季折々の楽しみがあります。沖縄は独特の文化や美しいビーチがあり、リラックスしたい方にぴったりです。東京は多様な観光スポットやショッピング、グルメが楽しめる都市です。
それぞれの都道府県には異なる魅力があるので、あなたの興味に合わせて選んでみてください!
ちゃんとknowledgetabの中に格納されている2018年のデータを参考にして、北海道と沖縄、東京を回答をしてくれました。
まとめ
23aiから利用可能なdbms_vector_chainを活用することで、LLMへのChatからEmbeddings、RAGまでを短いコードで実装することができました。
引数にモデル名も入れないようにすることも考えましたが、ChatGPTだけではなくCohereやOCI Generative AIも同様に活用することができる&llm_configテーブルを見ればモデル名もわかるので、一旦は引数にモデル名も入れるようにしています。
なお、環境としてAutonomous Database の Always Free を使えば、かかる費用はLLMへの問い合わせ費用だけになるので、ちょっとしたRAGシステムを安く作りたいという時はお勧めです。